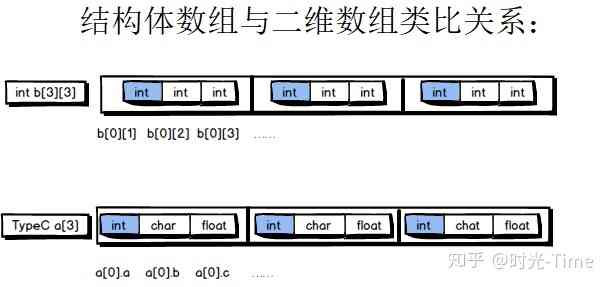
Golang from 1.5 And it started to introduce three colors GC, After many improvements , Current 1.9 Version of GC The pause time can already be very short .
The reduction in pause time means " Maximum response time " The shortening of , It also makes go It is more suitable for writing network service program .
This article will analyze golang The source code to explain go Three colors in GC Implementation principle of .
This series analyzes golang The source code is Google Officially realized 1.9.2 edition , Not applicable to other versions and gccgo And so on ,
The operating environment is Ubuntu 16.04 LTS 64bit.
First, I will explain the basic concepts , Then explain the distributor , Let's talk about the implementation of the collector .
Basic concepts
Memory structure
go A block of virtual memory will be allocated when the program starts. The address is continuous memory , The structure is as follows :

This memory is divided into 3 Regions , stay X64 The upper sizes are 512M, 16G and 512G, Their functions are as follows :
arena
arena Area is what we usually call heap, go from heap The allocated memory is in this area .
bitmap
bitmap Areas are used to indicate arena Which address in the region holds the object , And which addresses in the object contain The pointer .
bitmap One of the areas byte(8 bit) Corresponding arena Four pointer size memory in the region , That is to say 2 bit Memory corresponding to a pointer size .
therefore bitmap The size of the area is 512GB / Pointer size (8 byte) / 4 = 16GB.
bitmap One of the areas byte Corresponding arena The four pointer size memory structure of the region is as follows ,
Each pointer size of memory will have two bit Indicates whether the scan should continue and whether the pointer should be included :
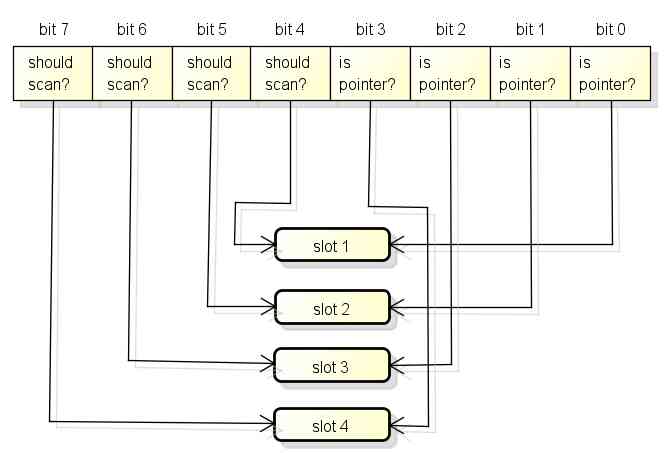
bitmap Medium byte and arena From the end of , That is, as memory allocation expands to both sides :

spans
spans Areas are used to indicate arena A page in the section (Page) Which is it? span, What is? span It will be introduced below .
spans A pointer in the region (8 byte) Corresponding arena A page in the area ( stay go Middle page =8KB).
therefore spans Its size is 512GB / Page size (8KB) * Pointer size (8 byte) = 512MB.
spans A pointer to a region corresponds to arena The structure of the page of the area is as follows , and bitmap The difference is that correspondence starts at the beginning :

When from Heap Assigned to
A lot of explanation go It has been mentioned in both articles and books , go Automatically determines which objects should be placed on the stack , Which objects should be placed on the heap .
In a nutshell , When the contents of an object may be accessed after the end of the function that generated the object , Then the object will be allocated on the heap .
Allocation of objects on the heap includes :
- Returns a pointer to the object
- Pass the pointer of the object to other functions
- Objects are used in closures and need to be modified
- Use new
stay C It's very dangerous for functions to return pointers to objects on the stack , But in go But it's safe , Because this object is automatically allocated on the heap .
go The process of deciding whether to use the heap to allocate objects is also called " Escape analysis ".
GC Bitmap
GC When marking, you need to know where to include the pointer , For example, the above mentioned bitmap The area covers arena Pointer information in the region .
besides , GC You also need to know where in the stack space there are pointers ,
Because stack space doesn't belong to arena Area , Stack space pointer information will be in The function of information Inside .
in addition , GC When assigning an object, you also need to set it according to the type of the object bitmap Area , The source pointer information will be in Type information Inside .
Sum up go There are the following GC Bitmap:
- bitmap Area : covers arena Area , Use 2 bit Represents a pointer size memory
- The function of information : Covering the stack space of the function , Use 1 bit Represents a pointer size memory ( be located stackmap.bytedata)
- Type information : When assigning objects, it will be copied to bitmap Area , Use 1 bit Represents a pointer size memory ( be located _type.gcdata)
Span
span Is the block used to allocate objects , Here is a simple illustration of Span The internal structure of :

Usually a span Contains multiple elements of the same size , An element holds an object , Unless :
- span Used to save large objects , This situation span There's only one element
- span Object used to hold tiny objects without pointers (tiny object), This situation span You can save multiple objects with one element
span There is one of them. freeindex Mark the address where the next assignment should start , After the distribution freeindex Will increase ,
stay freeindex All previous elements are assigned , stay freeindex The following elements may have been assigned , It may not be allocated .
span Every time GC Some elements may be recycled in the future , allocBits Used to mark which elements are assigned , Which elements are unallocated .
Use freeindex + allocBits You can skip assigned elements when allocating , Set the object in an unassigned element ,
But because every time I visit allocBits Efficiency will be slower , span There is an integer type in allocCache Used to cache freeindex At the beginning bitmap, The cache bit The value is opposite to the original value .
gcmarkBits Used in gc Mark which objects are alive when , Every time gc in the future gcmarkBits Will turn into allocBits.
It should be noted that span The memory of the structure itself is allocated from the system , As mentioned above spans Areas and bitmap The region is just an index .
Span The type of
span It can be divided into 67 A type of , as follows :
// class bytes/obj bytes/span objects tail waste max waste
// 1 8 8192 1024 0 87.50%
// 2 16 8192 512 0 43.75%
// 3 32 8192 256 0 46.88%
// 4 48 8192 170 32 31.52%
// 5 64 8192 128 0 23.44%
// 6 80 8192 102 32 19.07%
// 7 96 8192 85 32 15.95%
// 8 112 8192 73 16 13.56%
// 9 128 8192 64 0 11.72%
// 10 144 8192 56 128 11.82%
// 11 160 8192 51 32 9.73%
// 12 176 8192 46 96 9.59%
// 13 192 8192 42 128 9.25%
// 14 208 8192 39 80 8.12%
// 15 224 8192 36 128 8.15%
// 16 240 8192 34 32 6.62%
// 17 256 8192 32 0 5.86%
// 18 288 8192 28 128 12.16%
// 19 320 8192 25 192 11.80%
// 20 352 8192 23 96 9.88%
// 21 384 8192 21 128 9.51%
// 22 416 8192 19 288 10.71%
// 23 448 8192 18 128 8.37%
// 24 480 8192 17 32 6.82%
// 25 512 8192 16 0 6.05%
// 26 576 8192 14 128 12.33%
// 27 640 8192 12 512 15.48%
// 28 704 8192 11 448 13.93%
// 29 768 8192 10 512 13.94%
// 30 896 8192 9 128 15.52%
// 31 1024 8192 8 0 12.40%
// 32 1152 8192 7 128 12.41%
// 33 1280 8192 6 512 15.55%
// 34 1408 16384 11 896 14.00%
// 35 1536 8192 5 512 14.00%
// 36 1792 16384 9 256 15.57%
// 37 2048 8192 4 0 12.45%
// 38 2304 16384 7 256 12.46%
// 39 2688 8192 3 128 15.59%
// 40 3072 24576 8 0 12.47%
// 41 3200 16384 5 384 6.22%
// 42 3456 24576 7 384 8.83%
// 43 4096 8192 2 0 15.60%
// 44 4864 24576 5 256 16.65%
// 45 5376 16384 3 256 10.92%
// 46 6144 24576 4 0 12.48%
// 47 6528 32768 5 128 6.23%
// 48 6784 40960 6 256 4.36%
// 49 6912 49152 7 768 3.37%
// 50 8192 8192 1 0 15.61%
// 51 9472 57344 6 512 14.28%
// 52 9728 49152 5 512 3.64%
// 53 10240 40960 4 0 4.99%
// 54 10880 32768 3 128 6.24%
// 55 12288 24576 2 0 11.45%
// 56 13568 40960 3 256 9.99%
// 57 14336 57344 4 0 5.35%
// 58 16384 16384 1 0 12.49%
// 59 18432 73728 4 0 11.11%
// 60 19072 57344 3 128 3.57%
// 61 20480 40960 2 0 6.87%
// 62 21760 65536 3 256 6.25%
// 63 24576 24576 1 0 11.45%
// 64 27264 81920 3 128 10.00%
// 65 28672 57344 2 0 4.91%
// 66 32768 32768 1 0 12.50%
By type (class) by 1 Of span For example ,
span The size of the elements in is 8 byte, span It's up to you 1 Page means 8K, You can save 1024 Objects .
When assigning objects , Depending on the size of the object, what type of span,
for example 16 byte Objects that use span 2, 17 byte Objects that use span 3, 32 byte Objects that use span 3.
You can also see from this example that , Distribute 17 and 32 byte Objects of span 3, In other words, part of the size of the object in the allocation will waste a certain amount of space .
Some people may notice that , The biggest one up there span The size of the element is 32K, So the distribution exceeds 32K Where are the objects assigned to ?
exceed 32K The object of is called " Big object ", When assigning large objects , Directly from heap Assign a special span,
This special span The type of (class) yes 0, It contains only one big object , span The size of the object is determined by the size of the object .
special span Plus 66 A standard span, It's made up of 67 individual span type .
Span The location of
stay The previous I mentioned in P It's a virtual resource , Only one thread can access the same P, therefore P Data in does not need locks .
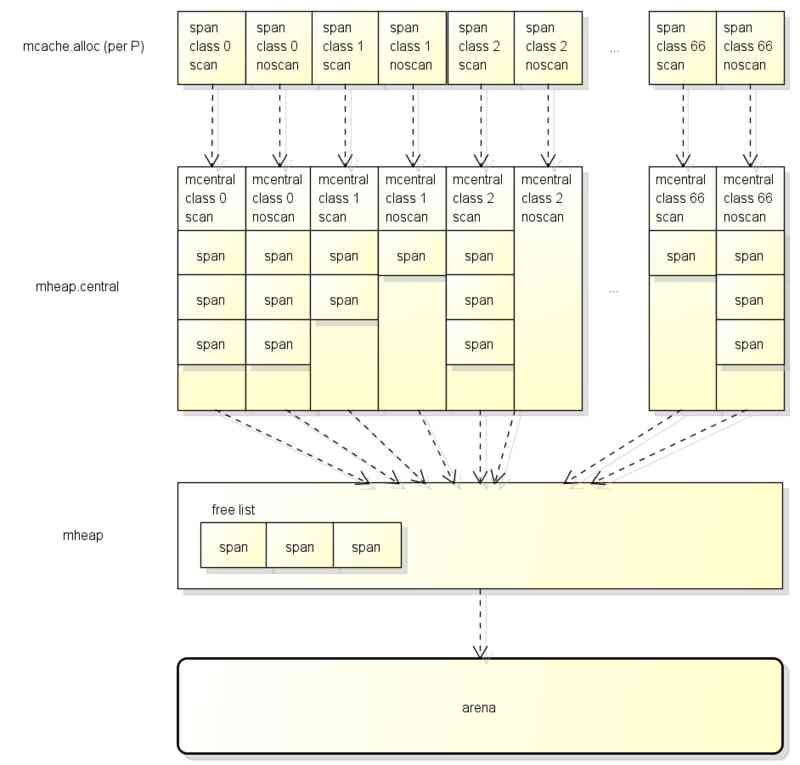
For better performance when allocating objects , each P There are span The cache of ( Also called mcache), The structure of the cache is as follows :

each P Press span Different types , Yes 67*2=134 individual span The cache of ,
among scan and noscan The difference is that ,
If the object contains a pointer , When assigning objects, you use scan Of span,
If the object does not contain a pointer , When assigning objects, you use noscan Of span.
hold span It is divided into scan and noscan The meaning of is ,
GC When you scan the object, you have to noscan Of span You don't have to check bitmap Area to mark sub objects , This can greatly improve the efficiency of tagging .
When assigning objects, the appropriate ones will be obtained from the following locations span Used to allocate :
- First of all, from the P The cache of (mcache) obtain , If there's a cache span And not full, use , There is no need to lock this step
- Then cache from the global (mcentral) obtain , If successful, set to P, This step requires a lock
- Finally from the mheap obtain , Set to global cache after getting , This step requires a lock
stay P Medium cache span It's like CoreCLR Thread cache allocation context in (Allocation Context) It's similar to ,
You can allocate objects without thread locks most of the time , Improve the performance of the distribution .
Processing of allocation objects
The process of assigning objects
go When an object is allocated from the heap newobject function , The flow of this function is as follows :

First of all, I will check GC Whether at work , If GC At work and currently G If a certain amount of memory is allocated, assistance is needed GC Do a certain job ,
This mechanism is called GC Assist, Used to prevent too fast allocation of memory GC Recycling doesn't keep up .
After that, we will judge whether it is a small object or a large object , If it is a large object, call largeAlloc Distribute from the heap ,
If it's a small object, divide 3 Get the available span, And then from span Objects assigned in :
- First of all, from the P The cache of (mcache) obtain
- Then cache from the global (mcentral) obtain , There are available in the global cache span A list of
- Finally from the mheap obtain , mheap There are also span Free list of , If both of them fail, they will get from arena Regional distribution
The detailed structure of these three stages is shown in the figure below :
Definition of data type
The data types involved in the allocation object include :
p: The previous article mentioned , P Is used to run in the coroutine go Virtual resources of code
m: The previous article mentioned , M Currently represents system threads
g: The previous article mentioned , G Namely goroutine
mspan: Blocks used to allocate objects
mcentral: Overall mspan cache , Altogether 67*2=134 individual
mheap: Used to manage heap The object of , There is only one global
Source code analysis
go When an object is allocated from the heap newobject function , Let's start with this function :
// implementation of new builtin
// compiler (both frontend and SSA backend) knows the signature
// of this function
func newobject(typ *_type) unsafe.Pointer {
return mallocgc(typ.size, typ, true)
}
newobject Called mallocgc function :
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
if gcphase == _GCmarktermination {
throw("mallocgc called with gcphase == _GCmarktermination")
}
if size == 0 {
return unsafe.Pointer(&zerobase)
}
if debug.sbrk != 0 {
align := uintptr(16)
if typ != nil {
align = uintptr(typ.align)
}
return persistentalloc(size, align, &memstats.other_sys)
}
// Judge whether to assist GC Work
// gcBlackenEnabled stay GC The marking phase of will open
// assistG is the G to charge for this allocation, or nil if
// GC is not currently active.
var assistG *g
if gcBlackenEnabled != 0 {
// Charge the current user G for this allocation.
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// Charge the allocation against the G. We'll account
// for internal fragmentation at the end of mallocgc.
assistG.gcAssistBytes -= int64(size)
// Will judge the need of assistance according to the size of the allocation GC How much work has been done
// The specific algorithm will be explained when the collector is explained below
if assistG.gcAssistBytes < 0 {
// This G is in debt. Assist the GC to correct
// this before allocating. This must happen
// before disabling preemption.
gcAssistAlloc(assistG)
}
}
// Add the current G Corresponding M Of lock Count , To prevent this G Be seized
// Set mp.mallocing to keep from being preempted by GC.
mp := acquirem()
if mp.mallocing != 0 {
throw("malloc deadlock")
}
if mp.gsignal == getg() {
throw("malloc during signal")
}
mp.mallocing = 1
shouldhelpgc := false
dataSize := size
// Get current G Corresponding M Corresponding P The local span cache (mcache)
// because M In a P I'll put P Of mcache Set to M in , What's back here is getg().m.mcache
c := gomcache()
var x unsafe.Pointer
noscan := typ == nil || typ.kind&kindNoPointers != 0
// Judge whether it is a small object , maxSmallSize The current value is 32K
if size <= maxSmallSize {
// If the object does not contain a pointer , And the size of the object is less than 16 bytes, Special treatment can be done
// Here's the optimization for very small objects , because span The smallest element of can only be 8 byte, If the object is smaller, a lot of space is wasted
// Very small objects can be integrated into "class 2 noscan" The elements of ( The size is 16 byte) in
if noscan && size < maxTinySize {
// Tiny allocator.
//
// Tiny allocator combines several tiny allocation requests
// into a single memory block. The resulting memory block
// is freed when all subobjects are unreachable. The subobjects
// must be noscan (don't have pointers), this ensures that
// the amount of potentially wasted memory is bounded.
//
// Size of the memory block used for combining (maxTinySize) is tunable.
// Current setting is 16 bytes, which relates to 2x worst case memory
// wastage (when all but one subobjects are unreachable).
// 8 bytes would result in no wastage at all, but provides less
// opportunities for combining.
// 32 bytes provides more opportunities for combining,
// but can lead to 4x worst case wastage.
// The best case winning is 8x regardless of block size.
//
// Objects obtained from tiny allocator must not be freed explicitly.
// So when an object will be freed explicitly, we ensure that
// its size >= maxTinySize.
//
// SetFinalizer has a special case for objects potentially coming
// from tiny allocator, it such case it allows to set finalizers
// for an inner byte of a memory block.
//
// The main targets of tiny allocator are small strings and
// standalone escaping variables. On a json benchmark
// the allocator reduces number of allocations by ~12% and
// reduces heap size by ~20%.
off := c.tinyoffset
// Align tiny pointer for required (conservative) alignment.
if size&7 == 0 {
off = round(off, 8)
} else if size&3 == 0 {
off = round(off, 4)
} else if size&1 == 0 {
off = round(off, 2)
}
if off+size <= maxTinySize && c.tiny != 0 {
// The object fits into existing tiny block.
x = unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
c.local_tinyallocs++
mp.mallocing = 0
releasem(mp)
return x
}
// Allocate a new maxTinySize block.
span := c.alloc[tinySpanClass]
v := nextFreeFast(span)
if v == 0 {
v, _, shouldhelpgc = c.nextFree(tinySpanClass)
}
x = unsafe.Pointer(v)
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
// See if we need to replace the existing tiny block with the new one
// based on amount of remaining free space.
if size < c.tinyoffset || c.tiny == 0 {
c.tiny = uintptr(x)
c.tinyoffset = size
}
size = maxTinySize
} else {
// Otherwise, it is assigned to ordinary small objects
// First get the size of the object, which should be used span type
var sizeclass uint8
if size <= smallSizeMax-8 {
sizeclass = size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]
} else {
sizeclass = size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]
}
size = uintptr(class_to_size[sizeclass])
// be equal to sizeclass * 2 + (noscan ? 1 : 0)
spc := makeSpanClass(sizeclass, noscan)
span := c.alloc[spc]
// Try to quickly get from this span The distribution of
v := nextFreeFast(span)
if v == 0 {
// Allocation failed , May need to be from mcentral perhaps mheap In order to get
// If from mcentral perhaps mheap Got new span, be shouldhelpgc It will be equal to true
// shouldhelpgc It will be equal to true You will decide whether to trigger it below GC
v, span, shouldhelpgc = c.nextFree(spc)
}
x = unsafe.Pointer(v)
if needzero && span.needzero != 0 {
memclrNoHeapPointers(unsafe.Pointer(v), size)
}
}
} else {
// Directly from large objects mheap Distribute , there s It's a special one span, its class yes 0
var s *mspan
shouldhelpgc = true
systemstack(func() {
s = largeAlloc(size, needzero, noscan)
})
s.freeindex = 1
s.allocCount = 1
x = unsafe.Pointer(s.base())
size = s.elemsize
}
// Set up arena Corresponding bitmap, Record where the pointer is contained , GC Will use bitmap Scan all accessible objects
var scanSize uintptr
if !noscan {
// If allocating a defer+arg block, now that we've picked a malloc size
// large enough to hold everything, cut the "asked for" size down to
// just the defer header, so that the GC bitmap will record the arg block
// as containing nothing at all (as if it were unused space at the end of
// a malloc block caused by size rounding).
