当前位置:网站首页>After SQL group query, get the first n records of each group
After SQL group query, get the first n records of each group
2020-11-09 10:51:00 【osc A 3gbrdm】

Catalog
One 、 background
lately , There is a functional requirement in development . The system has an information query module , Ask for information to be presented in card form . Here's the picture :
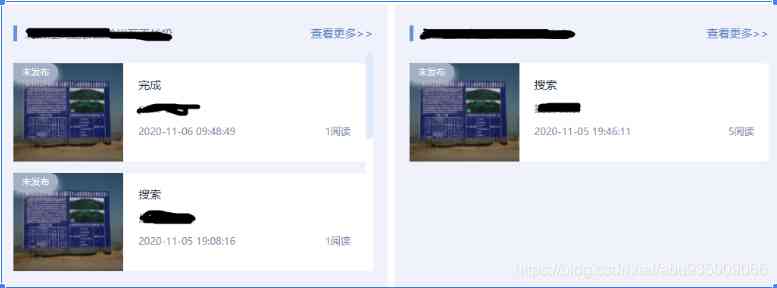
Show the cards according to the project team , Each project group shows the most read TOP2.
Demand analysis : Group by project group , Then take the top of each group with the most reading 2 strip .
Two 、 Practical analysis
be based on Mysql database
The table definition
1、 The project team :team
| id |
Primary key |
| name |
Project team name |
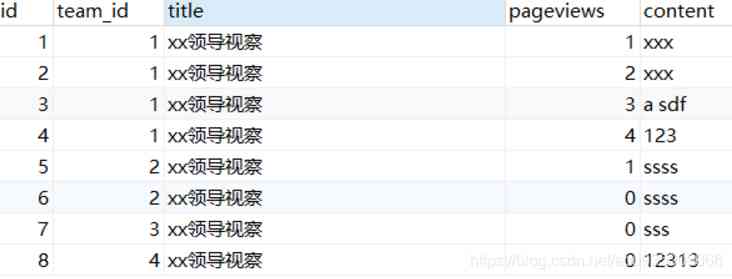
2、 Information sheet :info
| id |
Primary key |
| team_id |
The project team id |
| title |
Information name |
| pageviews |
Browse volume |
| content |
Information content |
info Table data is shown in the figure below :
Let's preview Select Basic knowledge of
Writing order :
select *columns*
from *tables*
where *predicae1*
group by *columns*
having *predicae1*
order by *columns*
limit *start*, *offset*;Execution order :
from *tables*
where *predicae1*
group by *columns*
having *predicae1*
select *columns*
order by *columns*
limit *start*, *offset*;
count( Field name ) # Returns the total number of records in this field in the table
DISTINCT Field name # Filter duplicate records in the field
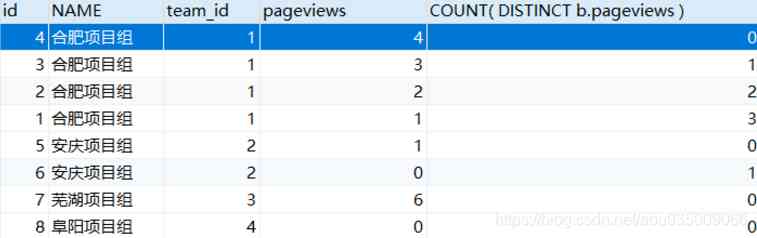
First step : First find out the top two readings in the information sheet
info Information table self correlation
SELECT a.*
FROM info a
WHERE (
SELECT count(DISTINCT b.pageviews)
FROM info b
WHERE a.pageviews < b.pageviews AND a.team_id= b.team_id
) < 2 ;At first glance, it's hard to understand , Here's an example
for instance :
When the amount of reading pageviews a = b = [1,2,3,4]
a.pageviews = 1,b.pageviews It can take [2,3,4],count(DISTINCT b.pageviews) = 3
a.pageviews = 2,b.pageviews It can take [3,4],count(DISTINCT b.pageviews) = 2 # Yes 2 strip , That's the third place
a.pageviews = 3,b.pageviews It can take [4],count(DISTINCT b.pageviews) = 1 # Yes 1 strip , That's the second place
a.pageviews = 4,b.pageviews It can take [],count(DISTINCT b.pageviews) = 0 # Yes 0 strip , That is, the biggest The first name count(DISTINCT b.pageviews) Represents several values larger than this value
a.team_id= b.team_id Autocorrelation condition , It's about equal to grouping
therefore Top two Equivalent to count(DISTINCT e2.Salary) < 2 , therefore a.pageviews It can be taken as 3、4, Before the assembly 2 high
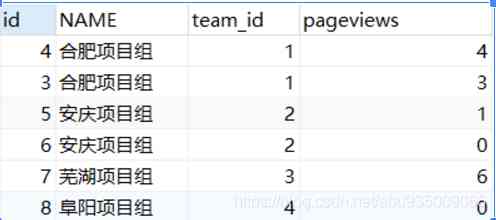
The second step : Put the watch again team And table info Connect
SELECT a.id, t.NAME, a.team_id, a.pageviews
FROM info a
LEFT JOIN team t ON a.team_id = t.id
WHERE (
SELECT count(DISTINCT b.pageviews)
FROM info b
WHERE a.pageviews < b.pageviews AND a.team_id= b.team_id) < 2
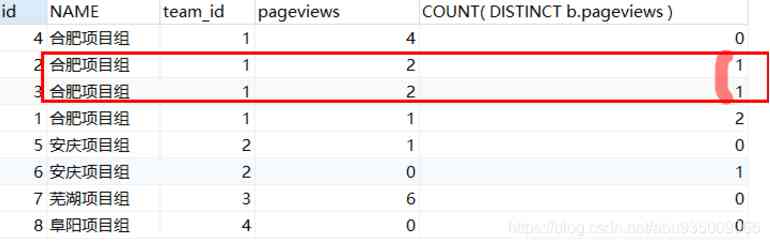
ORDER BY a.team_id, a.pageviews descThe results are as follows :
There is also a way to understand :
grouping GROUP BY + HAVING, This method can be used to debug the results step by step
SELECT a.id, t.NAME, a.team_id, a.pageviews, COUNT( DISTINCT b.pageviews )
FROM info a
LEFT JOIN info b ON ( a.pageviews < b.pageviews AND a.team_id = b.team_id )
LEFT JOIN team t ON a.team_id = t.id
GROUP BY a.id, t.NAME, a.team_id, a.pageviews
HAVING COUNT( DISTINCT b.pageviews ) < 2
ORDER BY a.team_id, a.pageviews DESCproblem : If the number of readings is the same , It just cracked .
Illustrate with examples :
When the amount of reading pageviews a = b = [1,2,2,4]
a.pageviews = 1,b.pageviews It can take [2,2,4],count(DISTINCT b.pageviews) = 3
a.pageviews = 2,b.pageviews It can take [4],count(DISTINCT b.pageviews) = 1 # Yes 1 strip , That is to say, they are tied for the second place
a.pageviews = 2,b.pageviews It can take [4],count(DISTINCT b.pageviews) = 1 # Yes 1 strip , That's the second place
a.pageviews = 4,b.pageviews It can take [],count(DISTINCT b.pageviews) = 0 # Yes 0 strip , That is, the biggest The first name count(DISTINCT e2.Salary) < 2 , therefore a.pageviews It can be taken as 2、2、4, Before the assembly 2 high , But there are three pieces of data
3、 ... and 、 summary
Demand transformation : We will find the first few in groups , It's self related , There are several numbers larger than this one
In fact, this is similar to LeetCode The difficulty is hard A database title of
185. All the employees with the top three salaries in the Department
Reference resources :
版权声明
本文为[osc A 3gbrdm]所创,转载请带上原文链接,感谢
边栏推荐
- Commodity management system -- integrate warehouse services and obtain warehouse list
- Program life: from Internet addicts to Microsoft, bat and byte offer harvesters
- Start learning discrete mathematics again
- jsliang 求职系列 - 08 - 手写 Promise
- 理解 OC 中 RunLoop
- Android 复选框 以及回显
- What details does C + + improve on the basis of C
- 搭建全分布式集群全过程
- Commodity management system -- the search function of SPU
- 商品管理系统——商品新增本地保存实现部分
猜你喜欢

