当前位置:网站首页>[learning notes - Li Hongyi] Gan (generation of confrontation network) full series (I)
[learning notes - Li Hongyi] Gan (generation of confrontation network) full series (I)
2022-07-07 10:07:00 【iioSnail】
List of articles
Preface
Red text Representative focus , Yellow text Represents the secondary focus , Green text Represents understanding , Black text is explanation
Related links
- video :https://www.youtube.com/playlist?list=PLJV_el3uVTsMq6JEFPW35BCiOQTsoqwNw
1. Introduction
1. 1 Basic Idea of GAN
GAN, Generative Adversarial Network, The function is to train a Generator, Used to generate things . for example , If it is in the field of pictures , Can generate face pictures , If it is in the text field , Can be used to generate articles
Generator Use : to Generator A random Vector, then Generator Generate a random “ Long Vector”( picture 、 Words etc. )

Input Vector Of dimension( Is each value ) Corresponding to a feature , For example, the first one in the picture above 0.1 Maybe it corresponds to the color of hair
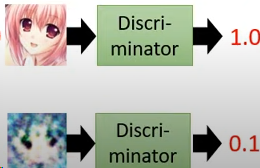
Discriminator( Judging device ): In the training Generator When , Train one at the same time Discriminator, The function is to judge the authenticity of a picture .
Discriminator Accept a picture , Output one Scalar( The number ),Scalar The bigger the picture is, the more realistic it is
GAN Training process of ( Simple version of )
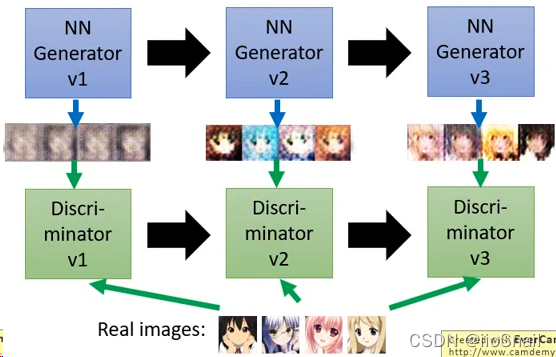
1. Prepare a data set of real pictures
2. Random initialization Generator and Discriminator, here Generator Generating pictures is blind ,Discriminator It's also blind discrimination
3. Training Discriminator:
3.1 Give Way Generator Generate a set of pictures , And then let Discriminator To distinguish between true and false , It will also tell Discriminator What does the real picture look like
3.2. According to the first 3.1 Step loss to update Discriminator
4. Training Generator:
4.1. Continue to let go Generator Generate a set of pictures , And then let Discriminator To tell the true from the false . Be careful , This time, we will only let Discriminator Look at the generated pictures
4.2. According to the first 4.1 Step to get the loss to update Generator
5. Repeat iteration 3,4 Step , Until you are satisfied
( ancestral )GAN Training process ( Formula version ), In each iteration process, do the following :
1. Get from the data set m m m Samples { x 1 , x 2 , … , x m } \{ x^1, x^2, \dots, x^m \} { x1,x2,…,xm}
2. from distribution Took out m m m A noise vector { z 1 , z 2 , … , z m } \{ z^1, z^2, \dots, z^m \} { z1,z2,…,zm}( It's generation m A uniformly distributed random vector , Of course, it can also be other distributions )
3. Give Way Generator Generate data according to the noise vector { x ~ 1 , x ~ 2 , … , x ~ m } \{ \tilde{x}^1, \tilde{x}^2, \dots, \tilde{x}^m \} { x~1,x~2,…,x~m}, namely x ~ i = G ( z i ) \tilde{x}^i =G(z^i) x~i=G(zi)( there x ~ i \tilde{x}^i x~i It's a picture , for example , To generate a 64x64 Pictures of the , that x ~ i \tilde{x}^i x~i It's just one. 4096 Dimension vector )
4. to update Discriminator Parameters of θ d \theta_d θd, The update process is as follows :
4.1. Calculation Discriminator Yes “ Real data ” Discrimination results , namely D ( x i ) ∈ [ 0 , 1 ] D(x^i) \in [0,1] D(xi)∈[0,1], We want this value The bigger the better
4.2. Calculation Discriminator Yes “ Generate the data ” The result of discrimination is , namely D ( x ~ i ) D(\tilde{x}^i) D(x~i), We hope this result The smaller the better.
