当前位置:网站首页>2022CoCa: Contrastive Captioners are Image-Text Fountion Models
2022CoCa: Contrastive Captioners are Image-Text Fountion Models
2022-07-04 19:16:00 【weixin_ forty-two million six hundred and fifty-three thousand 】
Abstract
Exploring the basic model of large-scale pre training is of great significance to computer vision , Because these models can be quickly transferred to many downstream tasks . In this paper, Contrast marker (CoCa), A kind of Minimalist design , Pre train a Images - Text encoder - Decoder model , And combine Compare the loss and mark the loss , Thus, it includes comparison methods such as CLIP And generation methods such as SimVLM Model capability of . Standard encoding with all decoder layers processing encoder output - decoder transformer comparison ,CoCa In the first half of the decoder, cross attention is ignored to encode the multimodal text representation , The remaining decoder layer is cross processed by the image encoder for multimodal image - The text means . We apply contrast loss between unimodal images and text embedding , And applying tagging loss to the output of a multimodal decoder that can automatically regress and predict text tags . By sharing the same calculation diagram , These two training objectives are effectively calculated with the minimum cost .CoCa stay web Perform end-to-end and start from scratch pre training on large-scale alternative text data and annotation images , By simply treating all labels as text , Seamlessly unify the natural language supervision of learning . In experiment ,CoCa The most advanced performance is achieved through zero sample transfer or minimum task specific adaptation on a wide range of downstream tasks , Including visual recognition 、 Cross modal Retrieval 、 Multimodal understanding (VQA) And image annotation .
One 、 Introduce
For the previous pre training model , The output of the decoder is used as the joint representation of the multimodal understanding task in the downstream task . Although pre trained coding - The decoder model achieves better visual language results , But they do not produce a plain text representation aligned with image embedding , Therefore, it is infeasible and inefficient in the task of cross modal alignment .
In this work , We Unified single encoder 、 Dual encoder and encoder - Decoder paradigm , And trained an image that includes the capabilities of all three methods - Text base model . We propose a simple model family , be called Contrast marker (CoCa), With an improved encoder - Decoder structure , Train to compare losses and mark losses . Pictured 1, We Will decoder transformer Decoupling into two parts , A single-mode decoder and a multi-mode decoder . We ignore the cross attention in the single-mode decoder layer to encode the text only representation , Cascaded multimodal decoder layer pays cross attention to the output of image encoder to learn multimodal images - The text means . It is applied between the output of image encoder and single-mode text decoder Compare goals , Apply between the outputs of the multimode decoder Label target . Besides , By simply treating all labels as text , Annotate image data and noisy images - Text data for training . The generation loss on image annotation text provides a fine-grained training signal similar to the single encoder cross entropy loss method , Effectively integrate all three pre training paradigms into a unified approach .
