当前位置:网站首页>基于synchronized锁的深度解析
基于synchronized锁的深度解析
2020-11-09 12:28:00 【AnonyStar】

1. 问题引入
小伙伴们都接触过线程,也都会使用线程,今天我们要讲的是线程安全相关的内容,在这之前我们先来看一个简单的代码案例。 代码案例:
/**
* @url: i-code.online
* @author: AnonyStar
* @time: 2020/10/14 15:39
*/
public class ThreadSafaty {
//共享变量
static int count = 0;
public static void main(String[] args) {
//创建线程
Runnable runnable = () -> {
for (int i = 0; i < 5; i++) {
count ++;
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
for (int i = 0; i < 100; i++) {
new Thread(runnable,"Thread-"+i).start();
}
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("count = "+ count);
}
}
执行结果:

问题说明
在上面的代码中我们可以看到,定义了一个线程 runnable 里面对公共成员变量进行 ++ 操作,并循环五次,每次睡眠一毫秒,之后我们在主线程 main 方法中创建一百个线程并且启动,然后主线程睡眠等待五秒以此来等所有的线程执行结束。我们预期结果应该是 500 。但是实际执行后我们发现 count 的值是不固定的 ,是小于 500 的,这里就是多线程并行导致的数据安全性问题!
通过上述案例我们可以清楚的看到线程安全的问题,那么我们想想是否有什么办法来避免这种安全问题尼 ?我们可以想到导致这种安全问题的原因是因为我们访问了共享数据,那么我们是否能将线程访问共享数据的过程变成串行的过程那么不就是不存在这个问题了。这里我们可以想到之前说的**
锁** ,我们知道锁是处理并发的一种同步方式,同时他也具备互斥性,在Java中实现加锁是通过synchronized关键字
2. 锁的基本认识
2.1 Synchronized 的认识
在Java 中我们知道有一个元老级的关键字 synchronized ,它是实现加锁的关键,但是我们一直都认为它是一个重量级锁,其实早在 jdk1.6 时就对其进行了大量的优化,让它已经变成非常灵活。也不再一直是重量级锁了,而是引入了 **偏向锁 **和 **轻量级锁。 **关于这些内容我们将详细介绍。
synchronized的基础使用
synchronized修饰实例方法,作用于当前实例加锁synchronized修饰静态方法,作用于当前类对象加锁,synchronized修饰代码块,指定加锁对象,对给定对象加锁,
在上述情况中,我们要进入被
synchronized修饰的同步代码前,必须获得相应的锁,其实这也体现出来针对不同的修饰类型,代表的是锁的控制粒度
- 我们修改一下前面我们写的案例,通过使用
synchronized关键字让其实现线程安全
//创建线程
Runnable runnable = () -> {
synchronized (ThreadSafaty.class){
