当前位置:网站首页>一次SQL优化,数据库查询速度提升 60 倍
一次SQL优化,数据库查询速度提升 60 倍
2022-08-02 02:16:00 【澎湖Java架构师】
导语
sql的性能优化能够帮助我们优化数据查询时间,本篇主要向大家介绍了10000w的数据在sql优化后查询速度提升60倍的优化过程。
正文
有一张财务流水表,未分库分表,目前的数据量为9555695,分页查询使用到了limit,优化之前的查询耗时16 s 938 ms (execution: 16 s 831 ms, fetching: 107 ms),按照下文的方式调整SQL后,耗时347 ms (execution: 163 ms, fetching: 184 ms);
操作:
查询条件放到子查询中,子查询只查主键ID,然后使用子查询中确定的主键关联查询其他的属性字段;
原理:
1、减少回表操作;
2、可参考《阿里巴巴Java开发手册(泰山版)》第五章-MySQL数据库、(二)索引规约、第7条:
【推荐】利用延迟关联或者子查询优化超多分页场景。
说明:
MySQL并不是挑过offeset行,而是取offset+N行,然后返回放弃前offset行,返回N行,那当offset特别大的时候,效率就非常的底下,要么控制返回的总页数,要么对超过特定阈值的页数进行SQL改写。在此我向大家推荐一个架构学习交流圈。交流学习指导伪鑫:1253431195(里面有大量的面试题及答案)里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构等这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多
正例:
先快速定位需要获取的id段,然后再关联:
SELECT a.* FROM 表1 a,(select id from 表1 where 条件 LIMIT 100000,20) b where a.id = b.id;
-- 优化前SQLSELECT 各种字段FROM `table_name`WHERE 各种条件LIMIT 0,10;
- 优化后SQLSELECT 各种字段FROM `table_name` main_taleRIGHT JOIN (SELECT 子查询只查主键FROM `table_name`WHERE 各种条件LIMIT 0,10;) temp_table ON temp_table.主键 = main_table.主键
一、前言
首先说明一下MySQL的版本:
mysql> select version();+-----------+| version() |+-----------+| 5.7.17 |+-----------+1 row in set (0.00 sec)
表结构:
mysql> desc test;+--------+---------------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+--------+---------------------+------+-----+---------+----------------+| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment || val | int(10) unsigned | NO | MUL | 0 | || source | int(10) unsigned | NO | | 0 | |+--------+---------------------+------+-----+---------+----------------+3 rows in set (0.00 sec)
id为自增主键,val为非唯一索引。
灌入大量数据,共500万:
mysql> select count(*) from test;+----------+| count(*) |+----------+| 5242882 |+----------+1 row in set (4.25 sec)
我们知道,当limit offset rows中的offset很大时,会出现效率问题:
mysql> select * from test where val=4 limit 300000,5;+---------+-----+--------+| id | val | source |+---------+-----+--------+| 3327622 | 4 | 4 || 3327632 | 4 | 4 || 3327642 | 4 | 4 || 3327652 | 4 | 4 || 3327662 | 4 | 4 |+---------+-----+--------+5 rows in set (15.98 sec)
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;+---------+-----+--------+---------+| id | val | source | id |+---------+-----+--------+---------+| 3327622 | 4 | 4 | 3327622 || 3327632 | 4 | 4 | 3327632 || 3327642 | 4 | 4 | 3327642 || 3327652 | 4 | 4 | 3327652 || 3327662 | 4 | 4 | 3327662 |+---------+-----+--------+---------+5 rows in set (0.38 sec)
为了达到相同的目的,我们一般会改写成如下语句:
时间相差很明显。
为什么会出现上面的结果?我们看一下select * from test where val=4 limit 300000,5;的查询过程:
- 查询到索引叶子节点数据。
- 根据叶子节点上的主键值去聚簇索引上查询需要的全部字段值。
类似于下面这张图:
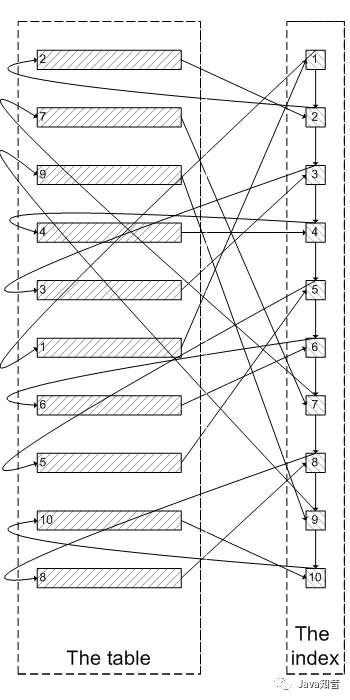
像上面这样,需要查询300005次索引节点,查询300005次聚簇索引的数据,最后再将结果过滤掉前300000条,取出最后5条。MySQL耗费了大量随机I/O在查询聚簇索引的数据上,而有300000次随机I/O查询到的数据是不会出现在结果集当中的。在此我向大家推荐一个架构学习交流圈。交流学习指导伪鑫:1253431195(里面有大量的面试题及答案)里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构等这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多
肯定会有人问:既然一开始是利用索引的,为什么不先沿着索引叶子节点查询到最后需要的5个节点,然后再去聚簇索引中查询实际数据。这样只需要5次随机I/O,类似于下面图片的过程:
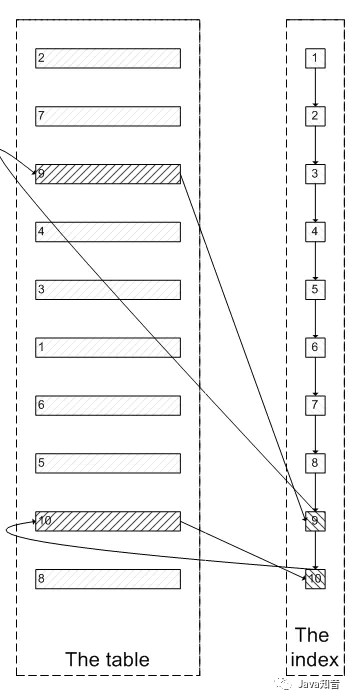
其实我也想问这个问题。
证实
下面我们实际操作一下来证实上述的推论:
为了证实select * from test where val=4 limit 300000,5是扫描300005个索引节点和300005个聚簇索引上的数据节点,我们需要知道MySQL有没有办法统计在一个sql中通过索引节点查询数据节点的次数。我先试了Handler_read_*系列,很遗憾没有一个变量能满足条件。
我只能通过间接的方式来证实:
InnoDB中有buffer pool。里面存有最近访问过的数据页,包括数据页和索引页。所以我们需要运行两个sql,来比较buffer pool中的数据页的数量。预测结果是运行select * from test a inner join (select id from test where val=4 limit 300000,5); 之后,buffer pool中的数据页的数量远远少于select * from test where val=4 limit 300000,5;对应的数量,因为前一个sql只访问5次数据页,而后一个sql访问300005次数据页。
select * from test where val=4 limit 300000,5
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;Empty set (0.04 sec)
可以看出,目前buffer pool中没有关于test表的数据页。
mysql> select * from test where val=4 limit 300000,5;+---------+-----+--------+| id | val | source |+---------+-----+--------+| 3327622 | 4 | 4 || 3327632 | 4 | 4 || 3327642 | 4 | 4 || 3327652 | 4 | 4 || 3327662 | 4 | 4 |+---------+-----+--------+5 rows in set (26.19 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;+------------+----------+| index_name | count(*) |+------------+----------+| PRIMARY | 4098 || val | 208 |+------------+----------+2 rows in set (0.04 sec)
可以看出,此时buffer pool中关于test表有4098个数据页,208个索引页。
select * from test a inner join (select id from test where val=4 limit 300000,5) ;为了防止上次试验的影响,我们需要清空buffer pool,重启mysql。
mysqladmin shutdown/usr/local/bin/mysqld_safe &
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;Empty set (0.03 sec)
运行sql:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;+---------+-----+--------+---------+| id | val | source | id |+---------+-----+--------+---------+| 3327622 | 4 | 4 | 3327622 || 3327632 | 4 | 4 | 3327632 || 3327642 | 4 | 4 | 3327642 || 3327652 | 4 | 4 | 3327652 || 3327662 | 4 | 4 | 3327662 |+---------+-----+--------+---------+5 rows in set (0.09 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;+------------+----------+| index_name | count(*) |+------------+----------+| PRIMARY | 5 || val | 390 |+------------+----------+2 rows in set (0.03 sec)
我们可以看明显的看出两者的差别:第一个sql加载了4098个数据页到buffer pool,而第二个sql只加载了5个数据页到buffer pool。符合我们的预测。也证实了为什么第一个sql会慢:读取大量的无用数据行(300000),最后却抛弃掉。
而且这会造成一个问题:加载了很多热点不是很高的数据页到buffer pool,会造成buffer pool的污染,占用buffer pool的空间。
遇到的问题
为了在每次重启时确保清空buffer pool,我们需要关闭innodb_buffer_pool_dump_at_shutdown和innodb_buffer_pool_load_at_startup,这两个选项能够控制数据库关闭时dump出buffer pool中的数据和在数据库开启时载入在磁盘上备份buffer pool的数据。、
边栏推荐
- 2022-08-01 安装mysql监控工具phhMyAdmin
- 【 wheeled odometer 】
- 拼多多借力消博会推动国内农产品品牌升级 看齐国际精品农货
- Force buckle, 752-open turntable lock
- Scheduled tasks for distributed applications in Golang
- 软件测试 接口自动化测试 pytest框架封装 requests库 封装统一请求和多个基础路径处理 接口关联封装 测试用例写在yaml文件中 数据热加载(动态参数) 断言
- 考完PMP学什么?前方软考等着你~
- 用位运算为你的程序加速
- Handwritten Blog Platform ~ Day Two
- Pinduoduo leverages the consumer expo to promote the upgrading of domestic agricultural products brands and keep pace with international high-quality agricultural products
猜你喜欢

