当前位置:网站首页>数据湖(二十):Flink兼容Iceberg目前不足和Iceberg与Hudi对比
数据湖(二十):Flink兼容Iceberg目前不足和Iceberg与Hudi对比
2022-08-04 02:31:00 【Lanson】
Flink兼容Iceberg目前不足和Iceberg与Hudi对比
一、Flink兼容Iceberg目前不足
Iceberg目前不支持Flink SQL 查询表的元数据信息,需要使用Java API 实现。 Flink不支持创建带有隐藏分区的Iceberg表 Flink不支持带有WaterMark的Iceberg表 Flink不支持添加列、删除列、重命名列操作。 Flink对Iceberg Connector支持并不完善。
二、Iceberg与Hudi对比
Iceberg和Hudi都是数据湖技术,从社区活跃度上来看,Iceberg有超越Hudi的趋势。他们有以下共同点:
都是构建于存储格式之上的数据组织方式 提供ACID能力,提供一定的事务、并行执行能力 提供行级别数据修改能力。 提供一定的Schema扩展能力,例如:新增、修改、删除列操作。 支持数据合并,处理小文件。 支持Time travel 查询快照数据。 支持批量和实时数据读写
Iceberg与Hudi之间不同点在于以下几点:
Iceberg支持Parquet、avro、orc数据格式,Hudi支持Parquet和Avro格式。 两者数据存储和查询机制不同
Iceberg只支持一种表存储模式,就是有metadata file、manifest file和data file组成存储结构,查询时首先查找Metadata元数据进而过滤找到对应的 SnapShot对应的manifest files ,再找到对应的数据文件。Hudi支持两种表存储模式:Copy On Write(写时合并) 和Merge On Read(读时合并),查询时直接读取对应的快照数据。
对于处理小文件合并时,Iceberg只支持API方式手动处理合并小文件,Hudi对于小文件合并处理可以根据配置自动的执行。 Spark与Iceberg和Hudi整合时,Iceberg对SparkSQL的支持目前来看更好。Spark与Hudi整合更多的是Spark DataFrame API 操作。 关于Schema方面,Iceberg Schema与计算引擎是解耦的,不依赖任何的计算引擎,而Hudi的Schema依赖于计算引擎Schema。
边栏推荐
- 自制蓝牙手机app控制stm8/stm32/C51板载LED
- 天地图坐标系转高德坐标系 WGS84转GCJ02
- Ant - the design of the Select component using a custom icon (suffixIcon attribute) suffixes, click on the custom ICONS have no reaction, will not display the drop-down menu
- Example 037: Sorting
- LeetCode:899. 有序队列【思维题】
- MallBook联合人民交通出版社,推动驾培领域新发展,开启驾培智慧交易新生态
- Rongyun "Audio and Video Architecture Practice" technical session [complete PPT included]
- 各位大佬好,麻烦问一下flink cdc oracle写入doris的时候,发现cpu异常,一下下跑
- 持续投入商品研发,叮咚买菜赢在了供应链投入上
- 在更一般意义上验算移位距离和假设
猜你喜欢

【学习笔记之菜Dog学C】动态内存管理
织梦响应式酒店民宿住宿类网站织梦模板(自适应手机端)
瑞能微计量芯片RN2026的实用程序
sqoop ETL工具
Small Turtle Compilation Notes
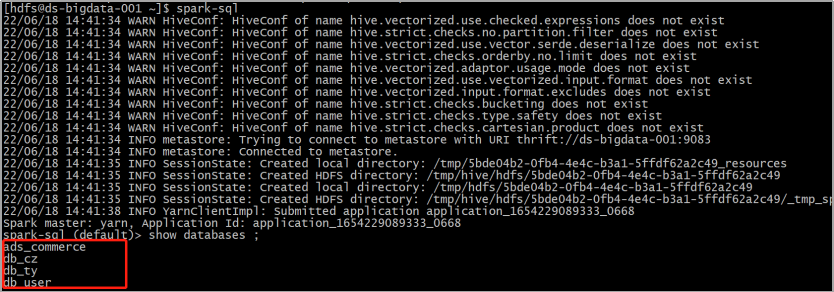
cdh6.x 集成spark-sql
小甲鱼汇编笔记
Development of Taurus. MVC WebAPI introductory tutorial 1: download environment configuration and operation framework (including series directory).
