当前位置:网站首页>Decrypting the future database design: implementation of mongodb's new storage engine wiredtiger (transaction)
Decrypting the future database design: implementation of mongodb's new storage engine wiredtiger (transaction)
2020-11-09 12:53:00 【osc_usgpahnick】
Decrypt future database design :MongoDB New storage engine WiredTiger Realization ( Affairs )
Introduction : Computer hardware is developing rapidly , The data scale is expanding rapidly , But the database still uses the architecture of ten years ago ,WiredTiger Try to break all this , Make full use of multi-core and large memory era , Develop a database that really meets the needs of future big data management . This paper is written by yuan Rongxi to 「 High availability Architecture 」 contribute , Introduce to WiredTiger Understanding of database design in the process of source code learning .
 Yuan Rongxi , Learn from Bajun Engineer ,2015 He joined xuebajun in 1987 , Responsible for the architecture design and implementation of xuebajun's network real-time transmission and distributed system , Focus on basic technology , Over the Internet 、 Database kernel 、 Knowledge of distributed systems and concurrent programming .
Yuan Rongxi , Learn from Bajun Engineer ,2015 He joined xuebajun in 1987 , Responsible for the architecture design and implementation of xuebajun's network real-time transmission and distributed system , Focus on basic technology , Over the Internet 、 Database kernel 、 Knowledge of distributed systems and concurrent programming .
WiredTiger From being MongoDB Acquisition to become MongoDB The default storage engine for a year and a half , It has been developing rapidly , Also gradually known to the outside world .
Modern computers are near 20 Over the years CPU Computing power and memory capacity are developing rapidly , But the speed of disk access has not been improved ,WT It is in such a case that it was developed , It's designed to make the most of CPU Lock free parallel framework for memory model of parallel computing , bring WT The engine is multi-core CPU It outperforms other storage engines .
For disk storage features ,WT A set of implementation based on BLOCK/Extent Friendly disk access algorithm based on , bring WT In data compression and disk I/O There are obvious advantages in visiting . Based on snapshot technology ACID Business ,snapshot Technology has greatly simplified WT Transaction model of , It abandons the traditional transaction lock isolation, and at the same time ensures the transaction's ACID.WT According to the characteristics of modern memory capacity, this paper implements a new method based on Hazard Pointer Of LRU cache Model , It makes full use of the memory capacity and has high transaction read-write concurrency .
In this paper , We mainly aim at WT The engine's transactions are analyzed , Let's see how its transactions are implemented . When it comes to database transactions , The concept of transaction and ACID A brief introduction .
Basic concepts : Affairs and ACID
What is business ?
A transaction is to accomplish a thing through a series of operations , In the course of these operations , Either these operations are performed completely , Or none of these operations are performed , There is no intermediate state , Transaction is divided into transaction execution phase and transaction commit phase . When it comes to business , You think of its characteristics — ACID, So what is ACID Well ? Let's use a real-world example to illustrate :AB Both students have accounts 1,000 Yuan ,A By bank transfer to B Turn around 100, This transaction is divided into two operations , From A Students account deduction 100, towards B Student account number increased 100.
Atomicity (Atomicity)
The series of operations that make up a transaction are a whole , Or do it all , Or not . Through the above example, it is from A Students deduct money and pay to B More students 100 It happened together , There can't be a deduction A The money , But it didn't increase B Of the money .
Uniformity (Consistency):
Before and after transaction start , The integrity and state of the database has not been compromised . How do you understand this ? Namely A、B The sum of the money they are transferring is 2,000, After the transfer, the sum of the two must also be 2,000. This transfer transaction will not destroy this state .
Isolation, (Isolation):
When multiple transactions are executed concurrently , The intermediate state of transaction execution is inaccessible to other transactions .A Transfer out 100 But the transaction did not commit , At this time, when the bank staff inquires about its account number , What you see should still be 1,000, No 900.
persistence (Durability)
Once the transaction has been committed , The results will be preserved forever , Not affected by any fault .A Once the transfer is completed , that A Namely 900,B Namely 1,100, This result will always be stored in the bank's database , Until the next time they do business .
