当前位置:网站首页>Data type case of machine learning -- using data to distinguish men and women based on Naive Bayesian method
Data type case of machine learning -- using data to distinguish men and women based on Naive Bayesian method
2022-07-02 09:07:00 【Qigui】
Author's brief introduction : The most important part of the whole building is the foundation , The foundation is unstable , The earth trembled and the mountains swayed . And to learn technology, we should lay a solid foundation , Pay attention to me , Take you to firm the foundation of the neighborhood of each plate .
Blog home page : Qigui's blog
Included column :《 Statistical learning method 》 The second edition —— Personal notes
From the south to the North , Don't miss it , Miss this article ,“ wonderful ” May miss you la
Triple attack( Three strikes in a row ):Comment,Like and Collect—>Attention
List of articles
Write it at the front
stay 《 Statistical learning method 》 In the fourth chapter of , The author only describes the simple Bayes method roughly , Because the theory is too difficult to understand , With probability ! But it doesn't matter , Theory , I think it's ok if I don't understand it for the first time , I still don't understand it the second time , It's okay. , The third time, I still don't understand , Nothing more ... Maybe you'll think I'm teasing you ? exactly ,, Of course not . The author suggests remembering the formula . When the , You must be asking again : So many formulas , How to remember ? Which ones should I remember ? Then I can only tell you : The Buddha is . Don't talk nonsense , Let's see the actual battle !
Naive Bayes
Naive Bayes is a simple but powerful predictive modeling algorithm , Simplicity lies in the assumption that each feature is independent .
Naive Bayesian model consists of two types of probability :
- 1、 The probability of each category —— P ( C j ) P(C_{j}) P(Cj)
- 2、 Conditional probability of each attribute —— P ( A i ∣ C j ) P(A_{i}|C_{j}) P(Ai∣Cj)
Bayes' formula :
- P ( C j ∣ A i ) = P ( A i ∣ C j ) P ( C j ) P ( A i ) P(C_{j}|A_{i})=\frac {P(A_{i}|C_{j})P(C_{j})}{P(A_{i})} P(Cj∣Ai)=P(Ai)P(Ai∣Cj)P(Cj)
Naive Bayes classifier :
- y = f ( x ) = a r g m a x P ( C j ) ∏ i P ( A i ∣ C j ) ∑ j P ( C j ) ∏ i P ( A i ∣ C j ) y=f(x)=argmax\frac{P(C_{j})\prod_{i}^{}P(A_{i}|C_{j})}{\sum_{j}^{}P(C_{j})\prod_{i}^{}P(A_{i}|C_{j})} y=f(x)=argmax∑jP(Cj)∏iP(Ai∣Cj)P(Cj)∏iP(Ai∣Cj)
- among , The full probability formula is :
- P ( A i ) = ∑ j P ( C j ) ∏ i P ( A i ∣ C j ) P(A_{i})={\sum_{j}^{}P(C_{j})\prod_{i}^{}P(A_{i}|C_{j})} P(Ai)=∑jP(Cj)∏iP(Ai∣Cj)
Denominator to all C j C_{j} Cj All the same :
- y = a r g m a x P ( C j ) ∏ i P ( A i ∣ C j ) y=arg maxP(C_{j})\prod_{i}^{}P(A_{i}|C_{j}) y=argmaxP(Cj)∏iP(Ai∣Cj)
How naive Bayesian classification works
Discrete data cases
- The data are as follows :
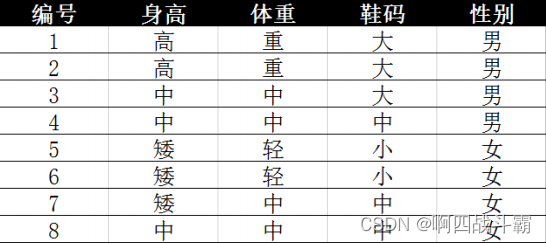
next , Determine the following characteristics :
- height
- weight
- shoe size
also , Set goals as follows :
- Gender
- C1: male
- C2: Woman
- Cj: Unknown
demand :
- Solve whether the gender of the following characteristic data is male or female
- A1: height = high
- A2: weight = in
- A3: shoe size = in
Realization :
- Simply speaking , We only need the probability that the solution is male under this feature , Then solve the probability of being female under this feature , And then compare them , Choose the most likely as the result
P ( C j ∣ A 1 A 2 A 3 ) = P ( A 1 A 2 A 3 ∣ C j ) P ( C j ) P ( A 1 A 2 A 3 ) P(C_{j}|A_{1}A_{2}A_{3})=\frac {P(A_{1}A_{2}A_{3}|C_{j})P(C_{j})}{P(A_{1}A_{2}A_{3})} P(Cj∣A1A2A3)=P(A1A2A3)P(A1A2A3∣Cj)P(Cj)
- Again because A i A_{i} Ai Independent of each other , So it can be converted as follows :
P ( A 1 A 2 A 3 ∣ C j ) = P ( A 1 ∣ C j ) P ( A 2 ∣ C j ) P ( A 3 ∣ C j ) P(A_{1}A_{2}A_{3}|C_{j})=P(A_{1}|C_{j})P(A_{2}|C_{j})P(A_{3}|C_{j}) P(A1A2A3∣Cj)=P(A1∣Cj)P(A2∣Cj)P(A3∣Cj)
- P(Cj|A1A2A3) = (P(A1A2A3|Cj) * P(Cj)) / P(A1A2A3)
- P(A1A2A3|Cj) = P(A1|Cj) * P(A2|Cj) *P(A3|Cj)
- C1 Attribute probability under category condition :
- P(A1|C1) = 2/4 = 1/2
- P(A2|C1) = 1/2
- P(A3|C1) = 1/4
- C2 Attribute probability under category condition :
- P(A1|C2) = 0
- P(A2|C2) =1/2
- P(A3|C2) = 1/2
