当前位置:网站首页>基于多特征的技术融合关系预测及其价值评估
基于多特征的技术融合关系预测及其价值评估
2022-07-26 13:54:00 【米朵儿技术屋】
摘要
【目的】 综合利用专利分类网络结构特征与文本语义特征,基于多种特征形成技术融合关系预测方法和价值评估方法。【方法】 区分专利与专利分类间的关联强度,构建专利分类共现网络,获取专利分类间的网络结构相似性特征,并根据关联强度赋予专利分类以专利文本,利用文本表示学习方法得到其文本语义相似性特征。根据网络结构特征和文本语义特征构建专利分类间多种相似性指标,融合多种指标构成特征向量,利用随机森林模型学习不同指标的权重和贡献,计算技术融合概率,排序得到候选技术融合关系集合。基于专利分类引用网络特征和文献计量特征,从影响力和成长潜力出发,提出领域技术价值、商业价值和战略价值评估指标,利用被引数加以验证,最后用所得方法评估技术融合关系,获取高价值技术融合关系。【结果】 本文方法的TopK预测准确率比单一特征至少提高20%;评测得到的前10对高价值技术融合关系与真实排名相差极小,平均绝对误差仅为3.2。【局限】 选取的数据库存在数据项不统一的问题;只尝试了单一的随机森林方法,未对其他前沿方法进行验证。【结论】 专利分类关联强度能够提高网络分析预测方法的预测效果,同时多特征融合方法相较于单一特征预测方法,能够提高技术融合关系预测效果;另一方面,本文的价值评估方法能够有效实现高价值技术融合关系价值的筛选。
关键词: 多特征; 技术融合关系; 预测; 价值评估
1 引言
创新是社会进步、国家发展的核心驱动力。对企业来说,创新是企业在行业竞争中保持优势或实现弯道超车的核心竞争力,是决定企业经济可行性的关键因素[1]。技术融合被认为是产业和技术之间创新的主要来源之一[2],它发生在现有技术的边界交汇处。提前发现高价值技术融合关系,有助于企业实现现有技术的创新突破,增强企业的行业竞争力,使企业更可能打破行业壁垒,在行业竞争中做到先人一步,发现蓝海赛道,实现各方面资源的高效配置。
当前对于技术融合的研究主要集中于对新生技术融合关系的预测。现有的研究方法分为定性和定量方法,定性分析方法主要是以德尔菲法为代表的专家分析方法,定量分析方法则有网络分析、语义分析、关联规则挖掘等。随着可用数据的持续增长,定量分析方法逐渐成为主流方法,但其中还存在一些问题,如网络分析方法中对网络结构信息的利用不全面,语义分析方法中对专利文本语义信息利用不准确以及缺乏针对技术融合关系的价值评估方法等,具体主要体现在以下方面:
(1)技术融合关系预测方法中主流的网络分析方法在衡量专利分类间相似性时忽略了专利分类间的关联强度,影响了技术融合的准确表示和表达。
(2)涉及文本语义方法时,平等地将专利文本赋予对应的所有专利分类,忽略了同一专利中多个专利分类间的重要性区别,并且现有方法未能充分融合网络结构与语义信息,使得技术融合关系预测结果不够全面。
(3)当前研究主要关注技术融合模式的识别与预测,但是预测所得技术融合关系并不一定都会产生价值,因而需要对预测结果进行价值评估,筛选获得高价值的技术融合关系。
因此,本文提出改进的专利分类相似性指标,考虑专利分类间的关联强度信息,并借助大数据环境下的机器学习方法,抽取专利数据的多项特征构成每对专利分类的向量表示,利用大量数据对随机森林模型进行训练,从而实现综合多种特征的技术融合关系预测方法;更进一步地,为实现对预测结果定量的价值评估,探索高价值的技术融合关系,本文从技术融合影响力和成长潜力角度提出技术融合关系价值评估指标和方法,在预测结果的基础上筛选出具有较高价值的技术融合关系。
2 国内外研究现状
2.1 技术融合关系预测
技术融合是指利用两种以上的现有技术来创造一种具有新功能的新技术[3],它被认为是技术创新的一种主要形式[4],不断推动技术更迭、进步和发展。通俗地认为,技术融合是两种现有技术的重叠、交叉[5]。技术可以用一个文档表示[6,7],也可以用一些数据的聚类表示[8,9,10,11],最常见的是用IPC表示技术[12,13,14,15,16]。
早期的技术融合研究方法以文献计量分析方法为主,Luan等[17]以太阳能技术领域为例,设计平均技术共类伙伴和平均技术共类指数对技术间关联关系演变做出分析。Jeong等[18]应用文献计量分析方法发现在技术生命周期的早期阶段、技术准备水平较低时更容易发生技术融合。Caviggioli[19]选用欧洲专利局(European Patent Office,EPO)的专利数据进行计量分析,发现当焦点技术领域联系密切时(即两种技术拥有较多的交叉引用),技术融合更为频发。