![[Python从零到壹] 五.网络爬虫之BeautifulSoup基础语法万字详解](/img/e8/dd70ddf3c2027907f64674676d676e.jpg)


随机推荐
Python零基础入门教程(01)
Android权限大全
MapStruct 解了对象映射的毒
百亿级数据分表后怎么分页查询?
JT-day09
Oschina plays disorderly on Monday
Android 解决setRequestedOrientation之后手机屏幕的旋转不触发onConfigurationChanged方法
使用CopyMemory API出现 尝试读取或写入受保护的内存。这通常指示其他内存已损坏。
Deng Junhui's notes on data structure and algorithm learning - Chapter 9
美国大选拜登获胜!硅谷的Python开发者用这种方式调侃懂王
Talk about my understanding of FAAS with Alibaba cloud FC
Rainbow sorting | Dutch flag problem
range_sensor_layer
抢球鞋?预测股市走势?淘宝秒杀?Python表示要啥有啥
EasyNTS上云网关设备在雪亮工程项目中的实战应用
When Python calls ffmpeg, 'ffmpeg' is not an internal or external command, nor a runnable program
2020,Android开发者打破寒冬的利器是什么?
推荐系统,深度论文剖析GBDT+LR
无法启动此程序,因为计算机中丢失 MSVCP120.dll。尝试安装该程序以解决此问题
2 normal mode