4.3. Calculation m m m A sample of “ Average loss ”, V ~ = 1 m ∑ i = 1 m log D ( x i ) + 1 m ∑ i = 1 m log ( 1 − D ( x ~ i ) ) \tilde{V} = \frac{1}{m}\sum_{i=1}^{m}\log D(x^i) + \frac{1}{m}\sum_{i=1}^{m}\log\left( 1- D(\tilde{x}^i)\right) V~=m1i=1∑mlogD(xi)+m1i=1∑mlog(1−D(x~i)) among V ~ \tilde{V} V~ It's a negative number , therefore The bigger the better
4.4. Update parameters θ d \theta_d θd, namely θ d ← θ d + η ∇ V ~ ( θ d ) \theta_d \leftarrow \theta_d + \eta\nabla\tilde{V}(\theta_d) θd←θd+η∇V~(θd)
5. to update Generator Parameters of θ g \theta_g θg, The update process is as follows
5.1. Again from distribution Take out a set of noise vectors { z 1 , z 2 , … , z m } \{ z^1, z^2, \dots, z^m \} { z1,z2,…,zm}
5.2. Give Way Generator Regenerate into a set of data , And give it to Discriminator To judge , And get a score D ( G ( z i ) ) D\left(G(z^i)\right) D(G(zi))
5.3. Calculation “ Average loss ” V ~ = 1 m ∑ i = 1 m log D ( G ( z i ) ) \tilde{V} = \frac{1}{m}\sum_{i=1}^{m}\log D\left(G(z^i)\right) V~=m1i=1∑mlogD(G(zi)) Again , V ~ \tilde{V} V~ It's a negative number , therefore The bigger the better
5.4. to update Generator Parameters of , θ g ← θ g + η ∇ V ~ ( θ g ) \theta_g \leftarrow \theta_g + \eta\nabla\tilde{V}(\theta_g) θg←θg+η∇V~(θg)
If the continuous internal difference between two noise vectors is given ,Generator Will tell you the transition process between these two pictures

1.2 GAN as structured learning
Structured Learning What is it? : If the output of a task is sequence、matrix, graph, tree etc. , Then this task is called Structured Learning
Structured learning Characteristics :
1. You can think of each output as a “ Category (Class)”
2. Huge output space ( There are too many kinds of output ), Means output “class” There is no corresponding “train data”, For example, the generated face image cannot be found in the training set
3. Testing phase , The output of the network must be something new . for example : The face image generated in the test phase is not generated in the training phase
4. Need a more intelligent network
5. The network must have an overall view , For example, when generating articles , Just looking at a few words can't tell whether the result is good or bad , Look at the whole article
Structured Learning Two ways :
1. Bottom Up( Bottom up ): From part to whole
2. Top Down( The top-down ): From the whole to the part
You can put GAN As a Structured Learning
GAN Of Generator It can be seen as Bottom UP Of , Because it is learned module by module , For example, when generating animation avatars task in , It first learns to generate contours , Then learn to generate eyes , Then learn to make mouth , Then go on
GAN Of Discriminator It can be seen as Top Down Of , Because it judges the quality of the goal from the whole
1.3 Generator Can you learn by yourself ?
The basic idea : Use Supervised Learning The way , Give the picture a vector , Then input as this vector , Output as picture vector , The goal is to make Generator The closer the output of is to the original picture, the better .
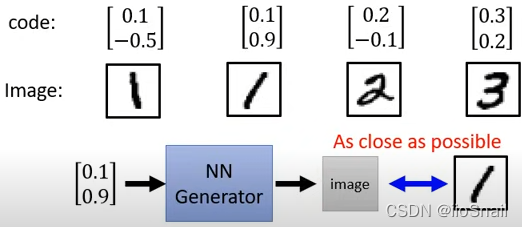
Pay attention to every one of them dimension To correspond to a feature , For example, the first dimension Corresponding 0.1,0.2 It's a number 1,2, And the second one. -0.5,0.9 Corresponding rotation
How to define the above Code( Input vector )? have access to Auto-Encoder
Ideas : Type the picture in Encoder, Encoding , Then send the code to Decoder Try to restore the picture as much as possible , Final Decoder That's what we want Generator
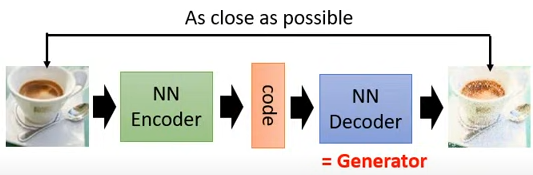
defects : Because the number of pictures is limited , It is impossible to enumerate all Code, In this way, once you give Decoder( That is to say Generator) An unknown Code, May be blind to produce pictures . But this question can be used VAE(Variational Auto-Encoder) solve
hypothesis code It's two-dimensional , The final effect is :

Enter each dimension Represents a feature
VAE(Variational Auto-encoder)
Ideas : Transform on the original basis Encoder, Give Way Encoder One more variance( σ \sigma σ), And then from distribution Take out a set of noise vectors ( e e e), Then merge the three (code,variance, Noise vector ), Get a new vector and send it to Decoder
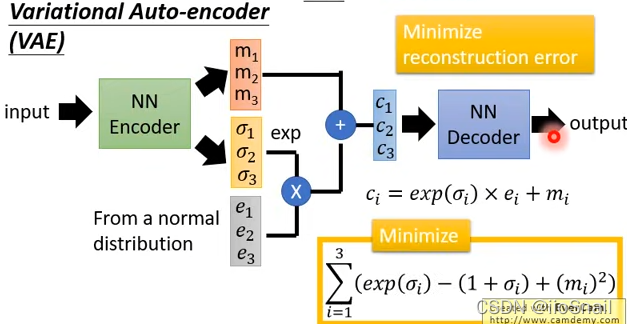
advantage : Because of the combination of variance And noise , You can make Decoder(Generator) A more stable , In the test phase, even if you see input that you haven't seen , It can also produce reasonable pictures
2. CGAN, Conditional Generation by GAN
Conditional GAN(CGAN): To specify GAN What kind of pictures are generated , That is, when entering , Except random noise, There is also an extra GAN One class, To refer to the category to be entered , for example “dog”、“cat” etc.