随着复杂网络理论的发展应用,研究人员开始将复杂网络理论方法应用于技术融合研究。如No等[20]利用专利引用网络绘制技术演化轨迹,根据专利的前向后向引用探究技术间的相互影响。Kim等[22]选择印刷电子技术领域的专利数据构建专利引用网络进行网络分析,发现中心度较高的核心技术对技术融合发展过程起到重要的促进作用。Park等[8]将专利引用网络和技术知识流动网络结合起来,预测不同技术之间的知识流动。Zhou等[23]在论文引用网络的基础上应用聚类方法展开知识融合过程以发现新兴技术。Kim等[21]在专利引用网络的基础上使用结构依存矩阵和神经网络方法识别关键融合技术。除了专利引用网络,研究人员还使用专利分类共现网络研究技术融合模式,如Jeong等[24]基于专利分类共现网络从技术领域的角度探索技术融合的产生,对韩国整体的技术发展阶段做出分析。Kim等[25]分别选择日韩两国柔性显示屏领域的专利数据构建专利分类共现网络并在此基础上进行聚类分析和浓度指数分析,发现两国分别专注于特定领域和从事分布式技术融合。Feng等[26]使用专利分类共现网络对电动汽车领域的技术融合加以探索,期望发现潜在的技术融合机会和有潜力的技术融合关系。
近年来,数据挖掘方法和自然语言处理的不断发展应用使得技术融合领域也出现了新的方法,如Cho等[27]、Lee等[28]基于关联规则挖掘方法构建技术网络,进而使用链路预测等方法预测技术融合模式;Preschitschek等[29]借助专利分类号表征技术,将专利分类号对应的所有专利文本合并后作为技术文本,通过计算技术文本间的相似性预测技术融合关系;Kong等[30]使用基于图神经网络模型的深度学习方法,将专利引用信息和文本语义信息结合起来,以识别技术融合轨迹并判断子技术在此过程中所发挥的作用;Eilers等[31]利用技术领域中包含的所有专利文本信息进行技术关键词提取,用以表征技术,并在此基础上计算不同技术的技术关键词相似性,识别可能的技术融合关系;Kim等[32]将文本语义分析和链路预测方法等多种研究方法结合起来构成输入向量训练机器学习模型,以期实现技术融合关系的预测。
基于专利引用网络和专利分类共现网络的技术融合预测方法在多个领域中取得了较好的效果,但是在衡量专利分类间相似性时忽略了专利分类间的关联强度,这影响了技术融合的准确表示和表达;另一方面,应用文本语义方法进行技术融合关系预测时,笼统地对专利分类号对应的所有专利文本都赋予专利分类,忽略了同一专利中多个专利分类间的重要性区别,并且现有方法未能充分融合网络结构与语义信息,使得技术融合关系预测结果不够全面。
2.2 技术融合关系价值评估
由于在技术融合预测领域还缺少对于融合关系的价值评估研究,本文借鉴针对专利的价值评估体系对融合关系价值进行评估。经济学领域一般使用成本法、预期收益法等实现专利价值评估,但这类方法易受外界因素干扰;情报学领域主要从技术价值定量分析角度实现专利价值评估,并逐步扩展到其他领域。
从技术价值角度展开的专利价值评估方法一般基于多种专利数据特征项定量计算设计多维度指标进行专利价值评估[33]。Lanjouw等[34]将专利被引频次、专利同族专利数和权利要求数作为评价指标,提出综合专利价值指数。李清海等[35]针对已有指标中的层次性、整体性问题进行梳理,得到被引频次、权利要求数、专利家族规模等7个指标。李春燕等[36]对现存的专利质量指标体系进行探索,筛选得到6类共29个专利质量指标。Lee等[37]认为被引频次是衡量技术价值的重要指标,一项专利的被引频次越高,代表其对所处技术领域产生的影响越大;Fischer等[38]则认为被引频次与专利的经济价值正相关。Blackman[39]经过统计发现专利权利要求在技术发展、战略规划中所起到的作用日渐明显;Grimaldi等[40]认为对专利权利要求进行分析可以得到专利创新点的技术重要性;Lanjouw等[34]认为专利诉讼和专利的权利要求数量相关,且被诉讼的专利往往具有更大的市场价值。
随着机器学习方法的快速发展,学者们尝试将其应用于专利价值评估中。赵蕴华等[41]将专利价值评估问题看作强度分类问题,对专利数据中可用于价值评估的指标进行分析和选取,数值化处理后输入到机器学习模型中进行专利强度分类实验。邱一卉等[42]利用CART模型判断不同指标对专利价值评估的影响程度,降低评估指标体系规模,提高评价效率。Ercan等[43]利用支持向量机模型构建了一种专利价值评估的智能分类模型,与贝叶斯分类算法进行比较发现支持向量机可以达到90%的准确率。Bessen[44]针对企业拥有的专利构建了一个专利价值回归模型,对企业专利价值做出量化分析。Chen等[45]使用BP神经网络算法对医药领域的专利数据进行价值评估。
综上,当前对专利价值的评估主要依靠建立专利价值评估体系,并研究不同指标权重的赋予方法,而对于专利技术中出现得越来越多的技术融合关系价值评估的研究还较少,需要结合当前的机器学习方法对关系价值进行评估,筛选高价值的技术融合关系为技术前沿分析提供基础和条件。
3 研究思路和方法
