本文是典型分布式系统分析系列的第四篇,主要介绍 Dynamo,一个在 Amazon 公司内部使用的去中心化的、高可用的分布式 key-value 存储系统。
在典型分布式系统分析系列的第一篇 MapReduce 中提出了本系列主要关心的问题:
- 系统在性能、可扩展性、可用性、一致性之间的衡量,特别是CAP
- 系统的水平扩展是如何实现的,是如何分片的
- 系统的元数据服务器的性能、可用性
- 系统的副本控制协议,是中心化还是去中心化
- 对于中心化副本控制协议,中心是如何选举的
- 系统还用到了哪些协议、理论、算法
本文的核心目的也是对这些问题进行解答。
本文地址:https://www.cnblogs.com/xybaby/p/13944662.html
Dynamo简介
Dynamo 与之前分析过的 Bigtable,或者笔者使用最多的 NoSql MongoDB 的最大区别,我认为是去中心化(decentralized)。在 Dynamo 中使用的各种技术,如 Vector Clock、Consistent Hash、Gossip 等,一定程度上来说都是因为去中心化。
这里所谓的去中心化,就是在副本集(replicaset)中没有中心节点,所有节点的地位是平等的,大家都可以接受更新请求,相互通过协商达成数据的一致。其优点在于可用性分厂强,但一致性比较弱,基本上都是最终一致性(eventually-consistent),因此,可以说是在 CAP 中选择了 A - Availability。
而去中心化的对立面 -- 中心化,已经在文章 带着问题学习分布式系统之中心化复制集 中做了详细介绍,简而言之,副本集的更新由一个中心节点(Leader、Primary)来执行,最大程度保障一致性,如果中心节点故障,即使有主从切换,也常常导致数十秒的不可用,因此,可以说是在 CAP 中选择了 C - Consistency 。
如何在一致性与可用性之间权衡,这取决于具体的业务需求与应用场景。Dynamo 是在 Amazon 内部使用的一个分布式 KV 存储系统,而 Amazon 作为一个电商网站,高可用是必须的,“always-on”。即使偶尔出现了数据不一致的情况,业务也是可以接受的,而且相对来说也比较好处理不一致,比如论文中提到购物车的例子。
这里需要注意的是,Dynamo 和 DynamDB 是两个不同的东西。前者是 Amazon 内部使用的kv存储,在07年的论文 Dynamo: Amazon's Highly Available Key-value Store 面世;而后者是 AWS 提供的 NoSql 数据存储服务,始于2012。
Dynamo详解
有意思的是,在论文中,并不存在一张所谓的架构图,只有一张表,介绍了Dynamo使用的一些通用技术:
focuses on the core distributed systems techniques used in Dynamo: partitioning, replication, versioning, membership, failure handling and scaling.
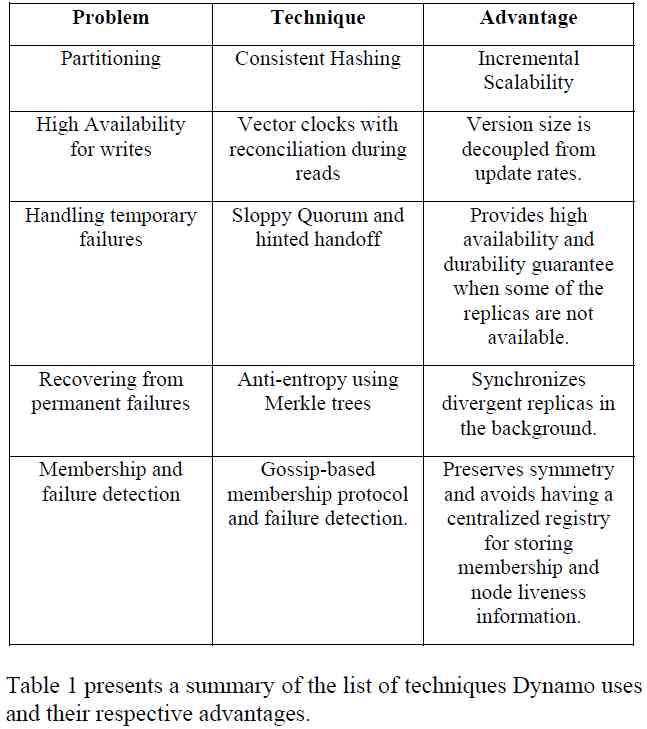
The main contribution of this work for the research community is the evaluation of how different techniques can be combined to
provide a single highly-available system.