Again , In the training Discriminator When , Consider also class

Conditional GAN Training process of ( Formula version ):
First Train Discriminator
1. Take it out of the data set m m m Samples { ( c 1 , x 1 ) , ( c 2 , x 2 ) , … , ( c m , x m ) } \{ (c^1, x^1),(c^2, x^2),\dots,(c^m, x^m) \} { (c1,x1),(c2,x2),…,(cm,xm)}, among x i x^i xi It's a picture. , c i c^i ci Is the category corresponding to the picture
2. from distribution Took out m m m A noise vector { z 1 , z 2 , … , z m } \{ z^1, z^2, \dots, z^m \} { z1,z2,…,zm}
3. Give Way Generator Generate data according to noise vectors and categories { x ~ 1 , x ~ 2 , … , x ~ m } \{ \tilde{x}^1, \tilde{x}^2, \dots, \tilde{x}^m \} { x~1,x~2,…,x~m}, namely x ~ i = G ( c i , z i ) \tilde{x}^i =G(c^i, z^i) x~i=G(ci,zi)
4. Then take it out of the data set m m m Samples { x ^ 1 , x ^ 2 , … , x ^ m } \{ \hat{x}^1, \hat{x}^2, \dots, \hat{x}^m \} { x^1,x^2,…,x^m}, Don't take the corresponding category this time
5. to update Discriminator Parameters of θ d \theta_d θd, Steps are as follows :
5.1 Give Way Discriminator Identify real samples and their corresponding categories , namely D ( c i , x i ) ∈ [ 0 , 1 ] D(c^i, x^i) \in [0,1] D(ci,xi)∈[0,1], This value The bigger the better
5.2 Give Way Discriminator Identify the generated samples and their corresponding categories , namely D ( c i , x ~ i ) D(c^i, \tilde{x}^i) D(ci,x~i) , This value The smaller the better.
5.3 Give Way Discriminator Identify the categories of errors corresponding to real samples , namely D ( c i , x ^ i ) D(c^i, \hat{x}^i) D(ci,x^i), This value The smaller the better. .
5.4. Calculation m m m A sample of “ Loss function ”, V ~ = 1 m ∑ i = 1 m log D ( c i , x i ) + 1 m ∑ i = 1 m log ( 1 − D ( c i , x ~ i ) ) + 1 m ∑ i = 1 m log ( 1 − D ( c i , x ^ i ) ) \tilde{V} = \frac{1}{m}\sum_{i=1}^{m}\log D(c^i, x^i) + \frac{1}{m}\sum_{i=1}^{m}\log\left( 1- D(c^i, \tilde{x}^i)\right) + \frac{1}{m}\sum_{i=1}^{m}\log\left( 1- D(c^i, \hat{x}^i)\right) V~=m1i=1∑mlogD(ci,xi)+m1i=1∑mlog(1−D(ci,x~i))+m1i=1∑mlog(1−D(ci,x^i)) among V ~ \tilde{V} V~ It's a negative number , therefore The bigger the better
5.5. Update parameters θ d \theta_d θd, namely θ d ← θ d + η ∇ V ~ ( θ d ) \theta_d \leftarrow \theta_d + \eta\nabla\tilde{V}(\theta_d) θd←θd+η∇V~(θd)
Next Train Generator
6. from distribution Took out m m m A noise vector { z 1 , z 2 , … , z m } \{ z^1, z^2, \dots, z^m \} { z1,z2,…,zm}
7. Pick from the data set m m m Categories { c 1 , c 2 , … , c m } \{ c^1, c^2, \dots, c^m \} { c1,c2,…,cm}
8. to update Generator Parameters of θ g \theta_g θg, The update process is as follows :
8.1. Give Way Generator Generate a set of data , And give it to Discriminator To judge , And get a score D ( G ( c i , z i ) ) D\left(G(c^i, z^i)\right) D(G(ci,zi))
8.2. Calculation “ Loss function ” V ~ = 1 m ∑ i = 1 m log D ( G ( c i , z i ) ) \tilde{V} = \frac{1}{m}\sum_{i=1}^{m}\log D\left(G(c^i, z^i)\right) V~=m1i=1∑mlogD(G(ci,zi)) Again , V ~ \tilde{V} V~ It's a negative number , therefore The bigger the better
8.3. to update Generator Parameters of , θ g ← θ g + η ∇ V ~ ( θ g ) \theta_g \leftarrow \theta_g + \eta\nabla\tilde{V}(\theta_g) θg←θg+η∇V~(θg)
2.1 discriminator Architecture improvements for
The common architecture is to “ Whether the sample is true ” and “ Whether the sample corresponds to the category ” Combine the two scores of , Give a score , But there's a drawback to that :Network It may be impossible to tell whether the current low score is caused by the unreal sample or the wrong sample category .