WT How to implement transactions
You know the basic concept of transactions and ACID after , Let's see WT How the engine implements transactions and ACID. To understand the implementation, you need to know the construction of its transaction and the related technology ,WT There are three main technologies used in the implementation of transactions :
- snapshot( Transaction snapshot )
- MVCC( Multi version concurrency control )
- redo log( Redo log )
To implement these three technologies , It also defines a transaction object and a global transaction manager based on these three technologies . The transaction object is described as follows
wt_transaction{
transaction_id: This transaction is globally unique ID, The version number used to indicate the transaction modification data
snapshot_object: The collection of other ongoing and uncommitted transactions at the start or operation time of the current transaction , For transaction isolation
operation_array: List of operations performed in this transaction , For transaction rollback .
redo_log_buf: Operation log buffer . For persistence after transaction commit
State: The current state of the transaction
}
WT Multi version concurrency control of
WT Medium MVCC Is based on key/value in value List of values , This linked list cell stores the transactions of the current version operation ID And the modified value of the operation . Described below :
wt_mvcc{
transaction_id: This time the transaction is modified ID
value: The value after this modification
}

WT The data changes in are all made in this linked list append operation , Every time you change a value, it's append To the head of the list , Each time the value is read, the read is modified from the chain header according to the value corresponding to the transaction transaction_id And this time reading business snapshot To determine whether it is readable , If it's not readable , Move towards the end of the list , Until we find the data version of the read transaction . A sample of :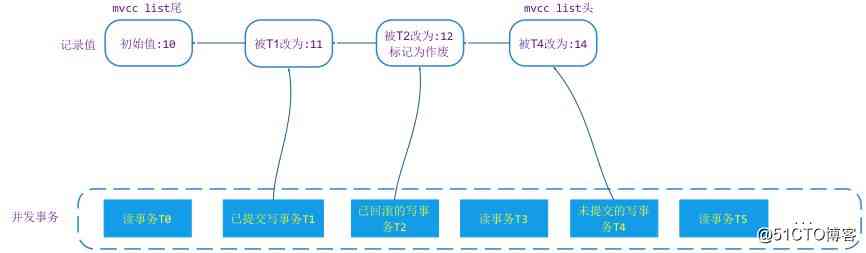
chart 1, Click on the image to zoom full screen
Above picture , Business T0 It happened at the earliest time ,T5 It happened at the latest .T1/T2/T4 It's a modification of the record . So in MVCC list There will be more 3 Versions of data , Namely 11/12/14. If transactions are based on snapshot Level of isolation ,T0 You can only see T0 Previously submitted values 10, Read business T3 When accessing a record, the value it can see is 11,T5 Read transactions when accessing records , because T4 Not submitted , It can only see 11 The value of this version . This is it. WT Of MVCC The basic principle .
WT Business snapshot
The above mentioned business many times snapshot, So what is business snapshot Well ? In fact, before the transaction starts or the operation is performed on the whole WT Take a snapshot of the transactions in progress or to be executed within the engine , Save the state of all transactions of the whole engine at that time , Determine what you see for yourself , What is invisible by itself . To put it bluntly, it's a series of things ID Section .WT The diagram of the whole transaction concurrency interval of the engine is as follows :
chart 2, Click on the image to zoom full screen
WT In the engine snapshot_oject There is a minimum execution transaction snap_min、 One of the biggest things snap max And one in [snap_min, snap_max] The sequence of all the executing write transactions in the interval consists of . If the picture above is in T6 Always do one transaction in the system snapshot, So what happens is
snapshot_object = {
snap_min=T1,
snap_max=T5,
snap_array={T1, T4, T5},
};
T6 There are two ranges of transaction modifications that can be accessed : All less than T1 Modification of transactions [0, T1) and [snap_min, snap_max] Transactions that have already been committed T2 Modification of . let me put it another way , Everything appears in snap_array Medium or business ID Greater than snap_max The modification of a transaction to a transaction T6 It's invisible . If T1 In establishment snapshot And then submitted ,T6 You can't access T1 Modification of . This is snapshot The basic principle of mode isolation .
