当前位置:网站首页>机器学习编译第2讲:张量程序抽象
机器学习编译第2讲:张量程序抽象
2022-07-05 16:13:00 【自动驾驶小学生】
02 张量程序抽象 【MLC-机器学习编译中文版】
课程主页:https://mlc.ai/summer22-zh/
文章目录
在本章中,我们将讨论对单个单元计算步骤的抽象以及在机器学习编译中对这些抽象的可能的变换。
2.1 元张量函数
在上一章的概述中,我们介绍到机器学习编译的过程可以被看作张量函数之间的变换。一个典型的机器学习模型的执行包含许多步将输入张量之间转化为最终预测的计算步骤,其中的每一步都被称为元张量函数 (primitive tensor function)。
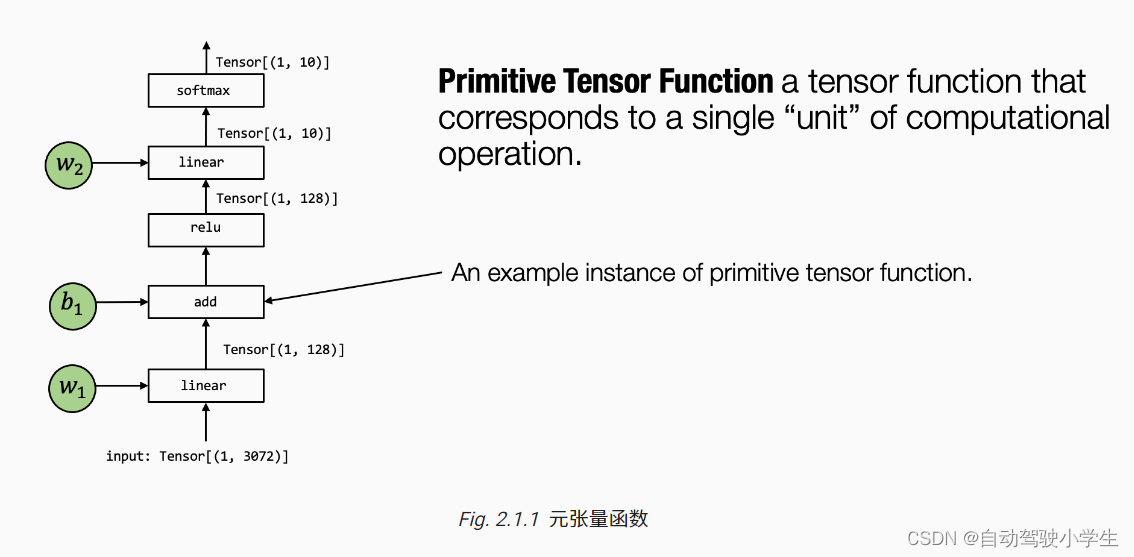
在上面这张图中,张量算子 linear, add, relu 和 softmax 均为元张量函数。特别的是,许多不同的抽象能够表示(和实现)同样的元张量函数(正如下图所示)。我们可以选择调用已经预先编译的框架库(如 torch.add 和 numpy.add)并利用在 Python 中的实现。在实践中,元张量函数被例如 C 或 C++ 的低级语言所实现,并且在一些时候会包含一些汇编代码。

许多机器学习框架都提供机器学习模型的编译过程,以将元张量函数变换为更加专门的、针对特定工作和部署环境的函数。
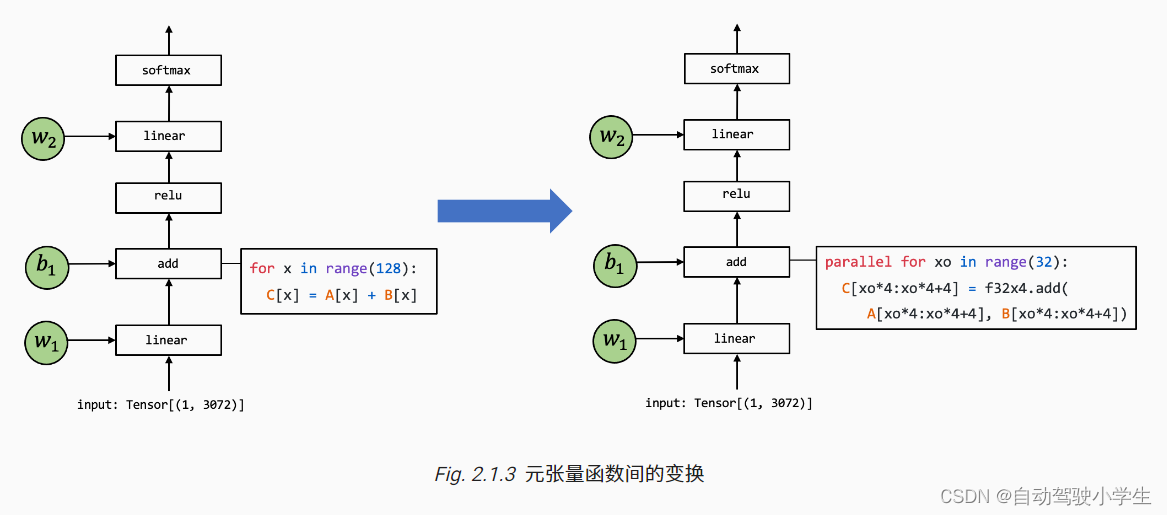
上面这张图展示了一个元张量函数 add 的实现被变换至另一个不同实现的例子,其中在右侧的代码是一段表示可能的组合优化的伪代码:左侧代码中的循环被拆分出长度为 4 的单元,f32x4.add 对应的是一个特殊的执行向量加法计算的函数。
2.2 张量程序抽象
上一节谈到了对元张量函数变换的需要。为了让我们能够更有效地变换元张量函数,我们需要一个有效的抽象来表示这些函数。
通常来说,一个典型的元张量函数实现的抽象包含了一下成分:存储数据的多维数组,驱动张量计算的循环嵌套以及计算部分本身的语句。

我们称这类抽象为 张量程序抽象。张量程序抽象的一个重要性质是,他们能够被一系列有效的程序变换所改变。
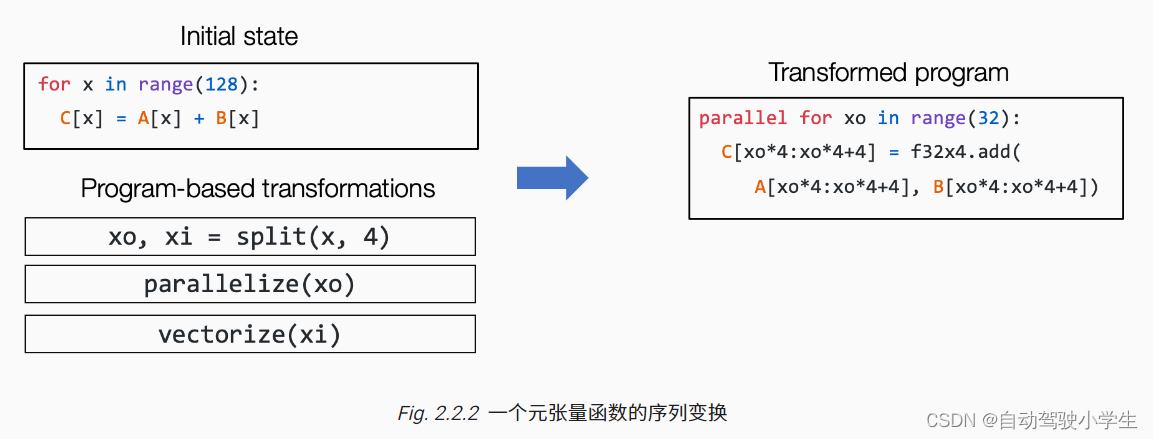
例如,我们能够通过一组变换操作(如循环拆分、并行和向量化)将上图左侧的一个初始循环程序变换为右侧的程序。
2.2.1 张量程序抽象中的其它结构
重要的是,我们不能任意地对程序进行变换,比方说这可能是因为一些计算会依赖于循环之间的顺序。但幸运的是,我们所感兴趣的大多数元张量函数都具有良好的属性(例如循环迭代之间的独立性)。
张量程序可以将这些额外的信息合并为程序的一部分,以使程序变换更加便利。

举个例子,上面图中的程序包含额外的 T.axis.spatial 标注,表明 vi 这个特定的变量被映射到循环变量 i,并且所有的迭代都是独立的。这个信息对于执行这个程序而言并非必要,但会使得我们在变换这个程序时更加方便。在这个例子中,我们知道我们可以安全地并行或者重新排序所有与 vi 有关的循环,只要实际执行中 vi 的值按照从 0 到 128 的顺序变化。