// The defer arg areas are scanned as part of scanstack.
if typ == deferType {
dataSize = unsafe.Sizeof(_defer{})
}
// This function is very long , You can see if you are interested
// https://github.com/golang/go/blob/go1.9.2/src/runtime/mbitmap.go#L855
// Although the code is very long, the content of the settings is the same as that mentioned above bitmap The structure of the region is the same
// Set according to type information scan bit Follow pointer bit, scan bit Yes, it means scanning should continue , pointer bit Yes means that the position is a pointer
// What needs to be noticed is
// - If a type only contains a pointer at the beginning , for example [ptr, ptr, large non-pointer data]
// So the back part scan bit Will be 0, This can greatly improve the efficiency of tagging
// - the second slot Of scan bit It's a special use , It's not used to mark whether to continue scan, It's a sign checkmark
// What is? checkmark
// - because go Parallel of GC More complicated , To check that the implementation is correct , go There needs to be a mechanism to check whether all objects that should be marked are marked
// The mechanism is checkmark, In the open checkmark when go It stops the world at the end of the tagging phase, and then executes the tag again
// The second one above slot Of scan bit It is used to mark objects in checkmark Whether marked or not
// - Some people may find a second slot Requires the object to have at least two pointer sizes , What about an object the size of a pointer ?
// Objects with only one pointer size can be divided into two situations
// An object is a pointer , Because the size is just 1 A pointer, so you don't need to look at bitmap Area , This is the first one slot Namely checkmark
// Object is not a pointer , Because there is tiny alloc The mechanism of , Objects that are not pointers and have only one pointer size are assigned to two pointers span in
// You don't need to look at bitmap Area , So the same as above, the first one slot Namely checkmark
heapBitsSetType(uintptr(x), size, dataSize, typ)
if dataSize > typ.size {
// Array allocation. If there are any
// pointers, GC has to scan to the last
// element.
if typ.ptrdata != 0 {
scanSize = dataSize - typ.size + typ.ptrdata
}
} else {
scanSize = typ.ptrdata
}
c.local_scan += scanSize
}
// Memory barrier , because x86 and x64 Of store It's not out of order, so it's just a barrier against compilers , In the compilation it is ret
// Ensure that the stores above that initialize x to
// type-safe memory and set the heap bits occur before
// the caller can make x observable to the garbage
// collector. Otherwise, on weakly ordered machines,
// the garbage collector could follow a pointer to x,
// but see uninitialized memory or stale heap bits.
publicationBarrier()
// If it's in GC in , You need to immediately mark the assigned object as " black ", To prevent it from being recycled
// Allocate black during GC.
// All slots hold nil so no scanning is needed.
// This may be racing with GC so do it atomically if there can be
// a race marking the bit.
if gcphase != _GCoff {
gcmarknewobject(uintptr(x), size, scanSize)
}
// Race Detector To deal with ( Used to detect thread conflicts )
if raceenabled {
racemalloc(x, size)
}
// Memory Sanitizer To deal with ( Used to detect memory problems such as dangerous pointers )
if msanenabled {
msanmalloc(x, size)
}
// Re allow the current G Be seized
mp.mallocing = 0
releasem(mp)
// Debug records
if debug.allocfreetrace != 0 {
tracealloc(x, size, typ)
}
// Profiler Record
if rate := MemProfileRate; rate > 0 {
if size < uintptr(rate) && int32(size) < c.next_sample {
c.next_sample -= int32(size)
} else {
mp := acquirem()
profilealloc(mp, x, size)
releasem(mp)
}
}
// gcAssistBytes subtract " Actual allocation size - Request allocation size ", Adjust to the exact value
if assistG != nil {
// Account for internal fragmentation in the assist
// debt now that we know it.
assistG.gcAssistBytes -= int64(size - dataSize)
}
// If you've got a new one before span, Then judge whether it is necessary to start in the background GC
// The logic of judgment here (gcTrigger) It will be explained in detail below
if shouldhelpgc {
if t := (gcTrigger{kind: gcTriggerHeap}); t.test() {
gcStart(gcBackgroundMode, t)
}
}
return x
}
Next, let's see how to get from span It's assigned to people , The first call nextFreeFast Try to allocate quickly :
// nextFreeFast returns the next free object if one is quickly available.
// Otherwise it returns 0.
func nextFreeFast(s *mspan) gclinkptr {
// Get the first non 0 Of bit It's the number one bit, Which element is unallocated
theBit := sys.Ctz64(s.allocCache) // Is there a free object in the allocCache?
// Find unallocated elements
if theBit < 64 {
result := s.freeindex + uintptr(theBit)
// The index value should be less than the number of elements
if result < s.nelems {
// next freeindex
freeidx := result + 1
// Can be 64 Division requires special treatment ( Reference resources nextFree)
if freeidx%64 == 0 && freeidx != s.nelems {
return 0
}
// to update freeindex and allocCache( High places are 0, It will be updated after exhaustion )
s.allocCache >>= uint(theBit + 1)
s.freeindex = freeidx
// Returns the address of the element
v := gclinkptr(result*s.elemsize + s.base())
// Add assigned element count
s.allocCount++
return v
}
}
return 0
}
If in freeindex Can't quickly find unallocated elements , You need to call nextFree Make more complicated processing :
// nextFree returns the next free object from the cached span if one is available.
// Otherwise it refills the cache with a span with an available object and
// returns that object along with a flag indicating that this was a heavy
// weight allocation. If it is a heavy weight allocation the caller must
// determine whether a new GC cycle needs to be started or if the GC is active
// whether this goroutine needs to assist the GC.
func (c *mcache) nextFree(spc spanClass) (v gclinkptr, s *mspan, shouldhelpgc bool) {
// Find the next one freeindex And update allocCache
s = c.alloc[spc]
shouldhelpgc = false
freeIndex := s.nextFreeIndex()
// If span All the elements in it have been assigned , You need to get new span
if freeIndex == s.nelems {
// The span is full.
if uintptr(s.allocCount) != s.nelems {
println("runtime: s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount != s.nelems && freeIndex == s.nelems")
}
// Apply for a new span
systemstack(func() {
c.refill(spc)
})
// After obtaining a new application span, And set the need to check whether it is executed GC
shouldhelpgc = true
s = c.alloc[spc]
freeIndex = s.nextFreeIndex()
}
if freeIndex >= s.nelems {
throw("freeIndex is not valid")
}
// Returns the address of the element
v = gclinkptr(freeIndex*s.elemsize + s.base())
// Add assigned element count
s.allocCount++
if uintptr(s.allocCount) > s.nelems {
println("s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount > s.nelems")
}
return
}
If mcache Of the type specified in span Is full , You need to call refill Function application new span:
// Gets a span that has a free object in it and assigns it
// to be the cached span for the given sizeclass. Returns this span.
func (c *mcache) refill(spc spanClass) *mspan {
_g_ := getg()
// prevent G Be seized
_g_.m.locks++
// Return the current cached span to the central lists.
s := c.alloc[spc]
// Make sure that the current span All elements have been assigned
if uintptr(s.allocCount) != s.nelems {
throw("refill of span with free space remaining")
}
// Set up span Of incache attribute , Unless it's empty for global use span( That is to say mcache Inside span The default value of the pointer )
if s != &emptymspan {
s.incache = false
}
// towards mcentral Apply for a new span
// Get a new cached span from the central lists.
s = mheap_.central[spc].mcentral.cacheSpan()
if s == nil {
throw("out of memory")
}
if uintptr(s.allocCount) == s.nelems {
throw("span has no free space")
}
// Set up the new span To mcache in
c.alloc[spc] = s
// allow G Be seized
_g_.m.locks--
return s
}
towards mcentral Apply for a new span Will pass cacheSpan function :
mcentral First try to reuse the original from the internal linked list span, If reuse fails, the mheap apply .
// Allocate a span to use in an MCache.
func (c *mcentral) cacheSpan() *mspan {
// Let the current G Assist a part of sweep Work
// Deduct credit for this span allocation and sweep if necessary.
spanBytes := uintptr(class_to_allocnpages[c.spanclass.sizeclass()]) * _PageSize
deductSweepCredit(spanBytes, 0)
// Yes mcentral locked , Because there may be more than one M(P) Simultaneous access
lock(&c.lock)
traceDone := false
if trace.enabled {
traceGCSweepStart()
}
sg := mheap_.sweepgen
retry:
// mcentral There are two in it span The linked list of
// - nonempty Indicates that the span There is at least one unallocated element
// - empty It means you are not sure span There is at least one unallocated element
// This is the first place to look for nonempty The linked list of
// sweepgen Every time GC Will increase 2
// - sweepgen == overall situation sweepgen, Express span already sweep too
// - sweepgen == overall situation sweepgen-1, Express span is sweep
// - sweepgen == overall situation sweepgen-2, Express span wait for sweep
var s *mspan
for s = c.nonempty.first; s != nil; s = s.next {
// If span wait for sweep, Try atomic modification sweepgen For the whole sweepgen-1
if s.sweepgen == sg-2 && atomic.Cas(&s.sweepgen, sg-2, sg-1) {
// If the modification is successful span Move to empty Linked list , sweep It then jumps to havespan
c.nonempty.remove(s)
c.empty.insertBack(s)
unlock(&c.lock)
s.sweep(true)
goto havespan
}
// If this span Being made by other threads sweep, Just skip.
if s.sweepgen == sg-1 {
// the span is being swept by background sweeper, skip
continue
}
// span already sweep too
// because nonempty In the list span Make sure there is at least one unallocated element , You can use it directly here
// we have a nonempty span that does not require sweeping, allocate from it
c.nonempty.remove(s)
c.empty.insertBack(s)
unlock(&c.lock)
goto havespan
}
// lookup empty The linked list of
for s = c.empty.first; s != nil; s = s.next {
// If span wait for sweep, Try atomic modification sweepgen For the whole sweepgen-1
if s.sweepgen == sg-2 && atomic.Cas(&s.sweepgen, sg-2, sg-1) {
// hold span Put it in empty At the end of the list
// we have an empty span that requires sweeping,
// sweep it and see if we can free some space in it
c.empty.remove(s)
// swept spans are at the end of the list
c.empty.insertBack(s)
unlock(&c.lock)
// Try sweep
s.sweep(true)
// sweep In the future, we need to detect whether there are unallocated objects , If you have it, you can use it
freeIndex := s.nextFreeIndex()
if freeIndex != s.nelems {
s.freeindex = freeIndex
goto havespan
}
lock(&c.lock)
// the span is still empty after sweep
// it is already in the empty list, so just retry
goto retry
}
// If this span Being made by other threads sweep, Just skip.
if s.sweepgen == sg-1 {
// the span is being swept by background sweeper, skip
continue
}
// Can't find any with unassigned objects span
// already swept empty span,
// all subsequent ones must also be either swept or in process of sweeping
break
}
if trace.enabled {
traceGCSweepDone()
traceDone = true
}
unlock(&c.lock)
// Can't find any with unassigned objects span, Need from mheap Distribute
// Add to after distribution empty In the list
// Replenish central list if empty.
s = c.grow()
if s == nil {
return nil
}
lock(&c.lock)
c.empty.insertBack(s)
unlock(&c.lock)
// At this point s is a non-empty span, queued at the end of the empty list,
// c is unlocked.
havespan:
if trace.enabled && !traceDone {
traceGCSweepDone()
}
// Statistics span The number of unallocated elements in , Add to mcentral.nmalloc in
// Statistics span Total size of unallocated elements in , Add to memstats.heap_live in
cap := int32((s.npages << _PageShift) / s.elemsize)
n := cap - int32(s.allocCount)
if n == 0 || s.freeindex == s.nelems || uintptr(s.allocCount) == s.nelems {
throw("span has no free objects")
}
// Assume all objects from this span will be allocated in the
// mcache. If it gets uncached, we'll adjust this.
atomic.Xadd64(&c.nmalloc, int64(n))
usedBytes := uintptr(s.allocCount) * s.elemsize
atomic.Xadd64(&memstats.heap_live, int64(spanBytes)-int64(usedBytes))
// Tracking processing
if trace.enabled {
// heap_live changed.
traceHeapAlloc()
}
// If it's in GC in , because heap_live Changed the , To readjust G The value of the auxiliary tag work
// Please refer to the following for details revise Analysis of function
if gcBlackenEnabled != 0 {
// heap_live changed.
gcController.revise()
}
// Set up span Of incache attribute , Express span is mcache in
s.incache = true
// according to freeindex to update allocCache
freeByteBase := s.freeindex &^ (64 - 1)
whichByte := freeByteBase / 8
// Init alloc bits cache.
s.refillAllocCache(whichByte)
// Adjust the allocCache so that s.freeindex corresponds to the low bit in
// s.allocCache.
s.allocCache >>= s.freeindex % 64
return s
}
mcentral towards mheap Apply for a new span Will use grow function :
// grow allocates a new empty span from the heap and initializes it for c's size class.
func (c *mcentral) grow() *mspan {
// according to mcentral Type calculation needs to apply for span Size ( Divide 8K = How many pages are there ) And how many elements can be saved
npages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()])
size := uintptr(class_to_size[c.spanclass.sizeclass()])
n := (npages << _PageShift) / size
// towards mheap Apply for a new span, Page (8K) In units of
s := mheap_.alloc(npages, c.spanclass, false, true)
if s == nil {
return nil
}
p := s.base()
s.limit = p + size*n
// Assign and initialize span Of allocBits and gcmarkBits
heapBitsForSpan(s.base()).initSpan(s)
return s
}
mheap Distribute span The function of is alloc:
func (h *mheap) alloc(npage uintptr, spanclass spanClass, large bool, needzero bool) *mspan {
// stay g0 In the stack space alloc_m function
// About systemstack Please refer to the previous article
// Don't do any operations that lock the heap on the G stack.
// It might trigger stack growth, and the stack growth code needs
// to be able to allocate heap.
var s *mspan
systemstack(func() {
s = h.alloc_m(npage, spanclass, large)
})
if s != nil {
if needzero && s.needzero != 0 {
memclrNoHeapPointers(unsafe.Pointer(s.base()), s.npages<<_PageShift)
}
s.needzero = 0
}
return s
}
alloc The function will be in the g0 In the stack space alloc_m function :
// Allocate a new span of npage pages from the heap for GC'd memory
// and record its size class in the HeapMap and HeapMapCache.
func (h *mheap) alloc_m(npage uintptr, spanclass spanClass, large bool) *mspan {
_g_ := getg()
if _g_ != _g_.m.g0 {
throw("_mheap_alloc not on g0 stack")
}
// Yes mheap locked , The lock here is a global lock
lock(&h.lock)
// In order to prevent heap It's growing too fast , In distribution n Before the page sweep And recycling n page
// Will enumerate first busy List and then enumerate busyLarge The list goes on sweep, Specific reference reclaim and reclaimList function
// To prevent excessive heap growth, before allocating n pages
// we need to sweep and reclaim at least n pages.
if h.sweepdone == 0 {
// TODO(austin): This tends to sweep a large number of
// spans in order to find a few completely free spans
// (for example, in the garbage benchmark, this sweeps
// ~30x the number of pages its trying to allocate).
// If GC kept a bit for whether there were any marks
// in a span, we could release these free spans
// at the end of GC and eliminate this entirely.
if trace.enabled {
traceGCSweepStart()
}
h.reclaim(npage)
if trace.enabled {
traceGCSweepDone()
}
}
// hold mcache Add local statistics in to global
// transfer stats from cache to global
memstats.heap_scan += uint64(_g_.m.mcache.local_scan)
_g_.m.mcache.local_scan = 0
memstats.tinyallocs += uint64(_g_.m.mcache.local_tinyallocs)
_g_.m.mcache.local_tinyallocs = 0
// call allocSpanLocked Distribute span, allocSpanLocked The function request is currently on mheap locked
s := h.allocSpanLocked(npage, &memstats.heap_inuse)
if s != nil {
// Record span info, because gc needs to be
// able to map interior pointer to containing span.
// Set up span Of sweepgen = overall situation sweepgen
atomic.Store(&s.sweepgen, h.sweepgen)
// Put it all together span In the list , there sweepSpans Is the length of the 2
// sweepSpans[h.sweepgen/2%2] Save what is currently in use span list
// sweepSpans[1-h.sweepgen/2%2] Save and wait sweep Of span list
// Because every time gcsweepgen Metropolitan plus 2, Every time gc Both lists are swapped
h.sweepSpans[h.sweepgen/2%2].push(s) // Add to swept in-use list.
// initialization span member
s.state = _MSpanInUse
s.allocCount = 0
s.spanclass = spanclass
if sizeclass := spanclass.sizeclass(); sizeclass == 0 {
s.elemsize = s.npages << _PageShift
s.divShift = 0
s.divMul = 0
s.divShift2 = 0
s.baseMask = 0
} else {
s.elemsize = uintptr(class_to_size[sizeclass])
m := &class_to_divmagic[sizeclass]
s.divShift = m.shift
s.divMul = m.mul
s.divShift2 = m.shift2
s.baseMask = m.baseMask
}
// update stats, sweep lists
h.pagesInUse += uint64(npage)
// above grow The function will pass in true, That is, through grow Call here large It will be equal to true
// Add assigned span To busy list , If the number of pages exceeds _MaxMHeapList(128 page =8K*128=1M) Is on the busylarge list
if large {
memstats.heap_objects++
mheap_.largealloc += uint64(s.elemsize)
mheap_.nlargealloc++
atomic.Xadd64(&memstats.heap_live, int64(npage<<_PageShift))
// Swept spans are at the end of lists.
if s.npages < uintptr(len(h.busy)) {
h.busy[s.npages].insertBack(s)
} else {
h.busylarge.insertBack(s)
}
}
}
// If it's in GC in , because heap_live Changed the , To readjust G The value of the auxiliary tag work
// Please refer to the following for details revise Analysis of function
// heap_scan and heap_live were updated.
if gcBlackenEnabled != 0 {
gcController.revise()
}
// Tracking processing
if trace.enabled {
traceHeapAlloc()
}
// h.spans is accessed concurrently without synchronization
// from other threads. Hence, there must be a store/store
// barrier here to ensure the writes to h.spans above happen
// before the caller can publish a pointer p to an object
// allocated from s. As soon as this happens, the garbage
// collector running on another processor could read p and
// look up s in h.spans. The unlock acts as the barrier to
// order these writes. On the read side, the data dependency
// between p and the index in h.spans orders the reads.
unlock(&h.lock)
return s
}
Keep looking at allocSpanLocked function :
// Allocates a span of the given size. h must be locked.