Global transaction manager
Through the top snapshot Description of , We can know to create a snapshot of the entire system transaction , We need a global transaction management to reference transaction snapshot , stay WT How is the global transaction manager defined in the engine ? stay CPU Multi core and multi thread , How does it manage concurrency ? Next, we will analyze its definition first :
wt_txn_global{
current_id: Global write transactions ID Produce seeds , Increasing all the time
oldest_id: The earliest write transaction in the system that is still in execution ID
transaction_array: Array of system transaction objects , Save all transaction objects in the system
scan_count: Scanning transaction_array The number of thread transactions in the array , For building snapshot Lock free concurrency of procedures
}
transaction_array It's a picture 2 The sequence of transaction objects in the interval where the transaction is being executed . In establishment snapshot when , It will be for the whole transaction_array Do a scan , determine snap_min/snap_max/snap_array These three parameters and updates oldest_id, In the process of scanning , Anyone who transaction_id It's not equal to WT_TNX_NONE Transactions that are considered to be in execution and have modification operations , Join directly in snap_array among . The whole process is a lock free operation process , The process is as follows :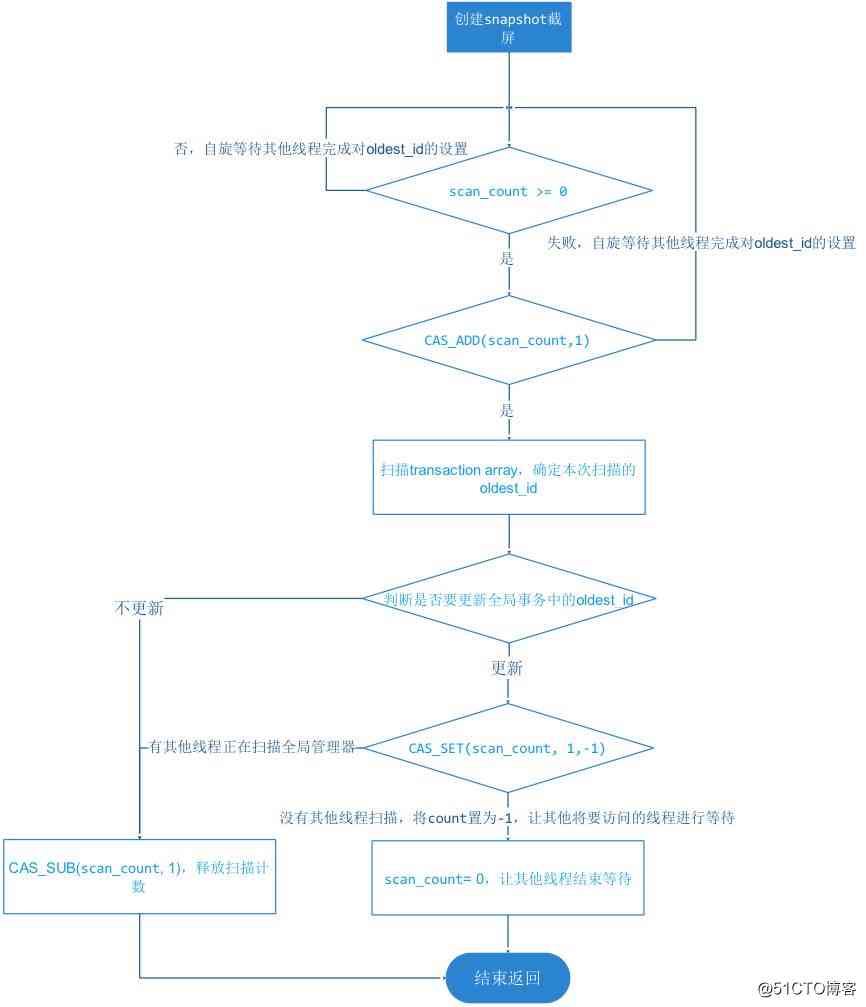
chart 3, Click on the image to zoom full screen
establish snapshot The process of snapshot is in WT Inside the engine is very frequent , Especially in the case of a large number of automatic commit type short transaction execution , Created by snapshot Action CPU Competition is a huge expense , So here WT Not used spin lock, Instead, it uses a lock free concurrency design as shown in the figure above , This design follows the concurrent design principle we started with .
Business ID
from WT The engine creates transactions snapshot In the process of , Now we can be sure ,snapshot Is a transaction with write operations , Read only transactions are not snapshot Of , because snapshot The goal is isolation MVCC list Records in , adopt MVCC in value The business of ID And reading business snapshot Read the version , And reading the transaction itself ID It doesn't matter .
stay WT In the engine , When opening a transaction , The engine will put a WT_TNX_NONE(= 0) The business of ID Set to open transaction , When it first writes to a transaction , Before the data is modified, it will pass through the current_id To assign a globally unique transaction ID. This process is also through CPU Of CAS_ADD Atomic operations complete the lock free process .
WT The transaction process of
General affairs are two phases : Transaction execution and transaction commit . Before the transaction is executed , We need to create a transaction object and open it first , And then we start to execute , If the execution encounters a conflict and or fails to execute , We need to roll back the transaction (rollback). If the execution is done normally , Finally, just submit (commit) It can .
