当前位置:网站首页>Yolov5 practice: teach object detection by hand
Yolov5 practice: teach object detection by hand
2022-07-02 07:01:00 【Huawei cloud developer community】
Abstract :YOLOv5 It's not a single model , It's a family of models , It includes YOLOv5s、YOLOv5m、YOLO...
This article is shared from Huawei cloud community 《YoloV5 actual combat : Teach object detection by hand ——YoloV5》, author : AI Ho .
Abstract
YOLOV5 Strictly speaking, it's not YOLO The fifth version of , Because it didn't get YOLO The father of Joe Redmon Recognition , But the overall performance of the test data is good . The details are as follows

YOLOv5 It's not a single model , It's a family of models , It includes YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x、YOLOv5x+TTA, It's a bit like this EfficientDet. Because I couldn't find it V5 The paper of , We can only learn it from the code . In general and YOLOV4 almost , Think of it as YOLOV5 The enhanced .
Project address :GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite
Training
1、 Download code
Project address :GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite, Recently, the author has updated some code .

2、 Configuration environment
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
pillow
PyYAML>=5.3
scipy>=1.4.1
tensorboard>=2.2
torch>=1.6.0
torchvision>=0.7.0
tqdm>=4.41.03、 Prepare the dataset
The dataset uses Labelme The data format of the annotation , Dataset from RSOD Two kinds of data sets, aircraft and oil tank, are obtained from the data set , And turn it into Labelme Annotated datasets .
The address of the dataset : https://pan.baidu.com/s/1iTUpvA9_cwx1qiH8zbRmDg
Extraction code :gr6g
perhaps :LabelmeData.zip_yolov5 actual combat - Deep learning document resources -CSDN download
Decompress the downloaded data set and put it in the root directory of the project . Prepare for the next step of generating test data sets . Here's the picture :

4、 Generate data set
YoloV5 The data set of is not the same as that of previous versions , Let's take a look at the converted dataset first .
The data structure is as follows :

images Folder storage train and val Pictures of the
labels Inside the store train and val Object data for , Each of them txt Document and images The pictures inside are one-to-one .
txt The contents of the document are as follows :

Format : Object category x y w h
Are coordinates real coordinates , It's calculated by dividing the coordinates by the width and height , It's the ratio of width to height .
Let's write the code to generate the data set , newly build LabelmeToYoloV5.py, Then write the following code .
import os
import numpy as np
import json
from glob import glob
import cv2
from sklearn.model_selection import train_test_split
from os import getcwd
classes = ["aircraft", "oiltank"]
# 1. Tag path
labelme_path = "LabelmeData/"
isUseTest = True # Whether to create test Set
# 3. Get the pending file
files = glob(labelme_path + "*.json")
files = [i.replace("\\", "/").split("/")[-1].split(".json")[0] for i in files]
print(files)
if isUseTest:
trainval_files, test_files = train_test_split(files, test_size=0.1, random_state=55)
else:
trainval_files = files
# split
train_files, val_files = train_test_split(trainval_files, test_size=0.1, random_state=55)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
wd = getcwd()
print(wd)
def ChangeToYolo5(files, txt_Name):
if not os.path.exists('tmp/'):
os.makedirs('tmp/')
list_file = open('tmp/%s.txt' % (txt_Name), 'w')
for json_file_ in files:
json_filename = labelme_path + json_file_ + ".json"
imagePath = labelme_path + json_file_ + ".jpg"
list_file.write('%s/%s\n' % (wd, imagePath))
out_file = open('%s/%s.txt' % (labelme_path, json_file_), 'w')
json_file = json.load(open(json_filename, "r", encoding="utf-8"))
height, width, channels = cv2.imread(labelme_path + json_file_ + ".jpg").shape
for multi in json_file["shapes"]:
points = np.array(multi["points"])
xmin = min(points[:, 0]) if min(points[:, 0]) > 0 else 0
xmax = max(points[:, 0]) if max(points[:, 0]) > 0 else 0
ymin = min(points[:, 1]) if min(points[:, 1]) > 0 else 0
ymax = max(points[:, 1]) if max(points[:, 1]) > 0 else 0
label = multi["label"]
if xmax <= xmin:
pass
elif ymax <= ymin:
pass
else:
cls_id = classes.index(label)
b = (float(xmin), float(xmax), float(ymin), float(ymax))
bb = convert((width, height), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
print(json_filename, xmin, ymin, xmax, ymax, cls_id)
ChangeToYolo5(train_files, "train")
ChangeToYolo5(val_files, "val")
ChangeToYolo5(test_files, "test")This code will be executed in LabelmeData Generate... For each image txt Annotation data , At the same time tmp Create the training set under the folder 、 Verification set and test set txt,txt It records the path of the image , Generate for next step YoloV5 Data sets for training and testing . stay tmp New under the folder MakeData.py file , Generate the final result , The directory structure is shown in the figure below :