2.3 张量程序变换实践
2.3.1 安装相关的包
为了本课程的目标,我们会使用 TVM (一个开源的机器学习编译框架)中一些正在持续开发的部分。我们提供了下面的命令用于为 MLC 课程安装一个包装好的版本。
python3 -m pip install mlc-ai-nightly -f https://mlc.ai/wheels
2.3.2 构造张量程序
让我们首先构造一个执行两向量加法的张量程序。
import numpy as np
import tvm
from tvm.ir.module import IRModule
from tvm.script import tir as T
@tvm.script.ir_module
class MyModule:
@T.prim_func
def main(A: T.Buffer[128, "float32"],
B: T.Buffer[128, "float32"],
C: T.Buffer[128, "float32"]):
# extra annotations for the function
T.func_attr({
"global_symbol": "main", "tir.noalias": True})
for i in range(128):
with T.block("C"):
# declare a data parallel iterator on spatial domain
vi = T.axis.spatial(128, i)
C[vi] = A[vi] + B[vi]
TVMScript 是一种让我们能以 Python 抽象语法树的形式来表示张量程序的方式。注意到这段代码并不实际对应一个 Python 程序,而是对应一个机器学习编译过程中的张量程序。TVMScript 的语言设计是为了与 Python 语法所对应,并在 Python 语法的基础上增加了能够帮助程序分析与变换的额外结构。
type(MyModule)
tvm.ir.module.IRModule
MyModule 是 IRModule 数据结构的一个实例,是一组张量函数的集合。
我们可以通过 script 函数得到这个 IRModule 的 TVMScript 表示。这个函数对于在一步步程序变换间检查 IRModule 而言非常有帮助。
print(MyModule.script())
@tvm.script.ir_module
class Module:
@tir.prim_func
def func(A: tir.Buffer[128, "float32"], B: tir.Buffer[128, "float32"], C: tir.Buffer[128, "float32"]) -> None:
# function attr dict
tir.func_attr({