From the above description, we can see that the transaction process has : Create open 、 perform 、 Commit and roll back . From these processes to analyze WT How to realize these processes .
The transaction open
WT In the process of transaction opening , First, a transaction object is created for the transaction and added to the global transaction manager , Then, the isolation level of the transaction and redo log And set the transaction status to the execution state , Finally, if the isolation level is ISOLATION_SNAPSHOT(snapshot Class isolation ), Create a system concurrent transaction before this transaction execution snapshot. As for why you want to create a snapshot, rearwards WT The transaction isolation chapter details .
Transaction execution
The transaction is in the execution phase , If it's a read operation , Don't make any records , Because read operations do not require rollback and commit . If it's a write operation ,WT Every write operation will be recorded in detail . The transaction object described above (wt_transaction) There are two members in , One is operation operation_array, One is redo_log_buf. These two members are used to record the details of the modification operation , stay operation_array In the array unit of , Contains a point to MVCC list Pointer corresponding to the modified version value . The detailed update process is as follows :
- Create a MVCC list Value unit object in (update)
- According to the transaction object's transaction id And transaction status to determine whether a write transaction has been created for this transaction ID, without , Assign a transaction to this transaction ID, And set the transaction state to HAS_TXN_ID state .
- Will the business of ID Set to update Unit as MVCC Version number .
- Create a operation object , And point the value pointer of this object to update, And will the operation Added to this transaction object operation_array.
- take update Unit added to MVCC list On the head of the chain .
. Write a piece of redo log To the object of this transaction redo_log_buf among .
The schematic diagram is as follows :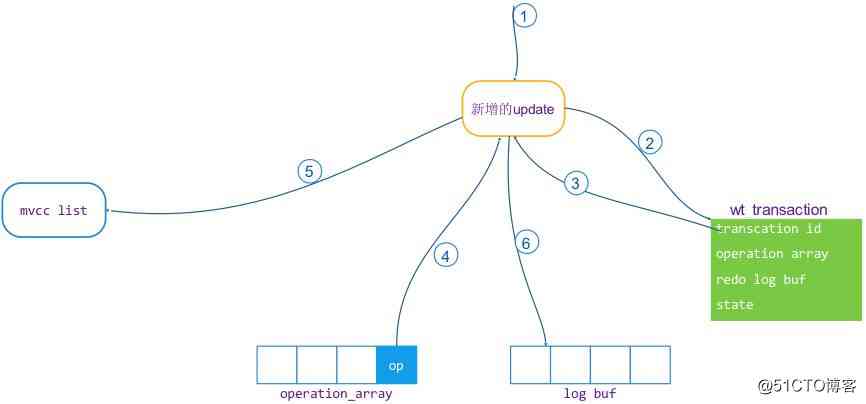
chart 4, Click on the image to zoom full screen
Transaction submission
WT The commit process of the engine to the transaction is relatively simple , In the transaction object to be committed first redo_log_buf The data in is written to redo log file( Redo log file ) in , And will redo log file Persist to disk . Clear the commit transaction object's snapshot object, In the submitted transaction object transaction_id Set to WT_TNX_NONE, Ensure that other transactions are creating system transactions snapshot The status of this transaction is the committed state .
Transaction rollback
WT The rollback process of the engine to the transaction is also relatively simple , Go through the whole thing first operation_array, For each array unit, it corresponds to update The business of id Set it to a WT_TXN_ABORTED(= uint64_max), Mark MVCC The corresponding modified cell value is rolled back , In other reading transactions MVCC When reading operations , Just skip the abandoned value . The whole process is a lock free operation , Efficient 、 concise .
WT Transaction isolation of
Traditional database transaction isolation is divided into :
- Read-Uncommited( Uncommitted read )
- Read-Commited( Submit to read )
- Repeatable-Read( Repeatable )
- Serializable( Serialization )
WT The engine does not implement these four levels according to the traditional transaction isolation , It's based on snapshot The characteristics of the realization of their own Read-Uncommited、Read-Commited And one called snapshot-Isolation( Snapshot Isolation ) Transaction isolation method of .
