当前位置:网站首页>Redis Key-Value数据库【初级】
Redis Key-Value数据库【初级】
2022-07-02 05:53:00 【进击的程序猿~】
相关链接:
Redis Key-Value数据库【初级】: https://blog.csdn.net/qq_41822345/article/details/125527045
Redis Key-Value数据库【高级】: https://blog.csdn.net/qq_41822345/article/details/125568007
Redis Key-Value数据库【秒杀】: https://blog.csdn.net/qq_41822345/article/details/125568012
一、NoSQL数据库简介
1、技术分类
1、解决功能性的问题【CRUD】:Java、Jsp、RDBMS、Tomcat、HTML、Linux、JDBC、SVN
2、解决扩展性的问题【规范】:Struts、Spring、SpringMVC、SpringBoot、Mybatis
3、解决性能的问题【并发】:NoSQL、Java线程、Hadoop、Nginx、MQ、ElasticSearch
随着Web2.0的时代的到来,用户访问量大幅度提升,同时产生了大量的用户数据。加上后来的智能移动设备的普及,所有的互联网平台都面临了巨大的性能挑战。
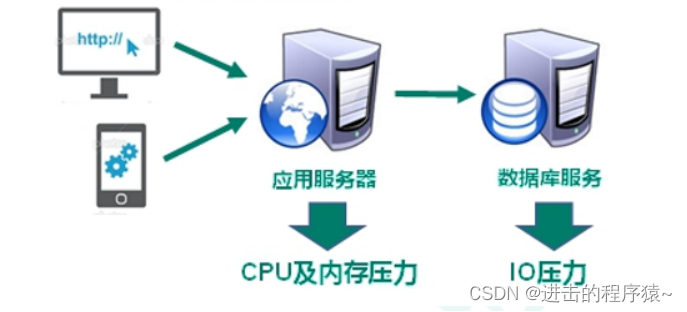
对于应用服务器,面临CPU及内存压力→缓存数据库。如下图:

对于数据库服务,面临IO压力→缓存数据库。如下图:

2、什么是NoSQL
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,泛指非关系型的数据库。
NoSQL 不依赖业务逻辑方式存储,而以简单的key-value模式存储。因此大大的增加了数据库的扩展能力。
特点:
不遵循SQL标准。
不支持ACID。
远超于SQL的性能。
3、NoSQL场景
- 适用场景
对数据高并发的读写。
海量数据的读写。
对数据高可扩展性的。
- 不适用场景
需要事务支持。
基于sql的结构化查询存储,处理复杂的关系,需要即席查询。
用不着sql的和用了sql也不行的情况,请考虑用NoSql。
4、常见NoSQL
数据库排名:https://db-engines.com/en/ranking
Memcache
很早出现的NoSql数据库。
数据都在内存中,一般不持久化。
支持简单的key-value模式,支持类型单一。
一般是作为缓存数据库辅助持久化的数据库。
Redis
几乎覆盖了Memcached的绝大部分功能。
数据都在内存中,支持持久化,主要用作备份恢复。
除了支持简单的key-value模式,还支持多种数据结构的存储,比如 list、set、hash、zset等。
一般是作为缓存数据库辅助持久化的数据库。
MongoDB
高性能、开源、模式自由(schema free)的文档型数据库。
数据都在内存中, 如果内存不足,把不常用的数据保存到硬盘。
虽然是key-value模式,但是对value(尤其是json)提供了丰富的查询功能。
支持二进制数据及大型对象。
可以根据数据的特点替代RDBMS ,成为独立的数据库。或者配合RDBMS,存储特定的数据。
MongoDB相关链接: https://blog.csdn.net/qq_41822345/article/details/123490879
Hbase
HBase是Hadoop项目中的数据库。它用于需要对大量的数据进行随机、实时的读写操作的场景中。
HBase的目标就是处理数据量非常庞大的表,可以用普通的计算机处理超过10亿行数据,还可处理有数百万列元素的数据表。
Cassandra
Apache Cassandra是一款免费的开源NoSQL数据库,其设计目的在于管理由大量商用服务器构建起来的庞大集群上的海量数据集(数据量通常达到PB级别)。
是对写入及读取操作进行规模调整,而且其不强调主集群的设计思路能够以相对直观的方式简化各集群的创建与扩展流程。
图数据库
主要应用:社会关系,公共交通网络,地图及网络拓谱(n*(n-1)/2)
二、Redis概述
1、概述
Redis是一个开源的key-value存储系统。- 和
Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set—有序集合)和hash(哈希类型)。 - 这些数据类型都支持
push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。 - 在此基础上,
Redis支持各种不同方式的排序。 - 与
memcached一样,为了保证效率,数据都是缓存在内存中。 - 区别的是Redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件。
- 并且在此基础上实现了
master-slave(主从)同步。
Redis与Memcache三点不同: 支持多数据类型,支持持久化,单线程+多路IO复用。
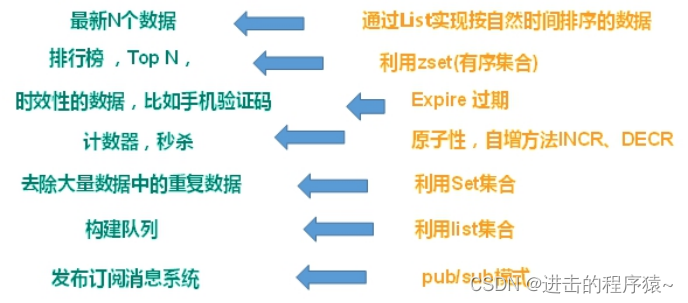
2、应用场景
- 配合关系型数据库做高速缓存
- 高频次,热门访问的数据,降低数据库IO
- 分布式架构,做session共享
- 多样的数据结构存储持久化数据【面试高频】
3、安装
Redis官网:http://redis.io
Redis中文官网:http://redis.cn
官网描述:
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
安装步骤【简单】:
step1:安装C 语言的编译环境
yum install centos-release-scl scl-utils-build
yum install -y devtoolset-8-toolchain
scl enable devtoolset-8 bash
gcc --version
step2:redis-6.2.1.tar.gz放/opt目录
cd /opt
tar -zxvf redis-6.2.6.tar.gz
cd redis-6.2.6
step3:编译安装
make
make install
step4:查看安装目录/usr/local/bin
有如下文件:redis-benchmark:性能测试工具,可以在自己本子运行,看看自己本子性能如何redis-check-aof:修复有问题的AOF文件,rdb和aof后面讲redis-check-dump:修复有问题的dump.rdb文件redis-sentinel:Redis集群使用redis-server:Redis服务器启动命令redis-cli:客户端,操作入口
4、启动
前台启动【不推荐】:
redis-server
# redis-server Redis服务器启动命令
# redis-cli Redis客户端,操作入口
后台启动【推荐】:
vim /opt/redis-6.2.6/redis.conf
#将daemonize no改成daemonize yes
redis-server /opt/redis-6.2.6/redis.conf
客户端访问:
redis-cli
redis-cli -p 6379
客户端关闭:
redis-cli shutdown
redis-cli -p 6379 shutdown
5、redis基础
默认16个数据库,类似数组下标从0开始,初始默认使用0号库。使用命令 select 来切换数据库。如: select 8 。统一密码管理,所有库同样密码。
dbsize #查看当前数据库的key的数量
flushdb #清空当前库
flushall #通杀全部库
Redis是单线程+多路IO复用技术
多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)
三、Redis配置文件
配置文件redis.conf
1、Units和include
Units部分配置大小单位,开头定义了一些基本的度量单位,只支持bytes,不支持bit。大小写不敏感。
include部分类似jsp中的include,多实例的情况可以把公用的配置文件提取出来。
2、网络相关配置
- bind
默认情况bind=127.0.0.1只能接受本机的访问请求。
不写的情况下,可以无限制接受任何ip地址的访问。
生产环境肯定要写应用服务器的地址;服务器是需要远程访问的,所以需要将其注释掉。
如果开启了protected-mode,那么在没有设定bind ip且没有设密码的情况下,Redis只允许接受本机的响应。
- protected-mode
本机访问保护模式设置no
- port
默认端口号 6379
- tcp-backlog
tcp的backlog其实是一个连接队列,backlog队列总和=未完成三次握手队列 + 已经完成三次握手队列。
在高并发环境下需要一个高backlog值来避免慢客户端连接问题。
注意Linux内核会将这个值减小到/proc/sys/net/core/somaxconn的值(128),所以需要确认增大/proc/sys/net/core/somaxconn和/proc/sys/net/ipv4/tcp_max_syn_backlog(128)两个值来达到想要的效果
- timeout
一个空闲的客户端维持多少秒会关闭,0表示关闭该功能。即永不关闭。
- tcp-keepalive
对访问客户端的一种心跳检测,每个n秒检测一次。
单位为秒,如果设置为0,则不会进行Keepalive检测,建议设置成60。
3、GENERAL通用
- daemonize
是否为后台进程,设置为yes表示为守护进程,后台启动。
- pidfile
存放pid文件的位置,每个实例会产生一个不同的pid文件。
- loglevel
指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为notice。
四个级别根据使用阶段来选择,生产环境选择notice 或者warning。
- logfile
日志文件的名称。
- databases 16
设定库的数量 默认16,默认数据库为0,可以使用SELECT 命令在连接上指定数据库id。
4、SECURITY安全
- requirepass foobared
访问密码的查看、设置和取消。永久设置,需要再配置文件中进行设置。
如果在命令中设置密码,只是临时的。重启redis服务器,密码就还原了。
5、LIMITS限制
- maxclients
Ø 设置redis同时可以与多少个客户端进行连接。
Ø 默认情况下为10000个客户端。
Ø 如果达到了此限制,redis则会拒绝新的连接请求,并且向这些连接请求方发出“max number of clients reached”以作回应。
- maxmemory
建议必须设置,否则,将内存占满,造成服务器宕机。
设置redis可以使用的内存量。一旦到达内存使用上限,redis将会试图移除内部数据,移除规则可以通过maxmemory-policy来指定。
如果redis无法根据移除规则来移除内存中的数据,或者设置了“不允许移除”,那么redis则会针对那些需要申请内存的指令返回错误信息,比如SET、LPUSH等。
但是对于不需要内存申请的指令,仍然会正常响应,比如GET等。如果redis是主redis(说明redis有从redis),那么在设置内存使用上限时,需要在系统中留出一些内存空间给同步队列缓存,只有在设置的是“不移除”的情况下,才不用考虑这个因素。
- maxmemory-policy
Ø volatile-lru:使用LRU算法移除key,只对设置了过期时间的键;(最近最少使用)
Ø allkeys-lru:在所有集合key中,使用LRU算法移除key
Ø volatile-random:在过期集合中移除随机的key,只对设置了过期时间的键
Ø allkeys-random:在所有集合key中,移除随机的key
Ø volatile-ttl:移除那些TTL值最小的key,即那些最近要过期的key
Ø noeviction:不进行移除。针对写操作,只是返回错误信息
- maxmemory-samples
设置样本数量,LRU算法和最小TTL算法都并非是精确的算法,而是估算值,所以可以设置样本的大小,redis默认会检查这么多个key并选择其中LRU的那个。
一般设置3到7的数字,数值越小样本越不准确,但性能消耗越小。
四、常用五大数据类型[核心]
redis常见数据类型操作命令:http://www.redis.cn/commands.html
五种常用数据类型对应的八种数据结构,每种数据类型至少对应两种编码方式,如下:
| 类型 | 编码常量 | 对象 | 编码所对应的底层数据结构 |
|---|---|---|---|
| REDIS_STRING | REDIS_ENCODING_INT | 使用整数值实现的字符串对象 | long 类型的整数 |
| REDIS_STRING | REDIS_ENCODING_EMBSTR embstr | 使用embstr编码的简单动态字符串实现的字符串对象 | 编码的简单动态字符串 |
| REDIS_STRING | REDIS_ENCODING_RAW | 使用简单动态字符串实现的字符串对象 | 简单动态字符串 |
| REDIS_LIST/REDIS_HASH/REDIS_ZSET | REDIS_ENCODING_ZIPLIST | 使用压缩队列实现的列表/哈希/有序集合对象 | 压缩列表 |
| REDIS_LIST | REDIS_ENCODING_LINKEDLIST | 使用双端链表实现的列表对象 | 双端链表 |
| REDIS_HASH/REDIS_SET | REDIS_ENCODING_HT | 使用字典实现的哈希/集合对象 | 字典[哈希表] |
| REDIS_SET | REDIS_ENCODING_INTSET | 使用整数集合实现的集合对象 | 整数集合 |
| REDIS_ZSET | REDIS_ENCODING_SKIPLIST | 使用跳跃表和字典实现的有序集合对象 | 跳跃表和字典 |
对象类型与底层数据结构之间的关系:

0、Redis Key
keys * 查看当前库所有key (匹配:keys *1)
exists key 判断某个key是否存在
type key 查看key是什么类型
del key 删除指定的key数据
unlink key 根据value选择非阻塞删除,仅将keys从keyspace元数据中删除,真正的删除会在后续异步操作。
expire key 10 10秒钟:为给定的key设置过期时间
ttl key 查看还有多少秒过期,-1表示永不过期,-2表示已过期
Select 命令切换数据库
dbsize 查看当前数据库的key的数量
flushdb 清空当前库
flushall 通杀全部库
1、string字符串
String是Redis最基本的类型,可以理解成与Memcached一模一样的类型,一个key对应一个value。
String类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以是512M。
set <key><value> 添加键值对
*NX:当数据库中key不存在时,可以将key-value添加数据库
*XX:当数据库中key存在时,可以将key-value添加数据库,与NX参数互斥
*EX:key的超时秒数
*PX:key的超时毫秒数,与EX互斥
get <key> 查询对应键值
append <key><value> 将给定的<value> 追加到原值的末尾
strlen <key> 获得值的长度
setnx <key><value> 只有在 key 不存在时 设置 key 的值
incr <key> 将 key 中储存的数字值进行原子性的增1;只能对数字值操作,如果为空,新增值为1
decr <key> 将 key 中储存的数字值进行原子性的减1;只能对数字值操作,如果为空,新增值为-1
incrby / decrby <key><步长> 将 key 中储存的数字值增减。自定义步长。
mset <key1><value1><key2><value2> ..... 同时设置一个或多个 key-value对
mget <key1><key2><key3> ..... 同时获取一个或多个 value
msetnx <key1><value1><key2><value2> ..... 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。
getrange <key><起始位置><结束位置> 获得值的范围,类似java中的substring
setrange <key><起始位置><value> 用 <value> 覆写<key>所储存的字符串值,从<起始位置>开始(索引从0开始)。
setex <key><过期时间><value> 设置键值的同时,设置过期时间,单位秒。
getset <key><value> 以新换旧,设置了新值同时获得旧值。
所谓原子操作是指不会被线程调度机制打断的操作。原子性,有一个失败则都失败。
这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程)。
(1)在单线程中, 能够在单条指令中完成的操作都可以认为是"原子操作",因为中断只能发生于指令之间。
(2)在多线程中,不能被其它进程(线程)打断的操作就叫原子操作。
Redis单命令的原子性主要得益于Redis的单线程。
1.1、string数据结构
String的数据结构为简单动态字符串(Simple Dynamic String,缩写SDS)。是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。

