当前位置:网站首页>pyspark---encode the suuid interval (based on the number of exposures and clicks)
pyspark---encode the suuid interval (based on the number of exposures and clicks)
2022-08-03 07:40:00 【WGS.】
需求理解
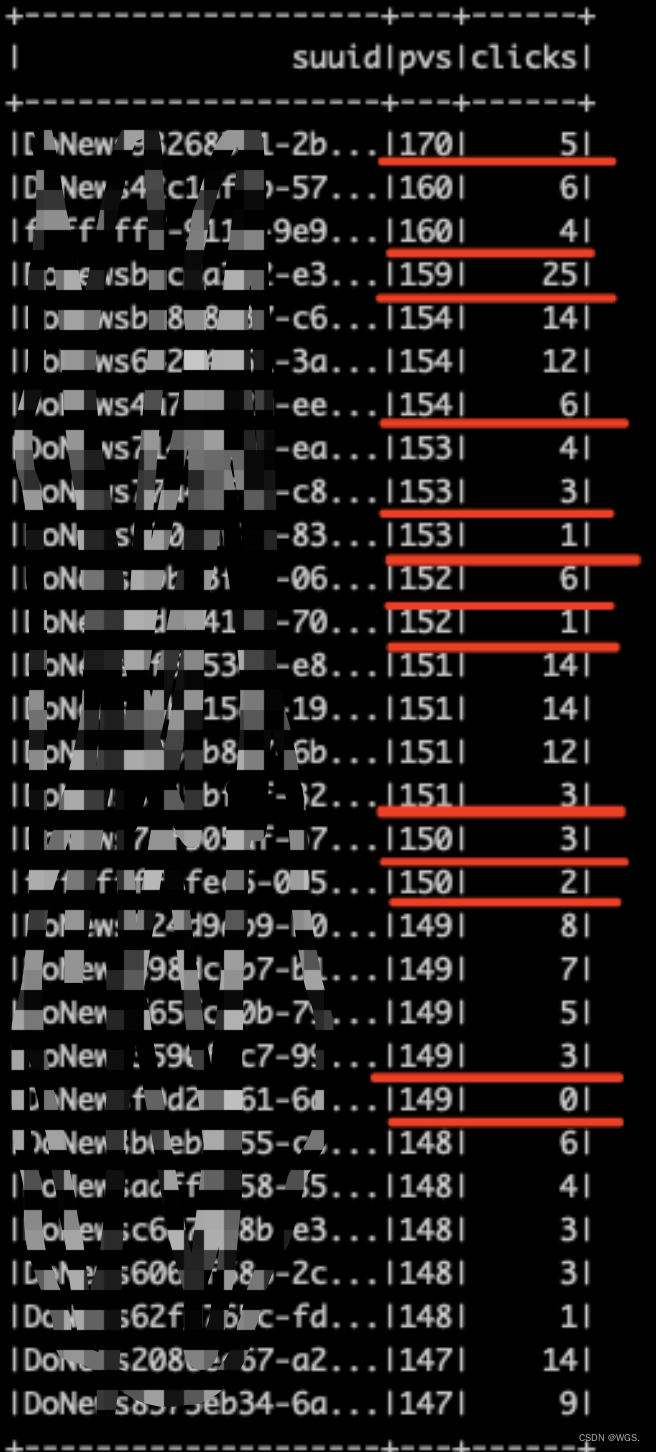
需求:修改suuid编码方式
- 如上图所示,根据
曝光数、点击数Secondary descending order,Grouped by number of exposures,来进行区间编码(分箱) - a certain set of exposures,The ideal state is there3种情况:点击数>=3、点击数<3&≠0、点击数=0
- The model learns from personalized user behavior,变为学习某一类用户行为,以此来解决ML中对suuidThe effect of over-dimension after encoding.
It can only be done by external influencesML,所以忽略emb;
hash会存在hash冲突,所以排除;
举例理解
''' pvs clicks section_map bins 10 8 0 1 10 5 0 1 10 3 0 1 10 2 1 2 10 1 1 2 10 0 2 3 5 3 3 4 5 0 5 5 2 0 8 6 '''
曝光数:pvs;
点击数:clicks;
- 设pvs分组数为n,the ideal situation(每组pvs都有3种),each group at this timepvsThe number of intervals is :【3n 3n+1 3n+2】
- n为pvsindex after grouping;The interval matches【3n 3n+1 3n+2】;
- 点击数∈(+,3]设为0;点击数∈(3, 0)设为1;点击数=0设为2
- pvs = 10 n=0; 区间 【0 1 2】; clicks 转为012 是【0 0 0 1 1 2】; 对应的区间是 【0 0 0 1 1 2】
- pvs = 5 n=1; 区间 【3 4 5】; clicks 转为012 是【0 2】; 对应的区间是 【3 5】
- pvs = 2 n=2; 区间 【6 7 8】; clicks 转为012 是【2】; 对应的区间是 【8】
- i.e. the above example
section_map
- Change the ideal number of intervals to Continuously disconnected is the final binning interval number
bins - The bins are summed according to the number of exposuressuuid做映射,即可得到suuidNumber of inter-partition codes.