open MakeData.py, Write the following code .
import shutil
import os
file_List = ["train", "val", "test"]
for file in file_List:
if not os.path.exists('../VOC/images/%s' % file):
os.makedirs('../VOC/images/%s' % file)
if not os.path.exists('../VOC/labels/%s' % file):
os.makedirs('../VOC/labels/%s' % file)
print(os.path.exists('../tmp/%s.txt' % file))
f = open('../tmp/%s.txt' % file, 'r')
lines = f.readlines()
for line in lines:
print(line)
line = "/".join(line.split('/')[-5:]).strip()
shutil.copy(line, "../VOC/images/%s" % file)
line = line.replace('JPEGImages', 'labels')
line = line.replace('jpg', 'txt')
shutil.copy(line, "../VOC/labels/%s/" % file)After execution, it can generate YoloV5 The data set used for training . give the result as follows :

5、 Modify configuration parameters
open voc.yaml file , Modify the configuration parameters inside
train: VOC/images/train/ # The path of the training set picture
val: VOC/images/val/ # Verify the path of the image set
# number of classes
nc: 2 # Category of detection , This dataset has two categories, so write 2
# class names
names: ["aircraft", "oiltank"]# The name of the category , And the transformation of data sets list Corresponding 6、 modify train.py Parameters of
cfg Parameter is YoloV5 The configuration file for the model , The model files are stored in models Under the folder , Fill in different documents as required .
weights Parameter is YoloV5 Pre training model of , and cfg Corresponding , example :cfg The configuration is yolov5s.yaml,weights We need to configure yolov5s.pt
data Is the configuration file for the configuration dataset , We chose voc.yaml, So configuration data/voc.yaml
Modify the above three parameters to start training , Other parameters are modified according to their own needs . The modified parameter configuration is as follows :
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/voc.yaml', help='data.yaml path')After the modification is completed , You can start training . As shown in the figure below :

7、 See the training results
After going through 300epoch After training , We will be in runs Find the training weight file and some files of the training process under the folder . Pictured :





test
The first thing you need to do is voc.yaml Add the path of test set in , open voc.yaml, stay val Add... After the field test: tmp/test.txt This line of code , Pictured :

modify test.py Parameters in , The following parameters need to be modified .
parser = argparse.ArgumentParser(prog='test.py')
parser.add_argument('--weights', nargs='+', type=str, default='runs/exp7/weights/best.pt', help='model.pt path(s)')
parser.add_argument('--data', type=str, default='data/voc.yaml', help='*.data path')
parser.add_argument('--batch-size', type=int, default=2, help='size of each image batch')
parser.add_argument('--save-txt', default='True', action='store_true', help='save results to *.txt')
stay 275 That's ok modify test Methods , Add a path to save test results . So that when the test is done, it can be done in inference\images See the picture of the test , stay inference\output You can see the saved test results in .
Pictured :

Here are the results of the run :

Click to follow , The first time to learn about Huawei's new cloud technology ~
边栏推荐
- Latex warning: citation "*****" on page y undefined on input line*
- Huawei mindspire open source internship machine test questions
- The table component specifies the concatenation parallel method
- sqli-labs通关汇总-page1
- How to debug wechat built-in browser applications (enterprise number, official account, subscription number)
- Redis -- cache breakdown, penetration, avalanche
- ts和js区别
- Go package name
- SQLI-LABS通关(less1)
- DNS攻击详解
猜你喜欢