// The returned span has been removed from the
// free list, but its state is still MSpanFree.
func (h *mheap) allocSpanLocked(npage uintptr, stat *uint64) *mspan {
var list *mSpanList
var s *mspan
// Try to mheap Free list assignment in
// The number of pages is less than _MaxMHeapList(128 page =1M) Freedom span Will be in free In the list
// The number of pages is greater than _MaxMHeapList Freedom span Will be in freelarge In the list
// Try in fixed-size lists up to max.
for i := int(npage); i < len(h.free); i++ {
list = &h.free[i]
if !list.isEmpty() {
s = list.first
list.remove(s)
goto HaveSpan
}
}
// free If you can't find the list, look for freelarge list
// If you can't find it, go to arena Area application for a new span Add to freelarge in , Then look for freelarge list
// Best fit in list of large spans.
s = h.allocLarge(npage) // allocLarge removed s from h.freelarge for us
if s == nil {
if !h.grow(npage) {
return nil
}
s = h.allocLarge(npage)
if s == nil {
return nil
}
}
HaveSpan:
// Mark span in use.
if s.state != _MSpanFree {
throw("MHeap_AllocLocked - MSpan not free")
}
if s.npages < npage {
throw("MHeap_AllocLocked - bad npages")
}
// If span Some have been released ( Break the relationship between virtual memory and physical memory ) Page of , Remind them that these pages will be used and update the statistics
if s.npreleased > 0 {
sysUsed(unsafe.Pointer(s.base()), s.npages<<_PageShift)
memstats.heap_released -= uint64(s.npreleased << _PageShift)
s.npreleased = 0
}
// If I get it span More pages than required
// Split the remaining pages to another span And put it on the free list
if s.npages > npage {
// Trim extra and put it back in the heap.
t := (*mspan)(h.spanalloc.alloc())
t.init(s.base()+npage<<_PageShift, s.npages-npage)
s.npages = npage
p := (t.base() - h.arena_start) >> _PageShift
if p > 0 {
h.spans[p-1] = s
}
h.spans[p] = t
h.spans[p+t.npages-1] = t
t.needzero = s.needzero
s.state = _MSpanManual // prevent coalescing with s
t.state = _MSpanManual
h.freeSpanLocked(t, false, false, s.unusedsince)
s.state = _MSpanFree
}
s.unusedsince = 0
// Set up spans Area , Which address corresponds to which mspan object
p := (s.base() - h.arena_start) >> _PageShift
for n := uintptr(0); n < npage; n++ {
h.spans[p+n] = s
}
// Update Statistics
*stat += uint64(npage << _PageShift)
memstats.heap_idle -= uint64(npage << _PageShift)
//println("spanalloc", hex(s.start<<_PageShift))
if s.inList() {
throw("still in list")
}
return s
}
Keep looking at allocLarge function :
// allocLarge allocates a span of at least npage pages from the treap of large spans.
// Returns nil if no such span currently exists.
func (h *mheap) allocLarge(npage uintptr) *mspan {
// Search treap for smallest span with >= npage pages.
return h.freelarge.remove(npage)
}
freelarge The type is mTreap, call remove The function searches the tree for at least one npage And the smallest in the tree span return :
// remove searches for, finds, removes from the treap, and returns the smallest
// span that can hold npages. If no span has at least npages return nil.
// This is slightly more complicated than a simple binary tree search
// since if an exact match is not found the next larger node is
// returned.
// If the last node inspected > npagesKey not holding
// a left node (a smaller npages) is the "best fit" node.
func (root *mTreap) remove(npages uintptr) *mspan {
t := root.treap
for t != nil {
if t.spanKey == nil {
throw("treap node with nil spanKey found")
}
if t.npagesKey < npages {
t = t.right
} else if t.left != nil && t.left.npagesKey >= npages {
t = t.left
} else {
result := t.spanKey
root.removeNode(t)
return result
}
}
return nil
}
towards arena Regional application new span The function of is mheap Class grow function :
// Try to add at least npage pages of memory to the heap,
// returning whether it worked.
//
// h must be locked.
func (h *mheap) grow(npage uintptr) bool {
// Ask for a big chunk, to reduce the number of mappings
// the operating system needs to track; also amortizes
// the overhead of an operating system mapping.
// Allocate a multiple of 64kB.
npage = round(npage, (64<<10)/_PageSize)
ask := npage << _PageShift
if ask < _HeapAllocChunk {
ask = _HeapAllocChunk
}
// call mheap.sysAlloc Function request
v := h.sysAlloc(ask)
if v == nil {
if ask > npage<<_PageShift {
ask = npage << _PageShift
v = h.sysAlloc(ask)
}
if v == nil {
print("runtime: out of memory: cannot allocate ", ask, "-byte block (", memstats.heap_sys, " in use)n")
return false
}
}
// Create a new span And add it to the free list
// Create a fake "in use" span and free it, so that the
// right coalescing happens.
s := (*mspan)(h.spanalloc.alloc())
s.init(uintptr(v), ask>>_PageShift)
p := (s.base() - h.arena_start) >> _PageShift
for i := p; i < p+s.npages; i++ {
h.spans[i] = s
}
atomic.Store(&s.sweepgen, h.sweepgen)
s.state = _MSpanInUse
h.pagesInUse += uint64(s.npages)
h.freeSpanLocked(s, false, true, 0)
return true
}
Keep looking at mheap Of sysAlloc function :
// sysAlloc allocates the next n bytes from the heap arena. The
// returned pointer is always _PageSize aligned and between
// h.arena_start and h.arena_end. sysAlloc returns nil on failure.
// There is no corresponding free function.
func (h *mheap) sysAlloc(n uintptr) unsafe.Pointer {
// strandLimit is the maximum number of bytes to strand from
// the current arena block. If we would need to strand more
// than this, we fall back to sysAlloc'ing just enough for
// this allocation.
const strandLimit = 16 << 20
// If arena Region currently not enough submitted areas , Call sysReserve Reserve more space , And then update arena_end
// sysReserve stay linux It's called mmap function
// mmap(v, n, _PROT_NONE, _MAP_ANON|_MAP_PRIVATE, -1, 0)
if n > h.arena_end-h.arena_alloc {
// If we haven't grown the arena to _MaxMem yet, try
// to reserve some more address space.
p_size := round(n+_PageSize, 256<<20)
new_end := h.arena_end + p_size // Careful: can overflow
if h.arena_end <= new_end && new_end-h.arena_start-1 <= _MaxMem {
// TODO: It would be bad if part of the arena
// is reserved and part is not.
var reserved bool
p := uintptr(sysReserve(unsafe.Pointer(h.arena_end), p_size, &reserved))
if p == 0 {
// TODO: Try smaller reservation
// growths in case we're in a crowded
// 32-bit address space.
goto reservationFailed
}
// p can be just about anywhere in the address
// space, including before arena_end.
if p == h.arena_end {
// The new block is contiguous with
// the current block. Extend the
// current arena block.
h.arena_end = new_end
h.arena_reserved = reserved
} else if h.arena_start <= p && p+p_size-h.arena_start-1 <= _MaxMem && h.arena_end-h.arena_alloc < strandLimit {
// We were able to reserve more memory
// within the arena space, but it's
// not contiguous with our previous
// reservation. It could be before or
// after our current arena_used.
//
// Keep everything page-aligned.
// Our pages are bigger than hardware pages.
h.arena_end = p + p_size
p = round(p, _PageSize)
h.arena_alloc = p
h.arena_reserved = reserved
} else {
// We got a mapping, but either
//
// 1) It's not in the arena, so we
// can't use it. (This should never
// happen on 32-bit.)
//
// 2) We would need to discard too
// much of our current arena block to
// use it.
//
// We haven't added this allocation to
// the stats, so subtract it from a
// fake stat (but avoid underflow).
//
// We'll fall back to a small sysAlloc.
stat := uint64(p_size)
sysFree(unsafe.Pointer(p), p_size, &stat)
}
}
}
// When the space reserved is enough, just add arena_alloc
if n <= h.arena_end-h.arena_alloc {
// Keep taking from our reservation.
p := h.arena_alloc
sysMap(unsafe.Pointer(p), n, h.arena_reserved, &memstats.heap_sys)
h.arena_alloc += n
if h.arena_alloc > h.arena_used {
h.setArenaUsed(h.arena_alloc, true)
}
if p&(_PageSize-1) != 0 {
throw("misrounded allocation in MHeap_SysAlloc")
}
return unsafe.Pointer(p)
}
// Processing after failed reservation space
reservationFailed:
// If using 64-bit, our reservation is all we have.
if sys.PtrSize != 4 {
return nil
}
// On 32-bit, once the reservation is gone we can
// try to get memory at a location chosen by the OS.
p_size := round(n, _PageSize) + _PageSize
p := uintptr(sysAlloc(p_size, &memstats.heap_sys))
if p == 0 {
return nil
}
if p < h.arena_start || p+p_size-h.arena_start > _MaxMem {
// This shouldn't be possible because _MaxMem is the
// whole address space on 32-bit.
top := uint64(h.arena_start) + _MaxMem
print("runtime: memory allocated by OS (", hex(p), ") not in usable range [", hex(h.arena_start), ",", hex(top), ")n")
sysFree(unsafe.Pointer(p), p_size, &memstats.heap_sys)
return nil
}
p += -p & (_PageSize - 1)
if p+n > h.arena_used {
h.setArenaUsed(p+n, true)
}
if p&(_PageSize-1) != 0 {
throw("misrounded allocation in MHeap_SysAlloc")
}
return unsafe.Pointer(p)
}
That's the whole process of assigning objects , The next analysis GC Handling of marked and recycled objects .
Recycle object processing
The process of reclaiming objects
GO Of GC It's parallel GC, That is to say GC Most of the processing and ordinary go The code is running at the same time , This makes GO Of GC The process is complicated .
First GC There are four stages , They are :
- Sweep Termination: For the unclean span Carry out the cleaning , Only the last round GC We can start a new round only after the cleaning work of GC
- Mark: Scan all root objects , And all the objects that the root object can reach , Mark them not to be recycled
- Mark Termination: Complete the marking work , Rescan some root objects ( requirement STW)
- Sweep: Clean according to the marked results span
The picture below is more complete GC technological process , The four stages are classified by color :
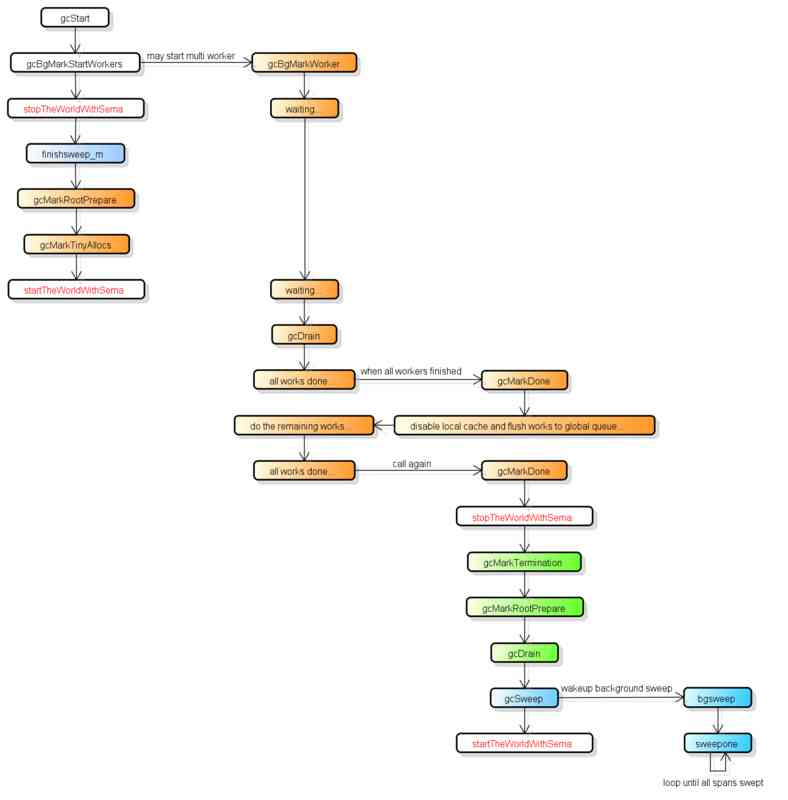
stay GC There are two kinds of background tasks in the process (G), One is the background task for marking , One is the background task for cleaning .
Background tasks for tagging will start when needed , The number of background tasks that can work at the same time is about P The quantity of 25%, That is to say go Let's talk about 25% Of cpu Use in GC On the basis of .
The background task for cleaning will start a , Wake up when entering the cleaning phase .
At present, the whole GC The process will take place twice STW(Stop The World), The first is Mark The beginning of the stage , The second, Mark Termination Stage .
for the first time STW Will be ready to scan the root object , Start write barrier (Write Barrier) And the auxiliary GC(mutator assist).
The second time STW Some root objects will be rescanned , Disable write barrier (Write Barrier) And the auxiliary GC(mutator assist).
It should be noted that , Not all root object scans require STW, For example, scanning an object on a stack only needs to stop owning the stack G.
from go 1.9 Start , The implementation of the write barrier uses Hybrid Write Barrier, A significant reduction in the second time STW Time for .
GC The trigger condition of
GC It will be triggered when certain conditions are met , The trigger conditions are as follows :
- gcTriggerAlways: Force trigger GC
- gcTriggerHeap: When the current allocated memory reaches a certain value GC
- gcTriggerTime: When a certain period of time has not been implemented GC It triggers GC
- gcTriggerCycle: Ask for a new round of GC, If started, skip , Manual trigger GC Of
runtime.GC()Will use this condition
The judgment of trigger condition is in gctrigger Of test function .
among gcTriggerHeap and gcTriggerTime These two conditions are naturally triggered , gcTriggerHeap The judgment code for is as follows :
return memstats.heap_live >= memstats.gc_trigger
heap_live As can be seen from the code analysis of the allocator above , When the duty reaches gc_trigger It will trigger GC, that gc_trigger How it was decided ?
gc_trigger Is calculated in gcSetTriggerRatio Function , Formula is :
trigger = uint64(float64(memstats.heap_marked) * (1 + triggerRatio))
Multiply the size of the current tag to survive 1+ coefficient triggerRatio, It's about starting next time GC The amount of allocation needed .
triggerRatio In every time GC It will be adjusted after , Calculation triggerRatio The function of is encCycle, Formula is :
const triggerGain = 0.5
// The goal is Heap growth rate , The default is 1.0
goalGrowthRatio := float64(gcpercent) / 100
// actual Heap growth rate , Equal to the total size of / Survival size -1
actualGrowthRatio := float64(memstats.heap_live)/float64(memstats.heap_marked) - 1
// GC The usage time of the marking phase ( because endCycle Is in Mark Termination Phase called )
assistDuration := nanotime() - c.markStartTime
// GC Marking stage of CPU Occupancy rate , The target value is 0.25
utilization := gcGoalUtilization
if assistDuration > 0 {
// assistTime yes G auxiliary GC Total time spent marking objects
// (nanosecnds spent in mutator assists during this cycle)
// additional CPU Occupancy rate = auxiliary GC The total time the object was marked / (GC Mark usage time * P The number of )
utilization += float64(c.assistTime) / float64(assistDuration*int64(gomaxprocs))
}
// Trigger factor offset value = Target growth rate - The original trigger factor - CPU Occupancy rate / The goal is CPU Occupancy rate * ( Real growth rate - The original trigger factor )
// Parameter analysis :
// The greater the real growth rate , The smaller the trigger factor offset is , Less than 0 Trigger next time GC It's going to be early
// CPU The more occupancy , The smaller the trigger factor offset is , Less than 0 Trigger next time GC It's going to be early
// The bigger the original trigger coefficient , The smaller the trigger factor offset is , Less than 0 Trigger next time GC It's going to be early
triggerError := goalGrowthRatio - memstats.triggerRatio - utilization/gcGoalUtilization*(actualGrowthRatio-memstats.triggerRatio)
// Adjust the trigger factor according to the offset value , Adjust only half of the offset at a time ( Gradual adjustment )
triggerRatio := memstats.triggerRatio + triggerGain*triggerError
Formula " The goal is Heap growth rate " You can set environment variables by "GOGC" adjustment , The default value is 100, Increasing its value can reduce GC Trigger .
Set up "GOGC=off" You can turn it off completely GC.
gcTriggerTime The judgment code for is as follows :
lastgc := int64(atomic.Load64(&memstats.last_gc_nanotime))
return lastgc != 0 && t.now-lastgc > forcegcperiod
forcegcperiod Is defined as 2 minute , That is to say 2 No execution in minutes GC It will force trigger .
The definition of tricolor ( black , ash , white )
I saw the three colors GC Of " Tricolor " The best article to explain this concept is This article 了 , It is highly recommended to read the explanation in this article first .
" Tricolor " The concept of "can be simply understood as :
- black : The object is this time GC Has been marked in , And the child objects contained in this object are also marked
- gray : The object is this time GC Has been marked in , But this object contains child objects that are not marked
- white : The object is this time GC Not marked in
stay go Internal objects do not have properties that hold colors , Tricolor is just a description of their state ,
The white object is where it is span Of gcmarkBits Corresponding bit by 0,
The gray object is where it is span Of gcmarkBits Corresponding bit by 1, And the object is in the tag queue ,
The black object is where it is span Of gcmarkBits Corresponding bit by 1, And the object has been removed from the tag queue and processed .
gc After completion , gcmarkBits Will move to allocBits And then reassign one that's all for 0 Of bitmap, So the black object turns white .
Write barriers (Write Barrier)
because go Support parallel GC, GC Scanning and go Code can run at the same time , The problem with this is GC In the process of scanning go The code may have changed the dependency tree of the object ,
For example, the root object is found at the beginning of the scan A and B, B Have C The pointer to , GC Scan first A, then B hold C Hand over the pointer of A, GC Scan again B, At this time C It won't be scanned .
To avoid this problem , go stay GC The markup phase of the will enable the write barrier (Write Barrier).
Write barrier enabled (Write Barrier) after , When B hold C Hand over the pointer of A when , GC Would think that in this round of scanning C The pointer is alive ,
Even if A It may be lost later C, that C It's just the next round of recycling .
The write barrier is enabled only for pointers , And only in GC The marking phase of the , Usually, the value will be written directly to the target address .
go stay 1.9 It's starting to work Hybrid write barrier (Hybrid Write Barrier), The pseudocode is as follows :
writePointer(slot, ptr):
shade(*slot)
if any stack is grey:
shade(ptr)
*slot = ptr
The hybrid write barrier will mark the pointer to write to the target at the same time " The original pointer " and “ New pointer ".
The reason to mark the original pointer is , Other running threads may copy the value of this pointer to local variables on the register or stack at the same time ,
because Copying a pointer to a register or a local variable on a stack does not pass through a write barrier , So it may cause the pointer not to be marked , Imagine the following :
[go] b = obj
[go] oldx = nil
[gc] scan oldx...
[go] oldx = b.x // Copy b.x To local variables , Not through the writing barrier
[go] b.x = ptr // Writing barriers should be marked b.x Original value of
[gc] scan b...
If the write barrier does not mark the original value , that oldx It won't be scanned .
The reason for marking the new pointer is , It is possible for other running threads to shift the pointer position , Imagine the following :
[go] a = ptr
[go] b = obj
[gc] scan b...
[go] b.x = a // Writing barriers should be marked b.x The new value of
[go] a = nil
[gc] scan a...
If the write barrier does not mark a new value , that ptr It won't be scanned .
The hybrid write barrier allows GC There is no need to rescan each... After parallel marking G The stack , Can reduce the Mark Termination Medium STW Time .