正是通过组合这些广为人知(well-known)的技术,实现了这么一个高可用的存储系统。
接下里就具体看看在 Dynamo 中是如何应用这些技术解决相关的问题。
Consistent hash
Dynamo 采用了一致性哈希(consistent hash)作为数据分片(data partition)方式,之前在 带着问题学习分布式系统之数据分片已经介绍过不同的数据分片方式,也包括一致性哈希。简而言之,Consistent hash:
- 是分布式哈希表(DHT, distribution hash table)的一种具体实现
- 元数据(数据到存储节点的映射关系)较少
- 在存储节点加入、退出集群时,对集群的影响较小
- 通过引入虚拟节点(virtual node),能充分利用存储节点的异构信息
一般来说,partition 和 replication 是两个独立的问题,只不过在 Dynamo 中,二者都是基于 consistent hash。
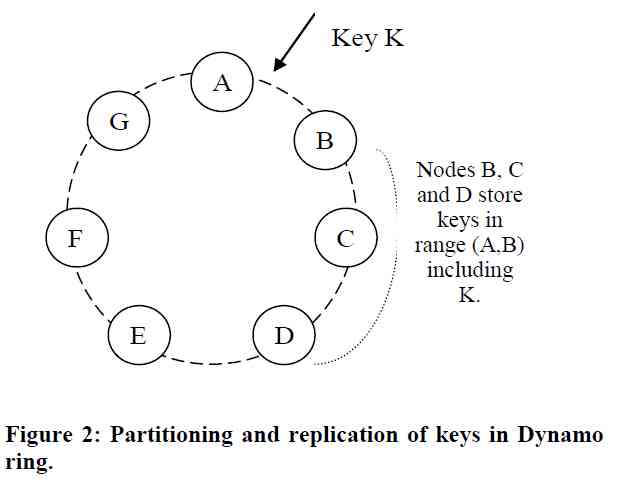
假设副本集数量为 N,那么一个 key 首先映射到对应的 node(virtual node),这个节点被称之为 coordinator,然后被复制到这个coordinator顺时针的 N - 1 个节点上,这就引入了另一个概念 preference list, 即一个 key 应该被存储的节点列表。
如上图所示, Key K 对应的 coordinator 为 node B,与此同时,Node C, D 也会存储 key K 的数据,即其 preference list 为 [B、C、D...]