Brief analysis of PHP session principle
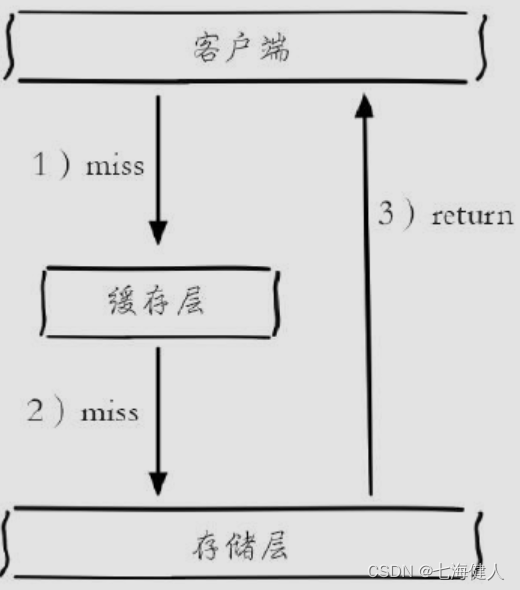
Redis -- cache breakdown, penetration, avalanche
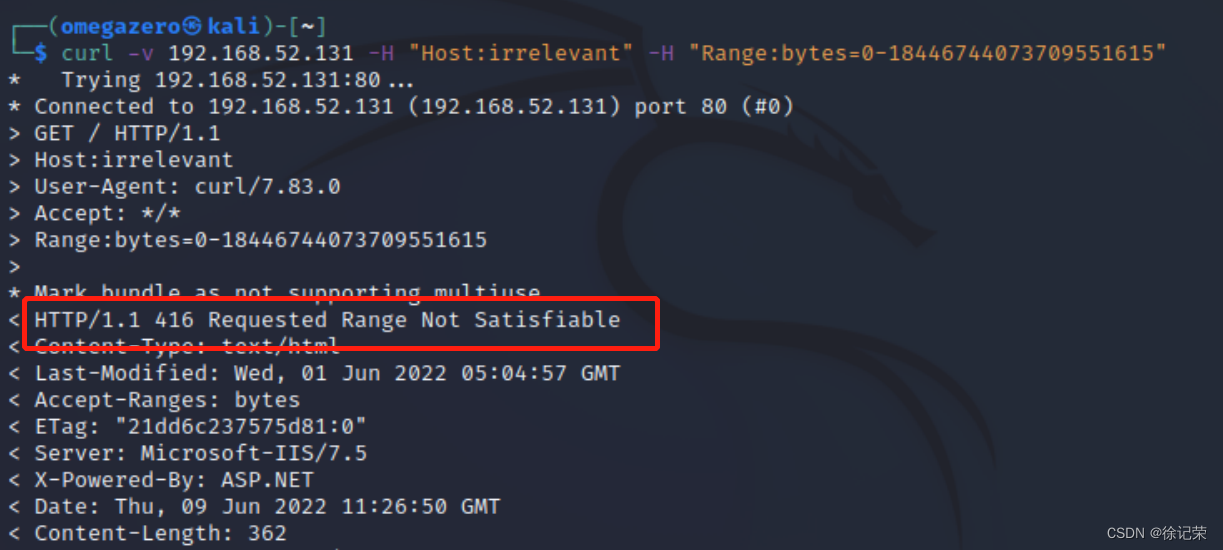
CVE-2015-1635(MS15-034 )遠程代碼執行漏洞複現

mapreduce概念和案例(尚硅谷学习笔记)

搭建frp进行内网穿透

微信小程序基础

SQLI-LABS通关(less18-less20)

Win10: add or delete boot items, and add user-defined boot files to boot items
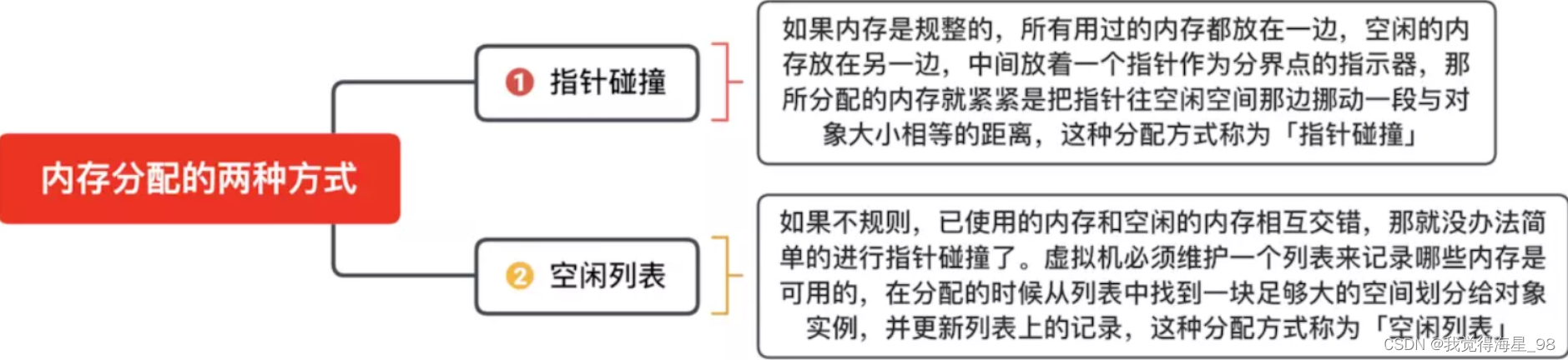
In depth study of JVM bottom layer (II): hotspot virtual machine object
Cve-2015-1635 (ms15-034) Remote Code Execution Vulnerability recurrence
随机推荐
Sqli-labs customs clearance (less18-less20)
js把一个数组分割成每三个一组
Win10: add or delete boot items, and add user-defined boot files to boot items
2021-07-17c /cad secondary development creation circle (5)
IDEA2020中测试PySpark的运行出错
SQLI-LABS通关(less1)
PIP install
How to debug wechat built-in browser applications (enterprise number, official account, subscription number)
js创建一个自定义json数组
Deployment API_ automation_ Problems encountered during test
php中的数字金额转换大写数字
Sentry搭建和使用
In depth study of JVM bottom layer (II): hotspot virtual machine object
JS divides an array into groups of three
TCP攻击
ARP攻击
Usage of map and foreach in JS
Eslint configuration code auto format
sqli-labs通关汇总-page3
js中map和forEach的用法