for (int i = 0; i < 5; i++) {
count ++;
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
只需要添加
synchronized (ThreadSafaty.class)的修饰,将操作的内容放入代码块中,那么就会实现线程安全
- 通过上面的实践我们可以直观感受
synchronized的作用,这是我们平时开发中常规使用,大家有没有过疑问,这个锁到底是怎么存储实现的?那么下面我们将对探索其中的奥秘
Java中锁的实现
- 我们知道锁是具有互斥性(
Mutual Exclusion)的 ,那么它是在什么地方标记存在的尼? - 我们也知道多个线程都可以获取锁,那么锁必然是可以共享的
- 我们最熟悉的
synchronized它获取锁的过程到底是怎么样的呢?它的锁是如何存储的呢? - 我们可以注意观察
synchronized的语法,可以看到 **synchronized(lock)是基于lock的生命周期来实现控制锁粒度的,**这里一定要理解,我们获得锁时都时一个对象,那么锁是不是会和这个对象有关系呢? - 到这里为止,我们将所有的关键信息都指向了对象,那么我们有必要以此为切入点,来首先了解对象在
jvm中的分布形式,再来看锁是怎么被实现的。
对象的内存布局
-
这里我们只谈论对象在
Heap中的布局,而不会涉及过多的关于对象的创建过程等细节,这些内容我们再单独文章详细阐述,可以关注i-code.online博客或wx"云栖简码" -
在我们最常用的虚拟机
hotspot中对象在内存中的分布可以分为三个部分:对象头(Header)、实列数据(Instance Data)、对其填充(Padding)
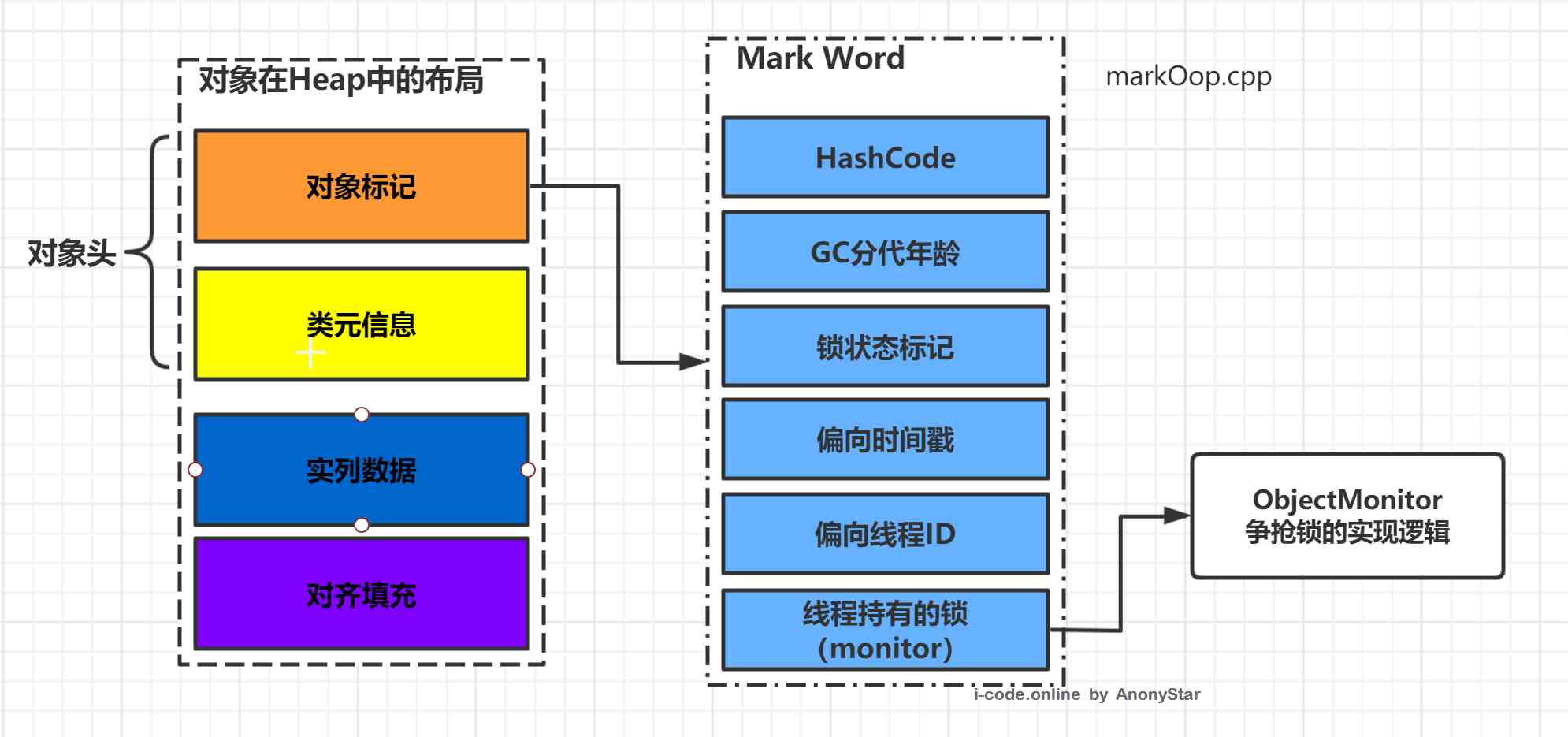
- 通过上述的图示我们可以看到,对象在内存中,包含三个部分, 其中对象头内分为 对象标记与类元信息,在对象标记中主要包含如图所示
hashcode、GC分代年龄、锁标记状态、偏向锁持有线程id、线程持有的锁(monitor)等六个内容,这部分数据的长度在 32 位和64位的虚拟机中分别为32bit 和 64bit,在官方将这部分称为Mark Word。 Mark Word实际是一中可以动态定义的数据结构,这样可以让极小的空间存储尽量多的数据,根据对象的状态复用自己的内存空间,比如在32位的虚拟机中,如果对象未被同步锁锁定的状态下,Mark Word的32个比特存储单元中,25个用于存储哈希码,4个用于存储GC分代年龄,2个存锁标记位,1个固定位0,针对各个状态下的分布可以直观的参看下面的图表
32位HotSpot虚拟机对象头Mark Word
| 锁状态 | 25bit | 4bit | 1bit(是否是偏向锁) | 2bit(锁标志位) | |
|---|---|---|---|---|---|
| 23bit | 2bit | ||||
| 无锁 | 对象的HashCode | 分代年龄 | 0 | 01 | |
| 偏向锁 | 线程ID | Epoch(偏向时间戳) | 分代年龄 | 1 | 01 |
| 轻量级锁 | 指向栈中锁记录的指针 | 00 | |||
| 重量级锁 | 指向重量级锁的指针 | 10 | |||
| GC标记 | 空 | 11 |
上述说的是32位虚拟机,需要注意。关于对象头的另一部分是类型指针,这里我们不展开再细说了,想了解的关注