有两点需要注意:
- 上述的 node 都是虚拟节点,那么为了容错,preference list 应该是不同的物理节点,因此可能跳过环上的某些虚拟节点
- 副本集为 N 时,preference list 的长度会大于 N,这也是为了达到"always writeable“的目标,后面介绍sloppy quorum 和 hinted handoff 会再提及。
Object versioning(vector clock)
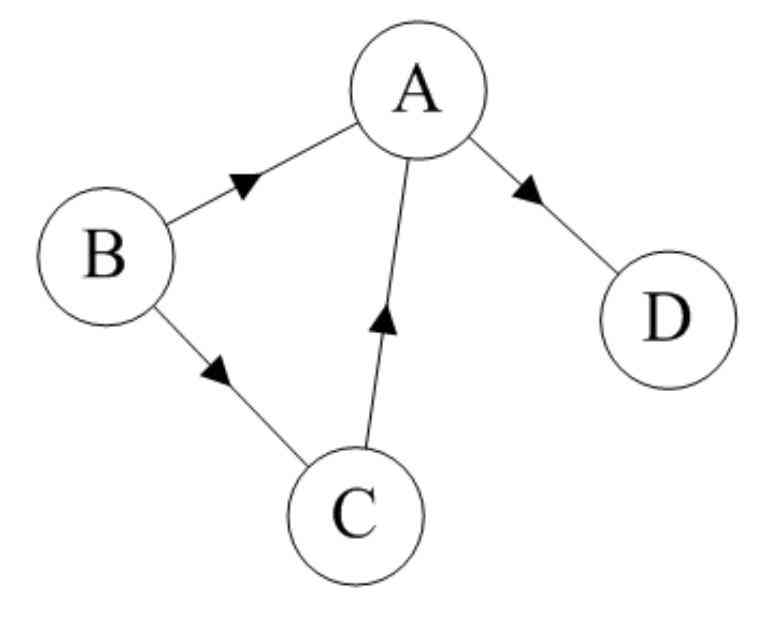
在去中心化副本集中,每个节点都可以接受数据的读写,可能是因为某些 client 无法连接上 coordinator,也可能是为了负载均衡。如果多个节点并发接受写操作,那么可以使用对象版本化(object versioning)来维护不同节点上数据的一致性视图。在 Dynamo 中,则是使用了向量时钟 vector clock 来确定写操作之间的顺序。
vector clock 为每个节点记录一个递增的序号,该节点每次操作的时候,其序号加 1,节点间同步数据、以及从节点读取数据时,也会携带对应的版本号。
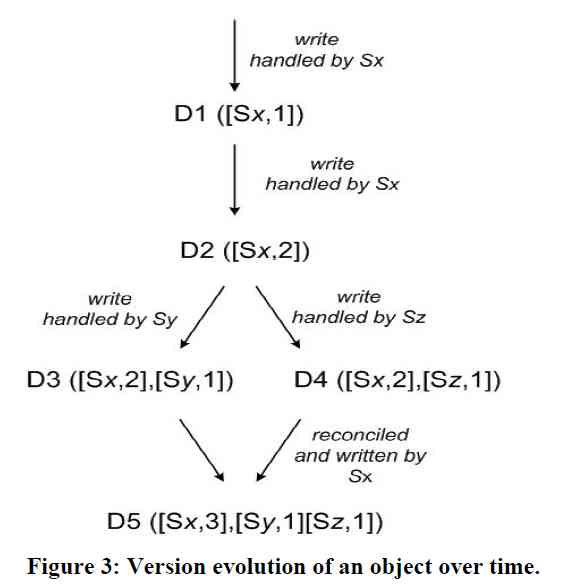
如上图所示,副本集由Sx, Sy, Sz三个节点组成,开始的时候序号都为0,接下来对某个 key 有以下操作:
- 节点Sx接受写操作,value 为 D1,对应的 vector clock 为[Sx, 1]
- 节点Sx再次接受写操作,value 变为 D2,对应的 vector clock 为[Sx, 2]
- 该数据(连同 vector clock)被复制到了节点 Sy,Sz
- 同时发生了一下两个操作
- 节点 Sy 接受写操作,value 变为 D3,对应的 vector clock 为 ([Sx, 2], [Sy, 1])
- 节点 Sz 接受写操作,value 变为 D4,对应的 vector clock 为 ([Sx, 2], [Sz, 1])
- Sy、Sz 将数据同步到 Sx,D3、D4 对应的版本号不具备偏序关系(所谓的偏序关系,即A向量中的每一维都与大于等于B向量的相应维),那么就没法确定这个 key 对应的 value 应该是 D3,还是 D4,因此这两个值都会被存下。
Both versions of the data must be kept and presented to a client (upon a read) for semantic reconciliation.