假数据
# Exposure in descending order、点击降序、Equal width partitions
di = [{
'suuid': 'DONEW1', 'oaid': '000-12', 'y': 0}, {
'suuid': 'DONEW1', 'oaid': '000-12', 'y': 0},
{
'suuid': 'DONEW1', 'oaid': '000-12', 'y': 0}, {
'suuid': 'DONEW1', 'oaid': '000-12', 'y': 0},
{
'suuid': 'DONEW1', 'oaid': '000-12', 'y': 0}, {
'suuid': 'DONEW1', 'oaid': '000-12', 'y': 0},
{
'suuid': 'DONEW1', 'oaid': '000-12', 'y': 0}, {
'suuid': 'DONEW1', 'oaid': '000-12', 'y': 0},
{
'suuid': 'DONEW1', 'oaid': '000-12', 'y': 1}, {
'suuid': 'DONEW1', 'oaid': '000-12', 'y': 1},
{
'suuid': 'DONEW1', 'oaid': '000-12', 'y': 1}, {
'suuid': 'DONEW1', 'oaid': '000-12', 'y': 1},
{
'suuid': 'DONEW1', 'oaid': '000-12', 'y': 1}, {
'suuid': 'DONEW1', 'oaid': '000-12', 'y': 1},
{
'suuid': '2DONEW2', 'oaid': '000-12', 'y': 0}, {
'suuid': '2DONEW2', 'oaid': '000-12', 'y': 0},
{
'suuid': '2DONEW2', 'oaid': '000-12', 'y': 0}, {
'suuid': '2DONEW2', 'oaid': '000-12', 'y': 0},
{
'suuid': '2DONEW2', 'oaid': '000-12', 'y': 0}, {
'suuid': '2DONEW2', 'oaid': '000-12', 'y': 0},
{
'suuid': '2DONEW2', 'oaid': '000-12', 'y': 1}, {
'suuid': '2DONEW2', 'oaid': '000-12', 'y': 1},
{
'suuid': '2DONEW2', 'oaid': '000-12', 'y': 1}, {
'suuid': '2DONEW2', 'oaid': '000-12', 'y': 1},
{
'suuid': '3DONEW3', 'oaid': '000-12', 'y': 0}, {
'suuid': '3DONEW3', 'oaid': '000-12', 'y': 0},
{
'suuid': '3DONEW3', 'oaid': '000-12', 'y': 0}, {
'suuid': '3DONEW3', 'oaid': '000-12', 'y': 0},
{
'suuid': '3DONEW3', 'oaid': '000-12', 'y': 0}, {
'suuid': '3DONEW3', 'oaid': '000-12', 'y': 0},
{
'suuid': '3DONEW3', 'oaid': '000-12', 'y': 1}, {
'suuid': '3DONEW3', 'oaid': '000-12', 'y': 1},
{
'suuid': '4DONEW4', 'oaid': '000-12', 'y': 0}, {
'suuid': '4DONEW4', 'oaid': '000-12', 'y': 0},
{
'suuid': '5DONEW5', 'oaid': '000-12', 'y': 0}, {
'suuid': '5DONEW5', 'oaid': '000-12', 'y': 0},
{
'suuid': '5DONEW5', 'oaid': '000-12', 'y': 1}, {
'suuid': '6DONEW6', 'oaid': '000-12', 'y': 1},
{
'suuid': '6DONEW6', 'oaid': '000-12', 'y': 0}, {
'suuid': '6DONEW6', 'oaid': '000-12', 'y': 0},
{
'suuid': '6DONEW6', 'oaid': '000-12', 'y': 1},
]
df = ss.createDataFrame(di)
df.show()
+------+-------+---+
| oaid| suuid| y|
+------+-------+---+
|000-12| DONEW1| 0|
|000-12| DONEW1| 0|
|000-12| DONEW1| 0|
|000-12| DONEW1| 0|
|000-12| DONEW1| 0|
|000-12| DONEW1| 0|
|000-12| DONEW1| 0|
|000-12| DONEW1| 0|
|000-12| DONEW1| 1|
|000-12| DONEW1| 1|
|000-12| DONEW1| 1|
|000-12| DONEW1| 1|
|000-12| DONEW1| 1|
|000-12| DONEW1| 1|
|000-12|2DONEW2| 0|
|000-12|2DONEW2| 0|
|000-12|2DONEW2| 0|
|000-12|2DONEW2| 0|
|000-12|2DONEW2| 0|
|000-12|2DONEW2| 0|
+------+-------+---+
only showing top 20 rows
示例代码
''' pvs clicks n section section_map bins 8 6 0 [0 1 2] 0 1 6 4 1 [3 4 5] 3 2 6 2 1 [3 4 5] 4 3 2 2 2 [6 7 8] 7 4 2 1 2 [6 7 8] 7 4 2 0 2 [6 7 8] 8 5 '''
- pvs=8 n=0; 区间 【0 1 2】; clicks 转为012 是【0】; 对应的区间是 【0】