如图中所示,内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M。
1.2、string应用场景
- session会话共享
在分布式系统中,用户的每次请求会访问到不同的服务器,这就会导致session不同步的问题,为了解决这个问题,使用redis集中管理这些session,将session存入redis,使用的时候直接从redis中获取。
- 热点数据缓存
对于高并发场景,为了减少对数据库服务IO压力,Web端的热点请求可以从Redis中获取的数据,如果Redis中没有需要的数据,再从MySQL中去获取,并将获取到的数据写入Redis。
- 计数器
文章的阅读量,视频的播放量等等都会使用redis来计数,每播放一次,对应的播放量就会加1,同时将这些数据异步存储到数据库中达到持久化的目的。
为了安全考虑,有些网站会对IP进行限制,限制同一IP在一定时间内访问次数不能超过n次。
- 分布式锁
在分布式系统中,可以使用setnx完成分布式锁。
当setnx返回1时,表示获取锁,做完操作以后del key,表示释放锁;如果setnx返回0表示获取锁失败。
- 短信验证码
利用setex操作可以为数据设置过期时间, 从而完成短信验证码的需求。
2、list列表
Redis 列表是简单的字符串列表,单键多值。
lpush/rpush <key><value1><value2><value3> .... 从左边/右边插入一个或多个值。
lpop/rpop <key> 从左边/右边吐出一个值。值在键在,值亡键亡。
rpoplpush <key1><key2> 从<key1>列表右边吐出一个值,插到<key2>列表左边。
lrange <key><start><stop> 按照索引下标获得元素(从左到右)
lrange mylist 0 -1 0左边第一个,-1右边第一个,(0-1表示获取所有)
lindex <key><index> 按照索引下标获得元素(从左到右)
llen <key> 获得列表长度
linsert <key> before <value><newvalue> 在<value>的后面插入<newvalue>插入值
lrem <key><n><value> 从左边删除n个value(从左到右)
lset<key><index><value> 将列表key下标为index的值替换成value
2.1、list数据结构
Redis 列表是简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边)。
它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。