- 直到在Sx上发生了读操作,读操作的返回值就应该是就是 D3、D4 的列表,客户端决定如何处理冲突,然后将冲突解决后的值 D5 写 到Sx,向量时钟为 [(Sx, 3), (Sy, 1), (Sz, 1)]。此时D5 与 D3、D4 间显然有了偏序关系。
但在上述第六步,如果在节点 Sy 上同时也发生 “读数据 -- 冲突解决” 的过程,写入D6 [(Sx, 3), (Sy, 2), (Sz, 1)], 那么D5、D6又会冲突。
由上可以看到,vector clock 会自动合并有偏序关系的冲突。但逻辑上并发时,vector clock 就无能为力,这时如何解决冲突就面临两个问题
第一:在何时解决冲突?
是在写数据的时候,还是读数据的时候。与众不同的是,Dynamo 选择了在读数据的时候来解决冲突,以保证永远可写(always writeable)。当然,只有在读数据的时候才来处理冲突,也可能导致数据长期处于冲突状态 -- 如果迟迟没有应用来读数据的话。
第二:谁来解决冲突?
是由系统(及Dynamo自身)还是由应用?系统缺乏必要的业务信息,很难在复杂的情况下做出合适的选择,因此只能执行一些简单粗暴的策略,比如 last write win,而这又依赖于 global time,需要配合NTP 一同使用。Dynamo 则是交由应用开发人员来处理冲突,因为具体的应用显然更清楚怎么处理特定环境下的冲突。
那这是否增加了开发人员的负担?在Amazon的技术架构中,一直都是坚持去中心化、面向服务的设计,“Design for failure ” 的设计原则已经成为了系统架构的基本原则,因此这对 Amazon 的程序来说并没有额外的复杂度。
Quorum
Quorum 是一套非常简单的副本管理机制,简而言之,N 个副本中,每次写入要求 W 个副本成功,每次读取从 R 个副本读取,只要 W+R > N,就能保证读取到最新写入的数据。
这个机制很直观,高中的时候就学过,W 和 R 之间一定会有交集。
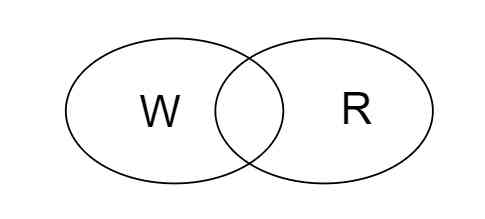
当然,在工程实践中也不是只操作 W 或 R 个节点,而是只需等到 W 或 R 个节点的返回即可,比如在 Dynamo 中,操作都会发给 preference list 中的前 N 个活跃的节点。
Dynamo 中,允许通过配置 R、W、N 参数,使得应用可以综合考虑 可用性、一致性、性能、成本 等因素,选择最适合具体业务的组合方式。这点在Cassandra、Mongodb中也都有相关体现。
不过需要注意的是,DDIA 中指出,即使使用了 quorum,保证了 W+R > N,也还是会有一些 Corner case 使得读到过时的数据(stale data)
- 在不同的节点并发写,发生了冲突,如果系统自动处理冲突,使用了类似 LWW(Last Write Win) 的仲裁机制,由于不同节点上的时钟漂移,可能会出现不一致的情况
- 大多分布式存储,并没有隔离性 Isolation,因此读写并发时,可能读到正在写入的数据
- 如果写失败,即成功写入的数量少于 W,已经写入的节点也不会回滚。
- 还有一种情况,就是 Dynamo 中采用的 Sloppy quorum
Sloppy quorum and hinted handoff