The original look :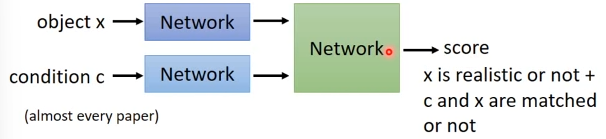
Discriminator Improved architecture : take “ Authenticity discrimination ” and “ Whether the category corresponds to ” Come apart :
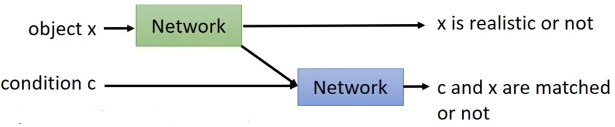
2.2 Stack GAN
Stack GAN:Conditional GAN A kind of , The idea is : First generate small pictures , And then produce big pictures . Thesis link :StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
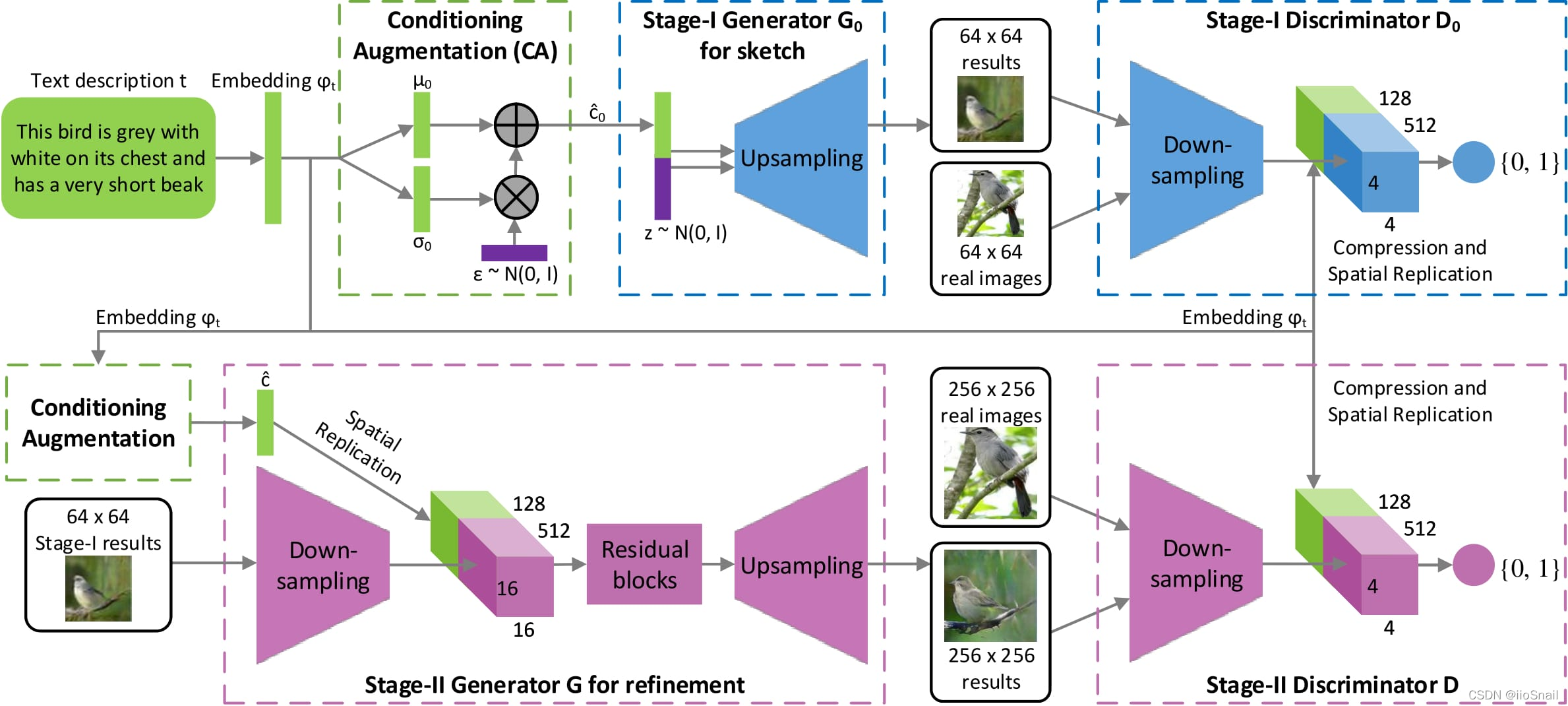
2.3 Image-to-image
Thesis link :Image-to-Image Translation with Conditional Adversarial Networks
Image-to-image: Give the machine a picture , Then let him generate a new picture . for example , Give the machine a cartoon picture , Let the machine produce a real picture .