stay WT No matter what kind of transaction isolation method is selected in the , It is based on the snapshot of transaction execution in the system . Let's see WT How to realize the above three ways ?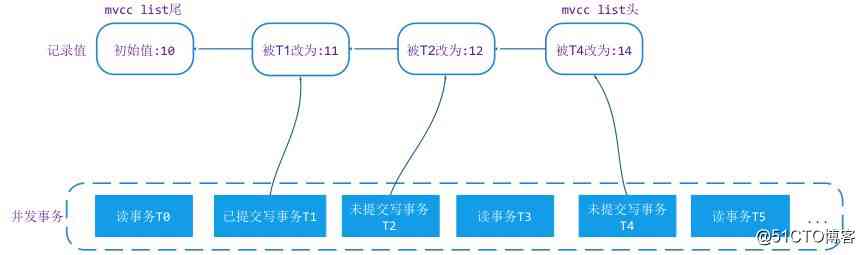
chart 5, Click on the image to zoom full screen
Read-uncommited
Read-Uncommited( Uncommitted read ) Isolated transactions always read the latest changes in the system when reading data , Even if the modified transaction has not committed the same read , This is actually a kind of dirty reading .WT When the engine implements this separation mode , Is to change the snap_object.snap_array Leave blank , In the reading MVCC list When the version value in , Always read MVCC list The first version data on the list header .
Illustrate with examples , In the figure 5 in , If T0/T3/T5 The transaction isolation level of is set to Read-uncommited Words ,T1/T3/T5 stay T5 When reading the value of the system after the time , All I read is 14. Generally, the database will not be set in this isolation mode , It's against the business of ACID characteristic . It may be used in some performance focused and dirty read insensitive scenarios , Such as web pages cache.
Read-Commited
Read-Commited( Submit to read ) The isolated transaction always reads the latest committed data modification in the system when reading data , This modification transaction must be in commit state . This isolation level may be different when a long transaction reads a value many times , This is what is often mentioned “ Phantom reading ”. stay WT Engine Implementation read-commited Isolation means that the transaction takes a snapshot of the transaction in the system before performing each operation , And then read and write on this snapshot .
Or look at the picture 5,T5 Transaction in T4 Before the transaction is committed, it does the transaction before reading
snapshot={
snap_min=T2,
snap_max=T4,
snap_array={T2,T4},
};
In the reading MVCC list when ,12 and 14 Modify the corresponding transaction T2/T4 All appear in snap_array in , It can only be read forward 11,11 yes T1 Modification of , and T1 Not in snap_array, explain T1 Submitted , So return 11 This is worth T5.
After that T2 Submit ,T5 Read the value again after it's committed , I'll do it again
snapshot={
snap_min=T4,
snap_max=T4,
snap_array={T4},
},
Now it's reading MVCC list When the version in , The latest commit changes will be read 12.
Snapshot-Isolation
Snapshot-Isolation( Snapshot Isolation ) Isolation is the last committed value version modification seen at the beginning of the read transaction , This value will only see this version during the whole read transaction execution , No matter how many times this value is modified by other transactions during this read transaction execution , This kind of isolation is not going to happen “ Phantom reading ”.WT It's very simple to implement this isolation , At the beginning of a transaction, do a transaction that is executing in the system snapshot, This snapshot It is used until the transaction is committed or rolled back . Or look at the picture 5, T5 At the beginning of the transaction , The execution of transactions in the system
snapshot={
snap_min=T2,
snap_max=T4,
snap_array={T2,T4}
},
When he reads the value, he reads 11. Even if it's T2 Finished submitting , but T5 Of snapshot The execution process does not update ,T5 The reading is still 11.
This kind of isolation is quite special , That is, if there are data changes that are invisible to the transaction , When a transaction attempts to modify this data, it fails and rolls back , The purpose of this is to prevent ignoring invisible data changes .
Through the above analysis of the three transaction isolation methods ,WT There is no traditional transaction exclusive lock and shared access lock to ensure transaction isolation , But by writing transactions to the system snapshot To achieve . The purpose of this is to improve the concurrency of system transactions while ensuring transaction isolation .
How to guarantee the memory design Durability: Transaction log
Through the above analysis, we can know that WT The modification of transactions is done in memory , The transaction will not be modified when it is committed MVCC list The data in it is flushed into the disk ,WT How to ensure that the results of transaction commit are preserved permanently ?
WT The engine ensures the persistence and reliability of transactions by redo log( Redo operation log ) The way to achieve , Write operation log is mentioned in the transaction execution and transaction commit phases of this paper .WT The operation log is based on K/V Logical log of operations , Its log is not based on btree page The physical log of . The popular point is to record the action of modifying data , for example : Insert a key = 10, value = 20 Record your actions in :
{
Operation = insert,( action )
Key = 10,
Value = 20
};
Record the data of the action as append Write to by appending wt_transaction In the object redo_log_buf in , Wait until the transaction is committed redo_log_buf Data in has been synchronized written to WT Redo log of the disk file . If the database program is abnormal or crashes , You can go through the last one checkpoint( checkpoint ) The location repeats the disk file on the disk to recover the committed transaction to ensure the persistence of the transaction .