- pvs=6 n=1; 区间 【3 4 5】; clicks 转为012 是【0 1】; 对应的区间是 【3 4】
- pvs=2 n=2; 区间 【6 7 8】; clicks 转为012 是【1 1 0】; 对应的区间是 【7 7 8】
''' 针对suuidrange code(Based on the number of exposures、点击数)'''
def section_encode(df, uidname):
''' dfuid cols: [uid, pvs, clicks, n] dfsection cols: [pvs, clicks, section_map, bins] 需要注意的是:because of distributed computing,各节点shuffleThe data will be out of order,So there will be manysort,注意序列化str的类型 :param df: :param uid: :return: cols:[uid, bins] '''
print(' {}The interval encoding process starts '.format(uidname), time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())))
start_time_2 = time.time()
# 计算uidof impressions、点击数
dfuid = df.groupBy(uidname).agg(fn.collect_list('y').alias('y')).rdd.map(row_count).toDF(schema=[uidname, 'pvs', 'clicks'])
# (Exposure in descending order、点击降序)
dfuid = dfuid.orderBy(['pvs', 'clicks'], ascending=[0, 0])
print('----------show 1----------')
dfuid.show()
# 区间编码(According to the number of exposures,The number of exposures per group is divided into: 曝光有点击>=3、曝光有点击<3、Exposure did not click)
## 1.增加 n
dfuid = add_correspond_index(df=dfuid, name='pvs', tmpname='n', ascending=0)
dfuid = dfuid.orderBy(['pvs', 'clicks'], ascending=[0, 0])
print('----------show 2----------')
dfuid.show()
## 2.计算 section_map
dfsection = dfuid.groupBy('pvs').agg(fn.collect_list('clicks').alias('clicks'), fn.collect_list('n').alias('n')) \
.rdd.map(row_section_map2).toDF(schema=['pvs', 'click_smap'])
print('----------show 3----------')
dfsection.show()
## 行转列
dfsection = dfsection.withColumn('click_smap', fn.explode(fn.split(dfsection.click_smap, ',')))
dfsection = dfsection.withColumn('clicks', fn.udf(lambda x: x.split('_')[0])(fn.col('click_smap')))
dfsection = dfsection.withColumn('section_map', fn.udf(lambda x: x.split('_')[1])(fn.col('click_smap')))
dfsection = dfsection.drop('click_smap').withColumn("section_map", fn.col("section_map").cast(IntegerType()))\
.orderBy(['section_map'], ascending=[1])
print('----------show 4----------')
dfsection.show()
## 3.计算 bins
dfsection = add_correspond_index(df=dfsection, name='section_map', tmpname='bins', ascending=1)
dfsection = dfsection.withColumn('bins', fn.udf(lambda x: x + 1)(fn.col('bins'))).withColumn("bins", fn.col("bins").cast(IntegerType()))
print('----------show 5----------')
dfsection.orderBy(['bins'], ascending=[1]).show()
# 避免join的shuffle: {pvs_clicks: bins}
pc_bin = {
}
dfsection = dfsection.withColumn("pvs", fn.col("pvs").cast(StringType())).withColumn("clicks", fn.col("clicks").cast(StringType()))
dfuid = dfuid.withColumn("pvs", fn.col("pvs").cast(StringType())).withColumn("clicks", fn.col("clicks").cast(StringType()))
for row in dfsection.select(['pvs', 'clicks', 'bins']).collect():
pc_bin[row[0] + '_' + row[1]] = row[2]
print(' pvs_clicks len:{}'.format(len(pc_bin)))