Besides writing barriers , stay GC All newly assigned objects will immediately turn black during the process , Above mallocgc You can see in the function .
auxiliary GC(mutator assist)
In order to prevent heap It's growing too fast , stay GC In the process of execution, if it runs at the same time G Allocated memory , So this G Will be asked to assist GC Do part of the work .
stay GC At the same time in the process of G be called "mutator", "mutator assist" The mechanism is G auxiliary GC The mechanism for doing part of the work .
auxiliary GC There are two types of work done , One is the mark (Mark), The other is cleaning (Sweep).
The trigger of the auxiliary marker can be viewed from the above mallocgc function , When triggered G Will help scan " workload " Objects , The formula for calculating the workload is :
debtBytes * assistWorkPerByte
It means the size of the distribution multiplied by the coefficient assistWorkPerByte, assistWorkPerByte In function revise in , Formula is :
// Number of objects waiting to be scanned = Number of objects not scanned - Number of objects scanned
scanWorkExpected := int64(memstats.heap_scan) - c.scanWork
if scanWorkExpected < 1000 {
scanWorkExpected = 1000
}
// Distance triggered GC Of Heap size = Expect to trigger GC Of Heap size - Current Heap size
// Be careful next_gc The calculation of the following gc_trigger Dissimilarity , next_gc be equal to heap_marked * (1 + gcpercent / 100)
heapDistance := int64(memstats.next_gc) - int64(atomic.Load64(&memstats.heap_live))
if heapDistance <= 0 {
heapDistance = 1
}
// Every distribution 1 byte The number of objects that need to be scanned auxiliary = Number of objects waiting to be scanned / Distance triggered GC Of Heap size
c.assistWorkPerByte = float64(scanWorkExpected) / float64(heapDistance)
c.assistBytesPerWork = float64(heapDistance) / float64(scanWorkExpected)
What's different from the auxiliary marker is , Auxiliary cleaning application new span Only when you check , The auxiliary marker checks every time an object is allocated .
The trigger of auxiliary cleaning can be seen from the above cacheSpan function , When triggered G Will help recycle " workload " The object of the page , The formula for calculating the workload is :
spanBytes * sweepPagesPerByte // Not exactly the same , To be specific, see deductSweepCredit function
It means the size of the distribution multiplied by the coefficient sweepPagesPerByte, sweepPagesPerByte In function gcSetTriggerRatio in , Formula is :
// Current Heap size
heapLiveBasis := atomic.Load64(&memstats.heap_live)
// Distance triggered GC Of Heap size = Next trigger GC Of Heap size - Current Heap size
heapDistance := int64(trigger) - int64(heapLiveBasis)
heapDistance -= 1024 * 1024
if heapDistance < _PageSize {
heapDistance = _PageSize
}
// The number of pages cleaned
pagesSwept := atomic.Load64(&mheap_.pagesSwept)
// The number of pages not cleaned = Number of pages in use - The number of pages cleaned
sweepDistancePages := int64(mheap_.pagesInUse) - int64(pagesSwept)
if sweepDistancePages <= 0 {
mheap_.sweepPagesPerByte = 0
} else {
// Every distribution 1 byte( Of span) The number of pages that need to be cleaned up = The number of pages not cleaned / Distance triggered GC Of Heap size
mheap_.sweepPagesPerByte = float64(sweepDistancePages) / float64(heapDistance)
}
Root object
stay GC The first thing that needs to be marked is " Root object ", All objects that are reachable from the root object are considered alive .
The root object contains global variables , each G Variables on the stack of , GC The root object is scanned first, and then all objects that the root object can reach .
Scanning the root object involves a series of tasks , They are defined in [https://github.com/golang/go/blob/go1.9.2/src/runtime/mgcmark.go#L54] function :
Fixed Roots: Special scanning work
- fixedRootFinalizers: Scan the constructor queue
- fixedRootFreeGStacks: Release suspended G The stack
- Flush Cache Roots: Release mcache All in span, requirement STW
- Data Roots: Scan global variables for read and write
- BSS Roots: Scan read-only global variables
- Span Roots: Scan each one span A special object in ( Destructor list )
- Stack Roots: Scan each one G The stack
Marking stage (Mark) Will do one of them "Fixed Roots", "Data Roots", "BSS Roots", "Span Roots", "Stack Roots".
Complete the marking phase (Mark Termination) Will do one of them "Fixed Roots", "Flush Cache Roots".
Tag queue
GC The marking phase of the " Tag queue " To make sure that all objects reachable from the root object are marked , As mentioned above " gray " Is the object in the tag queue .
for instance , If there is [A, B, C] These three root objects , Then when you scan the root objects, you put them in the tag queue :
work queue: [A, B, C]
Background marking tasks are taken out of the tag queue A, If A Refer to the D, Then put D Put in the tag queue :
work queue: [B, C, D]
The background tag task is taken from the tag queue B, If B It also quotes D, This is because D stay gcmarkBits Corresponding bit It's already 1 So I will skip :
work queue: [C, D]
If it runs in parallel go The code assigns an object E, object E Will be immediately marked , But it doesn't get into the tag queue ( Because sure E There are no references to other objects ).
And then run in parallel go Code puts objects F Set to object E Members of , The write barrier marks the object F And then put the object F Add to the run queue :
work queue: [C, D, F]
The background tag task is taken from the tag queue C, If C There are no references to other objects , There is no need to deal with :
work queue: [D, F]
The background tag task is taken from the tag queue D, If D Refer to the X, Then put X Put in the tag queue :
work queue: [F, X]
The background tag task is taken from the tag queue F, If F There are no references to other objects , There is no need to deal with .
The background tag task is taken from the tag queue X, If X There are no references to other objects , There is no need to deal with .
Finally, the marking queue is empty , Mark complete , The living objects are [A, B, C, D, E, F, X].
The actual situation will be a little more complicated than the situation described above .
The tag queue is divided into global tag queue and each tag queue P Local tag queue for , This is similar to a running queue in a coroutine .
The queue is empty and marked after , You also need to stop the whole world and ban writing barriers , Then check again if it's empty .
Source code analysis
go Trigger gc From gcStart Function to :
// gcStart transitions the GC from _GCoff to _GCmark (if
// !mode.stwMark) or _GCmarktermination (if mode.stwMark) by
// performing sweep termination and GC initialization.
//
// This may return without performing this transition in some cases,
// such as when called on a system stack or with locks held.
func gcStart(mode gcMode, trigger gcTrigger) {
// Judge the present G Is it possible to seize , Don't trigger when you can't preempt GC
// Since this is called from malloc and malloc is called in
// the guts of a number of libraries that might be holding
// locks, don't attempt to start GC in non-preemptible or
// potentially unstable situations.
mp := acquirem()
if gp := getg(); gp == mp.g0 || mp.locks > 1 || mp.preemptoff != "" {
releasem(mp)
return
}
releasem(mp)
mp = nil
// Clean up the last round in parallel GC Not cleaned span
// Pick up the remaining unswept/not being swept spans concurrently
//
// This shouldn't happen if we're being invoked in background
// mode since proportional sweep should have just finished
// sweeping everything, but rounding errors, etc, may leave a
// few spans unswept. In forced mode, this is necessary since
// GC can be forced at any point in the sweeping cycle.
//
// We check the transition condition continuously here in case
// this G gets delayed in to the next GC cycle.
for trigger.test() && gosweepone() != ^uintptr(0) {
sweep.nbgsweep++
}
// locked , And then check again gcTrigger Is the condition of , If it doesn't work, it doesn't trigger GC
// Perform GC initialization and the sweep termination
// transition.
semacquire(&work.startSema)
// Re-check transition condition under transition lock.
if !trigger.test() {
semrelease(&work.startSema)
return
}
// Whether the record is forced to trigger , gcTriggerCycle yes runtime.GC With
// For stats, check if this GC was forced by the user.
work.userForced = trigger.kind == gcTriggerAlways || trigger.kind == gcTriggerCycle
// Determines whether the prohibition of parallelism is specified GC Parameters of
// In gcstoptheworld debug mode, upgrade the mode accordingly.
// We do this after re-checking the transition condition so
// that multiple goroutines that detect the heap trigger don't
// start multiple STW GCs.
if mode == gcBackgroundMode {
if debug.gcstoptheworld == 1 {
mode = gcForceMode
} else if debug.gcstoptheworld == 2 {
mode = gcForceBlockMode
}
}
// Ok, we're doing it! Stop everybody else
semacquire(&worldsema)
// Tracking processing
if trace.enabled {
traceGCStart()
}
// Start the background scan task (G)
if mode == gcBackgroundMode {
gcBgMarkStartWorkers()
}
// Reset flag related state
gcResetMarkState()
// Reset parameters
work.stwprocs, work.maxprocs = gcprocs(), gomaxprocs
work.heap0 = atomic.Load64(&memstats.heap_live)
work.pauseNS = 0
work.mode = mode
// Record the start time
now := nanotime()
work.tSweepTerm = now
work.pauseStart = now
// Stop all running G, And they are forbidden to run
systemstack(stopTheWorldWithSema)
// !!!!!!!!!!!!!!!!
// The world has stopped (STW)...
// !!!!!!!!!!!!!!!!
// Clean up the last round GC Not cleaned span, Make sure the last round GC Completed
// Finish sweep before we start concurrent scan.
systemstack(func() {
finishsweep_m()
})
// Clean sched.sudogcache and sched.deferpool
// clearpools before we start the GC. If we wait they memory will not be
// reclaimed until the next GC cycle.
clearpools()
// increase GC Count
work.cycles++
// Judge whether it is parallel or not GC Pattern
if mode == gcBackgroundMode { // Do as much work concurrently as possible
// Mark a new round GC Started
gcController.startCycle()
work.heapGoal = memstats.next_gc
// Set the GC Status as _GCmark
// Then enable the write barrier
// Enter concurrent mark phase and enable
// write barriers.
//
// Because the world is stopped, all Ps will
// observe that write barriers are enabled by
// the time we start the world and begin
// scanning.
//
// Write barriers must be enabled before assists are
// enabled because they must be enabled before
// any non-leaf heap objects are marked. Since
// allocations are blocked until assists can
// happen, we want enable assists as early as
// possible.
setGCPhase(_GCmark)
// Reset the count of background marking tasks
gcBgMarkPrepare() // Must happen before assist enable.
// Calculate the number of tasks to scan the root object
gcMarkRootPrepare()
// Mark all tiny alloc Objects waiting to be merged
// Mark all active tinyalloc blocks. Since we're
// allocating from these, they need to be black like
// other allocations. The alternative is to blacken
// the tiny block on every allocation from it, which
// would slow down the tiny allocator.
gcMarkTinyAllocs()
// Enable auxiliary GC
// At this point all Ps have enabled the write
// barrier, thus maintaining the no white to
// black invariant. Enable mutator assists to
// put back-pressure on fast allocating
// mutators.
atomic.Store(&gcBlackenEnabled, 1)
// Record the start time of the mark
// Assists and workers can start the moment we start
// the world.
gcController.markStartTime = now
// Restart the world
// The background tag task created earlier will start to work , After all background marking tasks have been completed , Enter the completion marking stage
// Concurrent mark.
systemstack(startTheWorldWithSema)
// !!!!!!!!!!!!!!!
// The world has rebooted ...
// !!!!!!!!!!!!!!!
// How long has the record stopped , And mark the start of the phase
now = nanotime()
work.pauseNS += now - work.pauseStart
work.tMark = now
} else {
// It's not parallel GC Pattern
// Record the start time of the completion marking phase
t := nanotime()
work.tMark, work.tMarkTerm = t, t
work.heapGoal = work.heap0
// Skip the marking phase , Execution completion marking phase
// All work will stop in the state of the world
// ( The marking phase will set up work.markrootDone=true, If you skip, its value is false, The completion of the marking phase will do all the work )
// Completing the tagging phase will restart the world
// Perform mark termination. This will restart the world.
gcMarkTermination(memstats.triggerRatio)
}
semrelease(&work.startSema)
}
Next, analyze one by one gcStart Called function , It is suggested to cooperate with the above " The process of reclaiming objects " In the picture understanding .
function gcBgMarkStartWorkers Used to start the background marking task , First, separate each of them P Start a :
// gcBgMarkStartWorkers prepares background mark worker goroutines.
// These goroutines will not run until the mark phase, but they must
// be started while the work is not stopped and from a regular G
// stack. The caller must hold worldsema.
func gcBgMarkStartWorkers() {
// Background marking is performed by per-P G's. Ensure that
// each P has a background GC G.
for _, p := range &allp {
if p == nil || p.status == _Pdead {
break
}
// If it has been started, it will not be started repeatedly
if p.gcBgMarkWorker == 0 {
go gcBgMarkWorker(p)
// Wait for the task notification semaphore after startup bgMarkReady Go on
notetsleepg(&work.bgMarkReady, -1)
noteclear(&work.bgMarkReady)
}
}
}
Although here for each P Started a background marking task , But the only thing that can work at the same time is 25%, This logic is in the coroutine M obtain G Called when findRunnableGCWorker in :
// findRunnableGCWorker returns the background mark worker for _p_ if it
// should be run. This must only be called when gcBlackenEnabled != 0.
func (c *gcControllerState) findRunnableGCWorker(_p_ *p) *g {
if gcBlackenEnabled == 0 {
throw("gcControllerState.findRunnable: blackening not enabled")
}
if _p_.gcBgMarkWorker == 0 {
// The mark worker associated with this P is blocked
// performing a mark transition. We can't run it
// because it may be on some other run or wait queue.
return nil
}
if !gcMarkWorkAvailable(_p_) {
// No work to be done right now. This can happen at
// the end of the mark phase when there are still
// assists tapering off. Don't bother running a worker
// now because it'll just return immediately.
return nil
}
// Atoms decrease by the corresponding value , If the decrease is greater than or equal to 0 Then return to true, Otherwise return to false
decIfPositive := func(ptr *int64) bool {
if *ptr > 0 {
if atomic.Xaddint64(ptr, -1) >= 0 {
return true
}
// We lost a race
atomic.Xaddint64(ptr, +1)
}
return false
}
// Reduce dedicatedMarkWorkersNeeded, When successful, the mode of background marking task is Dedicated
// dedicatedMarkWorkersNeeded It is the present. P The quantity of 25% Remove the decimal point
// See startCycle function
if decIfPositive(&c.dedicatedMarkWorkersNeeded) {
// This P is now dedicated to marking until the end of
// the concurrent mark phase.
_p_.gcMarkWorkerMode = gcMarkWorkerDedicatedMode
} else {
// Reduce fractionalMarkWorkersNeeded, Success is the mode of background marking task Fractional
// If there is a number after the decimal point in the above calculation ( Can't divide ) be fractionalMarkWorkersNeeded by 1, Otherwise 0
// See startCycle function
// for instance , 4 individual P Will be executed 1 individual Dedicated The task of pattern , 5 individual P Will be executed 1 individual Dedicated Patterns and 1 individual Fractional The task of pattern
if !decIfPositive(&c.fractionalMarkWorkersNeeded) {
// No more workers are need right now.
return nil
}
// Press Dedicated Mode of task execution time judgment cpu Whether the occupancy rate exceeds the budget , Don't start when over
// This P has picked the token for the fractional worker.
// Is the GC currently under or at the utilization goal?
// If so, do more work.
//
// We used to check whether doing one time slice of work
// would remain under the utilization goal, but that has the
// effect of delaying work until the mutator has run for
// enough time slices to pay for the work. During those time
// slices, write barriers are enabled, so the mutator is running slower.
// Now instead we do the work whenever we're under or at the
// utilization work and pay for it by letting the mutator run later.
// This doesn't change the overall utilization averages, but it
// front loads the GC work so that the GC finishes earlier and
// write barriers can be turned off sooner, effectively giving
// the mutator a faster machine.
//
// The old, slower behavior can be restored by setting
// gcForcePreemptNS = forcePreemptNS.
const gcForcePreemptNS = 0
// TODO(austin): We could fast path this and basically
// eliminate contention on c.fractionalMarkWorkersNeeded by
// precomputing the minimum time at which it's worth
// next scheduling the fractional worker. Then Ps
// don't have to fight in the window where we've
// passed that deadline and no one has started the
// worker yet.
//
// TODO(austin): Shorter preemption interval for mark
// worker to improve fairness and give this
// finer-grained control over schedule?
now := nanotime() - gcController.markStartTime
then := now + gcForcePreemptNS
timeUsed := c.fractionalMarkTime + gcForcePreemptNS
if then > 0 && float64(timeUsed)/float64(then) > c.fractionalUtilizationGoal {
// Nope, we'd overshoot the utilization goal
atomic.Xaddint64(&c.fractionalMarkWorkersNeeded, +1)
return nil
}
_p_.gcMarkWorkerMode = gcMarkWorkerFractionalMode
}
// Schedule background marking task execution
// Run the background mark worker
gp := _p_.gcBgMarkWorker.ptr()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp
}
gcResetMarkState Function resets the tag related state :
// gcResetMarkState resets global state prior to marking (concurrent
// or STW) and resets the stack scan state of all Gs.
//
// This is safe to do without the world stopped because any Gs created
// during or after this will start out in the reset state.
func gcResetMarkState() {
// This may be called during a concurrent phase, so make sure
// allgs doesn't change.
lock(&allglock)
for _, gp := range allgs {
gp.gcscandone = false // set to true in gcphasework
gp.gcscanvalid = false // stack has not been scanned
gp.gcAssistBytes = 0
}
unlock(&allglock)
work.bytesMarked = 0
work.initialHeapLive = atomic.Load64(&memstats.heap_live)
work.markrootDone = false
}
stopTheWorldWithSema Function stops the world , This function must be in the g0 Run in :
// stopTheWorldWithSema is the core implementation of stopTheWorld.
// The caller is responsible for acquiring worldsema and disabling
// preemption first and then should stopTheWorldWithSema on the system
// stack:
//
// semacquire(&worldsema, 0)
// m.preemptoff = "reason"
// systemstack(stopTheWorldWithSema)
//
// When finished, the caller must either call startTheWorld or undo
// these three operations separately:
//
// m.preemptoff = ""
// systemstack(startTheWorldWithSema)
// semrelease(&worldsema)
//
// It is allowed to acquire worldsema once and then execute multiple
// startTheWorldWithSema/stopTheWorldWithSema pairs.
// Other P's are able to execute between successive calls to
// startTheWorldWithSema and stopTheWorldWithSema.
// Holding worldsema causes any other goroutines invoking
// stopTheWorld to block.
func stopTheWorldWithSema() {
_g_ := getg()
// If we hold a lock, then we won't be able to stop another M
// that is blocked trying to acquire the lock.
if _g_.m.locks > 0 {
throw("stopTheWorld: holding locks")
}
lock(&sched.lock)
// Need to stop P Number
sched.stopwait = gomaxprocs
// Set up gc Waiting for the mark , When scheduling, when you see this flag, you will enter the wait
atomic.Store(&sched.gcwaiting, 1)
// Preempt all running G
preemptall()
// Stop the current P
// stop current P
_g_.m.p.ptr().status = _Pgcstop // Pgcstop is only diagnostic.