研究总体流程如图1所示。基于专利分类共现网络和文本信息设计网络结构相似性指标、语义相似性指标,融合构成每对专利分类的向量表示,进而作为随机森林模型的输入进行技术融合关系预测,获得技术融合关系候选集;从影响力和成长潜力出发,基于专利分类引用网络和专利文献计量特征构建领域技术价值、商业价值和战略价值评估指标,利用被引数训练得到多元回归模型;最后使用所得模型评估技术融合关系,筛选获取高价值技术融合关系。
图1
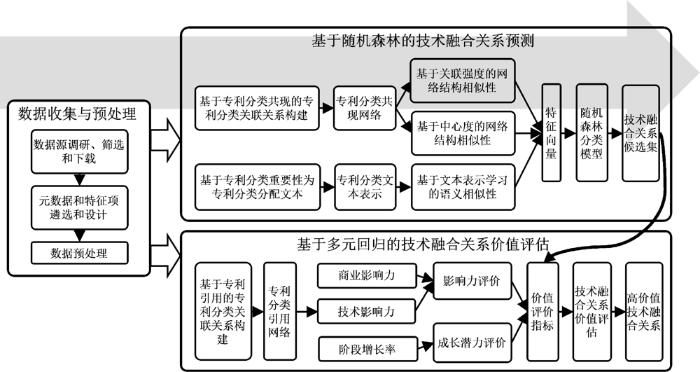
图1 总体流程
Fig.1 Overall Process
3.1 技术融合关系预测的特征构建
对技术融合关系进行预测时,以专利分类表示技术,以专利分类间的共现关系表示技术融合关系,因此技术融合关系预测的特征以专利分类间的关系来表示,主要包括专利分类之间的网络结构相似性和文本语义相似性,共同表示技术融合关系预测的输入特征。
(1)基于关联强度的网络结构相似性
专利分类的网络结构相似性描述了专利分类在共现网络中的相似程度,根据不同的定义可以用相应的指标进行度量。现有针对技术融合关系的网络分析方法在使用节点相似性作为专利分类间的网络结构相似性时,忽略了网络中节点间的连边权重。因此,本文提出基于节点间连边权重改进现有节点相似性指标。在应用至专利分类共现网络上时,使用专利分类共现频次作为节点间连边权重,对代表性的共同邻居指标和资源分配指标进行改进,改进后的指标分别如公式(1)和公式(2)所示。其中, Γ(m)Γ(m)表示与专利分类 mm共现的专利分类集合, Γ(n)Γ(n)同理, zz表示同时与专利分类 mm和 nn共现的专利分类, k(z)k(z)表示与专利分类 zz共现的专利分类总数, wz&mwz&m表示专利分类 zz与 mm间的共现频次, wz&nwz&n同理。
CNweightconsideredm&n=∑z∈Γ(m)⋂Γ(n)loge(|wz&m−wz&n|+e)CNm&nweightconsidered=∑z∈Γ(m)⋂Γ(n)loge(|wz&m-wz&n|+e)
(1)
RAweightconsideredm&n=∑z∈Γ(m)⋂Γ(n)loge(|wz&m−wz&n|k(z)+e)RAm&nweightconsidered=∑z∈Γ(m)⋂Γ(n)loge(|wz&m-wz&n|k(z)+e)
(2)
(2)基于中心度的网络结构相似性
除节点间相似性以外,中心度也是网络分析中的一个常用概念,不同的中心度可以衡量节点在网络中的活跃度或影响力。专利分类共现网络描述了技术间现有的融合关系,一个专利分类在其共现网络中的中心性越高,越能体现其在技术融合体系中的活跃程度和影响力。测度中心性的方法有三种,分别是度中心度、接近中心度和中介中心度。本文选择在专利分类共现网络上应用上述三种中心度概念,以获取可用的指标输入到预测模型中进行预测。
度中心度的定义最为简单,即与目标节点直接连接的节点总数;接近中心度计算的是一个节点到其他所有节点的距离总和,该总和越小则说明该节点到其他所有节点的路径越短,即距离其他点越近;中介中心度是指经过目标节点的最短路径的数量。
(3)基于文本表示学习的语义相似性
在计算专利分类的语义相似性之前,首先要确定每个专利分类对应的文本信息,然后利用表示学习方法获取专利分类文本的向量表示,在此基础上进行相似性计算。因此基于文本表示学习的语义相似性计算包含两部分:专利分类文本赋予和专利分类间的文本相似性计算。
专利分类文本赋予首先需要确定专利与专利分类的关联强度,然后设定阈值决定专利分类可获得的专利文本。为更细致地刻画专利分类语义信息,区分专利分类号在专利中的权重信息,本文提出专利分类与专利之间的关联强度计算方法,考虑不同专利分类在同一专利中出现的频次信息,对专利与专利分类的关联强度加以计算,如公式(3)所示。其中, WI&PWI&P为专利和专利分类间的关联强度, NxNx为专利 xx中出现IPC的总频次, NxANAx为专利 xx中专利分类 AA出现的频次。
WI&P=NxANxWI&P=NAxNx
(3)
在为专利分类赋予文本后,利用Doc2Vec方法获取专利分类的文本语义表示,将专利分类号类比于模型中的文本ID,专利文本中的每个词类比于“Word”序列。本文选择模型中包含的分布式记忆(Distributed Memory,DM)模型进行应用,因为DM模型更适合处理小型语料。训练时,模型将句子中的每个词以及专利文本对应的专利分类号作为输入一起训练。训练结束后,既可以得到每个词的词向量表征,又可以得到整个文本的向量表示,即每个专利分类的语义表示。
实现基于文本内容的专利分类语义表示后,给定两个专利分类,其向量可以分别表示为 xi=(x1,x2,x3,⋯,xn)xi=(x1,x2,x3,⋯,xn)和 yi=(y1,y2,y3,⋯,yn)yi=(y1,y2,y3,⋯,yn)。通过计算向量间的余弦相似性获得每一对专利分类之间的语义相似性,将其作为特征之一输入到预测模型中进行预测,具体计算方法如公式(4)所示。
cos(θ)=∑ni=1xi×yi∑ni=1(xi)2√×∑ni=1(yi)2√cosθ=∑i=1nxi×yi∑i=1n(xi)2×∑i=1n(yi)2