"global_symbol": "main", "tir.noalias": True})
# body
# with tir.block("root")
for i in tir.serial(128):
with tir.block("C"):
vi = tir.axis.spatial(128, i)
tir.reads(A[vi], B[vi])
tir.writes(C[vi])
C[vi] = A[vi] + B[vi]
2.3.3 编译与运行
在任何时刻,我们都可以通过 build 将一个 IRModule 转化为可以执行的函数。
rt_mod = tvm.build(MyModule, target="llvm") # The module for CPU backends.
type(rt_mod)
tvm.driver.build_module.OperatorModule
在编译后,mod 包含了一组可以执行的函数。我们可以通过这些函数的名字拿到对应的函数。
func = rt_mod["main"]
func
<tvm.runtime.packed_func.PackedFunc at 0x7fd5ad30aa90>
a = tvm.nd.array(np.arange(128, dtype="float32"))
b = tvm.nd.array(np.ones(128, dtype="float32"))
c = tvm.nd.empty((128,), dtype="float32")
要执行这个函数,我们在 TVM runtime 中创建三个 NDArray,然后执行调用这个函数。
func(a, b, c)
print(a)
[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13.
14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27.
28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41.
42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55.
56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69.
70. 71. 72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83.
84. 85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95. 96. 97.
98. 99. 100. 101. 102. 103. 104. 105. 106. 107. 108. 109. 110. 111.
112. 113. 114. 115. 116. 117. 118. 119. 120. 121. 122. 123. 124. 125.