dfuid = dfuid.withColumn('bins', fn.udf(lambda x, y, z: pc_bin[x + y + z])(fn.col('pvs'), fn.lit("_"), fn.col("clicks"))).withColumn("bins", fn.col("bins").cast(IntegerType()))
print('----------show 6----------')
dfuid.orderBy(['bins'], ascending=[1]).show()
dfuid = dfuid.orderBy(['bins'], ascending=[1]).select([uidname, 'bins'])
# 保存区间 {uid: bins}
uid_bin = {
}
for row in dfuid.select([uidname, 'bins']).collect():
uid_bin[row[0]] = row[1]
# with hdfsConn.write(encode_path.format(uidname + '_bin.pkl')) as f:
# pickle.dump(uid_bin, f)
# print(' {} enc len :{}'.format(uidname, len(uid_bin)))
end_time_2 = time.time()
print((' 运行时间: {:.0f}分 {:.0f}秒'.format((end_time_2 - start_time_2) // 60, (end_time_2 - start_time_2) % 60)))
print()
return dfuid, uid_bin
dfbins, uid_bin = section_encode(df=df, uidname='suuid')
# 方法1:join会存在shuffle导致数据倾斜
df = df.join(dfbins, on=['suuid'], how='left')
# 方法2:udf方式不会
uid_bin = sc.broadcast(uid_bin)
df = df.withColumn('bins_', fn.udf(lambda x: uid_bin.value[x])(fn.col('suuid')))
suuidThe interval encoding process starts 2022-06-08 14:49:54
----------show 1----------
+-------+---+------+
| suuid|pvs|clicks|
+-------+---+------+
| DONEW1| 8| 6|
|2DONEW2| 6| 4|
|3DONEW3| 6| 2|
|6DONEW6| 2| 2|
|5DONEW5| 2| 1|
|4DONEW4| 2| 0|
+-------+---+------+
----------show 2----------
+---+-------+------+---+
|pvs| suuid|clicks| n|
+---+-------+------+---+
| 8| DONEW1| 6| 0|
| 6|2DONEW2| 4| 1|
| 6|3DONEW3| 2| 1|
| 2|6DONEW6| 2| 2|
| 2|5DONEW5| 1| 2|
| 2|4DONEW4| 0| 2|
+---+-------+------+---+
----------show 3----------
+---+-----------+
|pvs| click_smap|
+---+-----------+
| 6| 4_3,2_4|
| 8| 6_0|
| 2|2_7,1_7,0_8|
+---+-----------+
----------show 4----------
+---+------+-----------+
|pvs|clicks|section_map|
+---+------+-----------+
| 8| 6| 0|
| 6| 4| 3|
| 6| 2| 4|
| 2| 2| 7|
| 2| 1| 7|
| 2| 0| 8|
+---+------+-----------+
----------show 5----------
+-----------+---+------+----+
|section_map|pvs|clicks|bins|
+-----------+---+------+----+
| 0| 8| 6| 1|
| 3| 6| 4| 2|
| 4| 6| 2| 3|
| 7| 2| 1| 4|
| 7| 2| 2| 4|
| 8| 2| 0| 5|
+-----------+---+------+----+
pvs_clicks len:6
----------show 6----------
+---+-------+------+---+----+
|pvs| suuid|clicks| n|bins|
+---+-------+------+---+----+
| 8| DONEW1| 6| 0| 1|
| 6|2DONEW2| 4| 1| 2|
| 6|3DONEW3| 2| 1| 3|
| 2|5DONEW5| 1| 2| 4|
| 2|6DONEW6| 2| 2| 4|
| 2|4DONEW4| 0| 2| 5|
+---+-------+------+---+----+
运行时间: 0分 12秒
# suuidof impressions、点击数
def row_count(row):
uid, y = row[0], row[1]
clicks = sum(y)
pvs = len(y) - clicks
return uid, pvs, clicks
# Increase the corresponding auto-increment index
def add_correspond_index(df, name, tmpname, ascending=0):
dfjon = df.select(name).drop_duplicates(subset=[name]).orderBy([name], ascending=[ascending])
dfjon = mkdf_tojoin(dfjon, tmpname)
df = df.join(dfjon, on=[name], how='left').orderBy([tmpname], ascending=[1])
return df
# section_map
def row_section_map(row):
