当前位置:网站首页>[model distillation] tinybert: distilling Bert for natural language understanding
[model distillation] tinybert: distilling Bert for natural language understanding
2022-07-02 07:22:00 【lwgkzl】
executive summary
TinyBert It mainly explores how to use model distillation to realize BERT Compression of models .
It mainly includes two innovations :
- Yes Transformer Parameters for distillation , Attention should be paid to embedding,attention_weight, After the complete connection layer hidden, And finally logits.
- For the pre training language model , It's divided into pretrain_model Distillation and task-specific Distillation . Study separately pretrain The initial parameters of the model in order to give a good initialization to the parameters of the compressed model , The second step is to learn pretrain model fine-tuning Of logits Let the compression model learn again .
Model
The model is mainly divided into three parts :
- Transformer Layer Distillation of
It mainly distills two parts , The first is on each floor attention weight, The second is the output of each layer hidden. As shown in the figure below .
The formula :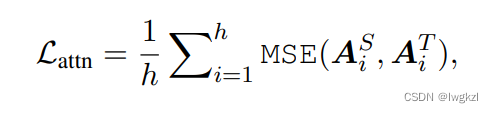

Using the mean square error as the loss function , And in hidden A comparison is introduced Wh, This is because the vector coding dimensions of the student model and the teacher model are inconsistent ( The vector dimension of the student model is smaller )
2. Embedding layer Distillation of 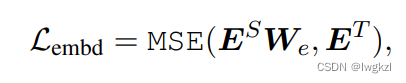
E Express embeddign Layer output .
3. Predict logits Distillation of 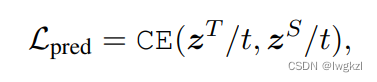
z Indicates that the teacher model and the student model are in task-specific Prediction probability on the task .
Another detail is data enhancement , The student model is task-specific On mission fine-tuning When ,Tinybert The original data set is enhanced .(ps: This is actually very strange , Because we can see in the experiment later , After removing the data enhancement , The effect of the model is better than that of the previous sota Not much improvement . The main selling point of this article is model distillation ummm)
Experiment and conclusion
The importance of distillation at all levels

It can be seen that , In terms of importance : Attn > Pred logits > Hidn > emb. among ,Attn,Hidn as well as emb It is useful in both stages of distillation .The importance of data enhancement
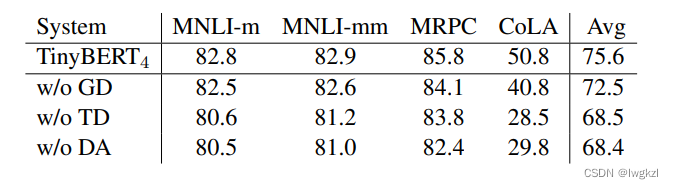
GD (General Distillation) Indicates the first stage distillation .
TD (Task-specific Distillation) Indicates the second stage distillation .
and DA (Data Augmentation). Indicates data enhancement .
The conclusion of this table is , Data enhancement is important : (.Which layers of the teacher model does the student model need to learn

Suppose the student model 4 layer , Teacher model 12 layer
top It means that the student model learns the teacher's post 4 layer (10,11,12),bottom Represents the front of the learning teacher model 4 layer (1,2,3,4),uniform It means even learning ( Equidistant ,3,6,9,12).
You can see , It is better to study each layer evenly .
Code
# This part of the code should be written in Trainer Inside , loss.backward Before .
# Get the student model logits, attention_weight as well as hidden
student_logits, student_atts, student_reps = student_model(input_ids, segment_ids, input_mask,
is_student=True)
# Get the teacher model in the test environment logits, attention_weight as well as hidden
with torch.no_grad():
teacher_logits, teacher_atts, teacher_reps = teacher_model(input_ids, segment_ids, input_mask)
# Divided into two steps , The next step is learning attentino_weight and hidden, Another step is to learn predict_logits. The general idea is to do the output of student model and teacher model loss, It's about attention_weight and hidden yes MSE loss, in the light of logits It's cross entropy .
if not args.pred_distill:
teacher_layer_num = len(teacher_atts)
student_layer_num = len(student_atts)
assert teacher_layer_num % student_layer_num == 0
layers_per_block = int(teacher_layer_num / student_layer_num)
new_teacher_atts = [teacher_atts[i * layers_per_block + layers_per_block - 1]
for i in range(student_layer_num)]
for student_att, teacher_att in zip(student_atts, new_teacher_atts):
student_att = torch.where(student_att <= -1e2, torch.zeros_like(student_att).to(device),
student_att)
teacher_att = torch.where(teacher_att <= -1e2, torch.zeros_like(teacher_att).to(device),
teacher_att)
tmp_loss = loss_mse(student_att, teacher_att)
att_loss += tmp_loss
new_teacher_reps = [teacher_reps[i * layers_per_block] for i in range(student_layer_num + 1)]
new_student_reps = student_reps
for student_rep, teacher_rep in zip(new_student_reps, new_teacher_reps):
tmp_loss = loss_mse(student_rep, teacher_rep)
rep_loss += tmp_loss
loss = rep_loss + att_loss
tr_att_loss += att_loss.item()
tr_rep_loss += rep_loss.item()
else:
if output_mode == "classification":
cls_loss = soft_cross_entropy(student_logits / args.temperature,
teacher_logits / args.temperature)
elif output_mode == "regression":
loss_mse = MSELoss()
cls_loss = loss_mse(student_logits.view(-1), label_ids.view(-1))
loss = cls_loss
tr_cls_loss += cls_loss.item()
边栏推荐
- 【Torch】解决tensor参数有梯度,weight不更新的若干思路
- CRP implementation methodology
- Error in running test pyspark in idea2020
- Three principles of architecture design
- Oracle EBs and apex integrated login and principle analysis
- 腾讯机试题
- 软件开发模式之敏捷开发(scrum)
- spark sql任务性能优化(基础)
- ssm人事管理系统
- Classloader and parental delegation mechanism
猜你喜欢
Only the background of famous universities and factories can programmers have a way out? Netizen: two, big factory background is OK

SSM student achievement information management system
![[Bert, gpt+kg research] collection of papers on the integration of Pretrain model with knowledge](/img/2e/e74d7a9efbf9fe617f4d7b46867c0a.png)
[Bert, gpt+kg research] collection of papers on the integration of Pretrain model with knowledge
Alpha Beta Pruning in Adversarial Search
離線數倉和bi開發的實踐和思考

How to efficiently develop a wechat applet
【论文介绍】R-Drop: Regularized Dropout for Neural Networks

User login function: simple but difficult
SSM学生成绩信息管理系统

The first quickapp demo
随机推荐
SSM garbage classification management system
华为机试题-20190417
腾讯机试题
JSP智能小区物业管理系统
使用 Compose 实现可见 ScrollBar
Sqli labs customs clearance summary-page1
如何高效开发一款微信小程序
view的绘制机制(一)
华为机试题
CAD secondary development object
【信息检索导论】第三章 容错式检索
图解Kubernetes中的etcd的访问
Module not found: Error: Can't resolve './$$_ gendir/app/app. module. ngfactory'
Network security -- intrusion detection of emergency response
ARP攻击
ORACLE EBS DATAGUARD 搭建
类加载器及双亲委派机制
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
ssm垃圾分类管理系统
使用MAME32K进行联机游戏