126. 127.]
print(b)
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1.]
print(c)
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14.
15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28.
29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42.
43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56.
57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70.
71. 72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84.
85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95. 96. 97. 98.
99. 100. 101. 102. 103. 104. 105. 106. 107. 108. 109. 110. 111. 112.
113. 114. 115. 116. 117. 118. 119. 120. 121. 122. 123. 124. 125. 126.
127. 128.]
2.3.4 张量程序变换
现在我们开始变换张量程序。一个张量程序可以通过一个辅助的名为调度(schedule)的数据结构得到变换。
sch = tvm.tir.Schedule(MyModule)
type(sch)
tvm.tir.schedule.schedule.Schedule
我们首先尝试拆分循环。
# Get block by its name
block_c = sch.get_block("C")
# Get loops surrounding the block
(i,) = sch.get_loops(block_c)
# Tile the loop nesting.
i_0, i_1, i_2 = sch.split(i, factors=[None, 4, 4])
print(sch.mod.script())
@tvm.script.ir_module
class Module:
@tir.prim_func
def func(A: tir.Buffer[128, "float32"], B: tir.Buffer[128, "float32"], C: tir.Buffer[128, "float32"]) -> None:
# function attr dict
tir.func_attr({
"global_symbol": "main", "tir.noalias": True})
# body
# with tir.block("root")
for i_0, i_1, i_2 in tir.grid(8, 4, 4):
with tir.block("C"):
vi = tir.axis.spatial(128, i_0 * 16 + i_1 * 4 + i_2)
tir.reads(A[vi], B[vi])
tir.writes(C[vi])
C[vi] = A[vi] + B[vi]
我们可以对这些循环重新排序。现在我们将 i_2 移动到 i_1 的外侧。
sch.reorder(i_0, i_2, i_1)
print(sch.mod.script())
@tvm.script.ir_module
class Module:
@tir.prim_func
def func(A: tir.Buffer[128, "float32"], B: tir.Buffer[128, "float32"], C: tir.Buffer[128, "float32"]) -> None:
# function attr dict
tir.func_attr({
"global_symbol": "main", "tir.noalias": True})
# body
# with tir.block("root")
for i_0, i_2, i_1 in tir.grid(8, 4, 4):
with tir.block("C"):
vi = tir.axis.spatial(128, i_0 * 16 + i_1 * 4 + i_2)
tir.reads(A[vi], B[vi])
tir.writes(C[vi])
C[vi] = A[vi] + B[vi]
最后,我们可以标注我们想要并行最外层的循环。
sch.parallel(i_0)
print(sch.mod.script())
@tvm.script.ir_module
class Module:
@tir.prim_func
def func(A: tir.Buffer[128, "float32"], B: tir.Buffer[128, "float32"], C: tir.Buffer[128, "float32"]) -> None:
# function attr dict
tir.func_attr({
"global_symbol": "main", "tir.noalias": True})
# body
# with tir.block("root")
for i_0 in tir.parallel(8):
for i_2, i_1 in tir.grid(4, 4):
with tir.block("C"):
vi = tir.axis.spatial(128, i_0 * 16 + i_1 * 4 + i_2)
tir.reads(A[vi], B[vi])
tir.writes(C[vi])
C[vi] = A[vi] + B[vi]
我们能够编译并运行变换后的程序。
transformed_mod = tvm.build(sch.mod, target="llvm") # The module for CPU backends.
transformed_mod["main"](a, b, c)
print(c)
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14.
15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28.
29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42.
43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56.
57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70.
71. 72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84.
85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95. 96. 97. 98.
99. 100. 101. 102. 103. 104. 105. 106. 107. 108. 109. 110. 111. 112.
113. 114. 115. 116. 117. 118. 119. 120. 121. 122. 123. 124. 125. 126.
127. 128.]