How to realize through operation log Durability?
According to the description above , There are a few questions that need to be clarified :
1、 How to design the operation log format ?
2、 When a transaction is committed concurrently , How the log of each transaction is written to the disk ?
3、 How the journal repeats itself ? It and checkpoint What is the relationship between ?
Before analyzing these three questions, let's look at WT How to manage redo log files , stay WT An engine is defined as LSN Serial number structure , The log object is manipulated by LSN To determine the location of the storage ,LSN Namely Log Sequence Number( Log serial number ), It's in WT The definition of file is file number plus file offset ,
wt_lsn{
file: The file number , Specify which log file is in
offset: The offset in the file , Specify the starting position of the storage file in the log object file
}
WT Through this LSN To manage redo log files .
Log format design
WT The operation log object of the engine ( Hereinafter referred to as logrec) This corresponds to the committed transaction , Each operation of the transaction is recorded as a logop object , One logrec Contains multiple logop,logrec Is a binary that is obtained by serializing the actions and parameters of a transaction buffer, This buffer Data is formatted by transaction and operation type .
WT The journal in is divided into 4 class , Namely :
- establish checkpoint Operation log of (LOGREC_CHECKPOINT)
- Normal transaction operation log (LOGREC_COMMIT)
- btree page Synchronous disk brushing operation log (LOGREC_FILE_SYNC)
- Logs provided for external use by the engine (LOGREC_MESSAGE)
Here is a brief introduction to transaction execution LOGREC_COMMIT, This kind of log is based on K/V The operation mode of the system is divided into :
- LOG_PUT( Add or modify K/V operation )
- LOG_REMOVE( single KEY Delete operation )
- Range deletion log
These operations will record the operation of key, Fill in different other parameters according to the operation mode , for example :update update operation , You need to value Fill in the . besides , Log objects also carry btree The index file of ID、 Commit transaction ID etc. , Whole logrec and logop The diagram of the relationship structure is as follows :
chart 6, Click on the image to zoom full screen
For the... In the picture above logrec header Why do two length fields appear in :logrec The length of space on the disk and in memory , because logrec Space compression is done before the disk is flushed in , The length on disk is different from that in memory . Compression is optional depending on the system configuration .
WAL Concurrent with log writing for lockless design
WT The engine is using WAL(Write-Ahead Log) Method to write to the log ,WAL Generally speaking, it means that the corresponding operation log should be written to the disk file before the transaction is submitted . In the introduction section of transaction execution, we introduce when the log is written , Here we will analyze how transaction logs are written to disk , The whole writing process is roughly divided into the following stages :
1、 When the transaction performs the first write operation , First, in the transaction object (wt_transaction) Medium redo_log_buf Create a buffer of logrec object , And will logrec The transaction type in is set to LOGREC_COMMIT.
2、 It then generates a logop object , And add it to the corresponding transaction logrec in .
3、 At transaction commit , hold logrec The corresponding content is written to a global level log Object's slot buffer And wait for the completion signal .
4、Slot buffer Will merge concurrent committed transactions based on concurrency logrec, Then the merged log contents are synchronously flushed to disk (sync file), Finally tell this slot buffer Corresponding to all transactions, the disk flushing is completed .
5、 Log completion of commit transaction , The execution result of the transaction is also persisted .
The schematic diagram of the whole process is as follows :
chart 7, Click on the image to zoom full screen
WT In order to reduce the amount of writing caused by flushing the disk IO, A lot of optimization has been done on the operation of log disk flushing , To achieve something similar to MySQL How the group submits the disk .
In this way, the transaction logs that are committed at the same time will be merged into one slot buffer in , The transaction thread that completes the merge first will synchronously wait for a signal to complete the disk flushing , Finally, the transaction thread that completes the log data merging will slot buffer All log data in sync Go to disk and notify on this slot buffer Wait for other transaction threads to finish flushing .
Concurrent transaction logrec Merge into slot buffer The process in is a completely lock free process , This reduces the need for CPU Contention and OS context switching . For this lockless design WT On the whole log Management defines a acitve_ready_slot And a slot_pool Array structure , It is roughly defined as follows :
wt_log{
. . .
active_slot: Ready and ready to merge logrec Of slot buffer object
slot_pool: All of the system slot buffer An array of objects , Include : Is merging 、 Ready to merge and idle slot buffer.