Ideas : to Generator A vector z z z And pictures , then Generator Generate a new picture . Next, throw the input image and output image to Discriminator, Let it produce a Scalar To judge the results
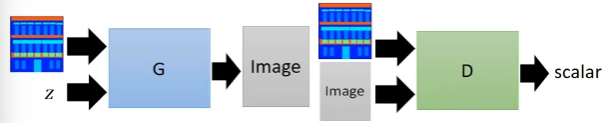
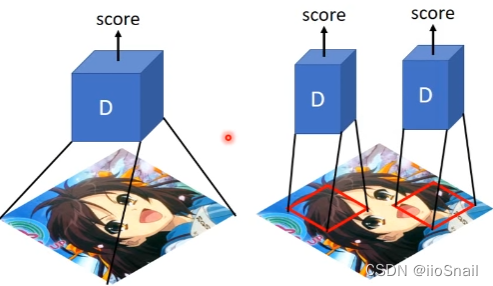
Patch GAN: above Gan It's not processing the whole picture at once , Because the pictures are too big overfiting And the long training time . So it is a small area of input image each time , And then deal with it , This technology is called Patch GAN
2.4 Speech Enhancement( Improve the quality of voice )
Speech Enhancement: Use algorithms to improve the quality of speech , be called Speech Enhancement

On the left is the sound containing noise , On the right is enhance after , Parts without noise
Traditional approach : Use Supervised learning The way of training , The goal is to make Output( Clear voice output ) And labels ( Real and clear voice ) The closer you get, the better
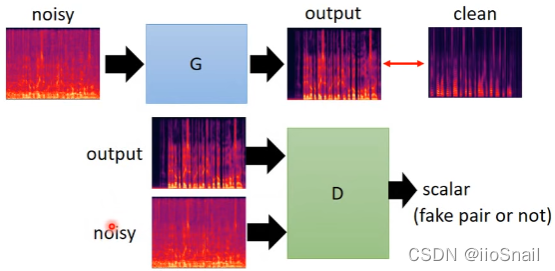
use GAN The way : stay “ Traditional approach ” To add Discriminator, Give Way Discriminator Judge whether the generated input and output are “ a pair ”
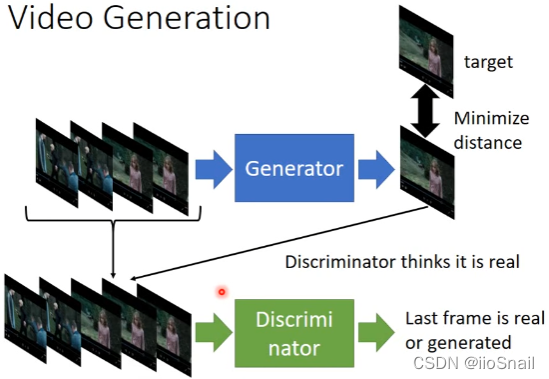
2.5 Video Generation
Video Generation: Give the machine a video , Then let the machine produce the next frame
Ideas : to Generator The previous frames , Let it produce the next frame . Then connect the generated frame picture with the previous picture , Send Discriminator, Let it judge whether this is a reasonable video
3. Unsupervised Conditional Generation
Unsupervised Conditional Generation: Give the machine two piles of data , The purpose is to let the machine generate data of another style based on data of one style . But the training materials do not indicate which two data are a pair . for example , We want to generate oil painting style pictures based on real pictures

3.1 Method 1: Direct conversion
Ideas : Train one Generator So that it can input from domain X Switch to another domain Y. At the same time, train another Discriminator, The task is to judge whether an input is domain Y Of .
