当前位置:网站首页>svm.SVC应用实践1--乳腺癌检测
svm.SVC应用实践1--乳腺癌检测
2022-08-02 02:32:00 【夺笋123】
决策边界绘制函数封装
参考书籍:《scikit-learn机器学习:常用算法原理及编程实战》
参考博客:基于支持向量机的数据分类以及绘制决策边界(超平面)
代码
import matplotlib.pyplot as plt
import numpy as np
def plot_hyperplane(clf, X, y,
h=0.02,
draw_sv=True,
title='hyperplan'):
x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1
y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1
# 生成网格点坐标矩阵,其中参数h控制间距
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
plt.title(title)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())
plt.yticks(())
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) # SVM的分割超平面
Z = Z.reshape(xx.shape)
# 为坐标矩阵的不同类别的点填充不同的颜色
plt.contourf(xx, yy, Z, cmap='hot', alpha=0.5)
plt.scatter(X[:,0],X[:,1],c=y)
# 是否将支持向量突出表示
if draw_sv:
sv = clf.support_vectors_
plt.scatter(sv[:, 0], sv[:, 1], c='r', marker='.',s=1)
plt.show()
该函数基于matplotlib库中的contourf()函数,可以画出等高线并填充颜色的函数
预测示例
1. 简单的数据点
import numpy as np
from sklearn.pipeline import make.pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
x=np.array([[-1,-1],[-2,-1],[1,1],[2,1]])
y=np.array([1,1,2,2])
clf=make_pipeline(StandardScaler(),SVC(gamma='atuo'))
clf.fit(x,y)
clf.predict([[-0.8,-1]])
>>> [1]
此处我们要注意make_pipeline()函数与StandardScaler()函数的联合使用,常用于构建管道pipeline,数据预处理、模型拟合等操作“一条龙”!
2. 生成数据点
接下来我们首先生成一个有两个特征、三种类别的数据集
from sklean.datasets import make_blobs
x,y=make_blobs(n_samples=100,centers=3,random_state=0,cluster_std=0.8)
然后使用线性核函数、三阶多项式核函数、 g a m m a gamma gamma=0.5、 g a m m a gamma gamma=0.1等4个SVC模型来拟合数据集,分别观察拟合效果
from sklearn.svm import SVC
clf_linear=svm.SVC(C=1.0,kernel='linear')
clf_poly=svm.SVC(C=1.0,kernel='poly',degree=3)
clf.rbf=svm.SVC(C=1.0,kernel='rbf',gamma=0.5)
clf_rbf2=svm.SVC(C=1.0,kernel='rbf',gamma=0.1)
最后将4个模型拟合出来的超平面画出来
plt.figure(figsize=(10,10),dpi=144)
clfs=[clf_linear,clf_poly,clf_rbf,clf_rbf2]
title=['linear','poly','rbf','rbf2']
for clf,i in zip(clfs,range(len(clfs))):
clf.fit(x,y)
plt.subplot(2,2,i+1)
plot_hyperplane(clf,x,y,title=title[i])
运行结果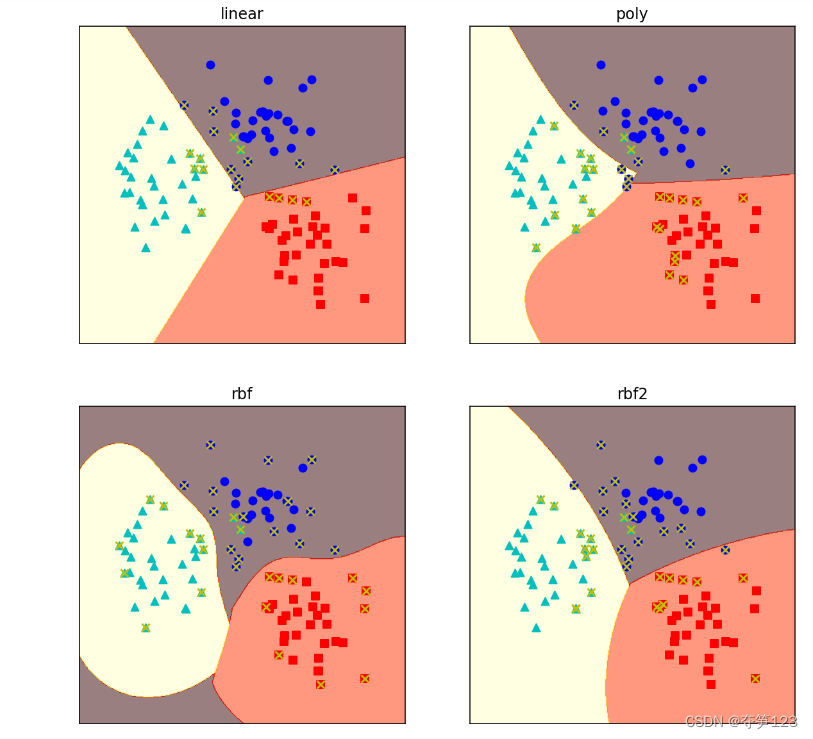 通过上面例子我们发现,当支持向量机使用不同的核函数进行分类时候,绘制出的决策边界也会随着改变
通过上面例子我们发现,当支持向量机使用不同的核函数进行分类时候,绘制出的决策边界也会随着改变
对于高斯核函数,gamma值过大会造成过拟合,过小则会使得高斯核函数退化为线性核函数,我们可以通过调节gamma的值来调整分隔超平面的形状
3. 乳腺癌数据集
首先我们加载出数据集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
x=cancer.data
y=cancer.target
分割出训练集与测试集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2)
接下来我们使用不同的核函数对应的模型对数据进行拟合
高斯核函数
我们首先尝试使用高斯核函数训练模型,分别得到训练集得分和测试集得分
from sklearn.svm import SVC
clf=SVC(C=1.0,kernel='rbf',gamma=0.1)
clf.fit(x_train,y_train)
train_score=clf.score(x_train,y_train)
test_score=clf.score(x_test,y_test)
train_score,test_score
>>> (0.98778345781,0.52631578949)
通过观察实验结果,我们发现训练集接近满分,测试集评分很低,典型的过拟合现象!由于我们使用的是高斯核函数,所以我们可以尝试改变gamma参数值来调整模型的表现
from sklearn.model_selection import GridSearchCV
gammas=np.linspace(0,0.0003,30)
grid={
'gamma':gammas}
clf=GridSearchCV(SVC(),grid,cv=5)
clf.fit(x,y)
clf.best_params_,clf.best_score_
>>> ({
'gamma': 0.00011379310344827585}, 0.9367334264865704)
此处注意GridSearchCV()函数的常用于参数选择
在最好的gamma参数下,平均最优得分也只有0.93…,说明该核函数对于该问题并非最合适的。
但是我们同样可以通过学习曲线观察模型的拟合情况,取gamma=0.01
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
cv=ShuffleSplit(n_splits=10,test_size=0.2,random_state=0)
title='gaussian kernel'
plt.figure(figsize=(10,4),dpi=144)
plot_learning_curve(SVC(C=1.0,gamma=0.01),title,x,y,cv=cv)
运行结果
学习曲线的封装请参考sklearn官方api:plot_learning_curve()函数,
也可以参考笔者的博客:学习曲线的封装–learning_curve()函数
交叉验证得分过低,明显的过拟合现象,下面我们尝试改变核函数
多项式核函数
from sklearn.svm import SVC
clf=SVC(C=1.0,kernel='poly',degree=2)
clf.fit(x_train,y_train)
train_score=clf.score(x_train,y_train)
test_score=clf.score(x_test,y_test)
train_score,test_score
>>> (0.9186813186813186, 0.9122807017543859)
训练集和测试集两者的得分都比较高,看起来结果还可以,接下来我们分别画出一阶多项式、二阶多项式学习曲线
from sklearn.model_selection import learning_curve
cv=ShuffleSplit(n_splits=5,test_size=0.2,random_state=0)
degrees=[1,2]
plt.figure(figsize=(12,4),dpi=144)
for i in range(len(degrees)):
plt.subplot(1,len(degrees),i+1)
title='degree_{}'.format(degrees[i])
plot_learning_curve(SVC(C=1.0,kernel='poly',degree=degrees[i]),title,x,y,cv=cv)
我们可以看出,与一阶多项式相比,二阶多项式核函数的拟合效果较好,但仍然不是最理想的情况