List的数据结构为快速链表ziplist→quickList。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。
它将所有的元素紧挨着一起存储,分配的是一块连续的内存。
当数据量比较多的时候才会改成quicklist。
因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。

Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
2.2、list应用场景
- 消息队列
因为列表的元素不但是有序的,而且还支持按照索引范围获取元素。因此我们可以使用命令lrange key 0 9分页获取文章列表。
redis应用场景相关链接:https://blog.csdn.net/CSDN2497242041/article/details/122530152
3、set集合
Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash table,所以添加,删除,查找的复杂度都是O(1)。 它对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的。
sadd <key><value1><value2> ..... 将一个或多个 member 元素加入到集合 key 中,已经存在的 member 元素将被忽略
smembers <key> 取出该集合的所有值。
sismember <key><value> 判断集合<key>是否为含有该<value>值,有1,没有0
scard <key> 返回该集合的元素个数。
srem <key><value1><value2> .... 删除集合中的某个元素。
spop <key> 随机从该集合中吐出一个值。
srandmember <key><n> 随机从该集合中取出n个值。不会从集合中删除 。
smove <source><destination>value 把集合中一个值从一个集合移动到另一个集合
sinter <key1><key2> 返回两个集合的交集元素。
sunion <key1><key2> 返回两个集合的并集元素。
sdiff <key1><key2> 返回两个集合的差集元素(key1中的,不包含key2中的)
3.1、set数据结构
Set数据结构是dict字典,字典是用哈希表实现的。
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
3.2、set应用场景
- 共同好友
比如把2个人的粉丝列表弄一个交集,就能看到两个人的共同好友是谁。
- 用户标签
例如一个用户对篮球、足球感兴趣,另一个用户对橄榄球、乒乓球感兴趣,这些兴趣点就是一个标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共同感兴趣的标签。给用户打标签的时候需要:①给用户打标签,②给标签加用户,需要给这两个操作增加事务。
- 抽奖功能
用户点击抽奖按钮,参数抽奖,将用户编号放入集合,然后抽奖,分别抽一等奖、二等奖,如果已经抽中一等奖的用户不能参数抽二等奖则使用spop,反之使用srandmember。
4、hash哈希
Redis hash 是一个键值对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
类似Java里面的Map<String,Object>
hset <key><field><value> 给<key>集合中的<field>键赋值<value>
hget <key1><field> 从<key1>集合<field>取出 value
hmset <key1><field1><value1><field2><value2>... 批量设置hash的值
hexists<key1><field> 查看哈希表 key 中,给定域 field 是否存在。
hkeys <key> 列出该hash集合的所有field
hvals <key> 列出该hash集合的所有value
hincrby <key><field><increment> 为哈希表 key 中的域 field 的值加上增量 1 -1
hsetnx <key><field><value> 将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在
4.1、hash数据结构
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。
4.2、hash应用场景
- 个人信息详情
使用哈希存储会比字符串更加方便直观 。比如: hset user:1 name 何哥 age 18
- 商品详情
5、Zset有序集合
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复的。
因为元素是有序的,所以也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
zadd <key><score1><value1><score2><value2>… 将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
zrange <key><start><stop> [WITHSCORES] 返回有序集 key 中,下标在<start><stop>之间的元素带WITHSCORES,可以让分数一起和值返回到结果集。
zrangebyscore key minmax [withscores] [limit offset count] 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
zrevrangebyscore key maxmin [withscores] [limit offset count] 同上,改为从大到小排列。
zincrby <key><increment><value> 为元素的score加上增量
zrem <key><value> 删除该集合下,指定值的元素
zcount <key><min><max> 统计该集合,分数区间内的元素个数
zrank <key><value> 返回该值在集合中的排名,从0开始。
5.1、Zset数据结构
Zset是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层使用了两种数据结构:
(1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
(2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
5.2、Zset应用场景
- topn类型排行榜
用户发布一篇文章a,初始点赞数为0,即score为0
zadd user:article 0 a
有人给文章a点赞,递增1
zincrby user:article 1 a
查询点赞前三篇文章
zrevrangebyscore user:article 0 2
查询点赞后三篇文章
zrangebyscore user:article 0 2
五、Redis新数据类型
1、Bitmaps
1.1、引入Bitmaps
合理地使用操作位能够有效地提高内存使用率和开发效率。
1.2、什么是Bitmaps
Redis提供了Bitmaps这个“数据类型”可以实现对位的操作:
(1)Bitmaps本身不是一种数据类型,实际上它就是字符串(k-v),但是它可以对字符串的位进行操作。
(2)Bitmaps单独提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。可以把Bitmaps想象成一个以位为单位的数组,数组的每个单元只能存储0和1,数组的下标在Bitmaps中叫做偏移量。
setbit <key> <offset> <value> 设置Bitmaps中某个偏移量的值(0或1),offset:偏移量从0开始
setbit unique:users:20220707 15 1 #[设置userid=15的用户在7月7号访问过网站]
#很多应用的用户id以一个指定数字(例如10000) 开头, 直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费, 通常的做法是每次做setbit操作时将用户id减去这个指定数字。
#在第一次初始化Bitmaps时, 假如偏移量非常大, 那么整个初始化过程执行会比较慢, 可能会造成Redis的阻塞。
getbit <key> <offset> 获取Bitmaps中某个偏移量的值
getbit unique:users:20220707 15 #[获取userid=15的用户在7月7号是否访问过网站]