// Reduce the need to stop P Number ( Current P Count one )
sched.stopwait--
// Grab everything in Psyscall State of P, Prevent them from participating in scheduling again
// try to retake all P's in Psyscall status
for i := 0; i < int(gomaxprocs); i++ {
p := allp[i]
s := p.status
if s == _Psyscall && atomic.Cas(&p.status, s, _Pgcstop) {
if trace.enabled {
traceGoSysBlock(p)
traceProcStop(p)
}
p.syscalltick++
sched.stopwait--
}
}
// Prevent all idle P Re participate in scheduling
// stop idle P's
for {
p := pidleget()
if p == nil {
break
}
p.status = _Pgcstop
sched.stopwait--
}
wait := sched.stopwait > 0
unlock(&sched.lock)
// If there's still something to stop P, Wait for them to stop
// wait for remaining P's to stop voluntarily
if wait {
for {
// Loop waiting for + Preempt all running G
// wait for 100us, then try to re-preempt in case of any races
if notetsleep(&sched.stopnote, 100*1000) {
noteclear(&sched.stopnote)
break
}
preemptall()
}
}
// Logical correctness check
// sanity checks
bad := ""
if sched.stopwait != 0 {
bad = "stopTheWorld: not stopped (stopwait != 0)"
} else {
for i := 0; i < int(gomaxprocs); i++ {
p := allp[i]
if p.status != _Pgcstop {
bad = "stopTheWorld: not stopped (status != _Pgcstop)"
}
}
}
if atomic.Load(&freezing) != 0 {
// Some other thread is panicking. This can cause the
// sanity checks above to fail if the panic happens in
// the signal handler on a stopped thread. Either way,
// we should halt this thread.
lock(&deadlock)
lock(&deadlock)
}
if bad != "" {
throw(bad)
}
// All of the running G It's going to be ready to run , And all of P Can't be M obtain
// That is to say, all go Code ( Except for the current ) Will stop running , And can't run new go Code
}
finishsweep_m Function will clean up the last round GC Not cleaned span, Make sure the last round GC Completed :
// finishsweep_m ensures that all spans are swept.
//
// The world must be stopped. This ensures there are no sweeps in
// progress.
//
//go:nowritebarrier
func finishsweep_m() {
// sweepone One of them will be taken out sweep Of span And then execute sweep
// The details will be in the following sweep Phase analysis
// Sweeping must be complete before marking commences, so
// sweep any unswept spans. If this is a concurrent GC, there
// shouldn't be any spans left to sweep, so this should finish
// instantly. If GC was forced before the concurrent sweep
// finished, there may be spans to sweep.
for sweepone() != ^uintptr(0) {
sweep.npausesweep++
}
// all span all sweep After completion , Start a new markbit Time
// This function implements span Of gcmarkBits and allocBits The key to the allocation and reuse of , The process is as follows
// - span Distribute gcmarkBits and allocBits
// - span complete sweep
// - primary allocBits No longer used
// - gcmarkBits Turn into allocBits
// - Assign a new gcmarkBits
// - Open a new markbit Time
// - span complete sweep, ditto
// - Open a new markbit Time
// - 2 Ages ago bitmap Will no longer be used , You can reuse these bitmap
nextMarkBitArenaEpoch()
}
clearpools The function cleans up sched.sudogcache and sched.deferpool, So that their memory can be recycled :
func clearpools() {
// clear sync.Pools
if poolcleanup != nil {
poolcleanup()
}
// Clear central sudog cache.
// Leave per-P caches alone, they have strictly bounded size.
// Disconnect cached list before dropping it on the floor,
// so that a dangling ref to one entry does not pin all of them.
lock(&sched.sudoglock)
var sg, sgnext *sudog
for sg = sched.sudogcache; sg != nil; sg = sgnext {
sgnext = sg.next
sg.next = nil
}
sched.sudogcache = nil
unlock(&sched.sudoglock)
// Clear central defer pools.
// Leave per-P pools alone, they have strictly bounded size.
lock(&sched.deferlock)
for i := range sched.deferpool {
// disconnect cached list before dropping it on the floor,
// so that a dangling ref to one entry does not pin all of them.
var d, dlink *_defer
for d = sched.deferpool[i]; d != nil; d = dlink {
dlink = d.link
d.link = nil
}
sched.deferpool[i] = nil
}
unlock(&sched.deferlock)
}
startCycle Mark the beginning of a new round of GC:
// startCycle resets the GC controller's state and computes estimates
// for a new GC cycle. The caller must hold worldsema.
func (c *gcControllerState) startCycle() {
c.scanWork = 0
c.bgScanCredit = 0
c.assistTime = 0
c.dedicatedMarkTime = 0
c.fractionalMarkTime = 0
c.idleMarkTime = 0
// camouflage heap_marked The value of if gc_trigger The value is very small. , Prevent the back face triggerRatio Make the wrong adjustments
// If this is the first GC cycle or we're operating on a very
// small heap, fake heap_marked so it looks like gc_trigger is
// the appropriate growth from heap_marked, even though the
// real heap_marked may not have a meaningful value (on the
// first cycle) or may be much smaller (resulting in a large
// error response).
if memstats.gc_trigger <= heapminimum {
memstats.heap_marked = uint64(float64(memstats.gc_trigger) / (1 + memstats.triggerRatio))
}
// Recalculate next_gc, Be careful next_gc The calculation of the following gc_trigger Dissimilarity
// Re-compute the heap goal for this cycle in case something
// changed. This is the same calculation we use elsewhere.
memstats.next_gc = memstats.heap_marked + memstats.heap_marked*uint64(gcpercent)/100
if gcpercent < 0 {
memstats.next_gc = ^uint64(0)
}
// Make sure next_gc and heap_live There is at least 1MB
// Ensure that the heap goal is at least a little larger than
// the current live heap size. This may not be the case if GC
// start is delayed or if the allocation that pushed heap_live
// over gc_trigger is large or if the trigger is really close to
// GOGC. Assist is proportional to this distance, so enforce a
// minimum distance, even if it means going over the GOGC goal
// by a tiny bit.
if memstats.next_gc < memstats.heap_live+1024*1024 {
memstats.next_gc = memstats.heap_live + 1024*1024
}
// Calculates the number of background marking tasks that can be performed simultaneously
// dedicatedMarkWorkersNeeded be equal to P The quantity of 25% Remove the decimal point
// If it can be divided fractionalMarkWorkersNeeded be equal to 0 Or equal to 1
// totalUtilizationGoal yes GC Occupied P The target value ( for example P Altogether 5 The goal is 1.25 individual P)
// fractionalUtilizationGoal yes Fractiona The task of the pattern occupies P The target value ( for example P Altogether 5 The goal is 0.25 individual P)
// Compute the total mark utilization goal and divide it among
// dedicated and fractional workers.
totalUtilizationGoal := float64(gomaxprocs) * gcGoalUtilization
c.dedicatedMarkWorkersNeeded = int64(totalUtilizationGoal)
c.fractionalUtilizationGoal = totalUtilizationGoal - float64(c.dedicatedMarkWorkersNeeded)
if c.fractionalUtilizationGoal > 0 {
c.fractionalMarkWorkersNeeded = 1
} else {
c.fractionalMarkWorkersNeeded = 0
}
// Reset P Auxiliary in GC Time statistics used
// Clear per-P state
for _, p := range &allp {
if p == nil {
break
}
p.gcAssistTime = 0
}
// Computational AIDS GC Parameters of
// Refer to the calculation above assistWorkPerByte Analysis of the formula of
// Compute initial values for controls that are updated
// throughout the cycle.
c.revise()
if debug.gcpacertrace > 0 {
print("pacer: assist ratio=", c.assistWorkPerByte,
" (scan ", memstats.heap_scan>>20, " MB in ",
work.initialHeapLive>>20, "->",
memstats.next_gc>>20, " MB)",
" workers=", c.dedicatedMarkWorkersNeeded,
"+", c.fractionalMarkWorkersNeeded, "n")
}
}
setGCPhase The function will modify to represent the current GC The global variables of the stage and Whether to open the write barrier Global variable of :
//go:nosplit
func setGCPhase(x uint32) {
atomic.Store(&gcphase, x)
writeBarrier.needed = gcphase == _GCmark || gcphase == _GCmarktermination
writeBarrier.enabled = writeBarrier.needed || writeBarrier.cgo
}
gcBgMarkPrepare Function resets the count of background marking tasks :
// gcBgMarkPrepare sets up state for background marking.
// Mutator assists must not yet be enabled.
func gcBgMarkPrepare() {
// Background marking will stop when the work queues are empty
// and there are no more workers (note that, since this is
// concurrent, this may be a transient state, but mark
// termination will clean it up). Between background workers
// and assists, we don't really know how many workers there
// will be, so we pretend to have an arbitrarily large number
// of workers, almost all of which are "waiting". While a
// worker is working it decrements nwait. If nproc == nwait,
// there are no workers.
work.nproc = ^uint32(0)
work.nwait = ^uint32(0)
}
gcMarkRootPrepare Function will calculate the number of tasks to scan the root object :
// gcMarkRootPrepare queues root scanning jobs (stacks, globals, and
// some miscellany) and initializes scanning-related state.
//
// The caller must have call gcCopySpans().
//
// The world must be stopped.
//
//go:nowritebarrier
func gcMarkRootPrepare() {
// Release mcache All in span The task of , Only in the completion marking phase (mark termination) In the implementation of
if gcphase == _GCmarktermination {
work.nFlushCacheRoots = int(gomaxprocs)
} else {
work.nFlushCacheRoots = 0
}
// Calculation block A function of quantity , rootBlockBytes yes 256KB
// Compute how many data and BSS root blocks there are.
nBlocks := func(bytes uintptr) int {
return int((bytes + rootBlockBytes - 1) / rootBlockBytes)
}
work.nDataRoots = 0
work.nBSSRoots = 0
// data and bss Every round GC Just one scan
// parallel GC Will scan in the background marking task , Complete the marking phase (mark termination) Don't scan
// Nonparallel GC It's going to be in the completion tag phase (mark termination) Medium scan
// Only scan globals once per cycle; preferably concurrently.
if !work.markrootDone {
// Calculate the number of tasks that scan global variables that are readable and writable
for _, datap := range activeModules() {
nDataRoots := nBlocks(datap.edata - datap.data)
if nDataRoots > work.nDataRoots {
work.nDataRoots = nDataRoots
}
}
// Calculate the number of tasks that scan read-only global variables
for _, datap := range activeModules() {
nBSSRoots := nBlocks(datap.ebss - datap.bss)
if nBSSRoots > work.nBSSRoots {
work.nBSSRoots = nBSSRoots
}
}
}
// span Medium finalizer And each G The stack of each round GC Just one scan
// ditto
if !work.markrootDone {
// Computational scan span Medium finalizer Number of tasks
// On the first markroot, we need to scan span roots.
// In concurrent GC, this happens during concurrent
// mark and we depend on addfinalizer to ensure the
// above invariants for objects that get finalizers
// after concurrent mark. In STW GC, this will happen
// during mark termination.
//
// We're only interested in scanning the in-use spans,
// which will all be swept at this point. More spans
// may be added to this list during concurrent GC, but
// we only care about spans that were allocated before
// this mark phase.
work.nSpanRoots = mheap_.sweepSpans[mheap_.sweepgen/2%2].numBlocks()
// Calculate and scan each G The number of tasks in the stack of
// On the first markroot, we need to scan all Gs. Gs
// may be created after this point, but it's okay that
// we ignore them because they begin life without any
// roots, so there's nothing to scan, and any roots
// they create during the concurrent phase will be
// scanned during mark termination. During mark
// termination, allglen isn't changing, so we'll scan
// all Gs.
work.nStackRoots = int(atomic.Loaduintptr(&allglen))
} else {
// We've already scanned span roots and kept the scan
// up-to-date during concurrent mark.
work.nSpanRoots = 0
// The hybrid barrier ensures that stacks can't
// contain pointers to unmarked objects, so on the
// second markroot, there's no need to scan stacks.
work.nStackRoots = 0
if debug.gcrescanstacks > 0 {
// Scan stacks anyway for debugging.
work.nStackRoots = int(atomic.Loaduintptr(&allglen))
}
}
// Calculate the total number of tasks
// The background marking task will be on markrootNext Increasing the number of atoms , To decide which task to do
// It's a clever way to lock free queues with numbers , Even though google The engineer doesn't think it's good ( Look at the back markroot Analysis of functions )
work.markrootNext = 0
work.markrootJobs = uint32(fixedRootCount + work.nFlushCacheRoots + work.nDataRoots + work.nBSSRoots + work.nSpanRoots + work.nStackRoots)
}
gcMarkTinyAllocs The function marks all tiny alloc Objects waiting to be merged :
// gcMarkTinyAllocs greys all active tiny alloc blocks.
//
// The world must be stopped.
func gcMarkTinyAllocs() {
for _, p := range &allp {
if p == nil || p.status == _Pdead {
break
}
c := p.mcache
if c == nil || c.tiny == 0 {
continue
}
// Mark each one P Medium mcache Medium tiny
// Above mallocgc You can see in the function tiny Is the object currently waiting to be merged
_, hbits, span, objIndex := heapBitsForObject(c.tiny, 0, 0)
gcw := &p.gcw
// Mark an object alive , And add it to the tag queue ( The object turns gray )
greyobject(c.tiny, 0, 0, hbits, span, gcw, objIndex)
// gcBlackenPromptly Variable indicates whether local queues are currently disabled , If disabled, mark the task flush To global queue
if gcBlackenPromptly {
gcw.dispose()
}
}
}
startTheWorldWithSema Function will restart the world :
func startTheWorldWithSema() {
_g_ := getg()
// prohibit G Be seized
_g_.m.locks++ // disable preemption because it can be holding p in a local var
// Judge the received network events (fd Readable, writable or error ) And add the corresponding G To the queue to be run
gp := netpoll(false) // non-blocking
injectglist(gp)
// Decide whether to start gc helper
add := needaddgcproc()
lock(&sched.lock)
// If you ask for a change gomaxprocs Then adjust P The number of
// procresize Will return to have a running task P The linked list of
procs := gomaxprocs
if newprocs != 0 {
procs = newprocs
newprocs = 0
}
p1 := procresize(procs)
// Cancel GC Waiting for the mark
sched.gcwaiting = 0
// If sysmon Wake it up while waiting
if sched.sysmonwait != 0 {
sched.sysmonwait = 0
notewakeup(&sched.sysmonnote)
}
unlock(&sched.lock)
// Wake up a task that can be run P
for p1 != nil {
p := p1
p1 = p1.link.ptr()
if p.m != 0 {
mp := p.m.ptr()
p.m = 0
if mp.nextp != 0 {
throw("startTheWorld: inconsistent mp->nextp")
}
mp.nextp.set(p)
notewakeup(&mp.park)
} else {
// Start M to run P. Do not start another M below.
newm(nil, p)
add = false
}
}
// If there's something free P, And there's no spinning M Wake up or create a M
// Wakeup an additional proc in case we have excessive runnable goroutines
// in local queues or in the global queue. If we don't, the proc will park itself.
// If we have lots of excessive work, resetspinning will unpark additional procs as necessary.
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 {
wakep()
}
// start-up gc helper
if add {
// If GC could have used another helper proc, start one now,
// in the hope that it will be available next time.
// It would have been even better to start it before the collection,
// but doing so requires allocating memory, so it's tricky to
// coordinate. This lazy approach works out in practice:
// we don't mind if the first couple gc rounds don't have quite
// the maximum number of procs.
newm(mhelpgc, nil)
}
// allow G Be seized
_g_.m.locks--
// If at present G Ask to be preempted and try again
if _g_.m.locks == 0 && _g_.preempt { // restore the preemption request in case we've cleared it in newstack
_g_.stackguard0 = stackPreempt
}
}
After restarting the world M Will restart scheduling , Scheduling will take precedence over the above mentioned findRunnableGCWorker Function lookup task , And then there was about 25% Of P Run background marking task .
The function of background marking task is gcBgMarkWorker:
func gcBgMarkWorker(_p_ *p) {
gp := getg()
// Used to retrieve after hibernation P The structure of
type parkInfo struct {
m muintptr // Release this m on park.
attach puintptr // If non-nil, attach to this p on park.
}
// We pass park to a gopark unlock function, so it can't be on
// the stack (see gopark). Prevent deadlock from recursively
// starting GC by disabling preemption.
gp.m.preemptoff = "GC worker init"
park := new(parkInfo)
gp.m.preemptoff = ""
// Set current M And it's forbidden to seize
park.m.set(acquirem())
// Set current P( Need to be associated with P)
park.attach.set(_p_)
// notice gcBgMarkStartWorkers You can continue to deal with
// Inform gcBgMarkStartWorkers that this worker is ready.
// After this point, the background mark worker is scheduled
// cooperatively by gcController.findRunnable. Hence, it must
// never be preempted, as this would put it into _Grunnable
// and put it on a run queue. Instead, when the preempt flag
// is set, this puts itself into _Gwaiting to be woken up by
// gcController.findRunnable at the appropriate time.
notewakeup(&work.bgMarkReady)
for {
// Let the current G Go to sleep
// Go to sleep until woken by gcController.findRunnable.
// We can't releasem yet since even the call to gopark
// may be preempted.
gopark(func(g *g, parkp unsafe.Pointer) bool {
park := (*parkInfo)(parkp)
// Re allow preemption
// The worker G is no longer running, so it's
// now safe to allow preemption.
releasem(park.m.ptr())
// Set the associated P
// Put the current G Set to P Of gcBgMarkWorker member , The next time findRunnableGCWorker Will use
// Do not sleep when setting failure
// If the worker isn't attached to its P,
// attach now. During initialization and after
// a phase change, the worker may have been
// running on a different P. As soon as we
// attach, the owner P may schedule the
// worker, so this must be done after the G is
// stopped.
if park.attach != 0 {
p := park.attach.ptr()
park.attach.set(nil)
// cas the worker because we may be
// racing with a new worker starting
// on this P.
if !p.gcBgMarkWorker.cas(0, guintptr(unsafe.Pointer(g))) {
// The P got a new worker.