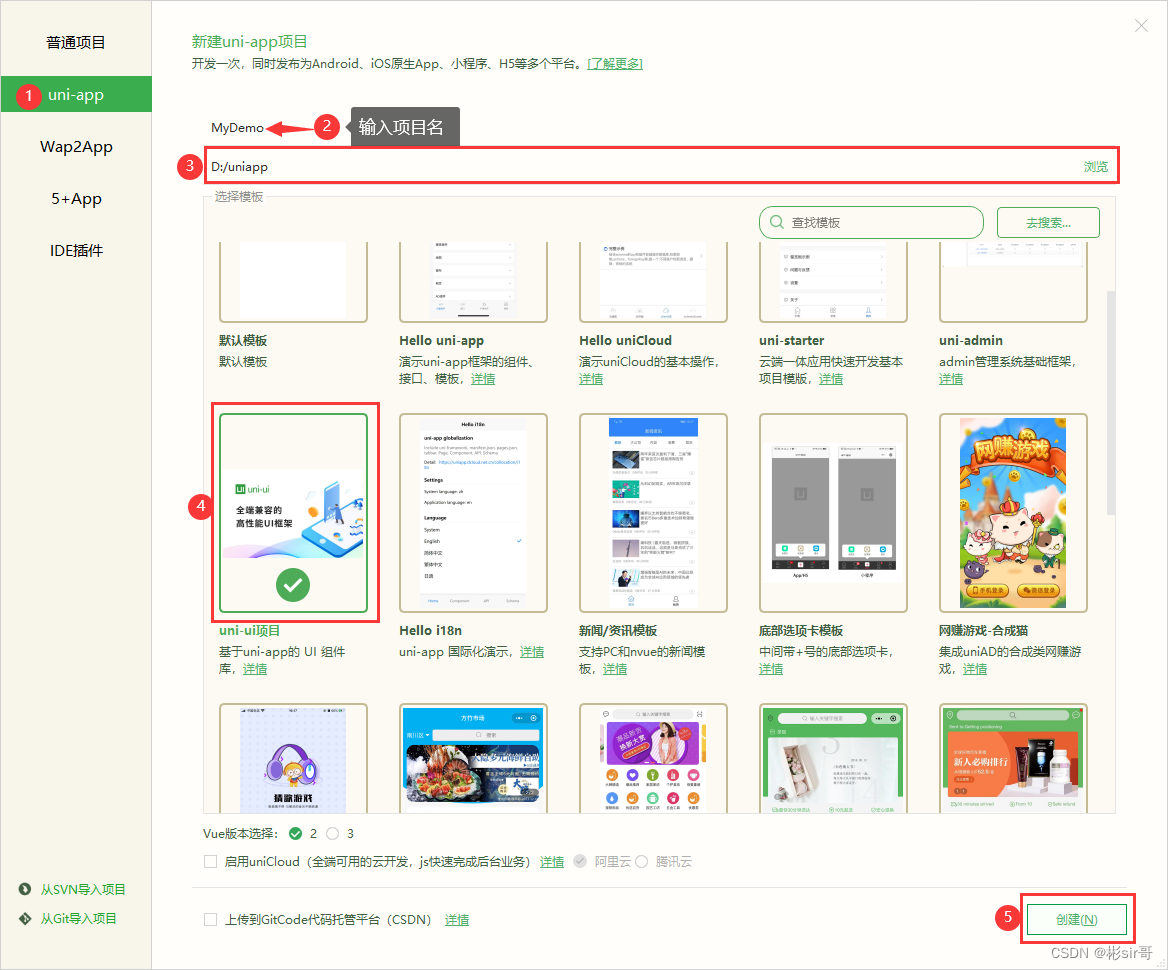
HBuilderX的下载安装和创建/运行项目
Flask框架初学-05-命令管理Manager及数据库的使用
随机推荐
Ant - the design of the Select component using a custom icon (suffixIcon attribute) suffixes, click on the custom ICONS have no reaction, will not display the drop-down menu
融云「音视频架构实践」技术专场【内含完整PPT】
Parquet encoding
Continuing to pour money into commodities research and development, the ding-dong buy vegetables in win into the supply chain
【原创】启动Win10自带的XPS/OXPS阅读器
【云原生】DevOps(六):Jenkins流水线
Development of Taurus. MVC WebAPI introductory tutorial 1: download environment configuration and operation framework (including series directory).
实例039:有序列表插入元素
P3384 【模板】轻重链剖分/树链剖分
Flink原理流程图简单记录
天地图坐标系转高德坐标系 WGS84转GCJ02
Continuing to invest in product research and development, Dingdong Maicai wins in supply chain investment
在更一般意义上验算移位距离和假设
activiti流程执行过程中,数据库表的使用关系
简单排序(暑假每日一题 14)
ssh服务详解
Use of lombok annotation @RequiredArgsConstructor
5. Scrapy middleware & distributed crawler
实例037:排序
2022焊工(初级)上岗证题目模拟考试平台操作