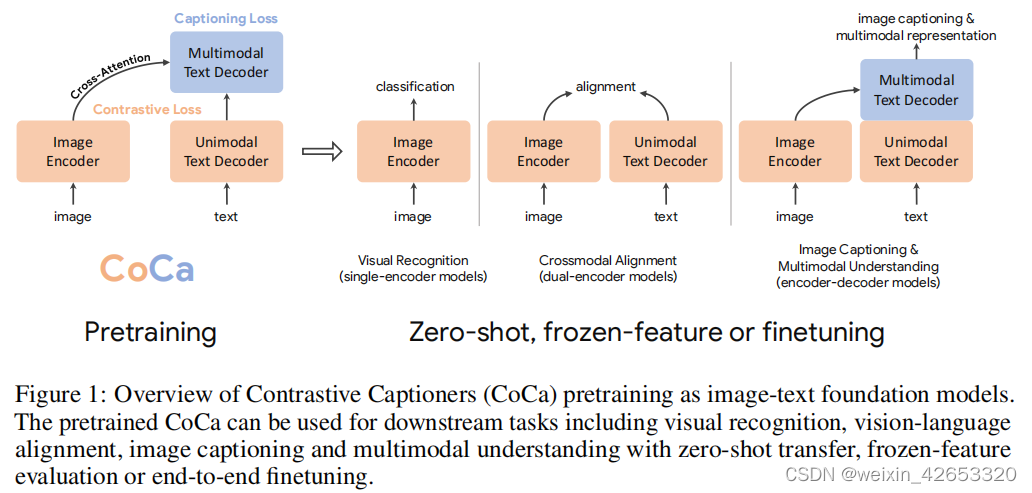
CoCa The design of Use contrast learning to learn global representation and annotation of fine-grained region level features , Thus, it is beneficial to figure 1 All three categories of tasks lost in .CoCa indicate , Use zero sample transfer or minimum task specific adaptation , A single pre training model can be better than many specific models , Such as CoCa stay ImageNet Got it. 86.3% Zero sample accuracy , stay MSCOCO and Flickr30k Get better zero sample cross modal retrieval . Use freeze encoder ,CoCa stay ImageNet Achieve... In classification 90.6%,88.0%/88.5%/81.1% Achieve 88.0%/88.5%/81.1%-40/600/700, Achieve 47.4%. After lightweight fine-tuning ,CoCa stay ImageNet Up to 91.0%, stay VQA Up to 82.3%, stay NoCaps Up to 120.6 Of CIDEr fraction .
Two 、 Related work
Vision - Language pre training Early work (LXMERT、UNITER、VinVL) Depends on the pre training target detection module , Such as Faster R-CNN To extract visual representation . later (ViLT and VLMo) Unified vision and language transformers, And train a multimodal from scratch transformer.
Images - Text base model Proposed image - Text based models can include vision and vision - Language pre training .CLIP and ALIGN prove , In noisy images - Text pairs can learn strong image and text representation by using the dual encoder model pre trained by contrast targets , Used for cross modal alignment tasks and zero sample image classification .Florence The unified comparison target of this method is further developed , Basic training model , It can be applied to a wide range of vision and images - Text datum . In order to further improve the accuracy of zero sample image classification ,LiT[32] and BASIC[33] First, preprocess on the large-scale image annotation data set of cross entropy , And fine tune on the noisy alternative text image data set .[16,17,34] Another research direction of A coding method using generative loss training is proposed - Decoder model , And show strong results in the visual language benchmark , And the visual encoder is still competitive in image classification . This work , We focus on training an image from scratch in a simple pre training phase - Text base model , To unify these methods . although [35,36,37] Recent work has also explored images - Unity of text , But they need multiple pre training stages of single-mode and multi-mode modules to obtain good performance . Such as ALBEF[36] A combination of contrast loss and masking language modeling (MLM) And dual encoder design . However , Our method is simpler , More effective training , It also supports more model functions :(1)CoCa Only for a batch of images - Text pairs perform a forward and backward propagation , and ALBEF You need two ( One is corrupted input , The other one is not damaged );(2)CoCa Start training from scratch on only two goals , and ALBEF Initialize from pre trained visual and text coders , There are additional training signals , Including momentum module ;(3) Decoder architecture with generation loss is the first choice for natural language generation , So as to directly realize image caption and zero sample learning [16].
3、 ... and 、 Method
First, review three basic models of using natural language supervision in different ways : Single encoder classification pre training 、 Dual encoder contrast learning and coding - Decoder image annotation . Then introduce the contrast marker (CoCa), stay Under a simple framework, it has the advantages of both comparative learning and image to annotation generation . Further discussion on CoCa Model How to quickly transfer to downstream tasks through zero sample transfer or minimum task adaptation .
3.1 Natural language Supervision
Single encoder classification The classic single encoder method annotates data sets in large multi-source images ( Such as ImageNet[9]、it[20] or JFT[21]) Image classification on , Pre classify the visual encoder , The vocabulary of annotation text is usually fixed . These image annotations are usually mapped to discrete class vectors , Learn by cross entropy loss :
![]()
among ,p(y) It's a real label from the ground y Single heat 、 How hot or smooth the label distribution . The learned image encoder is then used for downstream tasks Universal visual representation extractor .