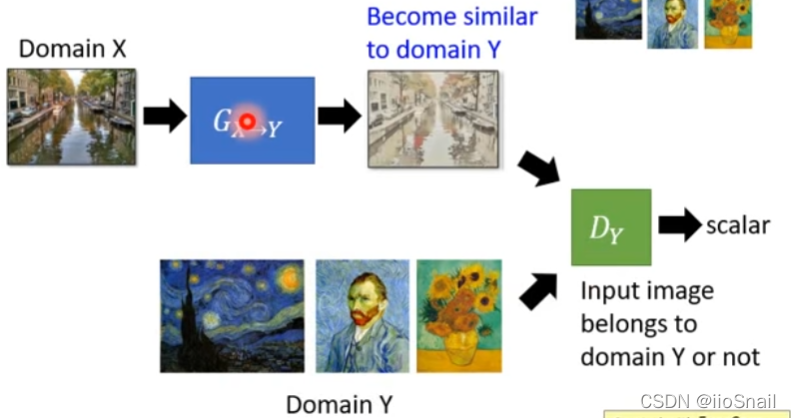
There is a drawback to doing this directly :Generator It may produce something completely unrelated to the original image , As long as this thing can make Discriminator Think it's domain Y The line . So we need to add some constraint
The current practice in the literature :
1. Nothing , direct train, because network It will tend not to modify the input too much , In especial Network When it's shallow . Related papers :The Role of Minimal Complexity Functions in Unsupervised Learning of Semantic Mappings
2. Yes Generator Input and output of embedding( For example, using VGG Wait for the pre trained model embedding), Then let two embedding The closer you get, the better
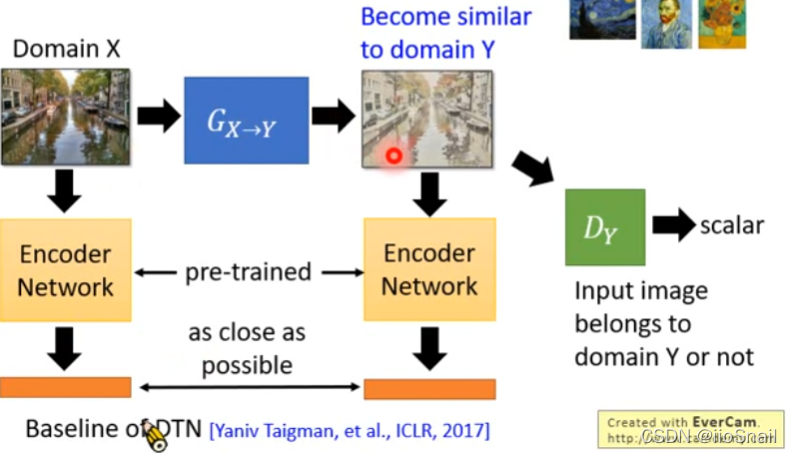
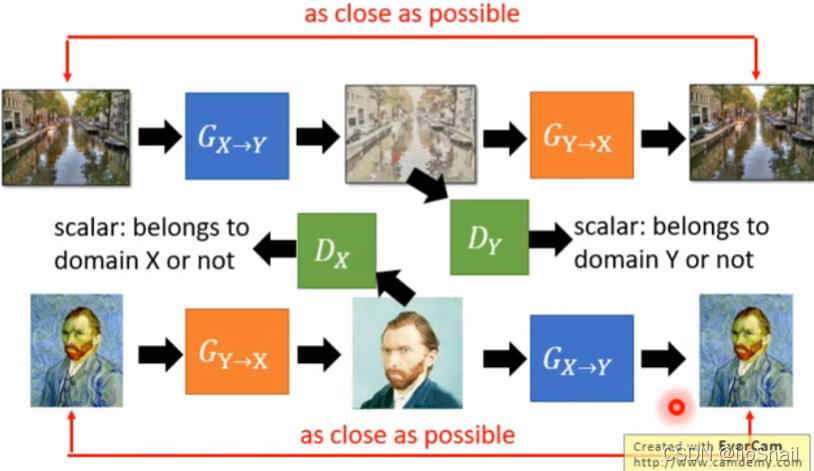
3. Use Cycle GAN
The basic idea : Train two Generator, The first is to input from domain X go to domain Y( This is the final need ). the second Generator It's going to be the first Generator The output of is from domain Y Turn it back domain X, Then let the second Generator The closer the output is to the initial input, the better .
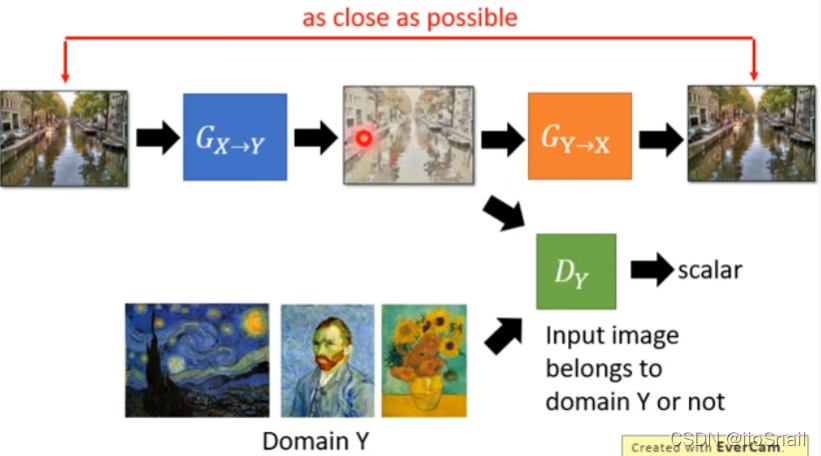
Advanced thinking :Discriminatior You can also cycle . There was only one before Discriminator, Used to judge the output G X → Y G_{X\rightarrow Y} GX→Y Whether the output of is domain Y. Now add another Discriminator, Judge G Y → X G_{Y\rightarrow X} GY→X Is the output of domain X.