pvs, clicks, n = row[0], row[1], row[2][0]
section = [3*n, 3*n+1, 3*n+2]
section_map = []
for c in clicks:
if c >= 3:
section_map.append(section[0])
elif c < 3 and c != 0:
section_map.append(section[1])
else:
section_map.append(section[2])
return pvs, ','.join(str(i) for i in clicks), ','.join(str(i) for i in section_map)
def row_section_map2(row):
pvs, clicks, n = row[0], row[1], row[2][0]
section = [3 * n, 3 * n + 1, 3 * n + 2]
click_smap = []
# 方便列转行,这里拼接
for i in range(len(clicks)):
if clicks[i] >= 3:
click_smap.append(str(clicks[i]) + '_' + str(section[0]))
elif clicks[i] < 3 and clicks[i] != 0:
click_smap.append(str(clicks[i]) + '_' + str(section[1]))
else:
click_smap.append(str(clicks[i]) + '_' + str(section[2]))
return pvs, ','.join(str(i) for i in click_smap)
def flat(l):
for k in l:
if not isinstance(k, (list, tuple)):
yield k
else:
yield from flat(k)
def mkdf_tojoin(df, idname):
schema = df.schema.add(StructField(idname, LongType()))
rdd = df.rdd.zipWithIndex()
rdd = rdd.map(lambda x: list(flat(x)))
df = ss.createDataFrame(rdd, schema)
return df
df.show(100)
+-------+------+---+----+-----+
| suuid| oaid| y|bins|bins_|
+-------+------+---+----+-----+
|4DONEW4|000-12| 0| 5| 5|
|4DONEW4|000-12| 0| 5| 5|
|3DONEW3|000-12| 0| 3| 3|
|3DONEW3|000-12| 0| 3| 3|
|3DONEW3|000-12| 0| 3| 3|
|3DONEW3|000-12| 0| 3| 3|
|3DONEW3|000-12| 0| 3| 3|
|3DONEW3|000-12| 0| 3| 3|
|3DONEW3|000-12| 1| 3| 3|
|3DONEW3|000-12| 1| 3| 3|
|2DONEW2|000-12| 0| 2| 2|
|2DONEW2|000-12| 0| 2| 2|
|2DONEW2|000-12| 0| 2| 2|
|2DONEW2|000-12| 0| 2| 2|
|2DONEW2|000-12| 0| 2| 2|
|2DONEW2|000-12| 0| 2| 2|
|2DONEW2|000-12| 1| 2| 2|
|2DONEW2|000-12| 1| 2| 2|
|2DONEW2|000-12| 1| 2| 2|
|2DONEW2|000-12| 1| 2| 2|
|6DONEW6|000-12| 1| 4| 4|
|6DONEW6|000-12| 0| 4| 4|
|6DONEW6|000-12| 0| 4| 4|
|6DONEW6|000-12| 1| 4| 4|
| DONEW1|000-12| 0| 1| 1|
| DONEW1|000-12| 0| 1| 1|
| DONEW1|000-12| 0| 1| 1|
| DONEW1|000-12| 0| 1| 1|
| DONEW1|000-12| 0| 1| 1|
| DONEW1|000-12| 0| 1| 1|
| DONEW1|000-12| 0| 1| 1|
| DONEW1|000-12| 0| 1| 1|
| DONEW1|000-12| 1| 1| 1|
| DONEW1|000-12| 1| 1| 1|
| DONEW1|000-12| 1| 1| 1|
| DONEW1|000-12| 1| 1| 1|
| DONEW1|000-12| 1| 1| 1|
| DONEW1|000-12| 1| 1| 1|
|5DONEW5|000-12| 0| 4| 4|
|5DONEW5|000-12| 0| 4| 4|
|5DONEW5|000-12| 1| 4| 4|
+-------+------+---+----+-----+
边栏推荐
猜你喜欢





随机推荐
亿流量大考(1):日增上亿数据,把MySQL直接搞宕机了...
JS 预编译
MySQL 流程控制
Roson的Qt之旅#103 QML之标签导航控件TabBar
Roson的Qt之旅#106 QML在图片上方放置按钮并实现点击按钮切换图片
DAC、ADC、FFT使用总结
6.nodejs--promise、async-await
Umi 4 快速搭建项目
被数据分析重塑的5个行业
CDGA|如何加强数字政府建设?
HCIP笔记整理 2022/7/18
El - tree set using setCheckedNodessetCheckedKeys default check nodes, and a new check through setChecked specified node
帆软11版本参数联动为null查询全部
第五章:指令集
多线程可见
(十五)51单片机——呼吸灯与直流电机调速(PWM)
tmp
【RT_Thread学习笔记】---以太网LAN8720A Lwip ping 通网络
VR全景市场拓展技巧之“拓客宝典”
Example of embedding code for continuous features