- P(A1A2A3|C1) = 1/16
- P(A1A2A3|C2) = 0
therefore , regard as P(A1A2A3|C1) > P(A1A2A3|C2), Should be C1 Category , For men .
Continuous data cases
- The data are as follows :
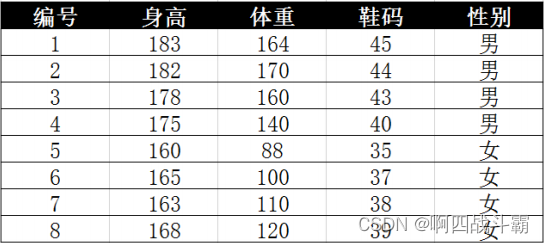
demand :
Solve whether the gender of the following characteristic data is male or female
- height :180
- weight :120
- shoe size :41
The formula is still the above formula , The difficulty here is , Because of height 、 weight 、 Shoe sizes are continuous variables , The method of discrete variables cannot be used to calculate probability . And because there are too few samples , Therefore, it cannot be divided into intervals .
What shall I do? ? At this time , Sure Suppose the height of men and women 、 weight 、 Shoe sizes are normally distributed , Calculate the mean and variance from the sample
That is to say, we get the density function of normal distribution . With the density function , You can substitute the value into , Calculate the value of the density function at a point
such as , The height of men is the average 179.5、 The standard deviation is 3.697 Is a normal distribution . So the height of men is 180 The probability of is 0.1069. How to calculate it ?
from scipy import stats
male_high = stats.norm.pdf(180,male_high_mean,male_high _var)
male_weight = stats.norm.pdf(120, male_weight_mean, male_weight_var)
male_code = stats.norm.pdf(41, male_code_mean, male_code_var)
Realization :
- Suppose the height of men and women 、 weight 、 Shoe sizes are normally distributed
- Calculate the mean and variance from the sample , That is to say, we get the density function of normal distribution
- With the density function , You can substitute the value into , Calculate the value of the density function at a point
import numpy as np
import pandas as pd
# Import data
df = pd.read_excel('table_data.xlsx', sheet_name="Sheet3", index_col=0)
df2 = df.groupby(" Gender ").agg([np.mean, np.var])
# men Of all characteristics mean value And variance
male_high_mean = df2.loc[" male ", " height "]["mean"]
male_high_var = df2.loc[" male ", " height "]["var"]
male_weight_mean = df2.loc[" male ", " weight "]["mean"]
male_weight_var = df2.loc[" male ", " weight "]["var"]
male_code_mean = df2.loc[" male ", " shoe size "]["mean"]
male_code_var = df2.loc[" male ", " shoe size "]["var"]
from scipy import stats
male_high_p = stats.norm.pdf(180, male_high_mean, male_high_var)
male_weight_p = stats.norm.pdf(120, male_weight_mean, male_weight_var)
male_code_p = stats.norm.pdf(41, male_code_mean, male_code_var)
print(' men :', male_high_p * male_weight_p * male_code_p)
# women Of all characteristics mean value And variance
female_high_mean = df2.loc[" Woman ", " height "]["mean"]
female_high_var = df2.loc[" Woman ", " height "]["var"]
female_weight_mean = df2.loc[" Woman ", " weight "]["mean"]
female_weight_var = df2.loc[" Woman ", " weight "]["var"]
female_code_mean = df2.loc[" Woman ", " shoe size "]["mean"]
female_code_var = df2.loc[" Woman ", " shoe size "]["var"]
from scipy import stats
female_high_p = stats.norm.pdf(180, female_high_mean, female_high_var)
female_weight_p = stats.norm.pdf(120, female_weight_mean, female_weight_var)
female_code_p = stats.norm.pdf(41, female_code_mean, female_code_var)
print(' women :', female_high_p * female_weight_p * female_code_p)
print(male_high_p*male_weight_p*male_code_p > female_high_p*female_weight_p*female_code_p)
Written in the back
This is a relatively simple case , Understand that naive Bayes is a generative model , It is a learning process , Constantly adjust cognitive probability .( The generation model is : The result given is not of type , It's probability ) Further understand Bayesian formula , It is helpful to better understand naive Bayesian model .
边栏推荐
- Linux安装Oracle Database 19c
- 【Go实战基础】gin 如何设置路由
- Cartoon rendering - average normal stroke
- Analysis and solution of a classical Joseph problem
- Mysql安装时mysqld.exe报`应用程序无法正常启动(0xc000007b)`
- CSDN Q & A_ Evaluation
- 使用IBM MQ远程连接时报错AMQ 4043解决思路
- How to realize asynchronous programming in a synchronous way?
- 2022/2/14 summary
- NPOI 导出Word 字号对应
猜你喜欢
Finishing the interview essentials of secsha system!!!
Mysql安装时mysqld.exe报`应用程序无法正常启动(0xc000007b)`