// Exit this worker.
return false
}
}
return true
}, unsafe.Pointer(park), "GC worker (idle)", traceEvGoBlock, 0)
// Check P Of gcBgMarkWorker Whether with the current G Agreement , End current task when inconsistent
// Loop until the P dies and disassociates this
// worker (the P may later be reused, in which case
// it will get a new worker) or we failed to associate.
if _p_.gcBgMarkWorker.ptr() != gp {
break
}
// prohibit G Be seized
// Disable preemption so we can use the gcw. If the
// scheduler wants to preempt us, we'll stop draining,
// dispose the gcw, and then preempt.
park.m.set(acquirem())
if gcBlackenEnabled == 0 {
throw("gcBgMarkWorker: blackening not enabled")
}
// Record the start time
startTime := nanotime()
decnwait := atomic.Xadd(&work.nwait, -1)
if decnwait == work.nproc {
println("runtime: work.nwait=", decnwait, "work.nproc=", work.nproc)
throw("work.nwait was > work.nproc")
}
// Switch to g0 function
systemstack(func() {
// Set up G Is waiting so that its stack can be scanned ( Two background marking tasks can scan each other's stacks )
// Mark our goroutine preemptible so its stack
// can be scanned. This lets two mark workers
// scan each other (otherwise, they would
// deadlock). We must not modify anything on
// the G stack. However, stack shrinking is
// disabled for mark workers, so it is safe to
// read from the G stack.
casgstatus(gp, _Grunning, _Gwaiting)
// Determine the mode of background marking task
switch _p_.gcMarkWorkerMode {
default:
throw("gcBgMarkWorker: unexpected gcMarkWorkerMode")
case gcMarkWorkerDedicatedMode:
// In this mode P You should focus on the execution of tags
// Execution tag , Until they're robbed , And we need to calculate the amount of background scanning to reduce the auxiliary GC And wake up the waiting G
gcDrain(&_p_.gcw, gcDrainUntilPreempt|gcDrainFlushBgCredit)
// When preempted, all of the G All kicked to the global run queue
if gp.preempt {
// We were preempted. This is
// a useful signal to kick
// everything out of the run
// queue so it can run
// somewhere else.
lock(&sched.lock)
for {
gp, _ := runqget(_p_)
if gp == nil {
break
}
globrunqput(gp)
}
unlock(&sched.lock)
}
// Continue with tag execution , Until there are no more missions , And we need to calculate the amount of background scanning to reduce the auxiliary GC And wake up the waiting G
// Go back to draining, this time
// without preemption.
gcDrain(&_p_.gcw, gcDrainNoBlock|gcDrainFlushBgCredit)
case gcMarkWorkerFractionalMode:
// In this mode P Tags should be properly executed
// Execution tag , Until they're robbed , And we need to calculate the amount of background scanning to reduce the auxiliary GC And wake up the waiting G
gcDrain(&_p_.gcw, gcDrainUntilPreempt|gcDrainFlushBgCredit)
case gcMarkWorkerIdleMode:
// In this mode P Mark only when idle
// Execution tag , Until it is preempted or reaches a certain amount , And we need to calculate the amount of background scanning to reduce the auxiliary GC And wake up the waiting G
gcDrain(&_p_.gcw, gcDrainIdle|gcDrainUntilPreempt|gcDrainFlushBgCredit)
}
// recovery G State to run
casgstatus(gp, _Gwaiting, _Grunning)
})
// If it is marked to disable local tag queues flush To the global tag queue
// If we are nearing the end of mark, dispose
// of the cache promptly. We must do this
// before signaling that we're no longer
// working so that other workers can't observe
// no workers and no work while we have this
// cached, and before we compute done.
if gcBlackenPromptly {
_p_.gcw.dispose()
}
// Add up the time taken
// Account for time.
duration := nanotime() - startTime
switch _p_.gcMarkWorkerMode {
case gcMarkWorkerDedicatedMode:
atomic.Xaddint64(&gcController.dedicatedMarkTime, duration)
atomic.Xaddint64(&gcController.dedicatedMarkWorkersNeeded, 1)
case gcMarkWorkerFractionalMode:
atomic.Xaddint64(&gcController.fractionalMarkTime, duration)
atomic.Xaddint64(&gcController.fractionalMarkWorkersNeeded, 1)
case gcMarkWorkerIdleMode:
atomic.Xaddint64(&gcController.idleMarkTime, duration)
}
// Was this the last worker and did we run out
// of work?
incnwait := atomic.Xadd(&work.nwait, +1)
if incnwait > work.nproc {
println("runtime: p.gcMarkWorkerMode=", _p_.gcMarkWorkerMode,
"work.nwait=", incnwait, "work.nproc=", work.nproc)
throw("work.nwait > work.nproc")
}
// Determine whether all background marking tasks have been completed , And there are no more tasks
// If this worker reached a background mark completion
// point, signal the main GC goroutine.
if incnwait == work.nproc && !gcMarkWorkAvailable(nil) {
// Cancel and P The associated
// Make this G preemptible and disassociate it
// as the worker for this P so
// findRunnableGCWorker doesn't try to
// schedule it.
_p_.gcBgMarkWorker.set(nil)
// allow G Be seized
releasem(park.m.ptr())
// Ready to enter the completion marking phase
gcMarkDone()
// It's reconnected before hibernation P
// Because it's allowed to be preempted , When you get here, it may become something else P
// If you re relate P If you fail, the task will end
// Disable preemption and prepare to reattach
// to the P.
//
// We may be running on a different P at this
// point, so we can't reattach until this G is
// parked.
park.m.set(acquirem())
park.attach.set(_p_)
}
}
}
gcDrain Function is used to execute the tag :
// gcDrain scans roots and objects in work buffers, blackening grey
// objects until all roots and work buffers have been drained.
//
// If flags&gcDrainUntilPreempt != 0, gcDrain returns when g.preempt
// is set. This implies gcDrainNoBlock.
//
// If flags&gcDrainIdle != 0, gcDrain returns when there is other work
// to do. This implies gcDrainNoBlock.
//
// If flags&gcDrainNoBlock != 0, gcDrain returns as soon as it is
// unable to get more work. Otherwise, it will block until all
// blocking calls are blocked in gcDrain.
//
// If flags&gcDrainFlushBgCredit != 0, gcDrain flushes scan work
// credit to gcController.bgScanCredit every gcCreditSlack units of
// scan work.
//
//go:nowritebarrier
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
if !writeBarrier.needed {
throw("gcDrain phase incorrect")
}
gp := getg().m.curg
// Do you want to return when you see the preemption sign
preemptible := flags&gcDrainUntilPreempt != 0
// Whether to wait for a task when there is no task
blocking := flags&(gcDrainUntilPreempt|gcDrainIdle|gcDrainNoBlock) == 0
// Whether to calculate the amount of background scanning to reduce auxiliary GC And wake up the waiting G
flushBgCredit := flags&gcDrainFlushBgCredit != 0
// Whether to perform only a certain amount of work
idle := flags&gcDrainIdle != 0
// Record the initial number of scans
initScanWork := gcw.scanWork
// scanning idleCheckThreshold(100000) Check to see if you want to return
// idleCheck is the scan work at which to perform the next
// idle check with the scheduler.
idleCheck := initScanWork + idleCheckThreshold
// If the root object is not finished scanning , Scan the root object first
// Drain root marking jobs.
if work.markrootNext < work.markrootJobs {
// If it's marked preemptible, Cycle until it's taken
for !(preemptible && gp.preempt) {
// Take a value from the root object scan queue ( Atoms increase in number )
job := atomic.Xadd(&work.markrootNext, +1) - 1
if job >= work.markrootJobs {
break
}
// Perform root object scanning
markroot(gcw, job)
// If it is idle Patterns and there are other jobs , Then return to
if idle && pollWork() {
goto done
}
}
}
// The root object is already in the tag queue , Consumer tag queue
// If it's marked preemptible, Cycle until it's taken
// Drain heap marking jobs.
for !(preemptible && gp.preempt) {
// If the global tag queue is empty , Divide part of the local tag queue
// ( If wbuf2 Move if not empty wbuf2 In the past , Otherwise move wbuf1 Half of the past )
// Try to keep work available on the global queue. We used to
// check if there were waiting workers, but it's better to
// just keep work available than to make workers wait. In the
// worst case, we'll do O(log(_WorkbufSize)) unnecessary
// balances.
if work.full == 0 {
gcw.balance()
}
// Get the object from the local tag queue , If not, it will be obtained from the global tag queue
var b uintptr
if blocking {
// Blocking access
b = gcw.get()
} else {
// Non blocking access
b = gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
}
}
// Can't get the object , Tag queue is empty , Out of the loop
if b == 0 {
// work barrier reached or tryGet failed.
break
}
// Scan the acquired object
scanobject(b, gcw)
// If you've scanned a certain number of objects (gcCreditSlack The value of is 2000)
// Flush background scan work credit to the global
// account if we've accumulated enough locally so
// mutator assists can draw on it.
if gcw.scanWork >= gcCreditSlack {
// Add the number of objects scanned to the global
atomic.Xaddint64(&gcController.scanWork, gcw.scanWork)
// Less assistance GC The workload and wake up waiting for G
if flushBgCredit {
gcFlushBgCredit(gcw.scanWork - initScanWork)
initScanWork = 0
}
idleCheck -= gcw.scanWork
gcw.scanWork = 0
// If it is idle Mode and the scanning amount of the check is reached , Check for other tasks (G), If so, jump out of the loop
if idle && idleCheck <= 0 {
idleCheck += idleCheckThreshold
if pollWork() {
break
}
}
}
}
// In blocking mode, write barriers are not allowed after this
// point because we must preserve the condition that the work
// buffers are empty.
done:
// Add the number of objects scanned to the global
// Flush remaining scan work credit.
if gcw.scanWork > 0 {
atomic.Xaddint64(&gcController.scanWork, gcw.scanWork)
// Less assistance GC The workload and wake up waiting for G
if flushBgCredit {
gcFlushBgCredit(gcw.scanWork - initScanWork)
}
gcw.scanWork = 0
}
}
markroot Function is used to perform a root object scan :
// markroot scans the i'th root.
//
// Preemption must be disabled (because this uses a gcWork).
//
// nowritebarrier is only advisory here.
//
//go:nowritebarrier
func markroot(gcw *gcWork, i uint32) {
// Determine which task the extracted value corresponds to
// (google 's engineers find this approach ridiculous )
// TODO(austin): This is a bit ridiculous. Compute and store
// the bases in gcMarkRootPrepare instead of the counts.
baseFlushCache := uint32(fixedRootCount)
baseData := baseFlushCache + uint32(work.nFlushCacheRoots)
baseBSS := baseData + uint32(work.nDataRoots)
baseSpans := baseBSS + uint32(work.nBSSRoots)
baseStacks := baseSpans + uint32(work.nSpanRoots)
end := baseStacks + uint32(work.nStackRoots)
// Note: if you add a case here, please also update heapdump.go:dumproots.
switch {
// Release mcache All in span, requirement STW
case baseFlushCache <= i && i < baseData:
flushmcache(int(i - baseFlushCache))
// Scan global variables for read and write
// It's just scanning here i Corresponding block, When scanning, the input contains the pointer bitmap data
case baseData <= i && i < baseBSS:
for _, datap := range activeModules() {
markrootBlock(datap.data, datap.edata-datap.data, datap.gcdatamask.bytedata, gcw, int(i-baseData))
}
// Scan read-only global variables
// It's just scanning here i Corresponding block, When scanning, the input contains the pointer bitmap data
case baseBSS <= i && i < baseSpans:
for _, datap := range activeModules() {
markrootBlock(datap.bss, datap.ebss-datap.bss, datap.gcbssmask.bytedata, gcw, int(i-baseBSS))
}
// Scan the constructor queue
case i == fixedRootFinalizers:
// Only do this once per GC cycle since we don't call
// queuefinalizer during marking.
if work.markrootDone {
break
}
for fb := allfin; fb != nil; fb = fb.alllink {
cnt := uintptr(atomic.Load(&fb.cnt))
scanblock(uintptr(unsafe.Pointer(&fb.fin[0])), cnt*unsafe.Sizeof(fb.fin[0]), &finptrmask[0], gcw)
}
// Release suspended G The stack
case i == fixedRootFreeGStacks:
// Only do this once per GC cycle; preferably
// concurrently.
if !work.markrootDone {
// Switch to the system stack so we can call
// stackfree.
systemstack(markrootFreeGStacks)
}
// Scan each one span A special object in ( Destructor list )
case baseSpans <= i && i < baseStacks:
// mark MSpan.specials
markrootSpans(gcw, int(i-baseSpans))
// Scan each one G The stack
default:
// Get the G
// the rest is scanning goroutine stacks
var gp *g
if baseStacks <= i && i < end {
gp = allgs[i-baseStacks]
} else {
throw("markroot: bad index")
}
// Record the time of waiting to start
// remember when we've first observed the G blocked
// needed only to output in traceback
status := readgstatus(gp) // We are not in a scan state
if (status == _Gwaiting || status == _Gsyscall) && gp.waitsince == 0 {
gp.waitsince = work.tstart
}
// Switch to g0 function ( You may sweep to your own stack )
// scang must be done on the system stack in case
// we're trying to scan our own stack.
systemstack(func() {
// Determine whether the scanned stack is its own
// If this is a self-scan, put the user G in
// _Gwaiting to prevent self-deadlock. It may
// already be in _Gwaiting if this is a mark
// worker or we're in mark termination.
userG := getg().m.curg
selfScan := gp == userG && readgstatus(userG) == _Grunning
// If you are scanning your stack, switch the state to wait to prevent deadlock
if selfScan {
casgstatus(userG, _Grunning, _Gwaiting)
userG.waitreason = "garbage collection scan"
}
// scanning G The stack
// TODO: scang blocks until gp's stack has
// been scanned, which may take a while for
// running goroutines. Consider doing this in
// two phases where the first is non-blocking:
// we scan the stacks we can and ask running
// goroutines to scan themselves; and the
// second blocks.
scang(gp, gcw)
// If you are scanning your stack, switch the state back to running
if selfScan {
casgstatus(userG, _Gwaiting, _Grunning)
}
})
}
}
scang Function is responsible for scanning G The stack :
// scang blocks until gp's stack has been scanned.
// It might be scanned by scang or it might be scanned by the goroutine itself.
// Either way, the stack scan has completed when scang returns.
func scang(gp *g, gcw *gcWork) {
// Invariant; we (the caller, markroot for a specific goroutine) own gp.gcscandone.
// Nothing is racing with us now, but gcscandone might be set to true left over
// from an earlier round of stack scanning (we scan twice per GC).
// We use gcscandone to record whether the scan has been done during this round.
// Mark scan not complete
gp.gcscandone = false
// See http://golang.org/cl/21503 for justification of the yield delay.
const yieldDelay = 10 * 1000
var nextYield int64
// Cycle until the scan is complete
// Endeavor to get gcscandone set to true,
// either by doing the stack scan ourselves or by coercing gp to scan itself.
// gp.gcscandone can transition from false to true when we're not looking
// (if we asked for preemption), so any time we lock the status using
// castogscanstatus we have to double-check that the scan is still not done.
loop:
for i := 0; !gp.gcscandone; i++ {
// Judge G Current state
switch s := readgstatus(gp); s {
default:
dumpgstatus(gp)
throw("stopg: invalid status")
// G Has suspended , There's no need to scan it
case _Gdead:
// No stack.
gp.gcscandone = true
break loop
// G The stack is expanding , Try again next time
case _Gcopystack:
// Stack being switched. Go around again.
// G It's not running , First, you need to prevent it from running
case _Grunnable, _Gsyscall, _Gwaiting:
// Claim goroutine by setting scan bit.
// Racing with execution or readying of gp.
// The scan bit keeps them from running
// the goroutine until we're done.
if castogscanstatus(gp, s, s|_Gscan) {
// Scan the stack of an atom when it switches state successfully
if !gp.gcscandone {
scanstack(gp, gcw)
gp.gcscandone = true
}
// recovery G The state of , And out of the loop
restartg(gp)
break loop
}
// G Scanning itself , Wait for the scan to finish
case _Gscanwaiting:
// newstack is doing a scan for us right now. Wait.
// G Running
case _Grunning:
// Goroutine running. Try to preempt execution so it can scan itself.
// The preemption handler (in newstack) does the actual scan.
// If there is already a preemption request , If we succeed, we will deal with it
// Optimization: if there is already a pending preemption request
// (from the previous loop iteration), don't bother with the atomics.
if gp.preemptscan && gp.preempt && gp.stackguard0 == stackPreempt {
break
}
// preemption G, When you succeed in seizing G It scans itself
// Ask for preemption and self scan.
if castogscanstatus(gp, _Grunning, _Gscanrunning) {
if !gp.gcscandone {
gp.preemptscan = true
gp.preempt = true
gp.stackguard0 = stackPreempt
}
casfrom_Gscanstatus(gp, _Gscanrunning, _Grunning)
}
}
// The first round of dormancy 10 millisecond , The second round of dormancy 5 millisecond
if i == 0 {
nextYield = nanotime() + yieldDelay
}
if nanotime() < nextYield {
procyield(10)
} else {
osyield()
nextYield = nanotime() + yieldDelay/2
}
}
// Scan complete , Request to cancel preemptive scan
gp.preemptscan = false // cancel scan request if no longer needed
}
Set up preemptscan after , They are seizing G When successful, it will call scanstack Scan its own stack , Specific code ad locum .
The function used to scan the stack is scanstack:
// scanstack scans gp's stack, greying all pointers found on the stack.
//
// scanstack is marked go:systemstack because it must not be preempted
// while using a workbuf.
//
//go:nowritebarrier
//go:systemstack
func scanstack(gp *g, gcw *gcWork) {
if gp.gcscanvalid {
return
}
if readgstatus(gp)&_Gscan == 0 {
print("runtime:scanstack: gp=", gp, ", goid=", gp.goid, ", gp->atomicstatus=", hex(readgstatus(gp)), "n")
throw("scanstack - bad status")
}
switch readgstatus(gp) &^ _Gscan {
default:
print("runtime: gp=", gp, ", goid=", gp.goid, ", gp->atomicstatus=", readgstatus(gp), "n")
throw("mark - bad status")
case _Gdead:
return
case _Grunning:
print("runtime: gp=", gp, ", goid=", gp.goid, ", gp->atomicstatus=", readgstatus(gp), "n")
throw("scanstack: goroutine not stopped")
case _Grunnable, _Gsyscall, _Gwaiting:
// ok
}
if gp == getg() {
throw("can't scan our own stack")
}
mp := gp.m
if mp != nil && mp.helpgc != 0 {
throw("can't scan gchelper stack")
}
// Shrink the stack if not much of it is being used. During
// concurrent GC, we can do this during concurrent mark.
if !work.markrootDone {
shrinkstack(gp)
}
// Scan the stack.
var cache pcvalueCache
scanframe := func(frame *stkframe, unused unsafe.Pointer) bool {
// scanframeworker According to the code address (pc) Get function information
// And then find the function information in stackmap.bytedata, It stores where there are pointers on the stack of functions
// Call again scanblock To scan the stack space of functions , At the same time, the parameters of the function are scanned in this way
scanframeworker(frame, &cache, gcw)
return true
}
// Enumerate all call frames , Respectively called scanframe function
gentraceback(^uintptr(0), ^uintptr(0), 0, gp, 0, nil, 0x7fffffff, scanframe, nil, 0)
// Enumerate all defer Call frame of , Respectively called scanframe function
tracebackdefers(gp, scanframe, nil)
gp.gcscanvalid = true
}
scanblock Function is a general scan function , Scanning global variables and stack space will use it , and scanobject The difference is bitmap It needs to be passed in manually :
// scanblock scans b as scanobject would, but using an explicit
// pointer bitmap instead of the heap bitmap.
//
// This is used to scan non-heap roots, so it does not update
// gcw.bytesMarked or gcw.scanWork.
//
//go:nowritebarrier
func scanblock(b0, n0 uintptr, ptrmask *uint8, gcw *gcWork) {
// Use local copies of original parameters, so that a stack trace
// due to one of the throws below shows the original block
// base and extent.
b := b0
n := n0
arena_start := mheap_.arena_start
arena_used := mheap_.arena_used
// Enumerate scanned addresses
for i := uintptr(0); i < n; {
// find bitmap Corresponding byte
// Find bits for the next word.
bits := uint32(*addb(ptrmask, i/(sys.PtrSize*8)))
if bits == 0 {
i += sys.PtrSize * 8
continue
}
// enumeration byte
for j := 0; j < 8 && i < n; j++ {
// If the address contains pointers
if bits&1 != 0 {
// Mark the object at that address alive , And add it to the tag queue ( The object turns gray )
// Same work as in scanobject; see comments there.
obj := *(*uintptr)(unsafe.Pointer(b + i))
if obj != 0 && arena_start <= obj && obj < arena_used {
// Find the corresponding object span and bitmap
if obj, hbits, span, objIndex := heapBitsForObject(obj, b, i); obj != 0 {
// Mark an object alive , And add it to the tag queue ( The object turns gray )
greyobject(obj, b, i, hbits, span, gcw, objIndex)
}
}
}
// Handle the next pointer, the next bit
bits >>= 1
i += sys.PtrSize
}
}
}
greyobject Used to mark the survival of an object , And add it to the tag queue ( The object turns gray ):
// obj is the start of an object with mark mbits.
// If it isn't already marked, mark it and enqueue into gcw.
// base and off are for debugging only and could be removed.