Dual encoder contrast learning Compared with the pre training of single encoder classification that requires manual annotation of labels and data cleaning , The double encoder method utilizes the noisy network scale text description , A learnable text tower is introduced to encode free-form text . Compare the paired text of the two encoders with the others for joint optimization :

Besides image encoder , The dual encoder method also learns an aligned text encoder , Align across modes , Such as images - Text retrieval and zero sample image classification .
Encoder - Decoder annotation Although the dual encoder method encodes the text as a whole , But the generation method (a.k.a. Header ) The goal of is detailed granularity , And require the model to predict with automatic regression y Precise tokenized text . According to the standard encoder - Decoder architecture , Image coders provide potential coding features ( for example , Use a visual transformer [39] or ConvNets[40]), The text decoder learns to maximize the pair of texts under the forward autoregressive decomposition y Conditional likelihood :
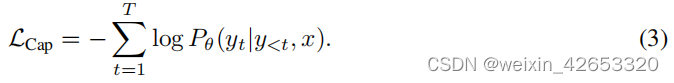
Use teachers to force [41] Coding - Decoder training , Maximize the efficiency of parallel computing and learning . Different from the previous method , The annotator method produces a joint image - The text means , It can be used for visual language understanding , And it can also generate image annotation applications through natural language .
3.2 Contrast marker pre training

chart 2 Indicates the comparison locator (CoCa): A simple encoder - Decoder method , Seamlessly combines these three training modes . With standard images - Text encoder - The decoder model is similar ,CoCa The image is encoded by neural network encoder as a potential representation , Such as ViT( By default , It can also be ConvNets), And use a causal mask transformer Decoder decodes text . With standard decoder transformer Different ,CoCa In the first half of the decoder layer, cross attention is omitted to encode the multimodal text representation , And cascade the other decoder layers , Cross focus image encoder for multimodal image - The text means . therefore ,CoCa The decoder generates both single-mode and multimodal text representations , Enables us to apply comparison and generate targets at the same time :
![]()
among ,λCon and λCap Loss weighted hyperparameter . We noticed that , When the vocabulary is a collection of all tag names , The single encoder cross entropy classification target can be interpreted as a special case applied to the generation method of image annotation data .
Decouple text decoder and CoCa framework Annotation method optimizes the conditional possibility of text , The comparison method uses unconditional text representation . To solve this dilemma , And combine these two methods into a single model , We propose a simple Decoupling decoder design , By skipping the cross attention mechanism in the single-mode decoder layer , The decoder is divided into single-mode and multi-mode components . namely , Bottom nuni The single-mode decoder layer encodes the input text into a potential vector with causal masking self attention , At the top of the nuni The multimodal layer further applies causal masking self attention and cross attention to the output of the visual encoder . All decoder layers prohibit tags from paying attention to future tags , also The output of the multimodal text decoder can be directly used to label the target LCap. For comparison purposes LCon, We added a learnable at the end of the input sentence [CLS] Mark , And the output of its corresponding single-mode decoder is embedded as text . We divide the decoder into two halves , such nuni=nmulti. according to ALBEF, We use an image resolution of 288×288, The patch size is 18×18 pretraining , All in all 256 An image marker . Our biggest CoCa Model ( abbreviation “CoCa”) follow [21] Medium vit-giant Set up , The image encoder has 1B Parameters ,2.1 individual b Parameter and text decoder . We also explored tables 1 In detail “CoCa-Base and CoCa-Large” Two smaller variants of .