(4)
3.2 基于随机森林的技术融合关系预测
随机森林是一种经典的机器学习模型,在决策树的基础上改进得到。随机森林不仅克服了决策树主观性强的缺点,还能够清晰说明各项特征对预测过程的贡献度,从而可以在后续过程中实现输入特征的优化与改进。
将每一对专利分类表示为一个实例输入到随机森林模型中,实例的表达形式为(IPC1,IPC2)=(CN,RA,Text similarity,Betweenness centrality,Degree centrality,Closeness centrality,y),其中 yy表示该实例是否已经发生过技术融合,若发生过则 yy取值为1,否则取值为0。将实例集合输入随机森林模型中进行训练,能够实现多种特征的融合,充分利用多种信息实现技术融合关系的预测。
模型对输入的数据集合随机划分,通过信息增益逐一判定特征向量中每个特征对融合与否的影响程度,在每个划分后的数据集中,根据每个特征的信息增益大小排序生成不同的决策树,根据这些决策树确定最终预测结果。模型输出结果向量为 (IPC1,IPC2)=(r1,r2)(IPC1,IPC2)=(r1,r2),其中, r1r1代表该对专利分类发生融合的概率, r2r2代表预测结果是否发生融合。
3.3 技术融合关系价值的评价指标构建
在预测过程结束后,从影响力和成长潜力两方面对候选技术融合关系进行二维评价,以得到高价值和具备发展性的技术融合关系。
(1)商业影响力
从专利的权利要求数量计算专利的商业影响力,专利权利要求是专利申请中的一项重要内容,定义了其专利权保护范围,一项技术融合关系中所包含的权利要求数量可以体现出其商业价值。因此,选择专利权利要求数作为技术融合关系价值的评估指标,数量越多商业价值可能越高。专利分类 VV中对应专利的权利要求数量总和计算方法如公式(5)所示。其中, xx为专利分类 VV中涉及的专利, num(x)num(x)为专利 xx的权利要求数量。
num_of_claim=∑x∈Vnum(x)num_of_claim=∑x∈Vnum(x)
(5)
(2)技术影响力
专利分类引用网络中节点的PageRank得分和中介中心度反映一项技术在整体的技术流动关系网络所具有的影响力,因而可以用作一项技术融合关系的技术影响力评判。专利分类节点的PageRank得分计算有两种方式,一种是直接在专利分类引用网络上计算;另一种是在专利引用网络上计算专利的PageRank得分,而后根据专利与专利分类的对应关系将其累加得到专利分类节点的PageRank得分。在后续实验中,根据实验效果选择其中一种使用或者二者共同使用。PageRank得分计算方法如公式(6)所示。其中,集合 UU为目标节点 xx的邻居节点集合,节点 yy为集合 UU中任一节点, PR(y)PR(y)为节点 yy的PageRank得分。
PR(x)=∑y∈UPR(y)PRx=∑y∈UPRy
(6)
专利分类引用网络对技术之间的知识流动进行描述,专利分类在引用网络上的中介中心度反映了其与其他专利分类进行知识交换的密切程度,衡量了专利分类的技术影响力。中介中心度计算方法如公式(7)所示。其中, δδ代表点 yy和 zz间最短路径的数量, δ(x)δ(x)为经过点 xx的最短路径的数量, CB(x)CBx为点 xx的中介中心度。
CB(x)=∑x≠y≠zδ(x)δCBx=∑x≠y≠zδ(x)δ
(7)
(3)成长潜力
本文以一项技术融合关系目标阶段的融合次数增量与此前阶段的融合总数之比作为其成长潜力衡量指标。技术融合关系的价值形成是一个动态过程,成长潜力能够判断一项技术融合关系发展的稳定性,从而确定其未来发展前景。融合增长率计算方法如公式(8)所示。其中, growth(n)growth(n)为一项技术融合关系在第 nn年的融合增长率, NiNi为该技术融合关系在第 ii年的融合次数。
growth(n)=Nn−1−Nn−2∑n−2i=1Nigrowth(n)=Nn-1-Nn-2∑i=1n-2Ni
(8)
3.4 基于多元回归的技术融合关系价值评估
被引频次是衡量专利价值的公认指标,Lee等[37]认为专利的被引频次越高,其对所处技术领域产生的影响越大,因此本文利用被引频次的历史数据训练得到技术融合关系价值评估模型,利用该模型对技术融合关系进行价值评估。
具体地,将每一对技术融合关系价值的评价指标作为自变量,技术融合关系的平均被引频次作为因变量进行多元回归分析,得到拟合后的线性关系,用于后续的候选技术融合关系价值评估。
针对得到的技术融合关系价值评估指标,根据多元回归分析的常用评价方法均方根误差(Root Mean Square Error,RMSE)进行效果验证。 RMSERMSE能够测度真实值与评价值之间的差距,如公式(9)所示。其中, yryr是真实值, ypyp是评价值, mm是样本个数。 RMSERMSE是对真实值与评价值之差平方后求和再开方,即对线性回归的损失函数进行开方,它是多元线性回归中最为常用的测度拟合效果的评价指标。