Scheduled tasks for distributed applications in Golang
oracle查询扫描全表和走索引

【LeetCode每日一题】——103.二叉树的锯齿形层序遍历

Reflex WMS Intermediate Series 7: What should I do if I want to cancel the picking of an HD that has finished picking but has not yet been loaded?

Analysis of volatile principle
使用DBeaver进行mysql数据备份与恢复
2022-07-30 mysql8执行慢SQL-Q17分析

Pinduoduo leverages the consumer expo to promote the upgrading of domestic agricultural products brands and keep pace with international high-quality agricultural products
【Unity入门计划】2D Game Kit:初步了解2D游戏组成

手写博客平台~第二天
随机推荐
Force buckle, 752-open turntable lock
Nanoprobes免疫测定丨FluoroNanogold试剂免疫染色方案
『网易实习』周记(三)
Software testing Interface automation testing Pytest framework encapsulates requests library Encapsulates unified request and multiple base path processing Interface association encapsulation Test cas
The principle and code implementation of intelligent follower robot in the actual combat of innovative projects
Fly propeller power space future PIE - Engine Engine build earth science
openGauss切换后state状态显示不对
leetcode / anagram in string - some permutation of s1 string is a substring of s2
bool框架::PosInGrid (const简历:关键点kp, int &posX, int诗句)
[ORB_SLAM2] void Frame::ComputeImageBounds(const cv::Mat & imLeft)
Project Background Technology Express
LeetCode刷题日记:53、最大子数组和
【LeetCode每日一题】——704.二分查找
永磁同步电机36问(二)——机械量与电物理量如何转化?
Ringtone 1161. Maximum In-Layer Elements and
永磁同步电机36问(三)——SVPWM代码实现
Install mysql using docker
The ultra-large-scale industrial practical semantic segmentation dataset PSSL and pre-training model are open source!
Multi-Party Threshold Private Set Intersection with Sublinear Communication-2021: Interpretation
Rasa 3 x learning series - Rasa - 4873 dispatcher Issues. Utter_message study notes