}
slot buffer Object is a dynamic binary array , It can be expanded as needed . The definition is as follows :
wt_log_slot{
. . .
state: At present slot The state of ,ready/done/written/free These States
buf: Cache merge logrec Temporary buffer for
group_size: The length of data to be submitted
slot_start_offset: Consolidated logrec Deposit in log file Offset position in
. . .
}
An example is given to illustrate the lock free process , If in the system slot_pool Medium slot The number is 16, Set up slot buffer The size is 4KB, At present log In the manager active_slot Of slot_start_offset=0, Yes 4 One transaction (T1、T2、T3、T4) Concurrent submission , Their corresponding log objects are logrec1、logrec2、logrec3 and logrec4.
Logrec1 size = 1KB, logrec2 szie = 2KB, logrec3 size = 2KB, logrec4 size = 5KB. The process of merging and writing them is as follows :
1、T1 things Be sure to submit , First, we'll start with the overall situation log Object active_slot Launch once JOIN operation ,join The process is to active_slot Apply for your own merge location and space ,logrec1_size + slot_start_offset < slot_size also slot be in ready state , that T1 The merge location of the transaction is active_slot[0, 1KB],slot_group_size = 1KB
2、 This is a T2 At the same time, the submission should be merged logrec, I'm going to repeat 1 Ministry JOIN operation , The location it applied for is active_slot [1KB, 3KB], slot_group_size = 3KB.
3、 stay T1 Business JOIN After completion , It will judge itself as the first JOIN This active_slot The business of , The judgment condition is the write position returned slot_offset=0. If it's the first one, it will immediately active_slot The state of the from ready The state is set to done state , There is no subsequent transaction from slot_pool Get a free active_slot_new Instead of merging your own data .
4、 meanwhile T2 Business JOIN When it's done , It's also a judgment of the process ,T2 Find yourself not the first , It will wait for T1 take active_slot Set as done.
5、T1 and T2 They all got themselves in active_slot Write position in ,active_slot The status of is set to done when ,T1 and T2 Separate your own logrec Write to the corresponding buffer Location . If here T1 Than T2 Write the data first ,T1 Will wait for a slot_buffer The signal to completely swipe into the disk , and T2 After the writing is completed, it will put slot_buffer Data write in log file , Also on log File do sync The operation of swiping into the disk , The highest sending signal tells T1 Synchronous disk brushing completed ,T1 and T2 Return to each other , The log disk flushing operation of the transaction commit process is completed .
So here are a few other situations , If it's in the first 2 After the completion of the step operation ,T3 It's also going on JOIN operation , This is the time slot_size(4KB) < slot_group_size(3KB)+ logrec_size(2KB),T3 No JOIN At that time active_slot, It's spinning and waiting active_slot_new displacement active_slot Later JOIN To active_slot_new.
If in the first place 2 Step by step ,T4 Also submit , because logrec4(5KB) > slot_size(4KB),T4 It's not going to happen JOIN operation , It's about putting your own logrec Data writing log file , And do sync Swipe the disk back . Before I returned, I found that there was logrec4 Log data of size cannot be merged , overall situation log The object will try to put slot buffer Double the size of , The purpose of this is to make the following transaction commit log possible slot Merge write .
WT The reason why the engine was introduced slot The reason why the logs are merged is to reduce the number of disks I/O visit , Through lock free operation , Reduce global log buffer contention .
Transaction recovery
From above about transaction logs and MVCC list Related description we know , The transaction redo log It is mainly to prevent the loss of committed transaction modifications in memory , But if all the changes are in memory , As time goes by and more data is written , There's not enough memory , At this time, you need to write the modified data in memory to the disk .
Generally in WT It's going to be the whole thing BTREE Upper page Do it once checkpoint And write to disk .WT Medium checkpoint yes append Mode management , in other words WT It will save more than one checkpoint edition . No matter what version of checkpoint The beginning can be repeated redo log To recover committed transaction modifications in memory . The whole replay process is simply to logrec The execution of each operation in .
It's worth mentioning here because WT Save multiple versions of checkpoint, Then it will checkpoint As a kind of metadata, it is written to the metadata table , Metadata tables also have their own checkpoint and redo log, But the metadata table is saved by checkpoint Is stored in the WiredTiger.wt In file , Before the system repeats the commit transaction of a normal table , The metadata transaction commit modification will be repeated first . A separate space will be used to explain btree、checkpoint The relationship and implementation of metadata table .