Method 2:VAE GAN: Project to Common Space
Suppose we want to turn real character avatars into anime characters , We can do that : Train two groups VAE, The first pair Encoder and Decoder Be responsible for encoding and decoding real people , The second couple Encoder and Decoder Be responsible for encoding and decoding animation characters . When we need to transform , We only need to use the first pair of avatars of real people Encoder Encoding , Then use the second pair Decoder Just decode .
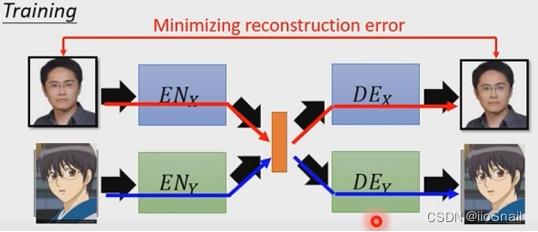
Train two groups VAE, Respectively for real character avatars and cartoon character avatars .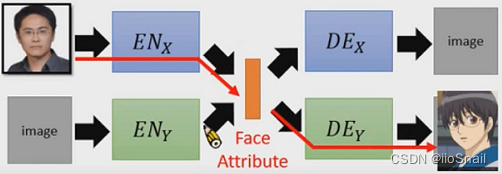
After training , We only need to use the avatar of real people E N X EN_X ENX Encoding , And then use D E Y DE_Y DEY decode , In this way, you can successfully convert .
There is a problem with the above method : The first group VAE The intermediate vector of is not necessarily compatible with the second group . for example , The vector coding of real people is the first dimension May represent gender , The second represents age , The vector coding of animation characters may be just the opposite , This will lead to the generated animation characters and real characters are far from each other .
In order to solve the above problems , A common method is : share Encoder And Decoder The first few layers of weight
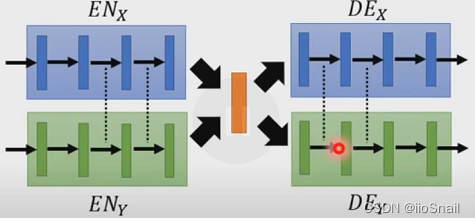
There are many other ways , More methods can be referred to video :https://www.youtube.com/watch?v=-3LgL3NXLtI&list=PLJV_el3uVTsMq6JEFPW35BCiOQTsoqwNw&index=3
GAN( Generative antagonistic network ) A full range ( Two )
because CSDN There is a limit on the length of the article , So we will divide it into chapters :
GAN( Generative antagonistic network ) A full range ( Two ) link :https://blog.csdn.net/zhaohongfei_358/article/details/123953391
More information
- All kinds of GAN:https://github.com/hindupuravinash/the-gan-zoo
边栏推荐
- web3.0系列之分布式存储IPFS
- MySQL can connect locally through localhost or 127, but cannot connect through intranet IP (for example, Navicat connection reports an error of 1045 access denied for use...)
- Integer inversion
- CSDN salary increase technology - learn about the use of several common logic controllers of JMeter
- Introduction to energy Router: Architecture and functions for energy Internet
- CDZSC_2022寒假个人训练赛21级(2)
- flink. CDC sqlserver. You can write the DEM without connector in sqlserver again
- Codeforces - 1324d pair of topics
- flink. CDC sqlserver. 可以再次写入sqlserver中么 有连接器的 dem
- 中国首款电音音频类“山野电音”数藏发售来了!