//go:nowritebarrierrec
func greyobject(obj, base, off uintptr, hbits heapBits, span *mspan, gcw *gcWork, objIndex uintptr) {
// obj should be start of allocation, and so must be at least pointer-aligned.
if obj&(sys.PtrSize-1) != 0 {
throw("greyobject: obj not pointer-aligned")
}
mbits := span.markBitsForIndex(objIndex)
if useCheckmark {
// checkmark It's a mechanism for checking that all reachable objects are marked correctly , Debug only
if !mbits.isMarked() {
printlock()
print("runtime:greyobject: checkmarks finds unexpected unmarked object obj=", hex(obj), "n")
print("runtime: found obj at *(", hex(base), "+", hex(off), ")n")
// Dump the source (base) object
gcDumpObject("base", base, off)
// Dump the object
gcDumpObject("obj", obj, ^uintptr(0))
getg().m.traceback = 2
throw("checkmark found unmarked object")
}
if hbits.isCheckmarked(span.elemsize) {
return
}
hbits.setCheckmarked(span.elemsize)
if !hbits.isCheckmarked(span.elemsize) {
throw("setCheckmarked and isCheckmarked disagree")
}
} else {
if debug.gccheckmark > 0 && span.isFree(objIndex) {
print("runtime: marking free object ", hex(obj), " found at *(", hex(base), "+", hex(off), ")n")
gcDumpObject("base", base, off)
gcDumpObject("obj", obj, ^uintptr(0))
getg().m.traceback = 2
throw("marking free object")
}
// If the object is in span Medium gcmarkBits Corresponding bit Has been set to 1 You can skip processing
// If marked we have nothing to do.
if mbits.isMarked() {
return
}
// Set the location of the object span Medium gcmarkBits Corresponding bit by 1
// mbits.setMarked() // Avoid extra call overhead with manual inlining.
atomic.Or8(mbits.bytep, mbits.mask)
// If it is determined that the object does not contain a pointer ( Where span The type is noscan), You don't need to put the object in the tag queue
// If this is a noscan object, fast-track it to black
// instead of greying it.
if span.spanclass.noscan() {
gcw.bytesMarked += uint64(span.elemsize)
return
}
}
// Put the object in the tag queue
// Put the local tag queue first , In case of failure, part of the work in the local tag queue is transferred to the global tag queue , Then put it into the local tag queue
// Queue the obj for scanning. The PREFETCH(obj) logic has been removed but
// seems like a nice optimization that can be added back in.
// There needs to be time between the PREFETCH and the use.
// Previously we put the obj in an 8 element buffer that is drained at a rate
// to give the PREFETCH time to do its work.
// Use of PREFETCHNTA might be more appropriate than PREFETCH
if !gcw.putFast(obj) {
gcw.put(obj)
}
}
gcDrain Function scans the root object , You start consuming tag queues , Call on an object that is taken out of the tag queue scanobject function :
// scanobject scans the object starting at b, adding pointers to gcw.
// b must point to the beginning of a heap object or an oblet.
// scanobject consults the GC bitmap for the pointer mask and the
// spans for the size of the object.
//
//go:nowritebarrier
func scanobject(b uintptr, gcw *gcWork) {
// Note that arena_used may change concurrently during
// scanobject and hence scanobject may encounter a pointer to
// a newly allocated heap object that is *not* in
// [start,used). It will not mark this object; however, we
// know that it was just installed by a mutator, which means
// that mutator will execute a write barrier and take care of
// marking it. This is even more pronounced on relaxed memory
// architectures since we access arena_used without barriers
// or synchronization, but the same logic applies.
arena_start := mheap_.arena_start
arena_used := mheap_.arena_used
// Find the bits for b and the size of the object at b.
//
// b is either the beginning of an object, in which case this
// is the size of the object to scan, or it points to an
// oblet, in which case we compute the size to scan below.
// Get the object corresponding to bitmap
hbits := heapBitsForAddr(b)
// Get the object's location span
s := spanOfUnchecked(b)
// Get the size of the object
n := s.elemsize
if n == 0 {
throw("scanobject n == 0")
}
// When the object size is too large (maxObletBytes yes 128KB) We need a split scan
// Scan at most... At most 128KB
if n > maxObletBytes {
// Large object. Break into oblets for better
// parallelism and lower latency.
if b == s.base() {
// It's possible this is a noscan object (not
// from greyobject, but from other code
// paths), in which case we must *not* enqueue
// oblets since their bitmaps will be
// uninitialized.
if s.spanclass.noscan() {
// Bypass the whole scan.
gcw.bytesMarked += uint64(n)
return
}
// Enqueue the other oblets to scan later.
// Some oblets may be in b's scalar tail, but
// these will be marked as "no more pointers",
// so we'll drop out immediately when we go to
// scan those.
for oblet := b + maxObletBytes; oblet < s.base()+s.elemsize; oblet += maxObletBytes {
if !gcw.putFast(oblet) {
gcw.put(oblet)
}
}
}
// Compute the size of the oblet. Since this object
// must be a large object, s.base() is the beginning
// of the object.
n = s.base() + s.elemsize - b
if n > maxObletBytes {
n = maxObletBytes
}
}
// Scan the pointer in the object
var i uintptr
for i = 0; i < n; i += sys.PtrSize {
// Get the corresponding bit
// Find bits for this word.
if i != 0 {
// Avoid needless hbits.next() on last iteration.
hbits = hbits.next()
}
// Load bits once. See CL 22712 and issue 16973 for discussion.
bits := hbits.bits()
// Check scan bit Determine whether to continue scanning , Pay attention to the second one scan bit yes checkmark
// During checkmarking, 1-word objects store the checkmark
// in the type bit for the one word. The only one-word objects
// are pointers, or else they'd be merged with other non-pointer
// data into larger allocations.
if i != 1*sys.PtrSize && bits&bitScan == 0 {
break // no more pointers in this object
}
// Check pointer bit, If it's not a pointer, it goes on
if bits&bitPointer == 0 {
continue // not a pointer
}
// Take the value of the pointer
// Work here is duplicated in scanblock and above.
// If you make changes here, make changes there too.
obj := *(*uintptr)(unsafe.Pointer(b + i))
// If the pointer is in arena In the region , Call greyobject Tag the object and put it in the tag queue
// At this point we have extracted the next potential pointer.
// Check if it points into heap and not back at the current object.
if obj != 0 && arena_start <= obj && obj < arena_used && obj-b >= n {
// Mark the object.
if obj, hbits, span, objIndex := heapBitsForObject(obj, b, i); obj != 0 {
greyobject(obj, b, i, hbits, span, gcw, objIndex)
}
}
}
// Count the size and number of objects scanned
gcw.bytesMarked += uint64(n)
gcw.scanWork += int64(i)
}
When all background marking tasks have consumed the tag queue , Will execute gcMarkDone The function is ready to enter the completion mark phase (mark termination):
In parallel GC in gcMarkDone Will be executed twice , The first time the local tag queue is disabled and then the background marking task is restarted , The second time, it will enter the completion marking stage (mark termination).
// gcMarkDone transitions the GC from mark 1 to mark 2 and from mark 2
// to mark termination.
//
// This should be called when all mark work has been drained. In mark
// 1, this includes all root marking jobs, global work buffers, and
// active work buffers in assists and background workers; however,
// work may still be cached in per-P work buffers. In mark 2, per-P
// caches are disabled.
//
// The calling context must be preemptible.
//
// Note that it is explicitly okay to have write barriers in this
// function because completion of concurrent mark is best-effort
// anyway. Any work created by write barriers here will be cleaned up
// by mark termination.
func gcMarkDone() {
top:
semacquire(&work.markDoneSema)
// Re-check transition condition under transition lock.
if !(gcphase == _GCmark && work.nwait == work.nproc && !gcMarkWorkAvailable(nil)) {
semrelease(&work.markDoneSema)
return
}
// Temporarily disable starting new background marking tasks
// Disallow starting new workers so that any remaining workers
// in the current mark phase will drain out.
//
// TODO(austin): Should dedicated workers keep an eye on this
// and exit gcDrain promptly?
atomic.Xaddint64(&gcController.dedicatedMarkWorkersNeeded, -0xffffffff)
atomic.Xaddint64(&gcController.fractionalMarkWorkersNeeded, -0xffffffff)
// Determine if the local tag queue is disabled
if !gcBlackenPromptly {
// Whether the local tag queue is not disabled , Disable and restart the background marking task
// Transition from mark 1 to mark 2.
//
// The global work list is empty, but there can still be work
// sitting in the per-P work caches.
// Flush and disable work caches.
// Disable local tag queue
// Disallow caching workbufs and indicate that we're in mark 2.
gcBlackenPromptly = true
// Prevent completion of mark 2 until we've flushed
// cached workbufs.
atomic.Xadd(&work.nwait, -1)
// GC is set up for mark 2. Let Gs blocked on the
// transition lock go while we flush caches.
semrelease(&work.markDoneSema)
// Push all objects in the local tag queue to the global tag queue
systemstack(func() {
// Flush all currently cached workbufs and
// ensure all Ps see gcBlackenPromptly. This
// also blocks until any remaining mark 1
// workers have exited their loop so we can
// start new mark 2 workers.
forEachP(func(_p_ *p) {
_p_.gcw.dispose()
})
})
// Eliminate misuse
// Check that roots are marked. We should be able to
// do this before the forEachP, but based on issue
// #16083 there may be a (harmless) race where we can
// enter mark 2 while some workers are still scanning
// stacks. The forEachP ensures these scans are done.
//
// TODO(austin): Figure out the race and fix this
// properly.
gcMarkRootCheck()
// Allow new background marking tasks to start
// Now we can start up mark 2 workers.
atomic.Xaddint64(&gcController.dedicatedMarkWorkersNeeded, 0xffffffff)
atomic.Xaddint64(&gcController.fractionalMarkWorkersNeeded, 0xffffffff)
// If you are sure that there are no more tasks, you can jump directly to the top of the function
// It's like a second call
incnwait := atomic.Xadd(&work.nwait, +1)
if incnwait == work.nproc && !gcMarkWorkAvailable(nil) {
// This loop will make progress because
// gcBlackenPromptly is now true, so it won't
// take this same "if" branch.
goto top
}
} else {
// Record the start time of the completion marking phase and STW Start time
// Transition to mark termination.
now := nanotime()
work.tMarkTerm = now
work.pauseStart = now
// prohibit G Be seized
getg().m.preemptoff = "gcing"
// Stop all running G, And they are forbidden to run
systemstack(stopTheWorldWithSema)
// !!!!!!!!!!!!!!!!
// The world has stopped (STW)...
// !!!!!!!!!!!!!!!!
// The gcphase is _GCmark, it will transition to _GCmarktermination
// below. The important thing is that the wb remains active until
// all marking is complete. This includes writes made by the GC.
// Mark the scan of the root object is complete , It will affect gcMarkRootPrepare Processing in
// Record that one root marking pass has completed.
work.markrootDone = true
// No assistance GC And background marking task running
// Disable assists and background workers. We must do
// this before waking blocked assists.
atomic.Store(&gcBlackenEnabled, 0)
// Wake up all because of assistance GC And dormant G
// Wake all blocked assists. These will run when we
// start the world again.
gcWakeAllAssists()
// Likewise, release the transition lock. Blocked
// workers and assists will run when we start the
// world again.
semrelease(&work.markDoneSema)
// Calculate the next trigger gc Needed heap size
// endCycle depends on all gcWork cache stats being
// flushed. This is ensured by mark 2.
nextTriggerRatio := gcController.endCycle()
// Enter the completion marking stage , Will restart the world
// Perform mark termination. This will restart the world.
gcMarkTermination(nextTriggerRatio)
}
}
gcMarkTermination The function will enter the completion mark phase :
func gcMarkTermination(nextTriggerRatio float64) {
// World is stopped.
// Start marktermination which includes enabling the write barrier.
// No assistance GC And background marking task running
atomic.Store(&gcBlackenEnabled, 0)
// Re allow local tag queues ( The next time GC Use )
gcBlackenPromptly = false
// Set up current GC Stage to completion marking stage , And enable the write barrier
setGCPhase(_GCmarktermination)
// Record the start time
work.heap1 = memstats.heap_live
startTime := nanotime()
// prohibit G Be seized
mp := acquirem()
mp.preemptoff = "gcing"
_g_ := getg()
_g_.m.traceback = 2
// Set up G Is waiting so that its stack can be scanned
gp := _g_.m.curg
casgstatus(gp, _Grunning, _Gwaiting)
gp.waitreason = "garbage collection"
// Switch to g0 function
// Run gc on the g0 stack. We do this so that the g stack
// we're currently running on will no longer change. Cuts
// the root set down a bit (g0 stacks are not scanned, and
// we don't need to scan gc's internal state). We also
// need to switch to g0 so we can shrink the stack.
systemstack(func() {
// Start STW Tags in
gcMark(startTime)
// It must be returned immediately , Because of the outside G The stack may be moved , You can't access outside variables after this
// Must return immediately.
// The outer function's stack may have moved
// during gcMark (it shrinks stacks, including the
// outer function's stack), so we must not refer
// to any of its variables. Return back to the
// non-system stack to pick up the new addresses
// before continuing.
})
// Switch back to g0 function
systemstack(func() {
work.heap2 = work.bytesMarked
// If enabled checkmark Then check , Check that all reachable objects are marked
if debug.gccheckmark > 0 {
// Run a full stop-the-world mark using checkmark bits,
// to check that we didn't forget to mark anything during
// the concurrent mark process.
gcResetMarkState()
initCheckmarks()
gcMark(startTime)
clearCheckmarks()
}
// Set up current GC Stage to close , And disable the write barrier
// marking is complete so we can turn the write barrier off
setGCPhase(_GCoff)
// Wake up the background cleaning task , Will be in STW When it's over, it starts running
gcSweep(work.mode)
// Eliminate misuse
if debug.gctrace > 1 {
startTime = nanotime()
// The g stacks have been scanned so
// they have gcscanvalid==true and gcworkdone==true.
// Reset these so that all stacks will be rescanned.
gcResetMarkState()
finishsweep_m()
// Still in STW but gcphase is _GCoff, reset to _GCmarktermination
// At this point all objects will be found during the gcMark which
// does a complete STW mark and object scan.
setGCPhase(_GCmarktermination)
gcMark(startTime)
setGCPhase(_GCoff) // marking is done, turn off wb.
gcSweep(work.mode)
}
})
// Set up G Is running
_g_.m.traceback = 0
casgstatus(gp, _Gwaiting, _Grunning)
// Tracking processing
if trace.enabled {
traceGCDone()
}
// all done
mp.preemptoff = ""
if gcphase != _GCoff {
throw("gc done but gcphase != _GCoff")
}
// Update next trigger gc Needed heap size (gc_trigger)
// Update GC trigger and pacing for the next cycle.
gcSetTriggerRatio(nextTriggerRatio)
// Update time history
// Update timing memstats
now := nanotime()
sec, nsec, _ := time_now()
unixNow := sec*1e9 + int64(nsec)
work.pauseNS += now - work.pauseStart
work.tEnd = now
atomic.Store64(&memstats.last_gc_unix, uint64(unixNow)) // must be Unix time to make sense to user
atomic.Store64(&memstats.last_gc_nanotime, uint64(now)) // monotonic time for us
memstats.pause_ns[memstats.numgc%uint32(len(memstats.pause_ns))] = uint64(work.pauseNS)
memstats.pause_end[memstats.numgc%uint32(len(memstats.pause_end))] = uint64(unixNow)
memstats.pause_total_ns += uint64(work.pauseNS)
// Update with cpu Record
// Update work.totaltime.
sweepTermCpu := int64(work.stwprocs) * (work.tMark - work.tSweepTerm)
// We report idle marking time below, but omit it from the
// overall utilization here since it's "free".
markCpu := gcController.assistTime + gcController.dedicatedMarkTime + gcController.fractionalMarkTime
markTermCpu := int64(work.stwprocs) * (work.tEnd - work.tMarkTerm)
cycleCpu := sweepTermCpu + markCpu + markTermCpu
work.totaltime += cycleCpu
// Compute overall GC CPU utilization.
totalCpu := sched.totaltime + (now-sched.procresizetime)*int64(gomaxprocs)
memstats.gc_cpu_fraction = float64(work.totaltime) / float64(totalCpu)
// Reset sweep status
// Reset sweep state.
sweep.nbgsweep = 0
sweep.npausesweep = 0
// Statistics forced to start GC The number of times
if work.userForced {
memstats.numforcedgc++
}
// Statistics execution GC Number of times then wake up waiting to be cleaned G
// Bump GC cycle count and wake goroutines waiting on sweep.
lock(&work.sweepWaiters.lock)
memstats.numgc++
injectglist(work.sweepWaiters.head.ptr())
work.sweepWaiters.head = 0
unlock(&work.sweepWaiters.lock)
// For performance statistics
// Finish the current heap profiling cycle and start a new
// heap profiling cycle. We do this before starting the world
// so events don't leak into the wrong cycle.
mProf_NextCycle()
// Restart the world
systemstack(startTheWorldWithSema)
// !!!!!!!!!!!!!!!
// The world has rebooted ...
// !!!!!!!!!!!!!!!
// For performance statistics
// Flush the heap profile so we can start a new cycle next GC.
// This is relatively expensive, so we don't do it with the
// world stopped.
mProf_Flush()
// Move the buffer used by the token queue to the free list , So they can be recycled
// Prepare workbufs for freeing by the sweeper. We do this
// asynchronously because it can take non-trivial time.
prepareFreeWorkbufs()
// Release unused stacks
// Free stack spans. This must be done between GC cycles.
systemstack(freeStackSpans)
// Eliminate misuse
// Print gctrace before dropping worldsema. As soon as we drop
// worldsema another cycle could start and smash the stats
// we're trying to print.
if debug.gctrace > 0 {
util := int(memstats.gc_cpu_fraction * 100)
var sbuf [24]byte
printlock()
print("gc ", memstats.numgc,
" @", string(itoaDiv(sbuf[:], uint64(work.tSweepTerm-runtimeInitTime)/1e6, 3)), "s ",
util, "%: ")
prev := work.tSweepTerm
for i, ns := range []int64{work.tMark, work.tMarkTerm, work.tEnd} {
if i != 0 {
print("+")
}
print(string(fmtNSAsMS(sbuf[:], uint64(ns-prev))))
prev = ns
}
print(" ms clock, ")
for i, ns := range []int64{sweepTermCpu, gcController.assistTime, gcController.dedicatedMarkTime + gcController.fractionalMarkTime, gcController.idleMarkTime, markTermCpu} {
if i == 2 || i == 3 {
// Separate mark time components with /.
print("/")
} else if i != 0 {
print("+")
}
print(string(fmtNSAsMS(sbuf[:], uint64(ns))))
}
print(" ms cpu, ",
work.heap0>>20, "->", work.heap1>>20, "->", work.heap2>>20, " MB, ",
work.heapGoal>>20, " MB goal, ",
work.maxprocs, " P")
if work.userForced {
print(" (forced)")
}
print("n")
printunlock()
}
semrelease(&worldsema)
// Careful: another GC cycle may start now.