Pooling of attention It is worth noting that , Contrast loss using a single embedding for each image , The decoder usually deals with the encoder - Decoder annotator [16] Image output tag sequence in . Our preliminary experiments show that , A single pooled image embedding helps visual recognition tasks as a global representation , And more visual signs ( Therefore, it is more fine-grained ) It is beneficial to multimodal understanding tasks that require region level features . therefore ,CoCa Use task specific attention pooling [42] To customize visual representation , Used for different types of training goals and downstream tasks . ad locum , The pool feeder is a simple multi head attention layer , have nquery Learnable queries , The encoder output is both a key and a value . Through this , The model can be learned to pool two training targets into embeddeds of different lengths , Pictured 2 Shown . The use of task specific pooling not only solves the different needs of different tasks , It also introduces a Pooler as a natural task adapter . We are generating losses nquery=256 And comparative losses nquery=1 The attention pool is used in the pre training of .
Pre training efficiency A key advantage of decoupling autoregressive decoder design is , It can calculate two training losses that are effectively considered . Because the one-way language model is to conduct causal masking training on complete sentences , The decoder can effectively generate the output of contrast loss and generation loss through a single forward propagation ( And the two-way approach [36] Compared with the two passes of ). therefore , Most calculations are shared between the two losses , With standard encoder - Compared with decoder model ,CoCa Minimal overhead . On the other hand , Although many existing methods [30,32,33,35,36,37] In various data sources and / Or use multiple stage training model components on the mode , but CoCa It is directly related to various data sources ( That is, annotation image and noise replace text image ) Do end-to-end pre training , Use all tags as text for comparison and generation targets .
3.3 Comparison annotator for downstream tasks
Zero sample transfer Pre trained CoCa The model uses image and text input , Perform many tasks with zero samples , Including zero sample image classification 、 Zero sample image - Text cross search 、 Zero sample video - Text cross search . According to previous practice [12,32], there “ Zero shot ” Different from the classic zero shot learning , In pre training , The model can see the relevant supervision information , However, the monitoring example is not used in the transmission protocol . For pre training data , We followed [13,32] The strict De duplication program To filter all near field examples into our downstream tasks .
Freeze feature evaluation As mentioned in the previous section ,CoCa Use task specific attention pooling [42]( It's called Pooler for short ) Customize different types of visual representations for downstream tasks , At the same time, share the trunk encoder . This enables the model to achieve strong performance as a freeze encoder , Among them, we only learn a new Pooler to aggregate features . It can also benefit from the multi task problem of sharing the same frozen image encoder calculation but different task specific headers . As in [23] As discussed in , Linear evaluation is difficult to accurately measure the learned representation , We find that attention pool is more practical in practical applications .
For video action recognition CoCa
Four 、 experiment
Our results are carried out in three types of downstream tasks : Zero sample transfer 、 Freeze feature evaluation and fine tuning . We also propose that ablation experiments include pre training objectives and structural design .
4.1 Training settings
data :CoCa By simply treating all labels as text , From the beginning web Pre training on the scale of alternative text data and annotated images . We use JFT-3B Data sets [21] As paired text , And replace the text with noise ALIGN Data sets [13]. We also train all model parameters from scratch , Without pre training the image coder with supervised cross entropy loss , To ensure simplicity and pre training efficiency . To ensure a fair assessment , We followed [13,32] Strict de duplication procedures introduced in , Filter all near field examples ( A total of 360 10000 images ) To our downstream tasks . To mark the text, enter , We use a sentence block model [43,44], Train vocabulary on the sampled pre training data set 64k.
Optimizer : Our model is in Lingvo frame [45] Implemented in , And use GSPMD[46,47,48,49] To scale performance .
