当前位置:网站首页>PyTorch(六)——PyTorch可视化
PyTorch(六)——PyTorch可视化
2022-08-02 02:53:00 【一蓑烟雨晴】
文章目录
datawhale 深入浅出PyTorch
可视化网络结构
随着深度神经网络的发展,网络的结构越来越复杂,我们也很难确定每一层的输入结构,输出结构以及参数等信息,这样导致我们很难在短时间内完成debug。因此掌握一个可以用来可视化网络结构的工具是十分有必要的。为了解决这个问题,人们开发了torchinfo工具包 ( torchinfo是由torchsummary和torchsummaryX重构出的库, torchsummary和torchsummaryX已经许久没更新了) 。本节我们将介绍如何使用torchinfo来可视化网络结构。
使用print函数打印模型基础信息
在本节中,我们将使用ResNet18的结构进行展示。
import torchvision.models as models
model = models.resnet18()
通过上面的两步,我们就得到resnet18的模型结构。在学习torchinfo之前,让我们先看下直接print(model)的结果。
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
... ...
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
我们可以发现单纯的print(model),只能得出基础构件的信息,既不能显示出每一层的shape,也不能显示对应参数量的大小。
使用torchinfo可视化网络结构
- torchinfo的安装
# 安装方法一
pip install torchinfo
# 安装方法二
conda install -c conda-forge torchinfo
- torchinfo的使用
trochinfo的使用也是十分简单,我们只需要使用torchinfo.summary()就行了,必需的参数分别是model,input_size[batch_size,channel,h,w]
import torchvision.models as models
from torchinfo import summary
resnet18 = models.resnet18() # 实例化模型
summary(resnet18, (1, 3, 224, 224)) # 1:batch_size 3:图片的通道数 224: 图片的高宽
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNet [1, 1000] --
├─Conv2d: 1-1 [1, 64, 112, 112] 9,408
├─BatchNorm2d: 1-2 [1, 64, 112, 112] 128
├─ReLU: 1-3 [1, 64, 112, 112] --
├─MaxPool2d: 1-4 [1, 64, 56, 56] --
├─Sequential: 1-5 [1, 64, 56, 56] --
│ └─BasicBlock: 2-1 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-1 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-2 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-3 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-4 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-5 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-6 [1, 64, 56, 56] --
│ └─BasicBlock: 2-2 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-7 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-8 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-9 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-10 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-11 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-12 [1, 64, 56, 56] --
├─Sequential: 1-6 [1, 128, 28, 28] --
│ └─BasicBlock: 2-3 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-13 [1, 128, 28, 28] 73,728
│ │ └─BatchNorm2d: 3-14 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-15 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-16 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-17 [1, 128, 28, 28] 256
│ │ └─Sequential: 3-18 [1, 128, 28, 28] 8,448
│ │ └─ReLU: 3-19 [1, 128, 28, 28] --