C4D quick start tutorial - C4d mapping

以字节跳动内部 Data Catalog 架构升级为例聊业务系统的性能优化
Function ‘ngram‘ is not defined

C language implementation of mine sweeping game
Don't spend money, spend an hour to build your own blog website

WSL installation, beautification, network agent and remote development

Avoid breaking changes caused by modifying constructor input parameters
Service de groupe minecraft
随机推荐
Don't spend money, spend an hour to build your own blog website
我服了,MySQL表500W行,居然有人不做分区?
C#钉钉开发:取得所有员工通讯录和发送工作通知
Minecraft空岛服开服
win10使用docker拉取redis镜像报错read-only file system: unknown
判断是否是数独
Driving test Baodian and its spokesperson Huang Bo appeared together to call for safe and civilized travel
gocv opencv exit status 3221225785
Move a string of numbers backward in sequence
Installing Oracle database 19C RAC on Linux
QT qtimer class
Openshift deployment application
During MySQL installation, mysqld Exe reports that the application cannot start normally (0xc000007b)`
commands out of sync. did you run multiple statements at once
队列的基本概念介绍以及典型应用示例
Qt QTimer类
C# 百度地图,高德地图,Google地图(GPS) 经纬度转换
Illegal use of crawlers, an Internet company was terminated, the police came to the door, and 23 people were taken away
Redis安装部署(Windows/Linux)
Select sort and insert sort