i-code.online,会持续更新相关内容
- 下面内容会涉及到源码的查看,需要提前下载源码,如果你不知道如何来下载,可以参看《下载JDK 与 Hotspot 虚拟机源码》这篇文章,或者关注
云栖简码。 - 在我们熟悉的虚拟机
Hotspot中实现Mark Word的代码在markOop.cpp中,我们可以看下面片段,这是描述了虚拟机中MarkWord的存储布局:
- 当我们在
new一个对象时,虚拟机层面实际会创建一个instanceOopDesc对象,我们熟悉的Hotspot虚拟机采用了OOP-Klass模型来描述Java对象实例,其中OOP就是我们熟悉的普通对象指针,而Klass则是描述对象的具体类型,在Hotspot中分别用instanceOopDesc和arrayOopDesc来描述,其中arrayOopDesc用来描述数组类型, - 对于
instanceOopDesc的实现我们可以从Hotspot源码中找到。对应在instanceOop.hpp文件中,而相应的arrayOopDesc在arrayOop.hpp中,下面我们来看一下相关的内容:
- 我们可以看到
instanceOopDesc继承了oopDesc,而oopDesc则定义在oop.hpp中,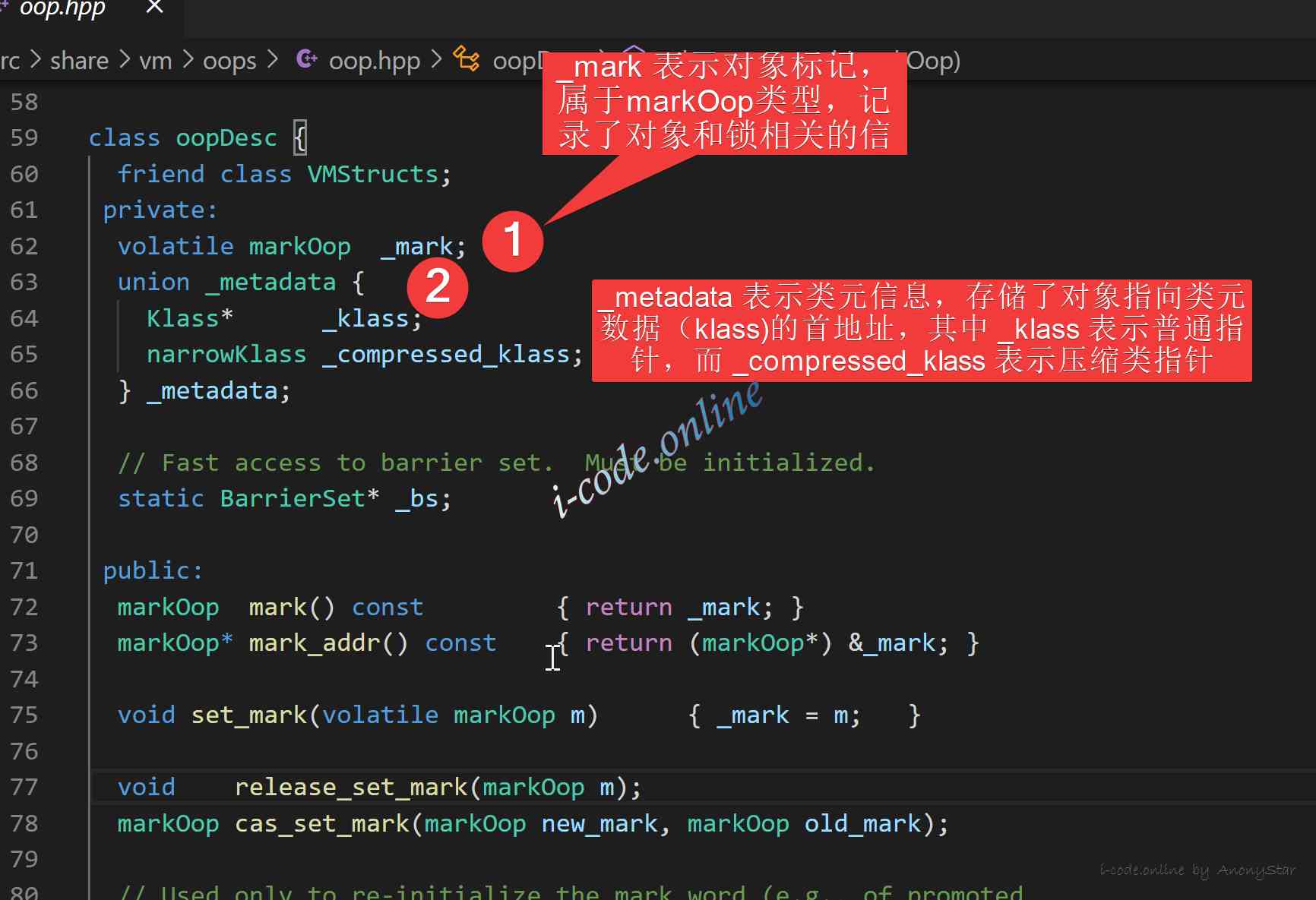
- 上述图示中我们可以看到相关信息,具体也注释了文字,那么接下来我们要探索一下
_mark的实现定义了,如下,我们看到它是markOopDesc
- 通过代码跟进我们可以在找到
markOopDesc的定义在markOop.hpp文件中,如下图所示: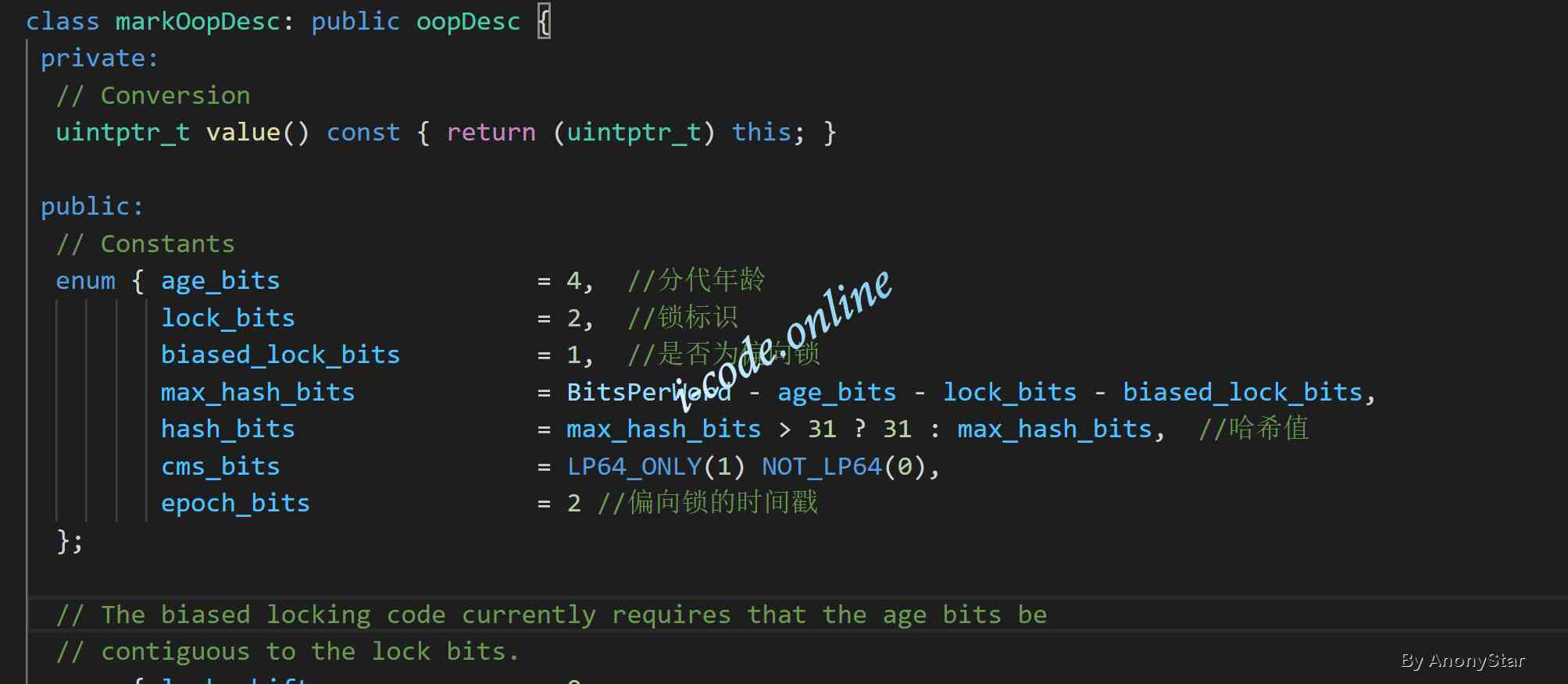
- 在上述图片中我们可以看到,内部有一个枚举。记录了
markOop中存储项,所以在我们实际开发时,当synchronized将某个对象作为锁时那么之后的一系列锁的信息都和markOop相关。如上面表格中mark word的分布记录所示具体的各个部分的含义 - 因为我们创建对象时实际在jvm层面都会生成一个
native的c++对象oop/oopdesc来映射的,而每个对象都带有一个monitor的监视器对象,可以在markOop.hpp中看到,其实在多线程中抢夺锁就是在争夺monitor来修改相应的标记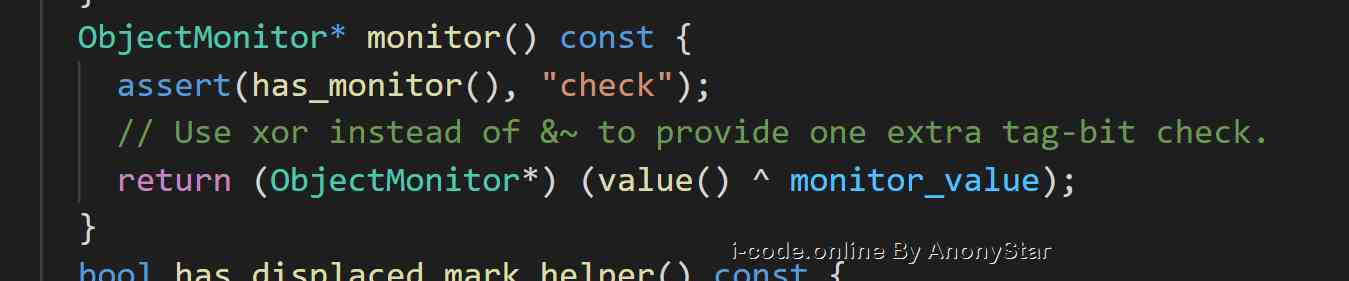
Synchronized 的深入
- 在
Java中synchronized是实现互斥同步最基本的方法,它是一个块结构(Block Structured)的同步语法,在经过javac编译后会在块的前后分别形成monitorrenter和monitorexit两个字节码指令,而它们又都需要一个reference类型的参数来指明锁对象,具体锁对象取决于synchronized修饰的内容,上面已经说过不在阐述。
《深入理解Java虚拟机》中有这样的描述: 根据《Java虚拟机规范》的要求,在执行monitorenter指令时,首先要去尝试获取对象的锁。如果 这个对象没被锁定,或者当前线程已经持有了那个对象的锁,就把锁的计数器的值增加一,而在执行 monitorexit指令时会将锁计数器的值减一。一旦计数器的值为零,锁随即就被释放了。如果获取对象 锁失败,那当前线程就应当被阻塞等待,直到请求锁定的对象被持有它的线程释放为止
- 所以被