│ └─BasicBlock: 2-4 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-20 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-21 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-22 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-23 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-24 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-25 [1, 128, 28, 28] --
├─Sequential: 1-7 [1, 256, 14, 14] --
│ └─BasicBlock: 2-5 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-26 [1, 256, 14, 14] 294,912
│ │ └─BatchNorm2d: 3-27 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-28 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-29 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-30 [1, 256, 14, 14] 512
│ │ └─Sequential: 3-31 [1, 256, 14, 14] 33,280
│ │ └─ReLU: 3-32 [1, 256, 14, 14] --
│ └─BasicBlock: 2-6 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-33 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-34 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-35 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-36 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-37 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-38 [1, 256, 14, 14] --
├─Sequential: 1-8 [1, 512, 7, 7] --
│ └─BasicBlock: 2-7 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-39 [1, 512, 7, 7] 1,179,648
│ │ └─BatchNorm2d: 3-40 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-41 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-42 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-43 [1, 512, 7, 7] 1,024
│ │ └─Sequential: 3-44 [1, 512, 7, 7] 132,096
│ │ └─ReLU: 3-45 [1, 512, 7, 7] --
│ └─BasicBlock: 2-8 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-46 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-47 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-48 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-49 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-50 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-51 [1, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-9 [1, 512, 1, 1] --
├─Linear: 1-10 [1, 1000] 513,000
==========================================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
Total mult-adds (G): 1.81
==========================================================================================
Input size (MB): 0.60
Forward/backward pass size (MB): 39.75
Params size (MB): 46.76
Estimated Total Size (MB): 87.11
==========================================================================================
我们可以看到torchinfo提供了更加详细的信息,包括模块信息(每一层的类型、输出shape和参数量)、模型整体的参数量、模型大小、一次前向或者反向传播需要的内存大小等
CNN可视化
卷积神经网络(CNN)是深度学习中非常重要的模型结构,它广泛地用于图像处理,极大地提升了模型表现,推动了计算机视觉的发展和进步。但CNN是一个“黑盒模型”,人们并不知道CNN是如何获得较好表现的,由此带来了深度学习的可解释性问题。如果能理解CNN工作的方式,人们不仅能够解释所获得的结果,提升模型的鲁棒性,而且还能有针对性地改进CNN的结构以获得进一步的效果提升。
