当前位置:网站首页>This year, the AI score of college entrance examination English is 134. The research of Fudan Wuda alumni is interesting
This year, the AI score of college entrance examination English is 134. The research of Fudan Wuda alumni is interesting
2022-06-26 16:04:00 【QbitAl】
bright and quick From the Aofei temple
qubits | official account QbitAI
After the challenge of writing Chinese composition ,AI Now I'm eyeing college entrance examination English .
Turns out, good guy , This year's college entrance examination English ( National A-test paper ) Get started , Just take 134 branch .

And it's not an accidental supernormal play .
stay 2018-2021 Year of 10 In the test of true questions ,AI All scores are 125 More than , The highest record is 138.5 branch , Listening and reading comprehension have also taken Full marks .
That's why CMU Proposed by scholars , College entrance examination English test AI System Qin.
Its parameter quantity is only GPT-3 Of 16 One of the points , The average score is better than GPT-3 Higher than 15 branch .

The secret behind it is called Reconstruction pre training (reStructured Pre-training), It is a new learning paradigm proposed by the author .
The specific term , Is to put Wikipedia 、YouTube And so on , Feed me again AI Training , So that AI It has stronger generalization ability .
The two scholars used enough 100 Multi page The paper of , This new paradigm is explained in depth .

that , What does this paradigm mean ?
Let's dig deep ~
What is refactoring pre training ?
The title of the thesis is very simple , Call reStructured Pre-training( Reconstruction pre training ,RST).

The core point of view is one sentence , want Value data ah !
The author thinks that , Valuable information is everywhere in the world , And now AI The system does not make full use of the information in the data .
Like Wikipedia ,Github, It contains various signals for model learning : Entity , Relationship , Text in this paper, , Text theme, etc . These signals have not been considered before due to technical bottlenecks .
therefore , In this paper, the author proposes a method , Neural network can be used to Storage and access Data containing various types of information .
They are in units of signals 、 Structured presentation data , This is very similar to data science, where we often construct data into tables or JSON Format , And then through special language ( Such as SQL) To retrieve the required information .
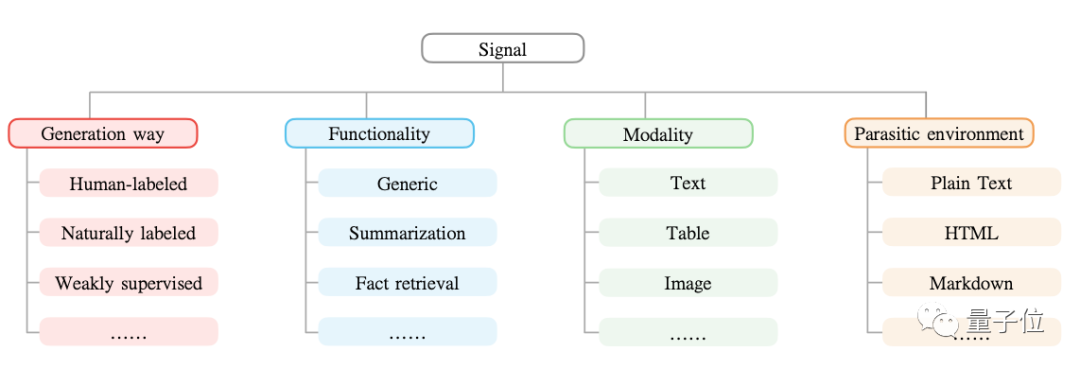
The specific term , The signal here , Actually, it refers to the useful information in the data .
For example “ Mozart was born in Salzburg ” In this sentence ,“ Mozart ”、“ Salzburg ” It's a signal .
then , It is necessary to mine data on various platforms 、 Pick up the signal , The author compares this process to looking for treasure from a mine .

Next , utilize prompt Method , These signals from different places can be unified into one form .
Last , Then integrate and store the reorganized data into the language model .
thus , The research can be started from 10 Data sources , Unified 26 Kind of Different types of signals , Make the model have strong generalization ability .
It turns out that , In multiple datasets ,RST-T、RST-A Zero sample learning performance , all be better than GPT-3 Small sample learning performance .

In order to further test the performance of the new method , The author also thought of making AI Do the college entrance examination Methods .
They said , At present, many working methods are sinicized GPT-3 The idea of , It also follows in the application scenario of evaluation OpenAI、DeepMind.
such as GLUE Evaluation benchmark 、 Protein folding score, etc .
Based on the present AI Observation of model development , The author thinks that we can open up a new track to try , So I thought of using the college entrance examination to AI Practice hands .
They found it for several years 10 Set of test papers for marking , Ask the high school teachers to grade .
Like hearing / Read pictures and understand such topics , And machine vision 、 Scholars in the field of speech recognition help .
Final , This set of college entrance examination English has been refined AI Model , You can also call her Qin.

As you can see from the test results ,Qin It's definitely Xueba level ,10 The scores of the test paper set are all higher than T0pp and GPT-3.