synchronized修饰的代码块对同一个线程是可重入的,这也就避免了同线程反复进入导致死锁的可能 - 在
synchronized修饰的代码块直接结束释放锁之前,会阻塞后面的其他线程
为什么说synchronized是重量级锁
- 从执行成本来说,持有锁是一个重量级(
Heavy-Weight)的操作过程,因为在Java中线程都是映射到操作系统的原生内核线程上的,如果要阻塞和唤醒某一个线程都需要经过操作系统来调度,而这就不可避免的会进行用户态和内核态的转换,但是这种转换是非常耗费处理器时间的,尤其对于本身业务代码简单的程序,可能在这里耗费的时间比业务代码自身执行的时间还长,所以说synchronized是一个重量级的操作,不过在jdk6后对其做了大量的优化,让它不再显得那么重
锁的优化
- 在
JDK5升级到JDK6后进行一系列关于锁的改进,通过多种技术手段来优化锁,让synchronized不再像以前一样显的很重,这其中涉及到适应性自旋(Adaptive Spinning)、锁消除(Lock Elimination)、锁膨胀(Lock Coarsening)、轻量级锁(LightWeight Locking)、偏向锁(Biased Locking)等,这些都是用来优化和提高多线程访问共享数据的竞争问题。
锁消除
- 锁消除是虚拟机在即时编译器运行时对一些代码要求同步,但是被检测到不可能存在共享数据竞争的锁进行消除,其中主要的判定依据是基于逃逸分析技术来实现的,关于这块内容不在这里展开,后续相关文章介绍。这里我们简单理解就是,如果一段代码中,在堆上的数据都不会逃逸出去被其他线程访问到,那么就可以把它们当作栈上的数据来对来,认为它们都是线程私有的,从而也就不需要同步加锁了,
- 关于代码中变量是否逃逸,对虚拟机来说需要通过复杂分析才能得到,但是对我们开发人员来说还是相对直观的,那可能有人会疑惑既然开发人员能清楚还为什么要多余的加锁同步呢?,其实实际上,程序上非常多的同步措施并不是我们开发人员自己加入的,而是
java内部就有大量的存在,比如下面这个典型的例子,下面展示的是字符串的相加
private String concatString(String s1,String s2,String s3){
return s1 + s2 + s3;
}
- 我们知道
String类是被final修饰的不可变类,所以对于字符串的相加都是通过生成新的String对象来试试先的,因此编译器会对这种操作做优化处理,在JDK5之前会转换为StringBuffer对象的append()操作,而在JDK5及其之后则转换为StringBuilder对象来操作。所以上述代码在jdk5可能会变成如下:
private String concatString(String s1,String s2,String s3){
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}
- 这时候,就可以看到,对于
StringBuffer。append()方法是一个同步方法,带有同步快,锁对象就是sb,这时候虚拟机通过分析发现sb的作用域被限制在方法内部,而不可能逃逸出方法外让其他线程访问到,所以这是在经过服务端编译器的即时编译后,这段代码的所有同步措施都会失效而直接执行。
上述代码是为了方便演示而选择了String,实际来说在jdk5之后都是转换为Stringbuilder ,也就不存在这个问题了,但是在jdk中类似这种还是非常多的。
锁粗化