理解CNN的重要一步是可视化,包括可视化特征是如何提取的、提取到的特征的形式以及模型在输入数据上的关注点等。
CNN卷积核可视化
卷积核在CNN中负责提取特征,可视化卷积核能够帮助人们理解CNN各个层在提取什么样的特征,进而理解模型的工作原理。例如在Zeiler和Fergus 2013年的paper中就研究了CNN各个层的卷积核的不同,他们发现靠近输入的层提取的特征是相对简单的结构,而靠近输出的层提取的特征就和图中的实体形状相近了。
在PyTorch中可视化卷积核也非常方便,核心在于特定层的卷积核即特定层的模型权重,可视化卷积核就等价于可视化对应的权重矩阵。下面给出在PyTorch中可视化卷积核的实现方案,以torchvision自带的VGG11模型为例。
首先加载模型,并确定模型的层信息:
import torch
from torchvision.models import vgg11
model = vgg11(pretrained=True)
print(dict(model.features.named_children()))
{
'0': Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'1': ReLU(inplace=True),
'2': MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
'3': Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'4': ReLU(inplace=True),
'5': MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
'6': Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'7': ReLU(inplace=True),
'8': Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'9': ReLU(inplace=True),
'10': MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
'11': Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'12': ReLU(inplace=True),
'13': Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'14': ReLU(inplace=True),
'15': MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
'16': Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'17': ReLU(inplace=True),
'18': Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'19': ReLU(inplace=True),
'20': MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)}
卷积核对应的应为卷积层(Conv2d),这里以第“3”层为例,可视化对应的参数:
import sys
plt.rcParams.update({
'figure.max_open_warning': 0})
conv1 = dict(model.features.named_children())['3']
kernel_set = conv1.weight.detach()
num = len(conv1.weight.detach())
print(kernel_set.shape)
for i in range(0,1):
i_kernel = kernel_set[i]
plt.figure(figsize=(20, 17))
if (len(i_kernel)) > 1:
for idx, filer in enumerate(i_kernel):
plt.subplot(9, 9, idx+1)
plt.axis('off')
plt.imshow(filer[ :, :].detach(),cmap='bwr')
plt.show()
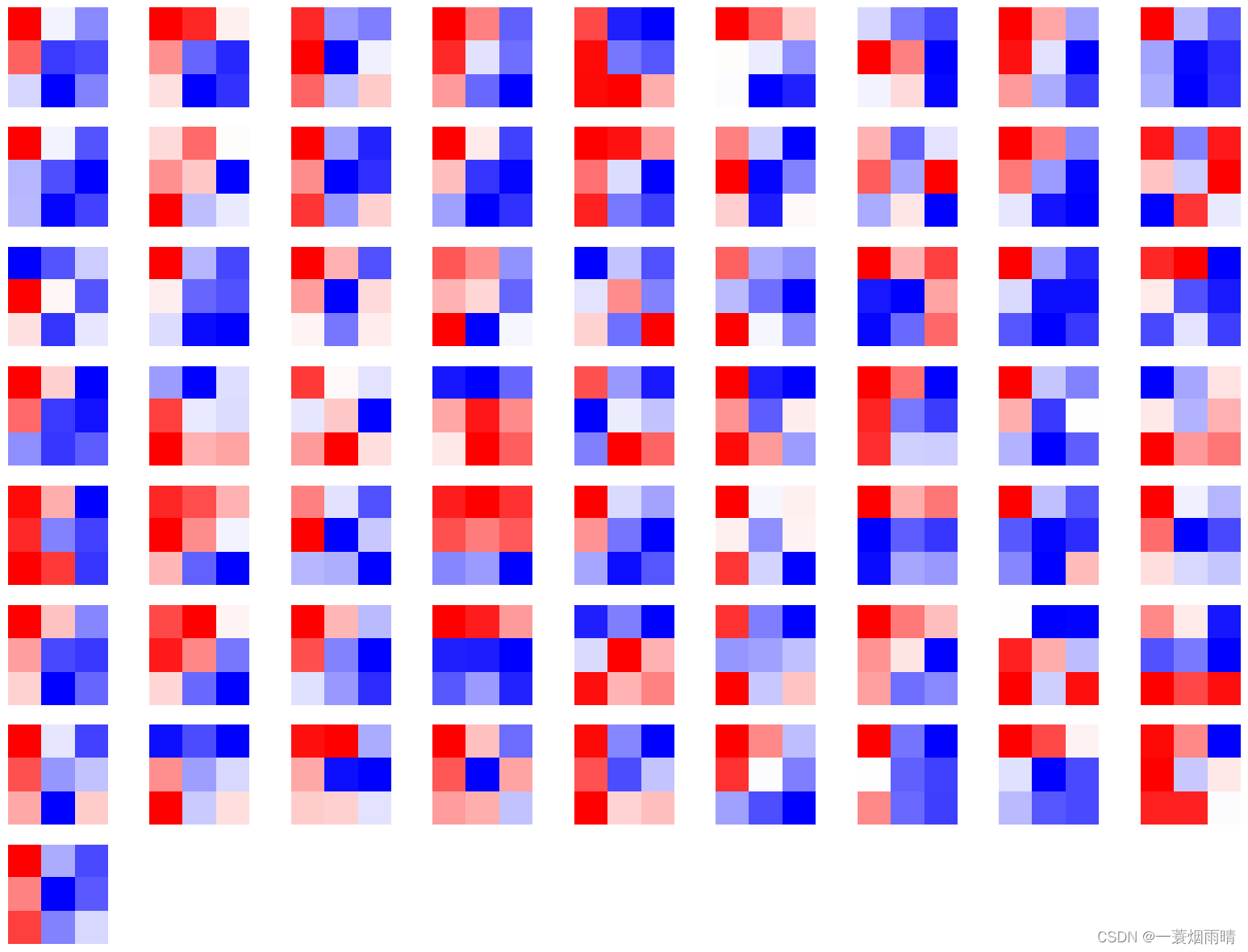
CNN特征图可视化方法
与卷积核相对应,输入的原始图像经过每次卷积层得到的数据称为特征图,可视化卷积核是为了看模型提取哪些特征,可视化特征图则是为了看模型提取到的特征是什么样子的。
获取特征图的方法有很多种,可以从输入开始,逐层做前向传播,直到想要的特征图处将其返回。尽管这种方法可行,但是有些麻烦了。在PyTorch中,提供了一个专用的接口使得网络在前向传播过程中能够获取到特征图,这个接口的名称非常形象,叫做hook。可以想象这样的场景,数据通过网络向前传播,网络某一层我们预先设置了一个钩子,数据传播过后钩子上会留下数据在这一层的样子,读取钩子的信息就是这一层的特征图。具体实现如下:
class Hook(object):
def __init__(self):
self.module_name = []
self.features_in_hook = []
self.features_out_hook = []
def __call__(self, module, fea_in, fea_out):
print("hooker working", self)
self.module_name.append(module.__class__)
self.features_in_hook.append(fea_in)
self.features_out_hook.append(fea_out)
return None
def plot_feature(model, idx, inputs):
hh = Hook()
model.features[idx].register_forward_hook(hh)
# forward_model(model, False)
model.eval()