前面提到了preference list,即一个 key 在环中的存储位置列表,虽然副本集数量为 N,但 preference list 的长度一般会超过 N,这是为了保证 “always writable”。比如N=3,W=2 的情况,如果此时有2个节点临时故障,那么按照严格(strict) quorum,是无法写入成功的,但在松散(sloppy) quorum下,就可以将数据写入到一个临时节点。在 Dynamo 中,这个临时节点就会加入到 preference list 的尾端,其实就是一致性哈希环上下一个本来没有该分片的节点。
当然,这个临时节点知道这份数据理论上应该存在的位置,因此会暂存到特殊位置。
The replica sent to temp node will have a hint in its metadata that suggests which node was the intended recipient of the replica
等到数据的原节点(home node)恢复之后,在将数据打包发生获取,这个过程称之为 hinted handoff
因此,sloppy quorums不是传统意义上的Quorum,即使满足 W+R > N,也不能保证读到最新的数据,只是提供更好的写可用性。
Replica synchronization
hinted handoff 只能解决节点的临时故障,考虑这么一个场景,临时节点在将数据前一会 home node 之前,临时节点也故障了,那么home node 中的数据就与副本集中的其他节点数据不一致了,这个时候就需要先找出哪些数据不一致,然后同步这部分数据。
由于写入的 keys 可能在环中的任意位置,那么如何找出哪些地方不一致,从而减少磁盘IO、以及网络传输的数据量,Dynamo 中使用了Merkle Tree。
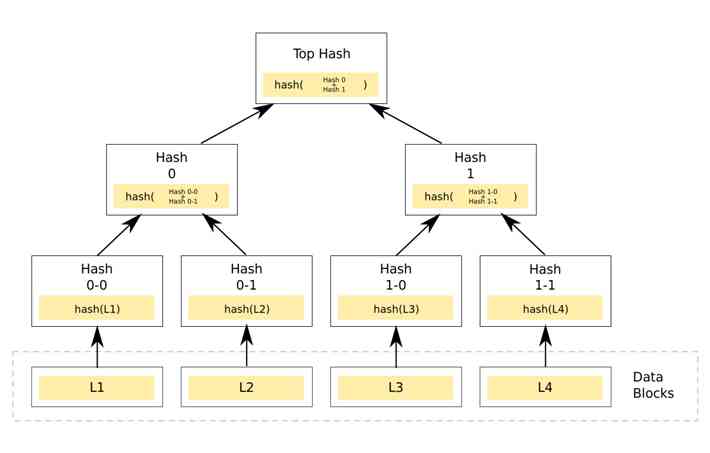
在 Merkle Tree学习 这篇文章中,有比较清晰易懂的介绍,这里只简单总结一下要点:
- 每个叶子节点对应一个data block,并记录其hash值,非叶子节点记录其所有子节点的hash值
- 从根节点开始比较,如果hash值一致,就表示这两棵树一致,否则分别比对左右子树
- 一致递归,直到叶子节点,只需拷贝不一致的叶子节点
具体 Dynamo 是如何应用 Merkle Tree 的呢
- 物理节点为每个虚拟节点维护一棵独立的 Merkle Tree
- 比较时,就按照 Merkle Tree 的作法,从根节点开始比较
Merkle Tree 加速了比对操作,但构建一棵 Merkle Tree 也是较为耗时的过程,那么在加入或删除节点的时候,某个 virtual node 所维护的 key range 就会发生变化,那么就需要重新构建这根 Merkle Tree。
节点加入、删除的影响不止于此,比如在增加节点时,需要迁移一部分 key range,这就需要对原节点的存储文件进行扫描,找出这部分 keys , 然后发送到目标节点,这会带来巨量的IO操作(当然,这高度依赖存储引擎对文件的组织形式)。这些操作是会影响到线上服务的,因此只能在后台缓慢执行,效率很低,论文中提到 上线一台节点需要花费几乎一整天时间。
Advanced partition scheme
问题的本质,在于数据的 partition 依赖于 virtual node 的位置,两个相 邻virtual node 之间的 key range 就是一个 partition,而每一 个partition 对应一个存储单元。这就是论文中说到的
The fundamental issue with this strategy is that the schemes for data partitioning and data placement are intertwined.