RMSE=∑mi=1(yr−yp)2m−−−−−−−−−√RMSE=∑i=1m(yr-yp)2m
(9)
由于 RMSERMSE衡量的是价值评估方法整体的评价效果,而本文注重价值评估方法在高价值技术融合关系上的应用,因此在实际试验中,同样以高价值技术融合关系的真实价值排名和其评价值排名作比较,利用平均绝对误差(Mean Absolute Error,MAE)进行效果评估,其计算方法如公式(10)所示。其中, yryr是真实值, ypyp是预测值, mm是样本个数。
MAE=∑mi=1(yr−yp)mMAE=∑i=1m(yr-yp)m
(10)
4 实证分析
4.1 数据获取与预处理
从德温特数据库下载其收录的各个国家地区关于物联网领域的专利数据,检索式为“Internet of things”OR“IOT”,对应时间段为2015年-2018年。同时,对拥有多个专利号的同一专利进行去重处理,并自动标注每篇专利的唯一标识码,用于后续网络构建。处理后的专利数据项简介如表1所示,在2015年和2016年,物联网领域的专利数量虽有明显增长,但数据量仍较少,而在2017年和2018年,专利数量仍在增长但是涉及的IPC数量已经趋于稳定,因此在后续的实验过程中重点考虑使用2017年和2018年的数据。
表1 数据描述
Table 1 Description of Data
年份 | 专利数量 | 专利引用关系数量 | 涉及IPC数量 | IPC共现关系数量 |
2015 | 1 673 | 145 | 525 | 1 483 |
2016 | 3 012 | 473 | 768 | 3 517 |
2017 | 6 848 | 1 222 | 1 222 | 7 866 |
2018 | 10 603 | 1 605 | 1 644 | 11 060 |
4.2 技术融合关系预测的特征构建
技术融合关系预测的特征构建包括基于关联强度的网络结构相似性、基于中心度的网络结构相似性和基于文本表示学习的语义相似性三部分。由于基于关联强度的结构相似性特征是在节点相似性的基础上进行改进,因此首先要确定改进是否有效,然后在此基础上将三类特征融合构成技术融合关系预测的输入向量。
(1)节点相似性改进效果
以2016年的专利数据构建专利分类共现网络,进行节点相似性计算,对比改进前后节点相似性预测技术融合关系的准确率。当K取10、50、100、500时,分别查看改进前后TopK准确率,改进的共同邻居指标和资源分配指标较未改进指标的提高效果如表2所示,只有在K取值为10时,改进的资源分配指标不如改进前,二者相差0.1,而在K取值为50、100和500时,不论是改进的共同邻居指标还是改进的资源分配指标,其TopK准确率都要高于未改进的共同邻居指标和资源分配指标。因此,在后续的多特征融合方法中,使用改进后的节点相似性作为网络结构特征。
表2 节点相似性指标改进效果
Table 2 Improvement Effect of Node Similarity Index
预测方法 | Top10 | Top50 | Top100 | Top500 |
共同邻居指标 | 0.8 | 0.70 | 0.68 | 0.52 |
改进共同邻居指标 | 0.9 | 0.72 | 0.71 | 0.54 |
资源分配指标 | 0.9 | 0.66 | 0.60 | 0.51 |
改进资源分配指标 | 0.8 | 0.68 | 0.68 | 0.53 |
(2)技术融合关系预测的输入向量
在确定节点相似性改进指标的有效性之后,将语义相似性与两类网络结构相似性一同构成向量,输入随机森林模型中进行多特征融合的技术融合关系预测。技术融合关系预测的输入向量如表3所示,将每一行实例视为一个向量。以“['G05B-015', 'G08B-021']”为例,G05B-015和G08B-021表示一对潜在技术融合关系中的两者,对二者相应的专利文本进行表示学习后计算得到二者语义相似性为0.66,在专利分类共现网络中求其基于关联强度的结构相似性,计算得到改进后的共同邻居和资源分配指标分别为7.25和12.75,对二者的中心度进行计算并求均值得到其度中心度为0.11、中介中心度为1.65、接近中心度为0.04。
表3 技术融合关系预测的输入向量
Table 3 Input Vector of Technology Convergence Relationship Prediction
潜在技术融合关系 | 语义相似性 | 基于中心度的结构相似性 | 基于关联强度的结构相似性 | |||
度中心度 | 中介中心度 | 接近中心度 | 改进的共同邻居指标 | 改进的资源分配指标 | ||
['G05B-015', 'G08B-021'] | 0.66 | 0.11 | 1.65 | 0.04 | 7.25 | 12.75 |