WT Of redo log It is turned on or off by configuration ,MongoDB Not used WT Of redo log To ensure that the transaction changes are not lost , Instead, it adopted WT Of checkpoint and MongoDB The function of replication set is combined to ensure data integrity .
The general details are if some MongoDB Instance down , After restart, pass through MongoDB The replication agreement will be up to date checkpoint The later changes are from the others MongoDB Copy the instance .
Postscript
although WT The multi operation transaction model is implemented , However MongoDB No transaction provided , This may be MongoDB Its architecture has something to do with product positioning . however MongoDB Take advantage of WT The isolation of short transactions of the implementation of document level row lock , Yes MongoDB It's a big step forward .
so to speak WT In the implementation of the transaction in a different way , The whole transaction system is implemented without complicated transaction locks , But use snapshot and MVCC These two technologies make it easy to implement transactional ACID, This implementation also greatly improves the concurrency of transaction execution .
besides ,WT In the implementation of each transaction module, lock free concurrency is used , make the best of CPU To reduce resource competition and I/O operation , so to speak WT There is a lot of innovation in the implementation . Through to WiredTiger Source code analysis and testing , And I've benefited a lot , Not only understand the latest technology of database storage engine , Also on the CPU Memory related concurrent programming has a new understanding , Many design patterns and concurrent program architectures can be directly used in real projects and products .
The follow-up work is to continue to deal with Wiredtiger Do a deeper analysis 、 Research and testing , And share the experience of these work , Let more engineers and developers understand this excellent storage engine .( Small make up : Please pay attention to the high availability architecture WiredTiger article )
Reference reading

MongoDB 2015 review : New milestone WiredTiger Storage engine
Yes WiredTiger And MongoDB New design and use of students interested in , Welcome to leave a message in this article , Introduce to WiredTiger/MongoDB The use and understanding of , We will invite those who are interested in the comments, the author of this article and relevant experts in the industry to 『 High availability Architecture —WiredTiger/MongoDB』 Wechat group for communication .
Technical originality and architecture practice article , Welcome to the official account menu 「 Contact us 」 To contribute . Please indicate from highly available Architecture 「ArchNotes」 The official account of WeChat and the following two-dimensional code .
High availability Architecture
Changing the way the Internet is built

Long press QR code Focus on 「 High availability Architecture 」 official account
版权声明
本文为[osc_usgpahnick]所创,转载请带上原文链接,感谢
边栏推荐
- Implement crud operation
- 苏宁基于知识图谱的大规模告警收敛和根因定位实践
- Oh, my God! Printing log only knows log4j?
- 用一种简单的方式实现终端文字粘贴板
- Four steps of Android integrated payment
- Online course of tutorial system processing is in progress
- IDEA rest-client,会了它我还没打开过postman
- Gather in Beijing! Openi / O 2020 Qizhi Developer Conference enters countdown
- 医疗项目管理的三种实用技巧
- List of wechat video Number broadcasters October 2020
猜你喜欢
Is multithreading really faster than single threading?
【golang】GC详解

移动安全加固助力 App 实现全面、有效的安全防护

FGC online service troubleshooting, this is enough!
Handwriting Koa.js Source code

What really drags you down is sunk costs
SQL statement to achieve the number of daffodils
What are the implementations of distributed locks?
使用TreeView树型菜单栏(递归调用数据库自动创建菜单)
Interface tests how to pass files in post requests
随机推荐
Chrome browser engine blink & V8
New features of Fedora 33 workstation
基于synchronized锁的深度解析
Android NDK development and actual combat WeChat official account 2-D code detection
真正拖垮你的,是沉没成本
Well, the four ways to query the maximum value of sliding window are good
Several methods of initializing singleton variable in go language
What really drags you down is sunk costs
“开源软件供应链点亮计划 - 暑期 2020”公布结果 基于 ChubaoFS 开发的项目获得最佳质量奖
The history of C1 research in Shenzhen
Android Development - service application, timer implementation (thread + service)
Interview summary on November 7, 2020 (interview 12K)
Implement crud operation
Fedora 33 Workstation 的新功能
Show profile analysis of SQL statement performance overhead
Adobe Experience Design /Xd 2020软件安装包(附安装教程)
The middle stage of vivo Monkey King activity
The third way to realize webrtc in embedded devices
Mobile security reinforcement helps app achieve comprehensive and effective security protection
块级元素和行内元素