data placement 就是指 data 的存放形式,其实就是 virtual node 在哈希环上的位置。
那么解决方案就是解耦 partitioning 和 placement,即数据的 partition 不再依赖 virtual node 在环上的绝对位置。
在Dynamo 中,改进方案如下:将hash环等分为 Q 份,当然 Q 远大于节点的数量,每个节点均为 Q/S 份partition(S 为节点数量),当节点增删时,只需要调整partition到节点的映射关系。
这就解决了前提提到的两个问题:
- 节点增删时,数据的转移以 partition 为单位,可以直接以文件为单位,无需扫描文件再发送,实现 zero copy,更加高效
- 一个 partition 就是一个 Merkle Tree,因此也无需重建 Merkle Tree
这种方案跟 redis cluter 的方案很像,redis cluter也是先划分为 16384 个slot,根据节点数量大致均等的slot分配到不同的节点。
Failure Detection
有意思的是,Dynamo 认为节点的故障是短时的、可恢复的,因此不会采取过激的自动容错,即不会主动进行数据的迁移以实现 rebalance。因此,Dynamo 才用显式机制(explicit mechanism),通过管理员手动操作,向集群中增删节点。
A node outage rarely signifies a permanent departure and therefore should not result in rebalancing of the partition assignment or repair of the unreachable replicas.
这与另外一些系统不一样,如果过半的节点认为某个节点不可用,那么这个节点就会被踢出集群,接下来执行容错逻辑。当然,自动容错是复杂的, 要让过半节点达成某个节点不可用的共识也是复杂的过程。
也许会有疑问,那 Dynamo 这种做法就不能及时响应故障了?会不会导致不可用、甚至丢数据?其实之前提到,Dynamo有 Sloppy quorum 和 hinted handoff 机制,即使对故障的响应有所滞后也是不会有问题的。
因此,Dynamo的故障检测是很简单的,点对点,A 访问不到 B,A 就可以单方面认为 B 故障了。一个例子,假设A在一次数据写入中充当Coordinator,需要操作到B,访问不了B,那么就会在Preference list中找一个节点(如D)来存储B的内容。
Membership
在Dynamo中,并没有一个元数据服务器(metadata server)来管理集群的元数据:比如partition对节点的映射关心。当管理员手动将节点加入、移除hash环后,首先这个映射关系需要发生变化,其次hash环上的所有节点都要知道变动后的映射关系(从而也就知道了节点的增删),达成一致性视图。Dynamo使用了Gossip-Based协议来同步这些信息。
Gossip 协议 这篇文章对Gossip协议有详细的介绍,这里就不再赘述的。不过后面有时间可以看看 Gossip 在redis cluster中的具体实现。
Summary
回答文章开头的问题
- 系统在性能、可扩展性、可用性、一致性之间的衡量,特别是CAP
牺牲一致性,追求高可用
- 系统的水平扩展是如何实现的,是如何分片的
使用一致性hash,先将整个 hash ring 均为为Q 分,然后均等分配到节点
- 系统的元数据服务器的性能、可用性
无额外的元数据服务器,元数据通过Gossip 协议在节点间广播
- 系统的副本控制协议,是中心化还是去中心化
去中心化
- 对于中心化副本控制协议,中心是如何选举的
无
- 系统还用到了哪些协议、理论、算法
Quorum、 Merkle Tree、Gossip
在论文中介绍 Merkle Tree 时,用到了术语 anti-entropy,翻译一下为 反熵,读书时应该学习过 熵 这个概念,不过现在已经忘光了。不严谨的解释为 熵为混乱程度,反熵就是区域稳定、一致,gossip 也就是一个 anti-entropy protocol。
非常有同感的一句话: 系统的可靠性和伸缩性取决于如何管理应用相关的状态
The reliability and scalability of a system is dependent on how its application state is managed.
是无状态 Stateless,还是自己管理,还是交给第三方管理(redis、zookeeper),大大影响了架构的设计。
References
Dynamo: Amazon's Highly Available Key-value Store
[译] [论文] Dynamo: Amazon's Highly Available Key-value Store(SOSP 2007)
![[Python from zero to one] 5. Detailed explanation of beautiful soup basic syntax of web crawler](/img/e8/dd70ddf3c2027907f64674676d676e.jpg)