4.2 The main result
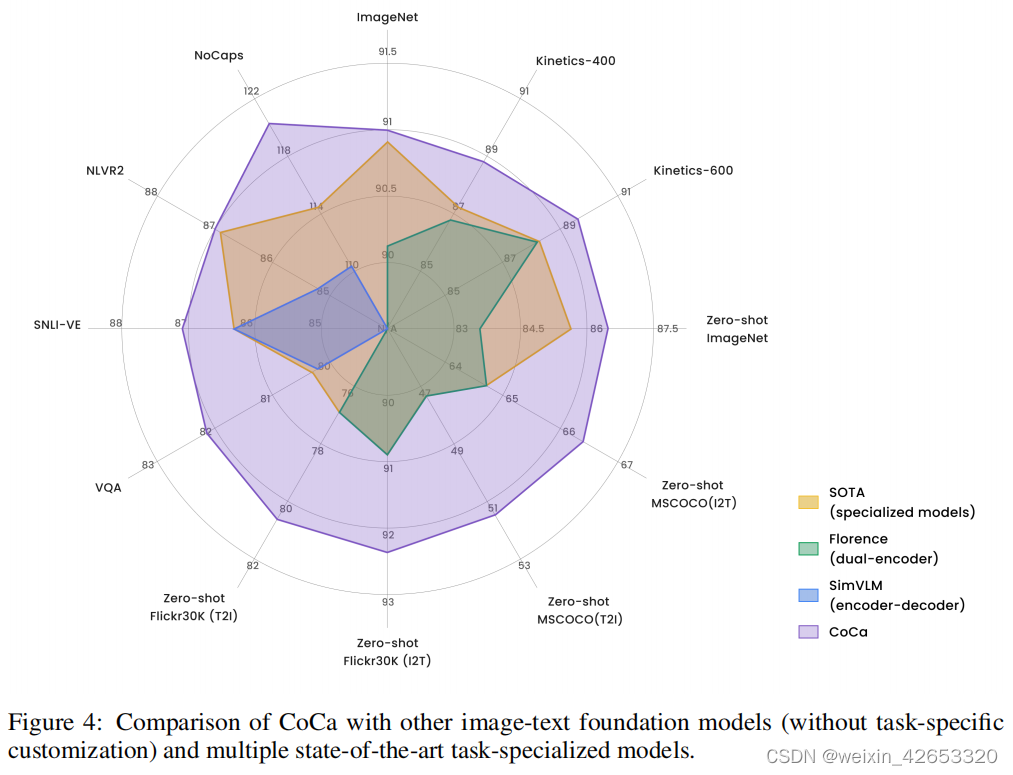
because CoCa At the same time, it produces aligned single-mode representation and fused multi-mode embedding , Therefore, it is easy to transfer to all three task groups with minimal adaptability . chart 4 Summed up with other dual encoders and encoders - The basic model of decoder is compared with the most advanced task specific method ,CoCa Performance on key benchmarks .
4.2.3 Multimodal understanding task
in general , Experimental results show that ,CoCa In addition to the visual and retrieval capabilities as a dual encoder method , It also takes advantage of the decoder model , Thus, a powerful multimodal understanding and generation ability is obtained .
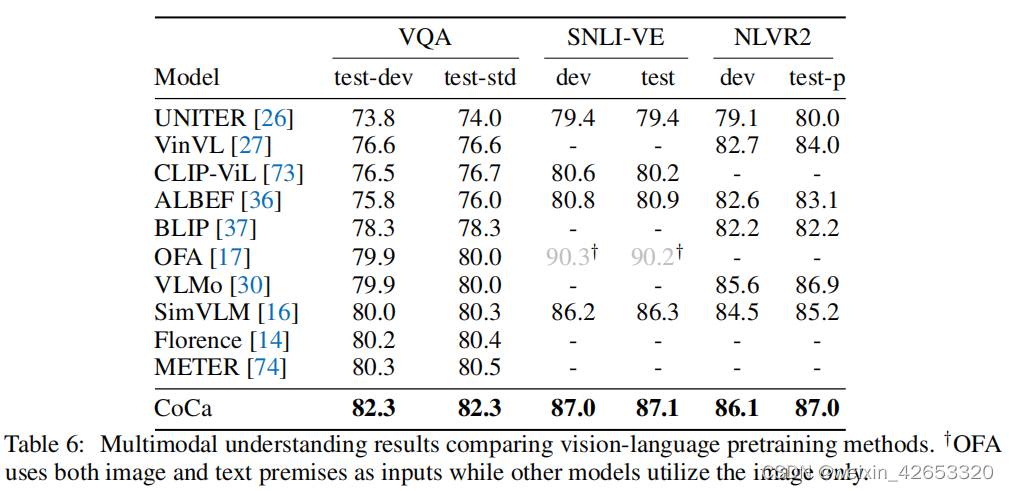
Multimodal understanding Such as [16] Shown , Encoder - The output of the decoder model can be combined with encoded image and text input , And it can be used for tasks that need to reason about these two patterns . We mainly follow [16] Settings in , And train a linear classifier on the output of the decoder to predict the answer ( See Appendix for more details B). We are on the table 6 The results in show that ,CoCa Better than strong visual language pre training (VLP) The baseline , And achieved the most advanced performance on all three tasks . Although the previous dual encoder model [12,14] Does not contain fusion layers , Therefore, for the downstream multimodal understanding task, an additional VL Pre training stage , but CoCa It includes three pre training paradigms , And through lightweight fine-tuning in VL Better performance on the task .