Besides , The author also puts forward the college entrance examination benchmark.
They feel that the task of many evaluation benchmarks is very single , Most of them have no practical value , It is also difficult to compare with human conditions .
The college entrance examination covers a variety of knowledge points , There are also human scores to compare directly , It can be said that killing two birds with one stone .
NLP The fifth paradigm of ?
If you look at it from a deeper level , The author thinks that , Refactoring pre training may become NLP A new paradigm of , Namely the Preliminary training / fine-tuning The process is regarded as data storage / visit The process .
before , The author will NLP The development of has been summed up as 4 There are paradigms :
P1. Fully supervised learning in the age of non neural networks (Fully Supervised Learning, Non-Neural Network)
P2. Fully supervised learning based on neural network (Fully Supervised Learning, Neural Network)
P3. Preliminary training , Fine tuning paradigm (Pre-train, Fine-tune)
P4. Preliminary training , Tips , Prediction paradigm (Pre-train, Prompt, Predict)

But based on the present NLP Observation of development , They thought maybe they could data-centric The way to look at things .
That is to say , Pre training / Fine tune 、few-shot/zero-shot The differentiation of such concepts will be more ambiguous , The core only focuses on one point ——
How much valuable information 、 How much .
Besides , They also put forward a NLP The evolutionary hypothesis .
The core idea is , The direction of technological development always follows this —— Do less to achieve better 、 A more general-purpose system .
The author thinks that ,NLP Experienced Feature Engineering 、 Architecture Engineering 、 Target project 、 Prompt project , At present, it is developing in the direction of data engineering .

Fudan Wuda alumni create
One of the achievements of this thesis Weizhe Yuan.
She graduated from Wuhan University , After that, he went to Carnegie Mellon University for postgraduate study , Study data science .
My research interests focus on NLP Task text generation and evaluation .
last year , She was AAAI 2022、NeurIPS 2021 Received one paper respectively , Also received ACL 2021 Best Demo Paper Award.

The corresponding author of this paper is the Institute of language technology, Carnegie Mellon University (LTI) Postdoctoral researcher of Liu Pengfei .
He is in 2019 He received his doctorate from the Department of computer science of Fudan University in , Under the guidance of Professor Qiu Xipeng 、 Professor Huang xuanjing .
Research interests include NLP Model interpretability 、 The migration study 、 Task learning, etc .
During the doctorate , He has won scholarships in various computer fields , Include IBM Doctoral Scholarship 、 Microsoft scholar Scholarship 、 Tencent AI Scholarship 、 Baidu Scholarship .

One More Thing
It is worth mentioning that , When liupengfei introduced this work to us , To be frank “ At first, we didn't plan to contribute ”.
This is because they do not want the format of the conference paper to limit the imagination of the paper .
We decided to tell this paper as a story , And give “ readers ” A movie experience .
That's why we're on page three , Set up a “ Viewing mode “ The panorama of .
Is to take you to understand NLP History of development , And what the future looks like , So that every researcher can have a certain sense of substitution , Feel yourself leading the pre training language models (PLMs) A process of mine treasure hunt towards a better tomorrow .

The end of the paper , There are also some surprise eggs .
such as PLMs Theme expression pack :

And the illustration at the end :

In this way ,100 Multi page I won't be tired after reading my thesis  ~
~
Address of thesis :
https://arxiv.org/abs/2206.11147
边栏推荐
- NFT 平台安全指南(1)
- Solana capacity expansion mechanism analysis (1): an extreme attempt to sacrifice availability for efficiency | catchervc research
- 为什么图像分割任务中经常用到编码器和解码器结构?
- Application of ansible automation
- 【leetcode】331. 验证二叉树的前序序列化
- svg canvas画布拖拽
- JVM notes
- Auto Sharding Policy will apply Data Sharding policy as it failed to apply file Sharding Policy
- Quickly get started with federal learning -- the practice of Tencent's self-developed federal learning platform powerfl
- CNN optimized trick
猜你喜欢

HW safety response

Simple use of tensor

(一)keras手写数字体识别并识别自己写的数字

Everyone is a scientist free gas experience Mint love crash
![[problem solving] the loading / downloading time of the new version of webots texture and other resource files is too long](/img/31/d14316dca740590c1871efe6587e04.png)
[problem solving] the loading / downloading time of the new version of webots texture and other resource files is too long

Solana扩容机制分析(2):牺牲可用性换取高效率的极端尝试 | CatcherVC Research

How to configure and use the new single line lidar

NFT transaction principle analysis (1)

Anaconda3安装tensorflow 2.0版本cpu和gpu安装,Win10系统
NFT交易原理分析(1)
随机推荐
AUTO sharding policy will apply DATA sharding policy as it failed to apply FILE sharding policy
补齐短板-开源IM项目OpenIM关于初始化/登录/好友接口文档介绍
Solana扩容机制分析(2):牺牲可用性换取高效率的极端尝试 | CatcherVC Research
9 Tensorboard的使用
1 张量的简单使用
现在券商的优惠开户政策是什么?现在在线开户安全么?
手机上怎么开户?在线开户安全么?
Ideal path problem
R语言plotly可视化:小提琴图、多分类变量小提琴图、分组(grouped)小提琴图、分裂的分组小提琴图、每个小提琴图内部分为两组数据、每个分组占小提琴图的一半、自定义小提琴图的调色板、抖动数据点
Swiftui retrieves the missing list view animation
JVM笔记
NFT 平台安全指南(2)
10 tf. data
【leetcode】701. Insert operation in binary search tree
Nanopi duo2 connection WiFi
【时间复杂度和空间复杂度】
Failed to get convolution algorithm. This is probably because cuDNN failed to initialize
神经网络“炼丹炉”内部构造长啥样?牛津大学博士小姐姐用论文解读
Development, deployment and online process of NFT project (2)
Everyone is a scientist free gas experience Mint love crash