当前位置:网站首页>Aren't you curious about how the CPU performs tasks?
Aren't you curious about how the CPU performs tasks?
2020-11-09 10:50:00 【InfoQ】
版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
边栏推荐
猜你喜欢

配置交换机Trunk接口流量本地优先转发(集群/堆叠)

重新开始学习离散数学
File queue in Bifrost (1)
Three ways to operate tables in Apache iceberg

Handwritten digital image recognition convolution neural network
3.你知道计算机是如何启动的吗?
美国大选拜登获胜!硅谷的Python开发者用这种方式调侃懂王
商品管理系统——SPU检索功能
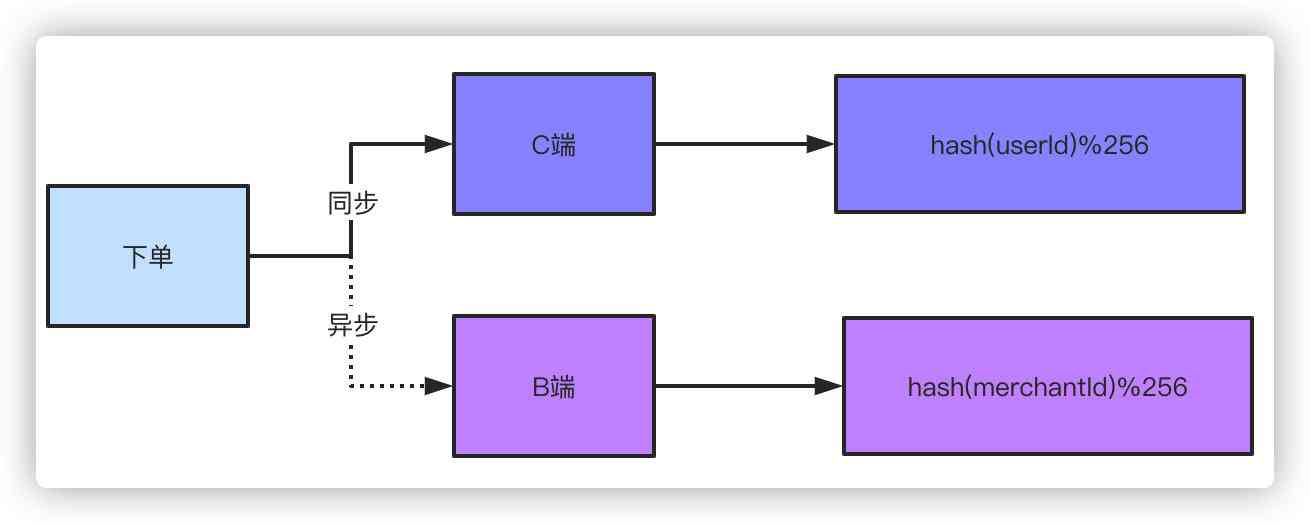
How to query by page after 10 billion level data is divided into tables?
The difference between GDI and OpenGL
随机推荐
Do you know how the computer starts?
商品管理系统——SPU检索功能
Depth analysis based on synchronized lock
Initial installation of linx7.5
JT-day09
Windows环境下如何进行线程Dump分析
SHOW PROFILE分析SQL语句性能开销
JT-day09
Android权限大全
一个简单的能力,决定你是否会学习!
商品管理系统——商品新增本地保存实现部分
GitHub 上适合新手的开源项目(Python 篇)
Application of cloud gateway equipment on easynts in Xueliang project
Service grid is still difficult - CNCF
Android 解决setRequestedOrientation之后手机屏幕的旋转不触发onConfigurationChanged方法
失业日志 11月5日
使用CopyMemory API出现 尝试读取或写入受保护的内存。这通常指示其他内存已损坏。
5 个我不可或缺的开源工具
重新开始学习离散数学
搭建全分布式集群全过程