2.3.5 通过张量表达式(Tensor Expression,TE)构造张量程序
在之前的例子中,我们直接使用 TVMScript 构造张量程序。在实际中,通过现有的定义方便地构造这些函数是很有帮助的。张量表达式(tensor expression)是一个帮助我们将一些可以通过表达式表示的张量计算转化为张量程序的 API。
# namespace for tensor expression utility
from tvm import te
# declare the computation using the expression API
A = te.placeholder((128, ), name="A")
B = te.placeholder((128, ), name="B")
C = te.compute((128,), lambda i: A[i] + B[i], name="C")
# create a function with the specified list of arguments.
func = te.create_prim_func([A, B, C])
# mark that the function name is main
func = func.with_attr("global_symbol", "main")
ir_mod_from_te = IRModule({
"main": func})
print(ir_mod_from_te.script())
@tvm.script.ir_module
class Module:
@tir.prim_func
def func(A: tir.Buffer[128, "float32"], B: tir.Buffer[128, "float32"], C: tir.Buffer[128, "float32"]) -> None:
# function attr dict
tir.func_attr({
"global_symbol": "main", "tir.noalias": True})
# body
# with tir.block("root")
for i0 in tir.serial(128):
with tir.block("C"):
i = tir.axis.spatial(128, i0)
tir.reads(A[i], B[i])
tir.writes(C[i])
C[i] = A[i] + B[i]
2.3.6 变换一个矩阵乘法程序
在上面的例子中,我们展示了如何变换一个向量加法程序。现在我们尝试应用一些变换到一个稍微更复杂的的程序——矩阵乘法程序。我们首先使用张量表达式 API 构造初始的张量程序,并编译执行它。
from tvm import te
M = 1024
K = 1024
N = 1024
# The default tensor type in tvm
dtype = "float32"
target = "llvm"
dev = tvm.device(target, 0)
# Algorithm
k = te.reduce_axis((0, K), "k")
A = te.placeholder((M, K), name="A")
B = te.placeholder((K, N), name="B")
C = te.compute((M, N), lambda m, n: te.sum(A[m, k] * B[k, n], axis=k), name="C")
# Default schedule
func = te.create_prim_func([A, B, C])
func = func.with_attr("global_symbol", "main")
ir_module = IRModule({
"main": func})
print(ir_module.script())
func = tvm.build(ir_module, target="llvm") # The module for CPU backends.
a = tvm.nd.array(np.random.rand(M, K).astype(dtype), dev)
b = tvm.nd.array(np.random.rand(K, N).astype(dtype), dev)
c = tvm.nd.array(np.zeros((M, N), dtype=dtype), dev)
func(a, b, c)
evaluator = func.time_evaluator(func.entry_name, dev, number=1)
print("Baseline: %f" % evaluator(a, b, c).mean)
@tvm.script.ir_module
class Module:
@tir.prim_func
def func(A: tir.Buffer[(1024, 1024), "float32"], B: tir.Buffer[(1024, 1024), "float32"], C: tir.Buffer[(1024, 1024), "float32"]) -> None:
# function attr dict
tir.func_attr({
"global_symbol": "main", "tir.noalias": True})
# body
# with tir.block("root")
for i0, i1, i2 in tir.grid(1024, 1024, 1024):
with tir.block("C"):
m, n, k = tir.axis.remap("SSR", [i0, i1, i2])
tir.reads(A[m, k], B[k, n])
tir.writes(C[m, n])
with tir.init():
C[m, n] = tir.float32(0)
C[m, n] = C[m, n] + A[m, k] * B[k, n]
Baseline: 2.967772
我们可以变换张量程序中的循环,使得在新循环下内存访问的模式对缓存更加友好。我们尝试下面的调度。
sch = tvm.tir.Schedule(ir_module)
type(sch)
block_c = sch.get_block("C")
# Get loops surrounding the block
(y, x, k) = sch.get_loops(block_c)
block_size = 32
yo, yi = sch.split(y, [None, block_size])
xo, xi = sch.split(x, [None, block_size])
sch.reorder(yo, xo, k, yi, xi)
print(sch.mod.script())
func = tvm.build(sch.mod, target="llvm") # The module for CPU backends.