# eg:获取id=8的用户是否在2020-11-06这天访问过, 返回0说明没有访问过。
bitcount <key> [start end] 统计字符串从start字节到end字节比特值为1的数量
bitcount unique:users:20220707 #[计算2022-07-07这天的独立访问用户数量]
bitcount unique:users:20220707 1 3 #[计算2022-07-07这天用户id早第1、3个字节的用户数量]
#注意:redis的setbit设置或清除的是bit位置,而bitcount计算的是byte位置。
bitop and(or/not/xor) <destkey> [key…]
#求多个Bitmaps的and(交集) 、 or(并集) 、 not(非) 、 xor(异或) 操作并将结果保存在destkey中
bitop and unique:users:and:20220707_08 unique:users:20220707 unique:users:20220708 #计算出7月7号和7月8号两天都访问过网站的用户数量,并保存到key→unique:users:and:20220707_08
bitop or unique:users:and:20220707_08 unique:users:20220707 unique:users:20220708
bitcount unique:users:and:20220707_08 #月活跃用户就是这么获取的
1.3、典型应用
假设网站有1亿用户, 每天独立访问的用户有5千万, 如果每天用集合类型和Bitmaps分别存储活跃用户可以得到表
| set和Bitmaps存储一天活跃用户对比 | |||
|---|---|---|---|
| 数据类型 | 每个用户id占用空间 | 需要存储的用户量 | 全部内存量 |
| 集合类型 | 64位 | 50000000 | 64位*50000000 = 400MB |
| Bitmaps | 1位 | 100000000 | 1位*100000000 = 12.5MB |
很明显, 这种情况下使用Bitmaps能节省很多的内存空间, 尤其是随着时间推移节省的内存还是非常可观的
| set和Bitmaps存储独立用户空间对比 | |||
|---|---|---|---|
| 数据类型 | 一天 | 一个月 | 一年 |
| 集合类型 | 400MB | 12GB | 144GB |
| Bitmaps | 12.5MB | 375MB | 4.5GB |
但Bitmaps并不是万金油, 假如该网站每天的独立访问用户很少, 例如只有10万(大量的僵尸用户) , 那么两者的对比如下表所示, 很显然, 这时候使用Bitmaps就不太合适了, 因为基本上大部分位都是0。
| set和Bitmaps存储一天活跃用户对比(独立用户比较少) | |||
|---|---|---|---|
| 数据类型 | 每个userid占用空间 | 需要存储的用户量 | 全部内存量 |
| 集合类型 | 64位 | 100000 | 64位*100000 = 800KB |
| Bitmaps | 1位 | 100000000 | 1位*100000000 = 12.5MB |
2、HyperLogLog
2.1、引入HyperLogLog
在工作当中,我们经常会遇到与统计相关的功能需求,比如统计网站PV(PageView页面访问量),可以使用Redis的incr、incrby轻松实现。
但像UV(UniqueVisitor,独立访客)、独立IP数、搜索记录数等需要去重和计数的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题。
解决基数问题有很多种方案:
(1)数据存储在MySQL表中,使用distinct count计算不重复个数
(2)使用Redis提供的hash、set、bitmaps等数据结构来处理
以上的方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。
能否能够降低一定的精度来平衡存储空间?Redis推出了HyperLogLog。
2.2、什么是HyperLogLog
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
2.3、典型应用
pfadd <key> <element> [element ...] #添加指定元素到 HyperLogLog 中
pfcount <key> [key ...] #计算key的近似基数,可以计算多个keyL,比如用key存储每天的UV,计算一周的UV可以使用7天的UV合并计算即可
pfmerge <destkey> <sourcekey> [sourcekey ...] #将一个或多个key合并后的结果存储在另一个key中,比如每月活跃用户可以使用每天的活跃用户来合并计算可得
3、Geospatial
3.1、引入Geospatial
Redis 3.2 中增加了对GEO类型的支持。
GEO,Geographic,地理信息的缩写。该类型,就是元素的2维坐标,在地图上就是经纬度。redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作。
3.2、什么是Geospatial
geoadd <key> <longitude><latitude><member> [longitude latitude member...] #添加地理位置(经度,纬度,名称)
geopos <key> <member> [member...] #获得指定地区的坐标值
geodist <key> <member1> <member2> [m|km|ft|mi ] #获取两个位置之间的直线距离
georadius <key> <longitude> <latitude> radius m|km|ft|mi #以给定的经纬度为中心,找出某一半径内的元素
3.3、典型应用
两极无法直接添加,一般会下载城市数据,直接通过 Java 程序一次性导入。
有效的经度从 -180 度到 180 度。有效的纬度从 -85.05112878 度到 85.05112878 度。
当坐标位置超出指定范围时,该命令将会返回一个错误。
已经添加的数据,是无法再次往里面添加的。
六、Redis发布与订阅
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。Redis 客户端可以订阅任意数量的频道。
1、命令行实现
- step1. 打开一个客户端订阅channeltest
SUBSCRIBE channeltest
执行上面命令客户端会进入订阅状态,处于此状态下客户端不能使用除subscribe、unsubscribe、psubscribe和punsubscribe这四个属于"发布/订阅"之外的命令,否则会报错。
psubscribe支持通配符订阅,eg:psubscribe test* d?mo
注:订阅是阻塞等待的
- step2. 打开另一个客户端,给channeltest发布消息hello
PUBLISH channeltest hello
会返回订阅者的数量。
- step3. 打开第一个客户端可以看到发送的消息
注:发布的消息没有持久化,客户端只能收到订阅后发布的消息。 如果出现网络断开、Redis 宕机等,消息就会被丢弃。
2、发布订阅对比list
1、list中的任务或消息无法被重复消费,消息被一个消费者pop 掉以后,其他消费者就获取不到了这个消息了。而发布/订阅模式中可以有多个订阅者消费同一个消息。
2、list可以保存任务或消息,直到客户端连接之后才消费掉。但发布/订阅模式中订阅者无法获取到订阅之前的历史消息,由于这个缺陷,在一些严格的生产消费场景下,建议还是用MQ的发布订阅模式。
3、Redis Stream
Redis Stream 是 Redis 从版本 5.0 新增加的数据结构。
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
Redis Stream 的结构如下所示, 每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。 它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容:
- Consumer Group :消费组,使用 XGROUP CREATE 命令创建,一个消费组有多个消费者(Consumer)。
- last_delivered_id :游标,每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
- pending_ids :消费者(Consumer)的状态变量,作用是维护消费者的未确认的 id。 pending_ids 记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)。