_ = model(inputs)
print(hh.module_name)
print(hh.features_in_hook[0][0].shape)
print(hh.features_out_hook[0].shape)
out1 = hh.features_out_hook[0]
total_ft = out1.shape[1]
first_item = out1[0].cpu().clone()
plt.figure(figsize=(20,17))
for ftidex in range(total_ft):
if ftidex > 99:
break
ft = first_item[ftidex]
plt.subplot(10, 10, ftidx+1)
plt.axis('off')
#plt.imshow(ft[:,:].detach(),cmap='gray')
plt.imshow(ft[:,:].detach())
plt.show()
from matplotlib import pyplot as plt
from torchvision.models import vgg11
import torch
model = vgg11(pretrained=True)
image_tensor = torch.randn(1, 3, 224, 224)
plot_feature(model, 10, image_tensor)
torch.Size([1, 256, 56, 56])
torch.Size([1, 256, 28, 28])

这里我们首先实现了一个hook类,之后在plot_feature函数中,将该hook类的对象注册到要进行可视化的网络的某层中。model在进行前向传播的时候会调用hook的__call__函数,我们也就是在那里存储了当前层的输入和输出。这里的features_out_hook 是一个list,每次前向传播一次,都是调用一次,也就是features_out_hook 长度会增加1。
CNN class activation map可视化方法
class activation map (CAM)的作用是判断哪些变量对模型来说是重要的,在CNN可视化的场景下,即判断图像中哪些像素点对预测结果是重要的。除了确定重要的像素点,人们也会对重要区域的梯度感兴趣,因此在CAM的基础上也进一步改进得到了Grad-CAM(以及诸多变种)。CAM和Grad-CAM的示例如下图所示:
相比可视化卷积核与可视化特征图,CAM系列可视化更为直观,能够一目了然地确定重要区域,进而进行可解释性分析或模型优化改进。CAM系列操作的实现可以通过开源工具包pytorch-grad-cam来实现。
使用TensorBoard可视化训练过程
边栏推荐
- 22-08-01 西安 尚医通(01)跨域配置、Swagger2、R类、统一异常处理和自定义异常、Logback日志
- 忽晴忽雨
- * Compare version numbers
- AcWing 1285. 单词 题解(AC自动机)
- 灰度传感器、、、diy原理。。图
- 【LeetCode】104. Maximum depth of binary tree
- Heuristic merge, DSU on Tree
- AcWing 1285. Word Problem Solving (AC Automata)
- iVX低代码平台系列详解 -- 概述篇(二)
- Go语学习笔记 - gorm使用 - gorm处理错误 Web框架Gin(十)
猜你喜欢
feign调用不通问题,JSON parse error Illegal character ((CTRL-CHAR, code 31)) only regular white space (r

"Paid paddling" stealthily brushes Brother Ali's face scriptures, challenges bytes three times, and finally achieves positive results

analog IC layout-Parasitic effects
![[Daily LeetCode]——1. The sum of two numbers](/img/11/8a68f4ecb24fa19e3c804d536cdbec.png)
[Daily LeetCode]——1. The sum of two numbers
aws s3 upload file
面试必备!TCP协议经典十五连问!

KICAD 小封装拉线卡顿问题 解决方法

2022牛客多校四_G M
svm.SVC应用实践1--乳腺癌检测

Flask 报错:WARNING This is a development server. Do not use it in a production deployment
随机推荐
Qt自定义控件和模板分享
合奥科技网络 面试(含参考答案)
Common SQL interview questions: 50 classic examples
(1) Redis: Key-Value based storage system
搭建zabbix监控及邮件报警(超详细教学)
* Compare version numbers
MySQL8.0.28安装教程
就瞎写=感想
canal同步Mariadb到Mysql
指针数组和数组指针
- daily a LeetCode 】 【 9. Palindrome
“带薪划水”偷刷阿里老哥的面经宝典,三次挑战字节,终成正果
递归检查配置项是否更变并替换
【CNN记录】tensorflow slice和strided_slice
IPFS部署及文件上传(golang)
2022年最新一篇文章教你青龙面板拉库,拉取单文件,安装依赖,设置环境变量,解决没有或丢失依赖can‘t find module之保姆教程(附带几十个青龙面板脚本仓库)
(一)Redis: 基于 Key-Value 的存储系统
esp32经典蓝牙和单片机连接,,,手机蓝牙作为主机
Go简单实现协程池
analog IC layout