c = tvm.nd.array(np.zeros((M, N), dtype=dtype), dev)
func(a, b, c)
evaluator = func.time_evaluator(func.entry_name, dev, number=1)
print("after transformation: %f" % evaluator(a, b, c).mean)
@tvm.script.ir_module
class Module:
@tir.prim_func
def func(A: tir.Buffer[(1024, 1024), "float32"], B: tir.Buffer[(1024, 1024), "float32"], C: tir.Buffer[(1024, 1024), "float32"]) -> None:
# function attr dict
tir.func_attr({
"global_symbol": "main", "tir.noalias": True})
# body
# with tir.block("root")
for i0_0, i1_0, i2, i0_1, i1_1 in tir.grid(32, 32, 1024, 32, 32):
with tir.block("C"):
m = tir.axis.spatial(1024, i0_0 * 32 + i0_1)
n = tir.axis.spatial(1024, i1_0 * 32 + i1_1)
k = tir.axis.reduce(1024, i2)
tir.reads(A[m, k], B[k, n])
tir.writes(C[m, n])
with tir.init():
C[m, n] = tir.float32(0)
C[m, n] = C[m, n] + A[m, k] * B[k, n]
after transformation: 0.296419
尝试改变 batch_size 的值,看看你能得到怎样的性能。在实际情况中,我们会利用一个自动化的系统在一个可能的变换空间中搜索找到最优的程序变换。
2.4 总结
元张量函数表示机器学习模型计算中的单个单元计算。一个机器学习编译过程可以有选择地转换元张量函数的实现。
张量程序是一个表示元张量函数的有效抽象。关键成分包括:
多维数组,循环嵌套,计算语句。程序变换可以被用于加速张量程序的执行。张量程序中额外的结构能够为程序变换提供更多的信息。
边栏推荐
- How to use FRP intranet penetration +teamviewer to quickly connect to the intranet host at home when mobile office
- Solve cmakelist find_ Package cannot find Qt5, ECM cannot be found
- Today's sleep quality record 79 points
- Quelques réflexions cognitives
- Accès aux données - intégration du cadre d'entité
- [vulnerability warning] cve-2022-26134 conflict Remote Code Execution Vulnerability POC verification and repair process
- 养不起真猫,就用代码吸猫 -Unity 粒子实现画猫咪
- 2020-2022两周年创作纪念日
- Enterprise backup software Veritas NetBackup (NBU) 8.1.1 installation and deployment of server
- Single merchant v4.4 has the same original intention and strength!
猜你喜欢
Hiengine: comparable to the local cloud native memory database engine
How to uninstall MySQL cleanly
"21 days proficient in typescript-3" - install and build a typescript development environment md
Summary of PHP pseudo protocol of cisp-pte
Jarvis OJ 简单网管协议

Data Lake (XIV): spark and iceberg integrated query operation

Data access - entityframework integration
Seaborn draws 11 histograms
Flet教程之 09 NavigationRail 基础入门(教程含源码)
《21天精通TypeScript-3》-安装搭建TypeScript开发环境.md
随机推荐
新春限定丨“牛年忘烦”礼包等你来领~
【 brosser le titre 】 chemise culturelle de l'usine d'oies
Mongodb getting started Tutorial Part 04 mongodb client
树莓派4b安装Pytorch1.11
Deep dive kotlin synergy (XXI): flow life cycle function
Raspberry pie 4B installation pytorch1.11
Solve the Hanoi Tower problem [modified version]
Research and development efficiency measurement index composition and efficiency measurement methodology
Hiengine: comparable to the local cloud native memory database engine
Google Earth engine (GEE) -- a brief introduction to kernel kernel functions and gray level co-occurrence matrix
Summary of PHP pseudo protocol of cisp-pte
Combined use of vant popup+ other components and pit avoidance Guide
英特尔第13代Raptor Lake处理器信息曝光:更多核心 更大缓存
Enter a command with the keyboard
公司自用的国产API管理神器
Flet教程之 12 Stack 重叠组建图文混合 基础入门(教程含源码)
Global Data Center released DC brain system, enabling intelligent operation and management through science and technology
面对新的挑战,成为更好的自己--进击的技术er
Do sqlserver have any requirements for database performance when doing CDC
挖财股票开户安全吗?怎么开股票账户是安全?