['G05B-019', 'H02J-013'] | 0.65 | 0.15 | 1.69 | 0.10 | 2.22 | 7.03 |
['G07C-001', 'G07F-007'] | 0.66 | 0.02 | 1.39 | 0 | 1.02 | 1.55 |
['G08G-001', 'H04N-007'] | 0.66 | 0.08 | 1.61 | 0.04 | 5.17 | 9.32 |
['G01D-021', 'G06Q-050'] | 0.66 | 0.11 | 1.70 | 0.03 | 8.74 | 19.46 |
['G06Q-020', 'G06Q-030'] | 0.66 | 0.06 | 1.54 | 0.02 | 3.23 | 4.84 |
… | … | … | … | … | … | … |
4.3 基于随机森林的技术融合关系预测
在技术融合关系预测实验中,使用2016年的数据对随机森林模型进行训练,得到训练好的模型后,使用2017年的数据进行预测,并使用2018年的真实数据对预测结果进行验证。
以基于单一特征的预测方法作为基线方法,对提出的融合多特征的随机森林方法进行预测效果的验证比较,结果如图2所示。可以看出基于专利分类网络的节点相似性方法在K取值较小时效果较好,而基于专利分类文本的语义相似性方法此时效果则相对较差;随着K取值的增大,语义相似性方法准确率逐渐超越节点相似性方法;而本文选用的多特征融合方法不论K取值多少,其效果都是最优的,较基线方法至少提高20%。在K取10、50时,多特征融合方法的TopK准确率均能达到100%,此时节点相似性方法可以达到70%以上,而语义相似性方法则表现最差,不足10%;当K取100、500时,多特征融合方法的TopK准确率也能够达到90%以上,而语义相似性方法和节点相似性方法则处于47%~70%。因此,融合网络结构特征和文本语义特征形成的特征向量可以更加有效地利用多种信息,实现技术融合关系预测准确率的提高。
图2

图2 不同预测方法预测效果比较
Fig.2 Prediction Effects of Different Methods
各项方法的AUC评分得分如表4所示,多特征融合方法的AUC值为0.93,较文本语义相似性方法提高了0.10,较网络结构相似性方法提高了0.27,显然在AUC得分方面也是多特征融合方法表现最佳。综上,可以认为本文所提多特征融合方法预测效果优于基于单一特征的预测方法。
表4 不同预测方法AUC比较
Table 4 Comparison of AUC of Different Methods
指标 | 文本语义 | 改进的CN | 改进的RA | 多特征融合 |
AUC | 0.83 | 0.66 | 0.66 | 0.93 |
对随机森林方法的各项输入特征进行贡献度分析,得到结果如图3所示。其中,专利分类间的文本语义相似性贡献度最高,达到34%,说明专利的文本语义信息对预测技术融合关系有着不可或缺的作用;基于专利分类共现网络节点活跃度的各项特征贡献度次之,最高占比20%,说明在共现网络中越活跃的专利分类越容易与其他专利分类产生共现从而实现技术融合;而基于网络结构相似性的各项特征则表现最差,约为8%,结合图2其较好的表现,说明网络结构相似性在多种特征共同作用时,对整体预测结果的贡献逐渐减弱。
图3

图3 多特征融合方法中各特征贡献度
Fig.3 Contribution of Each Feature in Multi Feature Convergence Method
4.4 基于多元回归的技术融合关系价值评估
(1)技术融合关系价值评估方程获取
将2017年的数据输入多元回归模型中训练获得线性模型,得到被引频次与评价指标的关系,如表5所示。
表5 回归方程的变量与系数
Table 5 Variables and Coefficients of Regression Equation
变量 | 影响力评价 | 成长潜力评价 | 截距 | |||
商业影响力 | 技术影响力 | 融合增长率 | —— | |||
专利权利要求数量 | 引用网络中介中心度 | 引用网络PageRank | 聚合的PageRank | |||
系数 | -9.3e+01 | -7.6e-02 | 1.8e+03 | 7.3e+02 | 2.2e-01 | 2.43 |
所得回归方程的MAE为11.73,RMSE为18.17。在使用2017年的数据进行多元线性回归后,将训练所得回归方程应用于2018年的共11 060对技术融合关系中。在2018年技术融合关系的真实价值(被引数)波动范围为0~621、平均价值为51.31的情况下,价值评估的总体结果如表6所示。
表6 回归方程的各项评价得分
Table 6 Evaluation scores of regression equation
评价指标 | 得分 |
MAE | 11.73 |