// Re allow the current G Be seized
releasem(mp)
mp = nil
// If it's parallel GC, Let the current M Continue operation ( Will return to gcBgMarkWorker Then sleep )
// If not in parallel GC, Let the present M Start scheduling
// now that gc is done, kick off finalizer thread if needed
if !concurrentSweep {
// give the queued finalizers, if any, a chance to run
Gosched()
}
}
gcSweep Function will wake up the background cleaning task :
The background cleaning task will be called when the program starts gcenable Function .
func gcSweep(mode gcMode) {
if gcphase != _GCoff {
throw("gcSweep being done but phase is not GCoff")
}
// increase sweepgen, such sweepSpans The two queue roles in will switch , all span Will become " To be cleaned up " Of span
lock(&mheap_.lock)
mheap_.sweepgen += 2
mheap_.sweepdone = 0
if mheap_.sweepSpans[mheap_.sweepgen/2%2].index != 0 {
// We should have drained this list during the last
// sweep phase. We certainly need to start this phase
// with an empty swept list.
throw("non-empty swept list")
}
mheap_.pagesSwept = 0
unlock(&mheap_.lock)
// If it's not parallel GC And finish all the work here (STW in )
if !_ConcurrentSweep || mode == gcForceBlockMode {
// Special case synchronous sweep.
// Record that no proportional sweeping has to happen.
lock(&mheap_.lock)
mheap_.sweepPagesPerByte = 0
unlock(&mheap_.lock)
// Sweep all spans eagerly.
for sweepone() != ^uintptr(0) {
sweep.npausesweep++
}
// Free workbufs eagerly.
prepareFreeWorkbufs()
for freeSomeWbufs(false) {
}
// All "free" events for this mark/sweep cycle have
// now happened, so we can make this profile cycle
// available immediately.
mProf_NextCycle()
mProf_Flush()
return
}
// Wake up the background cleaning task
// Background sweep.
lock(&sweep.lock)
if sweep.parked {
sweep.parked = false
ready(sweep.g, 0, true)
}
unlock(&sweep.lock)
}
The function of background cleaning task is bgsweep:
func bgsweep(c chan int) {
sweep.g = getg()
// Waiting to wake up
lock(&sweep.lock)
sweep.parked = true
c <- 1
goparkunlock(&sweep.lock, "GC sweep wait", traceEvGoBlock, 1)
// Cycle cleaning
for {
// Clean one up span, Then go to scheduling ( Do only a small amount of work at a time )
for gosweepone() != ^uintptr(0) {
sweep.nbgsweep++
Gosched()
}
// Release some unused tag queue buffers to heap
for freeSomeWbufs(true) {
Gosched()
}
// If the cleaning is not completed, continue the cycle
lock(&sweep.lock)
if !gosweepdone() {
// This can happen if a GC runs between
// gosweepone returning ^0 above
// and the lock being acquired.
unlock(&sweep.lock)
continue
}
// Otherwise, let the background cleaning task go to sleep , At present M Continue to dispatch
sweep.parked = true
goparkunlock(&sweep.lock, "GC sweep wait", traceEvGoBlock, 1)
}
}
gosweepone The function will start from sweepSpans Take out a single span Clean :
//go:nowritebarrier
func gosweepone() uintptr {
var ret uintptr
// Switch to g0 function
systemstack(func() {
ret = sweepone()
})
return ret
}
sweepone Function as follows :
// sweeps one span
// returns number of pages returned to heap, or ^uintptr(0) if there is nothing to sweep
//go:nowritebarrier
func sweepone() uintptr {
_g_ := getg()
sweepRatio := mheap_.sweepPagesPerByte // For debugging
// prohibit G Be seized
// increment locks to ensure that the goroutine is not preempted
// in the middle of sweep thus leaving the span in an inconsistent state for next GC
_g_.m.locks++
// Check that the cleaning has been completed
if atomic.Load(&mheap_.sweepdone) != 0 {
_g_.m.locks--
return ^uintptr(0)
}
// Update at the same time sweep Number of tasks
atomic.Xadd(&mheap_.sweepers, +1)
npages := ^uintptr(0)
sg := mheap_.sweepgen
for {
// from sweepSpans Take out one of span
s := mheap_.sweepSpans[1-sg/2%2].pop()
// Jump out of the loop when all cleaning is done
if s == nil {
atomic.Store(&mheap_.sweepdone, 1)
break
}
// other M It's been cleaning this span Skip on
if s.state != mSpanInUse {
// This can happen if direct sweeping already
// swept this span, but in that case the sweep
// generation should always be up-to-date.
if s.sweepgen != sg {
print("runtime: bad span s.state=", s.state, " s.sweepgen=", s.sweepgen, " sweepgen=", sg, "n")
throw("non in-use span in unswept list")
}
continue
}
// Atoms increase span Of sweepgen, Failure means something else M We've started cleaning this span, skip
if s.sweepgen != sg-2 || !atomic.Cas(&s.sweepgen, sg-2, sg-1) {
continue
}
// Clean this span, Then jump out of the loop
npages = s.npages
if !s.sweep(false) {
// Span is still in-use, so this returned no
// pages to the heap and the span needs to
// move to the swept in-use list.
npages = 0
}
break
}
// Update at the same time sweep Number of tasks
// Decrement the number of active sweepers and if this is the
// last one print trace information.
if atomic.Xadd(&mheap_.sweepers, -1) == 0 && atomic.Load(&mheap_.sweepdone) != 0 {
if debug.gcpacertrace > 0 {
print("pacer: sweep done at heap size ", memstats.heap_live>>20, "MB; allocated ", (memstats.heap_live-mheap_.sweepHeapLiveBasis)>>20, "MB during sweep; swept ", mheap_.pagesSwept, " pages at ", sweepRatio, " pages/byten")
}
}
// allow G Be seized
_g_.m.locks--
// Back to the number of pages cleaned
return npages
}
span Of sweep Function is used to clean a single span:
// Sweep frees or collects finalizers for blocks not marked in the mark phase.
// It clears the mark bits in preparation for the next GC round.
// Returns true if the span was returned to heap.
// If preserve=true, don't return it to heap nor relink in MCentral lists;
// caller takes care of it.
//TODO go:nowritebarrier
func (s *mspan) sweep(preserve bool) bool {
// It's critical that we enter this function with preemption disabled,
// GC must not start while we are in the middle of this function.
_g_ := getg()
if _g_.m.locks == 0 && _g_.m.mallocing == 0 && _g_ != _g_.m.g0 {
throw("MSpan_Sweep: m is not locked")
}
sweepgen := mheap_.sweepgen
if s.state != mSpanInUse || s.sweepgen != sweepgen-1 {
print("MSpan_Sweep: state=", s.state, " sweepgen=", s.sweepgen, " mheap.sweepgen=", sweepgen, "n")
throw("MSpan_Sweep: bad span state")
}
if trace.enabled {
traceGCSweepSpan(s.npages * _PageSize)
}
// Count the number of pages cleaned up
atomic.Xadd64(&mheap_.pagesSwept, int64(s.npages))
spc := s.spanclass
size := s.elemsize
res := false
c := _g_.m.mcache
freeToHeap := false
// The allocBits indicate which unmarked objects don't need to be
// processed since they were free at the end of the last GC cycle
// and were not allocated since then.
// If the allocBits index is >= s.freeindex and the bit
// is not marked then the object remains unallocated
// since the last GC.
// This situation is analogous to being on a freelist.
// Judgment in special Destructor in , If the corresponding object is no longer alive, mark the object alive to prevent recycling , Then move the destructor to the run queue
// Unlink & free special records for any objects we're about to free.
// Two complications here:
// 1. An object can have both finalizer and profile special records.
// In such case we need to queue finalizer for execution,
// mark the object as live and preserve the profile special.
// 2. A tiny object can have several finalizers setup for different offsets.
// If such object is not marked, we need to queue all finalizers at once.
// Both 1 and 2 are possible at the same time.
specialp := &s.specials
special := *specialp
for special != nil {
// A finalizer can be set for an inner byte of an object, find object beginning.
objIndex := uintptr(special.offset) / size
p := s.base() + objIndex*size
mbits := s.markBitsForIndex(objIndex)
if !mbits.isMarked() {
// This object is not marked and has at least one special record.
// Pass 1: see if it has at least one finalizer.
hasFin := false
endOffset := p - s.base() + size
for tmp := special; tmp != nil && uintptr(tmp.offset) < endOffset; tmp = tmp.next {
if tmp.kind == _KindSpecialFinalizer {
// Stop freeing of object if it has a finalizer.
mbits.setMarkedNonAtomic()
hasFin = true
break
}
}
// Pass 2: queue all finalizers _or_ handle profile record.
for special != nil && uintptr(special.offset) < endOffset {
// Find the exact byte for which the special was setup
// (as opposed to object beginning).
p := s.base() + uintptr(special.offset)
if special.kind == _KindSpecialFinalizer || !hasFin {
// Splice out special record.
y := special
special = special.next
*specialp = special
freespecial(y, unsafe.Pointer(p), size)
} else {
// This is profile record, but the object has finalizers (so kept alive).
// Keep special record.
specialp = &special.next
special = *specialp
}
}
} else {
// object is still live: keep special record
specialp = &special.next
special = *specialp
}
}
// Eliminate misuse
if debug.allocfreetrace != 0 || raceenabled || msanenabled {
// Find all newly freed objects. This doesn't have to
// efficient; allocfreetrace has massive overhead.
mbits := s.markBitsForBase()
abits := s.allocBitsForIndex(0)
for i := uintptr(0); i < s.nelems; i++ {
if !mbits.isMarked() && (abits.index < s.freeindex || abits.isMarked()) {
x := s.base() + i*s.elemsize
if debug.allocfreetrace != 0 {
tracefree(unsafe.Pointer(x), size)
}
if raceenabled {
racefree(unsafe.Pointer(x), size)
}
if msanenabled {
msanfree(unsafe.Pointer(x), size)
}
}
mbits.advance()
abits.advance()
}
}
// Calculate the number of objects released
// Count the number of free objects in this span.
nalloc := uint16(s.countAlloc())
if spc.sizeclass() == 0 && nalloc == 0 {
// If span The type is 0( Big object ) If the object is no longer alive, it will be released to heap
s.needzero = 1
freeToHeap = true
}
nfreed := s.allocCount - nalloc
if nalloc > s.allocCount {
print("runtime: nelems=", s.nelems, " nalloc=", nalloc, " previous allocCount=", s.allocCount, " nfreed=", nfreed, "n")
throw("sweep increased allocation count")
}
// Set up the new allocCount
s.allocCount = nalloc
// Judge span Whether there are no unallocated objects
wasempty := s.nextFreeIndex() == s.nelems
// Reset freeindex, Next assignment from 0 Begin your search
s.freeindex = 0 // reset allocation index to start of span.
if trace.enabled {
getg().m.p.ptr().traceReclaimed += uintptr(nfreed) * s.elemsize
}
// gcmarkBits Become new allocBits
// And then reallocate a block, all for 0 Of gcmarkBits
// The next time you assign objects, you can use allocBits Know which elements are unallocated
// gcmarkBits becomes the allocBits.
// get a fresh cleared gcmarkBits in preparation for next GC
s.allocBits = s.gcmarkBits
s.gcmarkBits = newMarkBits(s.nelems)
// to update freeindex At the beginning allocCache
// Initialize alloc bits cache.
s.refillAllocCache(0)
// If span If there is no existing object in the, it will be updated sweepgen Up to date
// I'll put span Add to mcentral perhaps mheap
// We need to set s.sweepgen = h.sweepgen only when all blocks are swept,
// because of the potential for a concurrent free/SetFinalizer.
// But we need to set it before we make the span available for allocation
// (return it to heap or mcentral), because allocation code assumes that a
// span is already swept if available for allocation.
if freeToHeap || nfreed == 0 {
// The span must be in our exclusive ownership until we update sweepgen,
// check for potential races.
if s.state != mSpanInUse || s.sweepgen != sweepgen-1 {
print("MSpan_Sweep: state=", s.state, " sweepgen=", s.sweepgen, " mheap.sweepgen=", sweepgen, "n")
throw("MSpan_Sweep: bad span state after sweep")
}
// Serialization point.
// At this point the mark bits are cleared and allocation ready
// to go so release the span.
atomic.Store(&s.sweepgen, sweepgen)
}
if nfreed > 0 && spc.sizeclass() != 0 {
// hold span Add to mcentral, res Is equal to whether the addition is successful
c.local_nsmallfree[spc.sizeclass()] += uintptr(nfreed)
res = mheap_.central[spc].mcentral.freeSpan(s, preserve, wasempty)
// freeSpan Will update sweepgen
// MCentral_FreeSpan updates sweepgen
} else if freeToHeap {
// hold span Release to mheap
// Free large span to heap
// NOTE(rsc,dvyukov): The original implementation of efence
// in CL 22060046 used SysFree instead of SysFault, so that
// the operating system would eventually give the memory
// back to us again, so that an efence program could run
// longer without running out of memory. Unfortunately,
// calling SysFree here without any kind of adjustment of the
// heap data structures means that when the memory does
// come back to us, we have the wrong metadata for it, either in
// the MSpan structures or in the garbage collection bitmap.
// Using SysFault here means that the program will run out of
// memory fairly quickly in efence mode, but at least it won't
// have mysterious crashes due to confused memory reuse.
// It should be possible to switch back to SysFree if we also
// implement and then call some kind of MHeap_DeleteSpan.
if debug.efence > 0 {
s.limit = 0 // prevent mlookup from finding this span
sysFault(unsafe.Pointer(s.base()), size)
} else {
mheap_.freeSpan(s, 1)
}
c.local_nlargefree++
c.local_largefree += size
res = true
}
// If span Not added to mcentral Or not released to mheap, said span Still in use
if !res {
// Put what is still in use span Add to sweepSpans Of " Cleaned up " In line
// The span has been swept and is still in-use, so put
// it on the swept in-use list.
mheap_.sweepSpans[sweepgen/2%2].push(s)
}
return res
}
from bgsweep And the previous allocator shows that the scanning phase is very lazy (lazy) Of ,
It may actually appear that the previous phase of the scan has not been completed , You need to start a new round of GC The situation of ,
So every round GC You need to finish the previous round before you start GC The scanning work of (Sweep Termination Stage ).
GC The whole process has been analyzed , Finally, we put up the barrier function writebarrierptr The implementation of the :
// NOTE: Really dst *unsafe.Pointer, src unsafe.Pointer,
// but if we do that, Go inserts a write barrier on *dst = src.
//go:nosplit
func writebarrierptr(dst *uintptr, src uintptr) {
if writeBarrier.cgo {
cgoCheckWriteBarrier(dst, src)
}
if !writeBarrier.needed {
*dst = src
return
}
if src != 0 && src < minPhysPageSize {
systemstack(func() {
print("runtime: writebarrierptr *", dst, " = ", hex(src), "n")
throw("bad pointer in write barrier")
})
}
// Marker pointer
writebarrierptr_prewrite1(dst, src)
// Set pointer to target
*dst = src
}
writebarrierptr_prewrite1 Function as follows :
// writebarrierptr_prewrite1 invokes a write barrier for *dst = src
// prior to the write happening.
//
// Write barrier calls must not happen during critical GC and scheduler
// related operations. In particular there are times when the GC assumes
// that the world is stopped but scheduler related code is still being
// executed, dealing with syscalls, dealing with putting gs on runnable
// queues and so forth. This code cannot execute write barriers because
// the GC might drop them on the floor. Stopping the world involves removing
// the p associated with an m. We use the fact that m.p == nil to indicate
// that we are in one these critical section and throw if the write is of
// a pointer to a heap object.
//go:nosplit
func writebarrierptr_prewrite1(dst *uintptr, src uintptr) {
mp := acquirem()
if mp.inwb || mp.dying > 0 {
releasem(mp)
return
}
systemstack(func() {
if mp.p == 0 && memstats.enablegc && !mp.inwb && inheap(src) {
throw("writebarrierptr_prewrite1 called with mp.p == nil")
}
mp.inwb = true
gcmarkwb_m(dst, src)
})
mp.inwb = false
releasem(mp)
}
gcmarkwb_m Function as follows :
func gcmarkwb_m(slot *uintptr, ptr uintptr) {
if writeBarrier.needed {
// Note: This turns bad pointer writes into bad
// pointer reads, which could be confusing. We avoid
// reading from obviously bad pointers, which should
// take care of the vast majority of these. We could
// patch this up in the signal handler, or use XCHG to
// combine the read and the write. Checking inheap is
// insufficient since we need to track changes to
// roots outside the heap.
//
// Note: profbuf.go omits a barrier during signal handler
// profile logging; that's safe only because this deletion barrier exists.
// If we remove the deletion barrier, we'll have to work out
// a new way to handle the profile logging.
if slot1 := uintptr(unsafe.Pointer(slot)); slot1 >= minPhysPageSize {
if optr := *slot; optr != 0 {
// Mark the old pointer
shade(optr)
}
}
// TODO: Make this conditional on the caller's stack color.
if ptr != 0 && inheap(ptr) {
// Mark new pointer
shade(ptr)
}
}
}
shade Function as follows :
// Shade the object if it isn't already.
// The object is not nil and known to be in the heap.
// Preemption must be disabled.
//go:nowritebarrier
func shade(b uintptr) {
if obj, hbits, span, objIndex := heapBitsForObject(b, 0, 0); obj != 0 {
gcw := &getg().m.p.ptr().gcw
// Mark an object alive , And add it to the tag queue ( The object turns gray )
greyobject(obj, 0, 0, hbits, span, gcw, objIndex)
// If it is marked to disable local tag queues flush To the global tag queue
if gcphase == _GCmarktermination || gcBlackenPromptly {
// Ps aren't allowed to cache work during mark
// termination.
gcw.dispose()
}
}
}
Reference link
https://github.com/golang/go
https://making.pusher.com/golangs-real-time-gc-in-theory-and-practice
https://github.com/golang/proposal/blob/master/design/17503-eliminate-rescan.md
https://golang.org/s/go15gcpacing
https://golang.org/ref/mem
https://talks.golang.org/2015/go-gc.pdf
https://docs.google.com/document/d/1ETuA2IOmnaQ4j81AtTGT40Y4_Jr6_IDASEKg0t0dBR8/edit#heading=h.x4kziklnb8fr
https://go-review.googlesource.com/c/go/+/21503
http://www.cnblogs.com/diegodu/p/5803202.html
http://legendtkl.com/2017/04/28/golang-gc
https://lengzzz.com/note/gc-in-golang
Golang Of GC and CoreCLR Of GC contrast
Because I've been right about CoreCLR Of GC I did some analysis ( see This article and This article ), Here I can make a simple comparison CoreCLR and GO Of GC Realization :
- CoreCLR Object with type information , GO You don't have to , But through bitmap Area records where the pointer is contained
- CoreCLR Assigning objects is significantly faster , GO The assignment object needs to find span And write bitmap Area
CoreCLR The collector needs to do more work than GO A lot more
- CoreCLR Objects of different sizes are placed in one segment in , Only linear scan
- CoreCLR Determine the object reference to access type information , and go Just access bitmap
- CoreCLR When cleaning, mark them as free objects one by one , and go Just switch allocBits
CoreCLR The pause time is longer than GO longer
- although CoreCLR Support parallel GC, But no GO thoroughly , GO Even scanning the root object does not require a complete pause
CoreCLR Support generational GC
- although Full GC when CoreCLR Is not as efficient as GO, however CoreCLR Most of the time, you can just scan 0 And the 1 The object of generation
- Because it supports generational GC, Usually CoreCLR Flowers in GC Upper CPU Time will be better than GO Less
CoreCLR The allocator and collector are usually more than GO Efficient , in other words CoreCLR There will be higher throughput .
but CoreCLR The maximum pause time is not as good as GO short , This is because GO Of GC The whole design is to reduce pause time .
Now distributed computing and scale out are becoming more and more popular ,
Compared with the pursuit of single machine throughput , It's a better choice to pursue low latency and then let distributed solve the throughput problem ,
GO It is designed to make it more suitable for writing web services than any other language .