消息队列相关命令:
XADD - 添加消息到末尾
XTRIM - 对流进行修剪,限制长度
XDEL - 删除消息
XLEN - 获取流包含的元素数量,即消息长度
XRANGE - 获取消息列表,会自动过滤已经删除的消息
XREVRANGE - 反向获取消息列表,ID 从大到小
XREAD - 以阻塞或非阻塞方式获取消息列表
消费者组相关命令:
XGROUP CREATE - 创建消费者组
XREADGROUP GROUP - 读取消费者组中的消息
XACK - 将消息标记为"已处理"
XGROUP SETID - 为消费者组设置新的最后递送消息ID
XGROUP DELCONSUMER - 删除消费者
XGROUP DESTROY - 删除消费者组
XPENDING - 显示待处理消息的相关信息
XCLAIM - 转移消息的归属权
XINFO - 查看流和消费者组的相关信息;
XINFO GROUPS - 打印消费者组的信息;
XINFO STREAM - 打印流信息
4、发布订阅的应用
- Redis Sentinel模式
Redis Sentinel使用发布订阅模式,实现新节点的发现,以及交换主节点之间的状态。
Redis Sentinel(哨兵)是Redis官方推荐的一套高可用方案,在Redis主从同步的场景下,Redis Sentinel作为一个独立运行的进程,监控多个master-slave集群,当主节点故障的时候,自动将从节点提升为主节点,从而避免大面积瘫痪。
- Redission分布式锁
Redission开源框架提供了一些便捷的操作Redis的方法,其中比较出名的是基于Redis的分布式锁。
RLock redissonLock = redisson.getLock("xxxx");
redissonLock.lock();
RLock 继承自Java标准的Lock接口,调用lock()方法,就会判断xxxx这把锁是否被其他客户端获取到,如果是的话,就会线程阻塞并等待锁释放。
当获取锁失败后,线程就会订阅redission_lock_channel_xxxx (xxxx代表锁的名称)通道,使用异步线程监听消息,然后利用Java中的SemaPhore使当前线程进入阻塞。
当锁被释放的时候,redission就会向redission_lock_channel_xxxx 这个通道中发布解锁的通知,异步线程收到消息,就会调用SemaPhore释放信号量,从而唤醒当前阻塞的线程去抢占锁。
边栏推荐
- PHP obtains some values in the string according to the specified characters, and reorganizes the remaining strings into a new array
- Typora installation (no need to enter serial number)
- 460. LFU 缓存 双向链表
- Cube magique infini "simple"
- PHP gets CPU usage, hard disk usage, and memory usage
- JS determines whether the mobile terminal or the PC terminal
- [paper translation] gcnet: non local networks meet squeeze exception networks and beyond
- Spark概述
- Some experience of exercise and fitness
- PHP 开发与测试 Webservice(SOAP)-Win
猜你喜欢