猜你喜欢
The landing practice of ByteDance kitex in SEMA e-commerce scene
ORM--数据库增删改查操作逻辑
ORM--查询类型,关联查询

喜马拉雅网页版每次暂停后弹窗推荐下载客户端解决办法

使用BigDecimal的坑
XML配置文件解析与建模

CentOS installs JDK1.8 and mysql5 and 8 (the same command 58 in the second installation mode is common, opening access rights and changing passwords)
Flex flexible layout
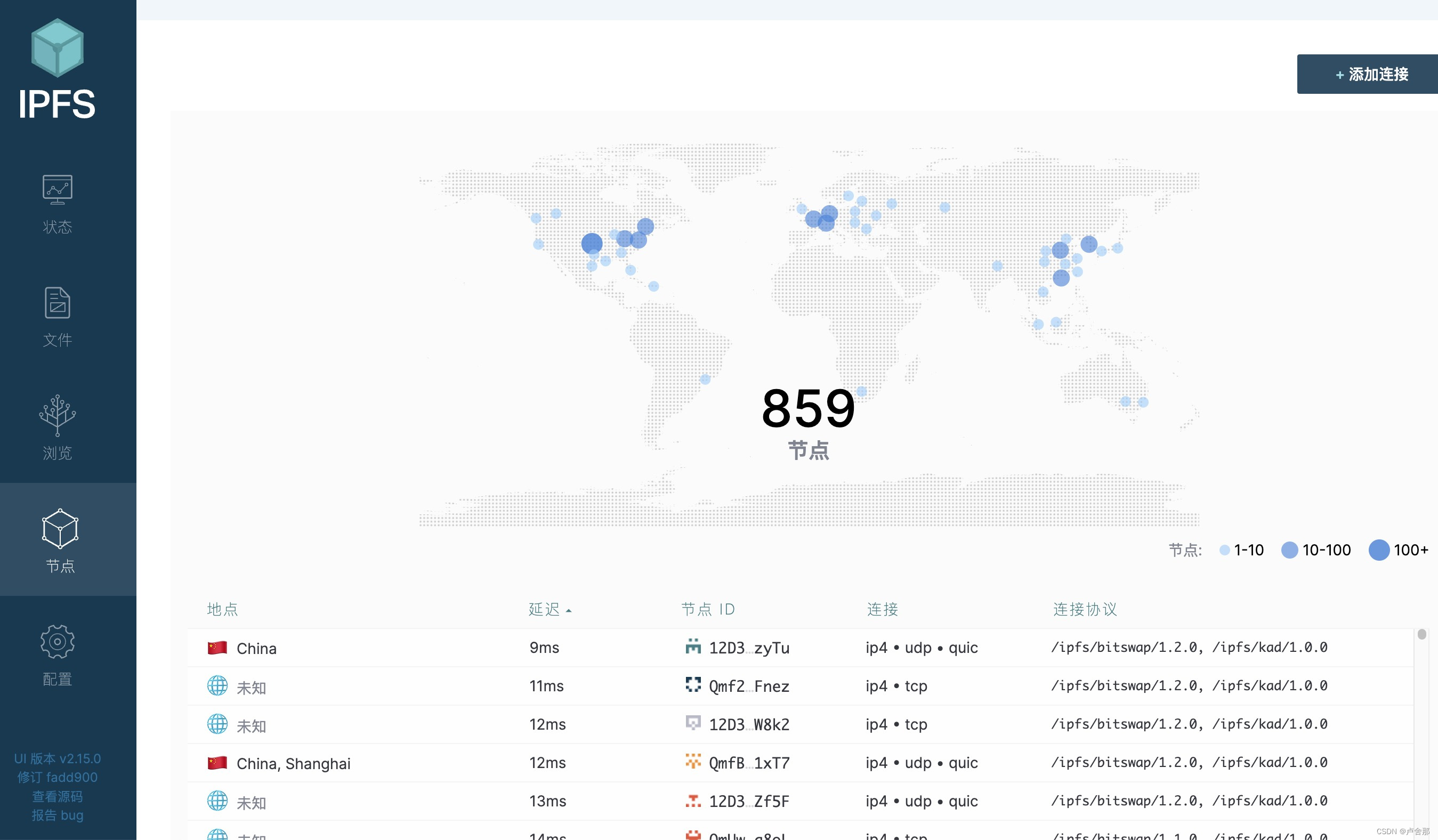
web3.0系列之分布式存储IPFS
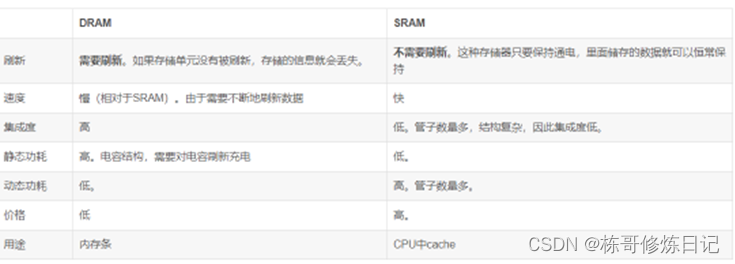
Memory ==c language 1
随机推荐
用flinksql的方式 写进 sr的表,发现需要删除的数据没有删除,参照文档https://do
[4g/5g/6g topic foundation -147]: Interpretation of the white paper on 6G's overall vision and potential key technologies -2-6g's macro driving force for development
CDZSC_2022寒假个人训练赛21级(1)
ORM模型--数据记录的创建操作,查询操作
Natapp intranet penetration
喜马拉雅网页版每次暂停后弹窗推荐下载客户端解决办法
phpcms实现PC网站接入微信Native支付
Delete a record in the table in pl/sql by mistake, and the recovery method
The new activity of "the arrival of twelve constellations and goddesses" was launched
Gym - 102219j kitchen plates (violent or topological sequence)
A wave of open source notebooks is coming
CDZSC_2022寒假个人训练赛21级(2)
Software modeling and analysis
Can flycdc use SqlClient to specify mysqlbinlog ID to execute tasks
Arthas simple instructions
Flinkcdc failed to collect Oracle in the snapshot stage. How do you adjust this?
第十四次试验
Web3.0 series distributed storage IPFs
Analyze Android event distribution mechanism according to popular interview questions (I)
Basic use of JMeter to proficiency (I) creation and testing of the first task thread from installation