当前位置:网站首页>【分层强化学习】HIRO:Data-Efficient Hierarchical Reinforcement Learning
【分层强化学习】HIRO:Data-Efficient Hierarchical Reinforcement Learning
2022-08-01 01:30:00 【小帅吖】
论文名称:Data-Efficient Hierarchical Reinforcement Learning
作者:Ofir Nachum, Shixiang (Shane) Gu, Honglak Lee, Sergey Levine
发布自:NeurIPS 2018
摘要
分层强化学习 (HRL) 是一种很有前途的方法,可以扩展传统的强化学习 (RL) 方法以解决更复杂的任务。当前的大多数 HRL 方法都需要仔细的特定任务设计和策略训练,这使得它们难以应用于现实世界的场景。在本文中,我们研究了如何开发通用的 HRL 算法,因为它们不会在标准 RL 算法之外做出繁重的额外假设,并且是高效的,因为它们可以与适度数量的交互样本一起使用,使它们适用于机器人控制等现实问题。为了一般性,我们开发了一个方案,其中低级控制器由高级控制器自动学习和提出的目标进行监督。为了提高效率,我们建议在高级和低级训练中使用off-policy经验。这带来了相当大的挑战,因为低层行为的变化会改变高层政策的行动空间,我们引入了一种Off-Policy Corrections来解决这一挑战。这使我们能够利用off-policy
model-free RL 的最新进展,使用比策略上算法少得多的环境交互来学习更高级别和更低级别的策略。我们将生成的 HRL 代理称为 HIRO,并发现它普遍适用且样本效率很高。我们的实验表明,HIRO 可用于学习模拟机器人的高度复杂行为,例如推动物体并利用它们到达目标位置,从几百万个样本中学习,相当于几天的实时交互。与许多先前的 HRL 方法相比,我们发现我们的方法大大优于先前的最先进技术。
算法框架


内部奖励
其中high-level的策略产生的目标 gt 表明状态观察中所需的相对变化。也就是说,在步骤 t,高层策略产生一个目标 gt,表明它希望低层智能体采取行动,产生一个接近于 st + gt 的观察 st+c。尽管某些状态维度作为目标子空间更自然,但我们选择了这种更通用的goal representation以使其具有广泛的适用性,而无需手动设计目标空间、基元或可控维度.这使得我们的方法具有通用性并适用于新的问题设定。
无论状态如何变化,为了保持目标的相同绝对位置,目标转移模型 h 定义为

将内在奖励定义为基于当前观察与目标观察之间的距离的参数化奖励函数: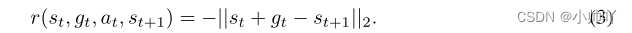
上面这个奖励函数针对low-level级别的策略,用于采取产生接近期望值 st + gt 的观察的行动。
可以通过简单地将 gt 作为附加输入合并到价值和策略模型中,使用标准方法训练较低级别的策略。例如,在 DDPG 中,low-level的critic通过最小化下面等式的误差来实现:
策略actor通过下面的方式更新:
Off-Policy Corrections for Higher-Level Training
什么是非平稳性问题?


这里我的理解是通过修改transition中的目标,使得当遇到同样的状态时,下层的策略最终产生的传递到上层的结果与之前遇到这种状态时的传递到上层的结果一致。
参考:
https://zhuanlan.zhihu.com/p/86602304
https://zhuanlan.zhihu.com/p/497424021
HIRO的pytorch代码:https://github.com/watakandai/hiro_pytorch
边栏推荐
- leetcode: 1562. Find latest grouping of size M [simulation + endpoint record + range merge]
- Unity3D study notes 10 - texture array
- Summary of MVCC
- date command
- Item 36: Specify std::launch::async if asynchronicity is essential.
- Inheritance Considerations
- ECCV2022 Workshop | 复杂环境中的多目标跟踪和分割
- Completely closed Chrome updated and in the top right corner of the tip
- Four ways the Metaverse is changing the way humans work
- MYSQL logical architecture
猜你喜欢
IDEA无法识别module(module右下角没有蓝色小方块)

Device tree - conversion from dtb format to struct device node structure
设备树的树形结构到底是怎样体现的?
![[Data analysis] Based on matlab GUI student achievement management system [including Matlab source code 1981]](/img/65/b84443b98c28d2728e9ae44b1294fb.jpg)
[Data analysis] Based on matlab GUI student achievement management system [including Matlab source code 1981]
Solve the problem that Excel opens very slowly after installing MySQL
How to get started with YOLO?How to implement your own training set?

Key Points Estimation and Point Instance

WeChat applet page syntax
![leetcode: 1648. Color ball with decreasing sales value [Boundary find by two points]](/img/b9/7bd33bd981ace25e3bbfc7be9117ff.png)
leetcode: 1648. Color ball with decreasing sales value [Boundary find by two points]

Cmake introductory study notes
随机推荐
Data Middle Office Construction (VII): Data Asset Management
How is the tree structure of the device tree reflected?
机器学习初学者可以学哪些实战项目?
【历史上的今天】7 月 31 日:“缸中之脑”的提出者诞生;Wi-Fi 之父出生;USB 3.1 标准发布
MYSQL transactions
OSF一分钟了解敏捷开发模式
MYSQL query interception optimization analysis
Talking about hardware device computing storage and data interaction
STK8321 I2C(昇佳-加速度传感器)示例
Application of integrated stepper motor in UAV automatic airport
Daily practice of LeetCode - Circular linked list question (interview four consecutive questions)
Solve the problem that when IDEA creates a new file by default, right-click, new, there is no XML file
修改Postman安装路径
链式编程、包、访问权限
ROS2系列知识(4): 理解【服务】的概念
/usr/sbin/vmware-authdlauncher: error while loading shared libraries: libssl.so.1.0.2*Solution
WebApi hits an Attribute to handle exceptions uniformly
【Cryptography/Cryptanalysis】Cryptanalysis method based on TMTO
JVM面试题总结(持续更新中)
IDEA修改注释字体