Minimum value ruler method for the length of continuous subsequences whose sum is not less than s

“简单”的无限魔方

5g market trend in 2020

With an amount of $50billion, amd completed the acquisition of Xilinx
文件包含漏洞(一)

15 C language advanced dynamic memory management

2022-2-14 learning xiangniuke project - Section 7 account setting

A collection of commonly used plug-ins for idea development tools

脑与认知神经科学Matlab Psytoolbox认知科学实验设计——实验设计四

RGB 无限立方体(高级版)
随机推荐
Common protocols and download paths of NR
ThreadLocal memory leak
PHP array to XML
c语言中的几个关键字
mock-用mockjs模拟后台返回数据
如何写出好代码 — 防御式编程指南
Cambrian was reduced by Paleozoic venture capital and Zhike shengxun: a total of more than 700million cash
Practice C language advanced address book design
The Hong Kong Stock Exchange learned from US stocks and pushed spac: the follow-up of many PE companies could not hide the embarrassment of the world's worst stock market
[golang syntax] be careful with the copy of slices
Here comes a new chapter in the series of data conversion when exporting with easyexcel!
File contains vulnerabilities (II)
Zzuli: maximum Convention and minimum common multiple
Appnuim environment configuration and basic knowledge
Zzuli:1061 sequential output of digits
Cube magique infini "simple"
[leetcode] day92 container with the most water
Fundamentals of software testing
Addchild() and addattribute() functions in PHP
Software testing learning - day 4