实际上,从模型拟合结果以及运算效率等方面来看,支持向量机模型对于乳腺癌检测的问题或许并非是最优选择,其他模型在解决这一问题时或许能够达到更加理想的结果,因为在针对实际问题时,前期模型的选择非常重要
边栏推荐
猜你喜欢
BI-SQL丨WHILE
![[Server data recovery] Data recovery case of server Raid5 array mdisk disk offline](/img/08/d693c7e2fff8343b55ff3c1f9317c6.jpg)
[Server data recovery] Data recovery case of server Raid5 array mdisk disk offline
Project Background Technology Express
Service discovery of kubernetes

Talking about the "horizontal, vertical and vertical" development trend of domestic ERP

详解最强分布式锁工具:Redisson
数值积分方法:欧拉积分、中点积分和龙格-库塔法积分

Power button 1374. Generate each character string is an odd number

Flask之路由(app.route)详解

字符串常用方法
随机推荐
Simple example of libcurl accessing url saved as file
Reflex WMS Intermediate Series 7: What should I do if I want to cancel the picking of an HD that has finished picking but has not yet been loaded?
永磁同步电机36问(二)——机械量与电物理量如何转化?
53. 最小的k个数
【web】理解 Cookie 和 Session 机制
架构:微服务网关(SIA-Gateway)简介
四元数、罗德里格斯公式、欧拉角、旋转矩阵推导和资料
isa指针使用详情
内卷的正确打开方式
最大层内元素和
Docker-compose安装mysql
FOFAHUB使用测试
Flask之路由(app.route)详解
Nanoprobes纳米探针丨Nanogold偶联物的特点和应用
qt点云配准软件
欧拉公式的证明
JS中获取对象数据类型的键值对的键与值
Safety (1)
记一次gorm事务及调试解决mysql死锁
JVM调优实战