RMSE | 18.17 |
(2)技术融合关系价值评估结果
针对技术融合关系的评估排名与真实排名前10对比结果如表7所示。可以看出所得模型在应用到2018年真实数据中时有着较为优良的效果,预测的影响力排名与真实的影响力排名非常接近,10项对比中只有一项的排名误差达到11,其余均控制在7以内,前10对融合关系的平均排名误差为3.20。此外,前50对融合关系的平均排名误差为9.36,前100对融合关系的平均排名误差为27.26,所以在对高价值的技术融合关系进行评价时,训练所得的评价方法有着较为良好的表现。
表7 影响力评价方法的实验结果
Table 7 Results of Impact Evaluation Methods
比较项 | 被引频次排名比较 | |||||||||
评估结果 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
真实结果 | 2 | 1 | 3 | 5 | 12 | 17 | 8 | 4 | 6 | 7 |
排名误差 | 1 | 1 | 0 | 1 | 7 | 11 | 1 | 4 | 3 | 3 |
将得到的价值评估公式应用于预测所得的技术融合关系,对其进行价值评估。2018年的真实技术融合关系共11 060项,以其中价值排名前5%,即前553项技术融合关系作为高价值技术关系。其中2018年新出现的技术融合关系共96对,其价值评估结果如图4所示。
图4

图4 高价值技术融合关系筛选
Fig.4 High Value Technology Convergence Relationship Screening
以技术融合关系对的总被引数作为价值衡量标准,对数据中所有的技术融合关系进行价值衡量,笔者认为价值排名中前100的技术融合关系是高价值技术融合关系,在图4预测所得结果中,共找到7对高价值技术融合关系,如表8所示。
表8 高价值技术融合关系
Table 8 High Value Technology Convergence Relationships
技术融合关系 | 预测价值排名 | 真实价值排名 | 排名误差 |
['F21V-023', 'H04L-029'] | 77 | 120 | 43 |
['H01Q-009', 'H04L-029'] | 83 | 122 | 39 |
['F21W-131', 'H04L-029'] | 86 | 183 | 97 |
['F21S-009', 'H04L-029'] | 91 | 184 | 93 |
['H01L-025', 'H04L-029'] | 93 | 105 | 12 |
['F21V-021', 'H04L-029'] | 97 | 186 | 89 |
['G16H-010', 'H04L-029'] | 98 | 258 | 160 |
表8以“['F21V-02,'H04L-029']”为例,其预测价值排名为77,而其真实价值则为120,两者相差43名。总体来看,价值评估的排名误差最低为12,最高为160,平均误差为76.1,在技术融合关系共11 060对的情况下,本文所提价值评估方法在应用到真实数据上时,其结果也是相对准确的。
5 结语
本文介绍了一种基于多特征的技术融合关系预测及其价值评估方法,具体包括专利数据的采集以及预处理、候选技术融合关系的预测和高价值技术融合关系筛选三个部分。从实验结果来看,本文所提技术融合关系预测方法准确率明显高于对比实验;而针对技术融合关系的评估方法,其RMSE也控制在20以内,MAE仅为11.73。实验结果证实,融合网络结构特征和文本语义特征的技术融合关系预测方法可以更有效地利用多种特征信息,对技术融合关系预测产生积极影响;从技术融合影响力角度提出的技术融合关系价值评估方法,可以在预测结果的基础上筛选出具有较高价值的技术融合关系。
本文从语义表示和融合视角提出了技术融合关系预测及其价值评估方法,但由于是初步研究,还存在一些不足需要后续完善和补充,主要包括:
(1)德温特专利数据库虽然数据丰富,但是存在部分数据项不统一的缺陷,可以尝试使用数据项规整统一的专利数据源进行实验。
(2)无论是预测阶段还是价值评估阶段,选取的特征都有待进一步扩展丰富,如在价值评估阶段中引入专利覆盖地区等特征。
(3)在方法设计上,只尝试了单一的随机森林方法,未来可以选择其他机器学习方法对特征进行融合实现预测,比较不同方法的效果。
边栏推荐
- 2022年,我们只用一个月就“送走”了这么多互联网产品
- How to remove black edges from hyperimage images (two methods)
- 421. Maximum XOR value of two numbers in the array
- JSON data returned by controller
- 「中高级试题」:MVCC实现原理是什么?