- 关于锁的粗话其实也是很简单的理解,我们在开发时总是推荐同步代码块要作用范围尽量小,尽量只在共享数据的实际作用域中才进行同步,这样的目的是为了尽可能减少同步的操作,让其他线程能更快的拿到锁
- 这是多大多数情况,但是总有一些特殊情况,比如在某个系列连续操作的都是对同一个对象反复的加锁和解锁,那么这会导致不必要的性能损耗
- 也如同上面
String的案例,在连续的append操作都是零碎的同步块,而且都是同一个锁对象,这时候会将锁的范围扩展,到整个操作序列外部,也就是第一个append之前到最后一个append操作之后,将这些全部放入一个同步锁中就可以了,这样就避免了多次的锁获取和释放。
自旋锁
- 通过之前的了解,我们知道挂起线程和恢复线程都是会涉及到用户态和内核态的转换,而这些都是非常耗时的,这会直接影响虚拟机的并发性能。
- 在我们平时开发中,如果共享数据的锁定状态只会持续很短的时间,那么为了这很短的时间而去挂起阻塞线程是非常浪费资源的。尤其现在的电脑都基本是多核处理器,所以在这种前提下,我们是是否可以让另一个请求锁对象的线程不去挂起,而是稍微等一下,这个等待并不会放弃
CPU的执行时间。等待观察持有锁的线程是否能很快的释放锁,其实这个等待就好比是一个空的循环,这种技术就是一个所谓的自旋锁 - 自旋锁在
JDK6中及已经是默认开启的了,在jdk4时就引入了。自旋锁并不是阻塞也代替不了阻塞。 - 自旋锁对处理器数量有一定的要求,同时它是会占用
CPU时间的,虽然它避免了线程切换的开销,但是这之间时存在平衡关系的,假如锁被占用的时间很短那么自旋就非常有价值,会节省大量的时间开销,但是相反,如果锁占用的时间很长,那么自旋的线程就会白白消耗处理器资源,造成性能的浪费。 - 所以自旋锁必须有一个限度,也就是它自旋的次数,规定一个自旋次数,如果超过这个次数则不再自旋转而用传统方式挂起线程,
- 自旋的次数默认时十次。但是我们也可以通过
-XX: PreBlockSpin参数来自定义设置
自适应自旋锁
- 在前面我们知道可以自定义自旋次数,但是这个很难有个合理的值,毕竟在程序中怎么样的情况都有,我们不可能通过全局设置一个。所以在
JDK6之后引入了自适应自旋锁,也就是对原有的自旋锁进行了优化 - 自适应自旋的时间不再是固定的,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态决定的,如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且支持有锁的线程正在运行中,那么虚拟机就会任务这次自旋也极有再次获得锁,那么就会允许自旋的持续时间更长
- 相应的 ,如果对于某个锁,自旋获得锁的次数非常少,那么在之后要获取锁的时候将直接忽略掉自旋的过程进而直接阻塞线程避免浪费处理器资源
轻量级锁
- 轻量级锁也是
JDK6时加入的新的锁机制,它的轻量级是相对于通过操作系统互斥量来实现的传统锁而言的,轻量级锁也是一种优化,而不是能替代重量级锁,轻量级锁的涉及初衷就是在没有多线程竞争下减少传统重量级锁使用操作系统互斥量产生的性能消耗。 - 要想了解轻量级锁我们必须对对象在
Heap中的分布了解,也就是上面说到的内容。
轻量级锁加锁
- 当代码执行到同步代码块时,如果同步对象没有被锁定也就是锁标志位为
01状态,那么虚拟机首先将在当前线程的栈帧中建立一个名为锁记录Lock Record的空间 - 这块锁记录空间用来存储锁对象目前的