4.3 Ablation analysis
5、 ... and 、 Wider impact
This work presents an image on a network scale dataset - Text pre training method , This method can be transferred to a wide range of downstream tasks in the form of zero lens or through lightweight fine-tuning . Although the pre trained model can perform many visual and visual language tasks , But we noticed that , Our model uses the same method as before [13,21,32,33] The same pre training data , Before using models in practice , Additional data analysis is necessary . We showed CoCa The model is more robust to damaged images , But it is still vulnerable to other image corruption , These damages have not been captured by the current evaluation set or in real scenes . For data and models , Further community exploration is needed to understand the wider impact , Including but not limited to fairness 、 Social prejudice and potential abuse .
6、 ... and 、 Conclusion
In this work , We proposed Contrast catcher (CoCa), A new image - Text base model family , it It includes the existing visual pre training paradigm and natural language supervision .CoCa In one stage, images from different data sources - The text pairs are pre trained , And in the encoder - The decoder model effectively combines Compare the target with the subtitle target .CoCa On a wide range of visual and visual language issues , A series of state-of-the-art performance is achieved through a single breakpoint . Our work has bridged the gap between various pre training methods , We hope it can be an image - Text based models inspire new directions .
边栏推荐
猜你喜欢

Li Kou brush question diary /day7/6.30
Lex and yacc based lexical analyzer + parser

Li Kou brush question diary /day2/2022.6.24
建立自己的网站(15)
Process of manually encrypt the mass-producing firmware and programming ESP devices

一种将Tree-LSTM的强化学习用于连接顺序选择的方法

神经网络物联网平台搭建(物联网平台搭建实战教程)
Nebula importer data import practice
Behind the ultra clear image quality of NBA Live Broadcast: an in-depth interpretation of Alibaba cloud video cloud "narrowband HD 2.0" technology
vbs或vbe如何修改图标
随机推荐
Perfect JS event delegation
1、 Introduction to C language
利用策略模式优化if代码【策略模式】
删除字符串中出现次数最少的字符【JS,Map排序,正则】
正则替换【JS,正则表达式】
Li Kou brush question diary /day5/2022.6.27
启牛开的证券账户安全吗?
信息学奥赛一本通 1336:【例3-1】找树根和孩子
力扣刷题日记/day4/6.26
物联网应用技术的就业前景和现状
LeetCode第300场周赛(20220703)
千万不要只学 Oracle、MySQL!
Interpretation of SIGMOD '22 hiengine paper
技术分享 | 接口测试价值与体系
基于C语言的菜鸟驿站管理系统
Scala basic tutorial -- 20 -- akka
国元期货是正规平台吗?在国元期货开户安全吗?
Learning path PHP -- phpstudy "hosts file does not exist or is blocked from opening" when creating the project
奥迪AUDI EDI INVOIC发票报文详解
力扣刷题日记/day2/2022.6.24