- Docker integrates the redis sentinel mode (one master, two slave and three sentinels)
- WPS凭什么拒绝广告?
- The difference between V-model and.Sync modifier
- Code cloud, which officially supports the pages function, can deploy static pages
- @千行百业,一起乘云而上!
猜你喜欢

2022年,我们只用一个月就“送走”了这么多互联网产品

Official announcement! Edweisen group and Baidu xirang reached a deep co creation cooperation
The shell script in Jenkins fails to execute but does not exit by itself
Pytorch学习笔记(三)模型的使用、修改、训练(CPU/GPU)及验证

Multi objective optimization series 1 --- explanation of non dominated sorting function of NSGA2

重押海外:阿里、京东、顺丰再拼“内力”
![[oauth2] v. oauth2loginauthenticationfilter](/img/54/3c3f02511e30c301a5cea6f6ddd4c2.png)
[oauth2] v. oauth2loginauthenticationfilter

The last time I heard about eBay, or the last time

Force deduction ----- the number of words in the string

Videojs to canvas pause, play, switch video
随机推荐
Multithreaded completable future usage
从标注好的xml文件中截取坐标点(人脸框四个点坐标)人脸图像并保存在指定文件夹
@千行百业,一起乘云而上!
【数学建模】常用基本模型总结
Rotation of 2D conversion, transform origin of 2D conversion center point and scale of 2D conversion
421. 数组中两个数的最大异或值
Using the geoprocessor tool
2022-07-26 Daily: the first anniversary of the establishment of alphafold DB database, research on the lighting point of official promotion
Subscription and publication of messages
二叉树的层序遍历(C语言实现)
Book download | introduction to lifelong supervised learning in 2022, CO authored by meta AI, CMU and other scholars, 171 Pages pdf
力扣------字符串中的单词数
Mobile dual finger scaling event (native), e.originalevent.touches
Inspiration from brain: introduction to synaptic integration principle in deep neural network optimization
Completable future practical usage
JS timer realizes the countdown and jumps to the login page
[dark horse morning post] many apps under bytek have been taken off the shelves; The leakage of deoxidizer in three squirrels caused pregnant women to eat by mistake; CBA claimed 406million yuan from
Pytoch learning notes (II) the use of neural networks
技术分享 | 需要小心配置的 gtid_mode
Add a display horizontal line between idea methods