Mark Word的拷贝,官方给其加了个Displaced的前缀,即Displaced Mark Word,如下图所示,这是在CAS操作之前堆栈与对象的状态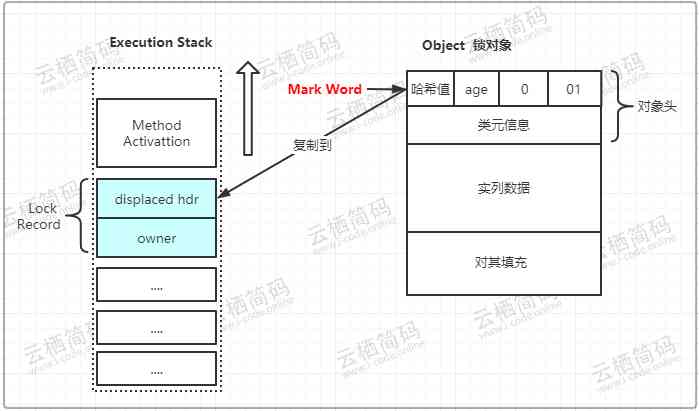
- 当复制结束后虚拟机会通过
CAS操作尝试把对象的Mark Word更新为指向Lock Record的指针,如果更新成功则代表该线程拥有了这个对象的锁,并且将Mark Word的锁标志位(最后两个比特)转变为 “00”,此时表示对象处于轻量级锁定状态,此时的堆栈与对象头的状态如下: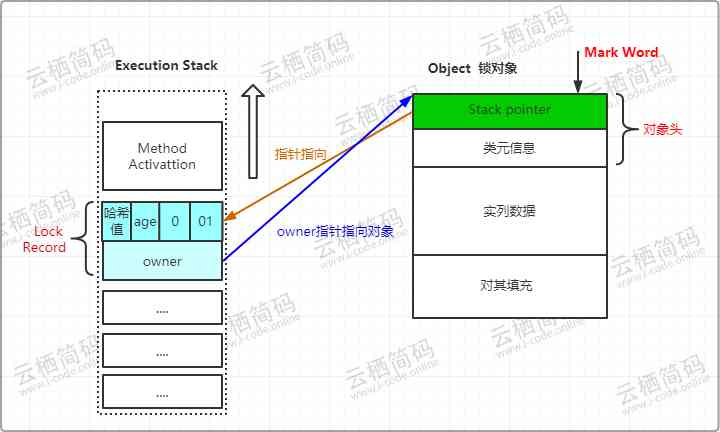
- 如果上述操作失败了,那说明至少存在一条线程与当前线程竞争获取该对象的锁,虚拟机会首先检查对象的
Mark Word是否指向当前线程的栈帧,如果是,则说明当前线程已经拥有了这个对象的锁,那么直接进入同步代码块执行即可。否则则说明这个对象已经被其他线程抢占了。 - 如果有超过两条以上的线程争夺同一个锁的情况,那么轻量级锁就不再有效,必须膨胀为重量级锁,锁的标记位也变为“10”,此时
Mark Word中存储的就是指向重量级锁的指针,等待的线程也必须进入阻塞状态
轻量级锁的解锁
- 轻量级锁的解锁同样是通过
CAS操作来进行的 - 如果对象的
Mark Word仍然指向线程的锁记录,那么就用CAS操作把对象当前的Mark Word和线程中复制的Displaced Mark Word替换回来 - 如果替换成功则整个同步过程结束,若失败则说明有其他线程正在尝试获取该锁,那就要在释放锁的同时,唤醒被挂起的线程
轻量级锁适用的场景是对于绝大部分锁在整个同步周期内都是不存在竞争的,因为如果没有竞争,轻量级锁便可以通过
CAS操作成功避免了使用互斥量的开销,但是如果确实存在锁竞争,那么除了互斥量本身的开销外还得额外发生了CAS操作的开销,这种情况下反而比重量级锁更慢
- 下面通过完整的流程图来直观看一下轻量级锁的加锁解锁及膨胀过程
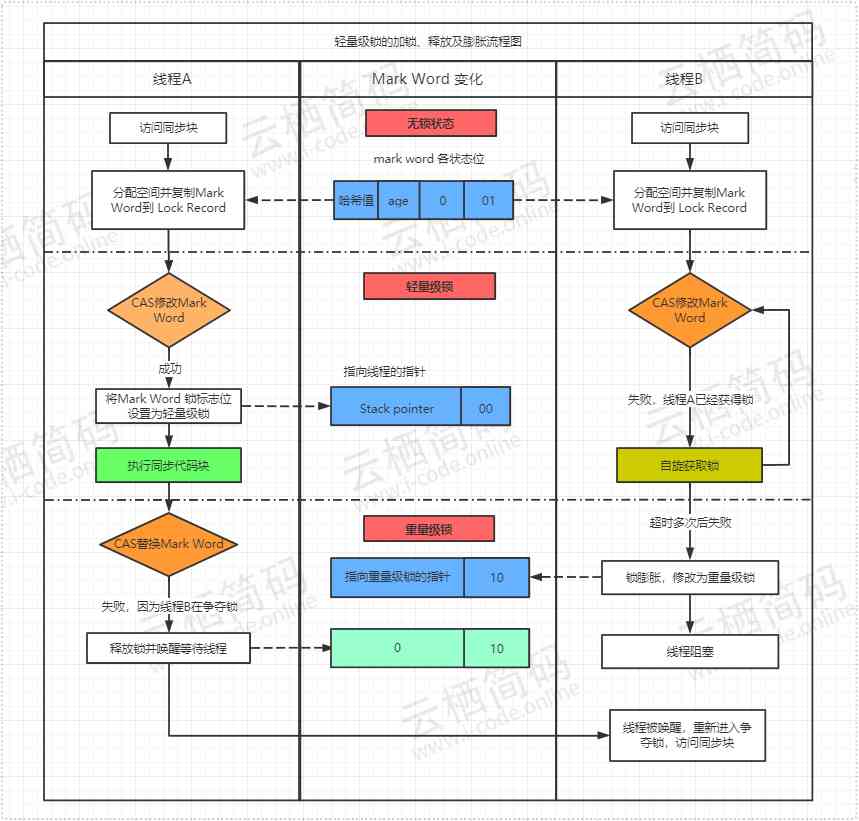
偏向锁
- 偏向锁也是
JDK6引入的一种锁优化技术,如果说轻量级锁是在无竞争情况下通过CAS操作消除了同步使用的互斥量,那么偏向锁则是再无竞争情况下把整个同步都给消除掉了,连CAS操作都不再去做了,可以看出这比轻量级锁更加轻 - 从对象头的分布上看,偏向锁中是没有哈希值的而是多了线程ID与
Epoch两个内容 - 偏向锁的意思就是锁会偏向第一个获得它的线程,如果接下来的执行过程中该锁一直没有被其他线程获取,那么只有偏向锁的线程将永远不需要再进行同步
偏向锁的获取和撤销
- 当代码执行到同步代码块时,在第一次被线程执行到时,锁对象是第一次被线程获取,此时虚拟机会将对象头中的锁标志改为“01”,同时把偏向锁标志位改为“1”,表示当前锁对象进入偏向锁模式。
- 接下来线程通过
CAS操作来将这个帧的线程ID记录到对象头中,如果CAS成功了。则持有锁对象的线程再之后进入同步代码不再进行任何同步操作(如获取锁解锁等操作)。每次都会通过判断当前线程与锁对象中记录的线程id是否一致。 - 如果 上述的
CAS操作失败了,那说明肯定存在另外一个线程在获取这个锁,并且获取成功了。这种情况下说明存在锁竞争,则偏向模式马上结束,偏向锁的撤销,需要等待全局安全点(在这个时间点上没有正在执行的字节码)。它会首先暂停拥有偏向锁的线程,会根据锁对象是否处于锁定状态来决定是否撤销偏向也就是将偏向锁标志位改为“0”,如果撤销则会变为未锁定(“01”)或者轻量级锁(“00”) - 如果锁对象未锁定,则撤销偏向锁(设置偏向锁标志位为“0”),此时锁处于未锁定不可以偏向状态,因为具有哈希值,进而变为轻量级锁
- 如果锁对象还在锁定状态则直接进入轻量级锁状态
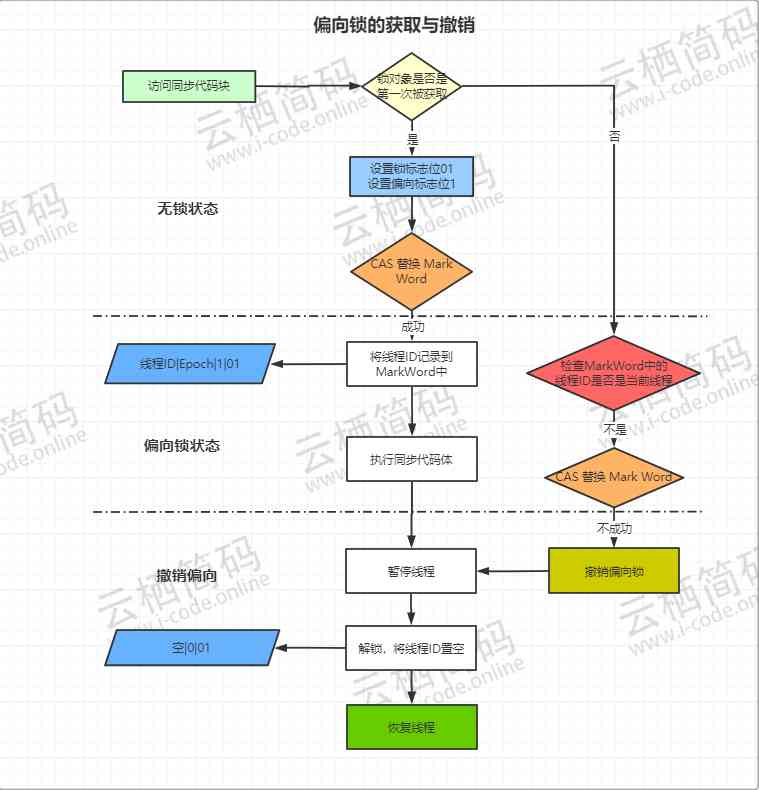
偏向锁的开关
- 偏向锁在
JDK6及其之后是默认启用的。由于偏向锁适用于无锁竞争的场景,如果我们应用程序里所有的锁通常情况下处于竞争状态,可以通过JVM参数关闭偏向锁:-XX:-UseBiasedLocking=false,那么程序默认会进入轻量级锁状态。 - 如果要开启偏向锁可以用:
-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
重量级锁
- 重量级锁也就是上述几种优化都无效后,膨胀为重量级锁,通过互斥量来实现,我们先来看下面的代码
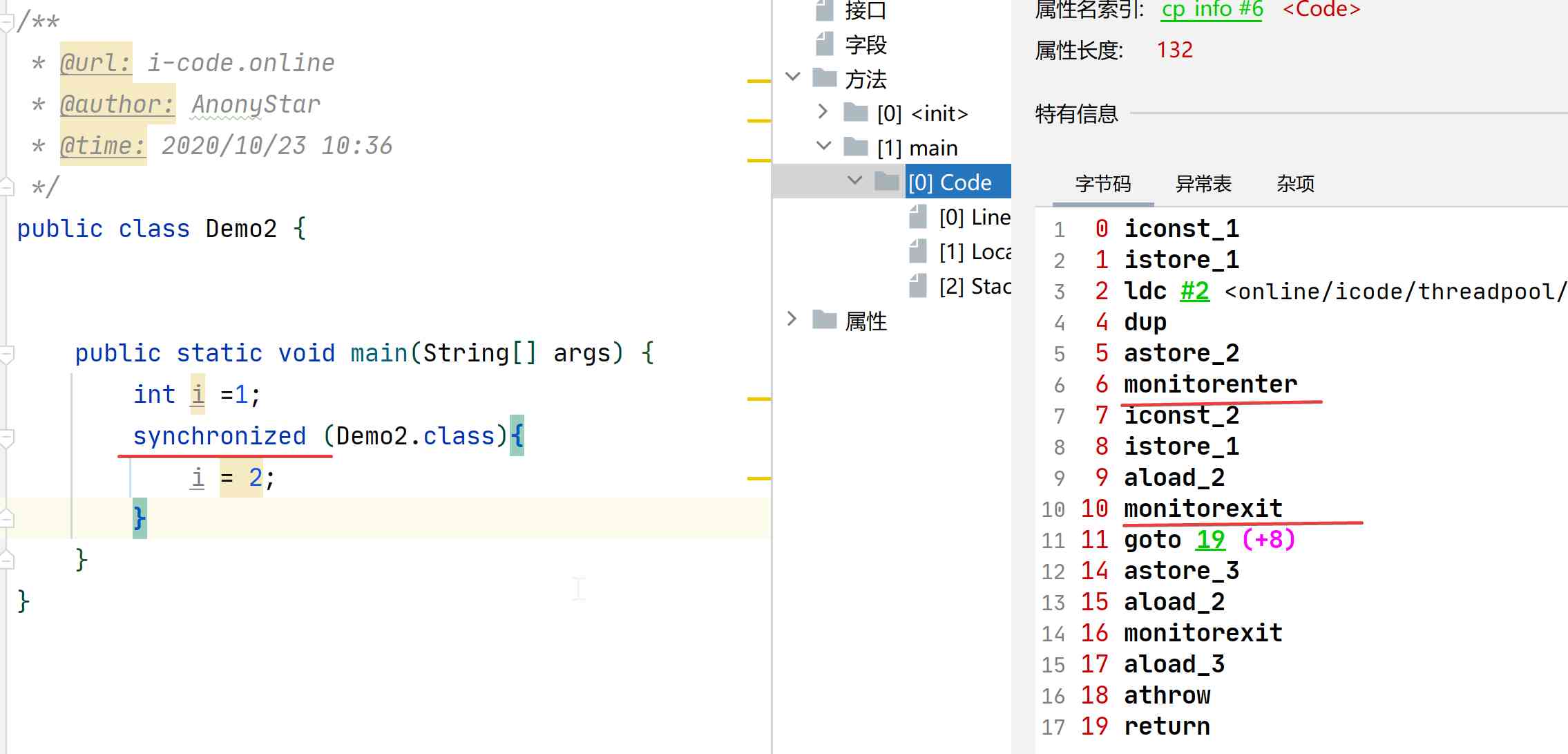
- 上面代码是一个简单使用了
synchronized的代码,我们通过字节码工具可以看到右侧窗口。我们发现,在同步代码块的前后分别形成了monitorenter和monitorexit两条指令 - 在Java对现中都会有一个
monitor的监视器,这里的monitorenter指令就是去获取一个对象的监视器。而相应的monitorexit则表示释放监视器monitor的所有权,允许被其他线程来获取 monitor是依赖于系统的MutexLock(互斥锁) 来实现的,当线程阻塞后进入内核态事,就会造成系统在用户态和内核态之间的切换,进而影响性能
总结
- 上面是阐述了关于
synchronized锁的一些优化与转换,在我们开启偏向锁和自旋时,锁的转变是 无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁, - 自旋锁实际是一种锁的竞争机制,而不是一种状态。在偏向锁和轻量级锁中都使用到了自旋
- 偏向锁适用于无锁竞争的场景,轻量级锁适合无多个线程竞争的场景
- 偏向锁和轻量级锁都依赖与
CAS操作,但是偏向锁中只有在第一次时才会CAS操作 - 当一个对象已经被计算过一致性哈希值时,那么这个对象就再也不无法进入到偏向锁状态了,如果对象正处于偏向锁状态,而接收到计算哈希值的请求,那么他的偏向锁状态会被立即撤销,并且会膨胀为重量级锁。这要是为什么偏向锁状态时
MarkWord中没有哈希值
本文由 AnonyStar 发布,可转载但需声明原文出处。 欢迎关注微信公账号 :云栖简码 获取更多优质文章 更多文章关注笔者博客 :云栖简码 i-code.online
版权声明
本文为[AnonyStar]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/3767760/blog/4708593
边栏推荐
- 注意.NET Core进行请求转发问题
- 深圳C1考证历程
- “开源软件供应链点亮计划 - 暑期 2020”公布结果 基于 ChubaoFS 开发的项目获得最佳质量奖
- 10款必装软件,让Windows使用效率飞起!
- 解决IDEA快捷键 Alt+Insert 失效的问题
- 分库分表的 9种分布式主键ID 生成方案,挺全乎的
- 嗯,查询滑动窗口最大值的这4种方法不错....
- Pay attention to the request forwarding problem of. Net core
- Solve the problem of idea shortcut key Alt + insert invalid
- Understanding runloop in OC
猜你喜欢
Dynamo: a typical distributed system analysis

为wget命令设置代理
El table dynamic header
Mac terminal oh my Zsh + solarized configuration

Nine kinds of distributed primary key ID generation schemes of sub database and sub table are quite comprehensive
Android rights
AI fresh student's annual salary has increased to 400000, you can still make a career change now!

The choice of domain name of foreign trade self built website

导师制Processing网课 双十一优惠进行中
Method of creating flat panel simulator by Android studio
随机推荐
Download Netease cloud music 10W + music library with Python
Visit Jingdong | members of Youth Innovation Alliance of China Academy of space technology visit Jingdong headquarters
Looking for better dynamic getter and setter solutions
How to ensure that messages are not consumed repeatedly? (how to ensure the idempotent of message consumption)
嗯,查询滑动窗口最大值的这4种方法不错....
如何保证消息不被重复消费?(如何保证消息消费的幂等性)
在嵌入式设备中实现webrtc的第三种方式③
jsliang 求职系列 - 08 - 手写 Promise
050_ object-oriented
A simple way to realize terminal text paste board
共创爆款休闲游戏 “2020 Ohayoo游戏开发者沙龙”北京站报名开启
阿里、腾讯、百度、网易、美团Android面试经验分享,拿到了百度、腾讯offer
Oh, my God! Printing log only knows log4j?
Stack & queue (go) of data structure and algorithm series
为wget命令设置代理
nodejs学习笔记(慕课网nodejs从零开发web Server博客项目)
在企业的降本增效诉求下,Cube如何助力科盾业务容器化“一步到位”?
Android权限大全
一个简单的能力,决定你是否会学习!
Is SEO right or wrong?