当前位置:网站首页>《CGNF: CONDITIONAL GRAPH NEURAL FIELDS》阅读笔记
《CGNF: CONDITIONAL GRAPH NEURAL FIELDS》阅读笔记
2022-07-02 05:33:00 【斯曦巍峨】
一.文章概述
在大多数GNNs中,并没有考虑节点标签间的依赖性。为此,作者将条件随机场(Conditional Random Fields, CRF)和图卷积网络整合在一起提出了CGNF(Conditional Graph Neural Network),该模型显式地建模了整个节点标签集的联合概率,从而在节点标签预测任务中能够利用邻域标签信息。
二.背景知识
2.1 图卷积网络
GCN中图卷积层的数学形式如下:
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) \boldsymbol{H}^{(l+1)}=\sigma\left(\tilde{\boldsymbol{D}}^{-\frac{1}{2}} \tilde{\boldsymbol{A}} \tilde{\boldsymbol{D}}^{-\frac{1}{2}} \boldsymbol{H}^{(l)} \boldsymbol{W}^{(l)}\right) H(l+1)=σ(D~−21A~D~−21H(l)W(l))
其中 A ~ = A + I \tilde{A}=\boldsymbol{A}+\boldsymbol{I} A~=A+I表示添加了自环的邻接矩阵, D ~ \tilde{D} D~是 A ~ \tilde{A} A~对应的度矩阵(对角阵), H ( l ) \boldsymbol{H}^{(l)} H(l)表示第 l l l层的节点表示, W ( l ) \boldsymbol{W}^{(l)} W(l)表示第 l l l层的权重矩阵, σ \sigma σ表示激活函数,常用的为ReLU。
2.2 条件随机场
条件随机场(CRF)是一种无向概率图模型,通常用于结构预测任务。给定输入特征 x ∈ R d x \in \mathbb{R}^{d} x∈Rd,CRF旨在找到最大化条件概率 P ( y ∣ x ) P(\boldsymbol{y} \mid \boldsymbol{x}) P(y∣x)的标签集 y \boldsymbol{y} y。在无向图上,CRF计算联合概率分布的方式是因子分解,即:
P ( y ∣ x ) = 1 Z ( x ) ∏ c Φ a ( x c , y c ) P(\boldsymbol{y} \mid \boldsymbol{x})=\frac{1}{Z(\boldsymbol{x})} \prod_{c} \Phi_{a}\left(\boldsymbol{x}_{c}, \boldsymbol{y}_{c}\right) P(y∣x)=Z(x)1c∏Φa(xc,yc)
其中 c c c表示图中的团, x c \boldsymbol{x}_{c} xc表示团 c c c中所有顶点对应的特征, Φ c \Phi_{c} Φc表示势函数, Z ( x ) = ∑ y c ′ ∏ c Φ a ( x c , y c ′ ) Z(\boldsymbol{x})=\sum_{\boldsymbol{y}_{c}^{\prime}} \prod_{c} \Phi_{a}\left(\boldsymbol{x}_{c}, \boldsymbol{y}_{c}^{\prime}\right) Z(x)=∑yc′∏cΦa(xc,yc′)表示归一化因子(用来保证计算出的概率值是合法的)。
团指的是所有顶点都有边连接的子图。
三.CGNF详细介绍
首先给出符号表以方便后续介绍:
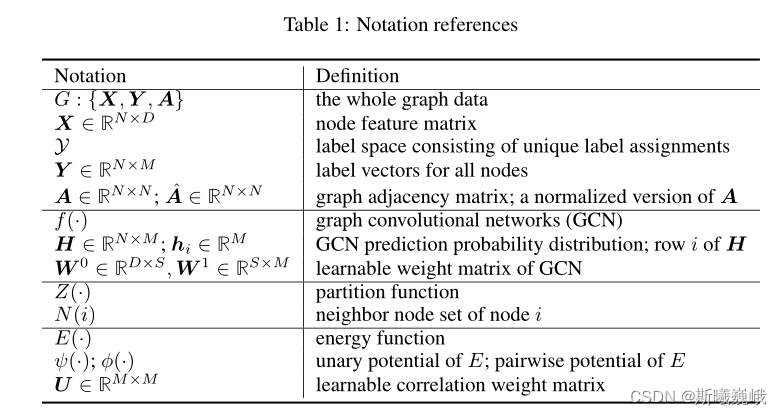
3.1 训练
CGNF的第一步是将输入图 G = { X , Y , A } G=\{\boldsymbol{X}, \boldsymbol{Y}, \boldsymbol{A}\} G={ X,Y,A}过一下Kipf和Welling提出来的2层GCN模型,即:
H = f ( X , A ) = Softmax ( A ^ ReLu ( A ^ X W 0 ) W 1 ) \boldsymbol{H}=f(\boldsymbol{X}, \boldsymbol{A})=\operatorname{Softmax}\left(\hat{\boldsymbol{A}} \operatorname{ReLu}\left(\hat{\boldsymbol{A}} \boldsymbol{X} \boldsymbol{W}^{0}\right) \boldsymbol{W}^{1}\right) H=f(X,A)=Softmax(A^ReLu(A^XW0)W1)
随后,作者考虑节点特征和标签依赖性的影响,定义能量函数(energy function)如下:
E ( Y , X , A ) = E c ( Y c , X c , A ) = ∑ i ψ ( y i , x i ) + γ ∑ ( i , j ) ∈ E , i < j ϕ ( y i , y j , A i , j ) E(\boldsymbol{Y}, \boldsymbol{X}, \boldsymbol{A})=E_{c}\left(\boldsymbol{Y}_{c}, \boldsymbol{X}_{c}, \boldsymbol{A}\right)=\sum_{i} \psi\left(\boldsymbol{y}_{i}, \boldsymbol{x}_{i}\right)+\gamma \sum_{(i, j) \in \mathcal{E}, i<j} \phi\left(\boldsymbol{y}_{i}, \boldsymbol{y}_{j}, A_{i, j}\right) E(Y,X,A)=Ec(Yc,Xc,A)=i∑ψ(yi,xi)+γ(i,j)∈E,i<j∑ϕ(yi,yj,Ai,j)
其中 c c c表示团, E \mathcal{E} E表示边集, ψ ( ⋅ ) \psi(\cdot) ψ(⋅)为一元势函数(用来策略观测节点 x i x_i xi与标签 y i y_i yi间的相容性compatibility,即观测值为 x i x_i xi时属于 y i y_i yi类的概率),成对势函数 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 用于捕捉标签相关性。基于该能量函数,可以导出Gibbs分布:
P ( Y ∣ X , A ) = exp ( − E ( Y , X , A ) ) ∑ Y ′ ∈ Y exp ( − E ( Y ′ , X , A ) ) = exp ( − E ( Y , X , A ) ) Z ( X , A ) P(\boldsymbol{Y} \mid \boldsymbol{X}, \boldsymbol{A})=\frac{\exp (-E(\boldsymbol{Y}, \boldsymbol{X}, \boldsymbol{A}))}{\sum_{\boldsymbol{Y}^{\prime} \in \mathcal{Y}} \exp \left(-E\left(\boldsymbol{Y}^{\prime}, \boldsymbol{X}, \boldsymbol{A}\right)\right)}=\frac{\exp (-E(\boldsymbol{Y}, \boldsymbol{X}, \boldsymbol{A}))}{Z(\boldsymbol{X}, \boldsymbol{A})} P(Y∣X,A)=∑Y′∈Yexp(−E(Y′,X,A))exp(−E(Y,X,A))=Z(X,A)exp(−E(Y,X,A))
作者的目标便是最大化该条件概率,即:
E ( Y , X , A ) = ∑ i ψ ( y i , h i ) + γ ∑ ( i , j ) ∈ E , i < j ϕ ( y i , y j , A ^ i , j ) = ∑ i ( ψ ( y i , h i ) + γ 2 ∑ j ∈ N ( i ) ϕ ( y i , y j , A ^ i , j ) ) \begin{aligned} E(\boldsymbol{Y}, \boldsymbol{X}, \boldsymbol{A}) &=\sum_{i} \psi\left(\boldsymbol{y}_{i}, \boldsymbol{h}_{\boldsymbol{i}}\right)+\gamma \sum_{(i, j) \in \mathcal{E}, i<j} \phi\left(\boldsymbol{y}_{i}, \boldsymbol{y}_{j}, \hat{A}_{i, j}\right) \\ &=\sum_{i}\left(\psi\left(\boldsymbol{y}_{i}, \boldsymbol{h}_{i}\right)+\frac{\gamma}{2} \sum_{j \in N(i)} \phi\left(\boldsymbol{y}_{i}, \boldsymbol{y}_{j}, \hat{A}_{i, j}\right)\right) \end{aligned} E(Y,X,A)=i∑ψ(yi,hi)+γ(i,j)∈E,i<j∑ϕ(yi,yj,A^i,j)=i∑⎝⎛ψ(yi,hi)+2γj∈N(i)∑ϕ(yi,yj,A^i,j)⎠⎞
其中 h i h_i hi是通过2层GCN模型获取到的节点表示, A ^ i , j \hat{A}_{i, j} A^i,j是正则化后的邻接矩阵中的原始, N ( i ) N(i) N(i)是节点 i i i的邻域。两个势函数的计算公式如下:
ψ ( y i , h i ) = − log p ( y i ∣ h i ) = − ∑ k y i , k log h i , k ϕ ( y i , y j , A ^ i , j ) = − 2 A ^ i , j U y i , y j \begin{aligned} \psi\left(\boldsymbol{y}_{i}, \boldsymbol{h}_{i}\right) &=-\log p\left(\boldsymbol{y}_{i} \mid \boldsymbol{h}_{i}\right)=-\sum_{k} y_{i, k} \log h_{i, k} \\ \phi\left(\boldsymbol{y}_{i}, \boldsymbol{y}_{j}, \hat{A}_{i, j}\right) &=-2 \hat{A}_{i, j} U_{y_{i}, y_{j}} \end{aligned} ψ(yi,hi)ϕ(yi,yj,A^i,j)=−logp(yi∣hi)=−k∑yi,kloghi,k=−2A^i,jUyi,yj
从上述公式可以看出 ψ ( y i , h i ) \psi\left(\boldsymbol{y}_{i}, \boldsymbol{h}_{i}\right) ψ(yi,hi)实际就是交叉熵, U y i , y j ∈ U U_{y_{i}, y_{j}} \in \boldsymbol{U} Uyi,yj∈U 是标签 y i y_i yi和 y j y_j yj之间可学习的相关性权重。采用类似传统CRF的做法,作者使用负对数似然来作为训练的目标函数:
− log P ( Y ∣ X , A ) = E ( Y , X , A ) + log Z ( X , A ) = E ( Y , X , A ) + log ∑ Y ′ exp ( − E ( Y ′ , X , A ) ) \begin{aligned} -\log P(\boldsymbol{Y} \mid \boldsymbol{X}, \boldsymbol{A}) &=E(\boldsymbol{Y}, \boldsymbol{X}, \boldsymbol{A})+\log Z(\boldsymbol{X}, \boldsymbol{A}) \\ &=E(\boldsymbol{Y}, \boldsymbol{X}, \boldsymbol{A})+\log \sum_{\boldsymbol{Y}^{\prime}} \exp \left(-E\left(\boldsymbol{Y}^{\prime}, \boldsymbol{X}, \boldsymbol{A}\right)\right) \end{aligned} −logP(Y∣X,A)=E(Y,X,A)+logZ(X,A)=E(Y,X,A)+logY′∑exp(−E(Y′,X,A))
在推断(inference)的时候,只需 min Y E ( Y , X , A ) \min _{\boldsymbol{Y}} E(\boldsymbol{Y}, \boldsymbol{X}, \boldsymbol{A}) minYE(Y,X,A)即可。但比上述训练目标优化比较困难,为此作者采用伪似然来对其进行近似:
P ( Y ∣ X , A ) ≈ P L ( Y ∣ X , A ) = ∏ i P ( y i ∣ y N ( i ) , X , A ) P(\boldsymbol{Y} \mid \boldsymbol{X}, \boldsymbol{A}) \approx P L(\boldsymbol{Y} \mid \boldsymbol{X}, \boldsymbol{A})=\prod_{i} P\left(\boldsymbol{y}_{i} \mid \boldsymbol{y}_{N(i)}, \boldsymbol{X}, \boldsymbol{A}\right) P(Y∣X,A)≈PL(Y∣X,A)=i∏P(yi∣yN(i),X,A)
其中:
P ( y i ∣ y N ( i ) , X , A ) = exp ( − ψ ( y i , h i ) − γ ∑ j ∈ N ( i ) ϕ ( y i , y j , A ^ i , j ) ∑ y i ′ ( exp ( − ψ ( y i ′ , h i ) − γ ∑ j ∈ N ( i ) ϕ ( y i ′ , y j , A ^ i , j ) ) = exp ( − log p ( y i ∣ h i ) − 2 γ ∑ j ∈ N ( i ) A ^ i , j U y i , y j ∑ y i ′ ( exp ( − log p ( y i ′ ∣ h i ) − 2 γ ∑ j ∈ N ( i ) A ^ i , j U y i ′ , y j ) \begin{aligned} P\left(\boldsymbol{y}_{i} \mid \boldsymbol{y}_{N(i)}, \boldsymbol{X}, \boldsymbol{A}\right) &=\frac{\exp \left(-\psi\left(\boldsymbol{y}_{i}, \boldsymbol{h}_{\boldsymbol{i}}\right)-\gamma \sum_{j \in N(i)} \phi\left(\boldsymbol{y}_{i}, \boldsymbol{y}_{j}, \hat{A}_{i, j}\right)\right.}{\sum_{\boldsymbol{y}_{i}^{\prime}}\left(\exp \left(-\psi\left(\boldsymbol{y}_{i}^{\prime}, \boldsymbol{h}_{\boldsymbol{i}}\right)-\gamma \sum_{j \in N(i)} \phi\left(\boldsymbol{y}_{i}^{\prime}, \boldsymbol{y}_{j}, \hat{A}_{i, j}\right)\right)\right.} \\ &=\frac{\exp \left(-\log p\left(\boldsymbol{y}_{i} \mid \boldsymbol{h}_{\boldsymbol{i}}\right)-2 \gamma \sum_{j \in N(i)} \hat{A}_{i, j} U_{y_{i}, y_{j}}\right.}{\sum_{\boldsymbol{y}_{i}^{\prime}}\left(\exp \left(-\log p\left(\boldsymbol{y}_{i}^{\prime} \mid \boldsymbol{h}_{\boldsymbol{i}}\right)-2 \gamma \sum_{j \in N(i)} \hat{A}_{i, j} U_{y_{i}^{\prime}, y_{j}}\right)\right.} \end{aligned} P(yi∣yN(i),X,A)=∑yi′(exp(−ψ(yi′,hi)−γ∑j∈N(i)ϕ(yi′,yj,A^i,j))exp(−ψ(yi,hi)−γ∑j∈N(i)ϕ(yi,yj,A^i,j)=∑yi′(exp(−logp(yi′∣hi)−2γ∑j∈N(i)A^i,jUyi′,yj)exp(−logp(yi∣hi)−2γ∑j∈N(i)A^i,jUyi,yj
y i ′ \boldsymbol{y}_{i}^{\prime} yi′是节点 x i \boldsymbol{x}_{i} xi的所有可能标签。因此,新的训练目标为:
− log P L ( Y ∣ X , A ) = ∑ i − log P ( y i ∣ y N ( i ) , X , A ) = ∑ i ( ψ ( y i , h i ) + γ ∑ j ∈ N ( i ) ϕ ( y i , y j , A ^ i , j ) + log ∑ y i ′ ( exp ( − ψ ( y i ′ , h i ) − γ ∑ j ∈ N ( i ) ϕ ( y i ′ , y j , A ^ i , j ) ) ) = − ∑ i , k ( Y ⊙ log H ) i , k − 2 γ ∑ i , j , i ≠ j ( A ^ ⊙ ( Y U Y T ) ) i , j + ∑ i log ∑ k ( H ⊙ exp ( 2 γ A ^ Y U ) ) i , k \begin{aligned} &-\log P L(\boldsymbol{Y} \mid \boldsymbol{X}, \boldsymbol{A})=\sum_{i}-\log P\left(\boldsymbol{y}_{i} \mid \boldsymbol{y}_{N(i)}, \boldsymbol{X}, \boldsymbol{A}\right)= \\ &\sum_{i}\left(\psi\left(\boldsymbol{y}_{i}, \boldsymbol{h}_{i}\right)+\gamma \sum_{j \in N(i)} \phi\left(\boldsymbol{y}_{i}, \boldsymbol{y}_{j}, \hat{A}_{i, j}\right)+\log \sum_{\boldsymbol{y}_{i}^{\prime}}\left(\exp \left(-\psi\left(\boldsymbol{y}_{i}^{\prime}, \boldsymbol{h}_{\boldsymbol{i}}\right)-\gamma \sum_{j \in N(i)} \phi\left(\boldsymbol{y}_{i}^{\prime}, \boldsymbol{y}_{j}, \hat{A}_{i, j}\right)\right)\right)\right. \\ &=-\sum_{i, k}(\boldsymbol{Y} \odot \log \boldsymbol{H})_{i, k}-2 \gamma \sum_{i, j, i \neq j}\left(\hat{\boldsymbol{A}} \odot\left(\boldsymbol{Y} \boldsymbol{U} \boldsymbol{Y}^{T}\right)\right)_{i, j}+\sum_{i} \log \sum_{k}(\boldsymbol{H} \odot \exp (2 \gamma \hat{\boldsymbol{A}} \boldsymbol{Y} \boldsymbol{U}))_{i, k} \end{aligned} −logPL(Y∣X,A)=i∑−logP(yi∣yN(i),X,A)=i∑⎝⎛ψ(yi,hi)+γj∈N(i)∑ϕ(yi,yj,A^i,j)+logyi′∑⎝⎛exp⎝⎛−ψ(yi′,hi)−γj∈N(i)∑ϕ(yi′,yj,A^i,j)⎠⎞⎠⎞=−i,k∑(Y⊙logH)i,k−2γi,j,i=j∑(A^⊙(YUYT))i,j+i∑logk∑(H⊙exp(2γA^YU))i,k
⊙ \odot ⊙ 表示逐元素乘法。
3.2 推断
如前文介绍的,在推断的时候仅需优化如下目标:
min Y ^ t e E ( Y ^ t e , X , A , Y t r ) = min Y ^ t e [ − log p ( Y ^ t e ∣ H ) − γ ∑ i ≠ j ( A ^ ⊙ ( Y ^ U Y ^ T ) ) i , j ] \min _{\hat{\boldsymbol{Y}}_{t e}} E\left(\hat{\boldsymbol{Y}}_{t e}, \boldsymbol{X}, \boldsymbol{A}, \boldsymbol{Y}_{t r}\right)=\min _{\hat{\boldsymbol{Y}}_{t e}}\left[-\log p\left(\hat{\boldsymbol{Y}}_{t e} \mid \boldsymbol{H}\right)-\gamma \sum_{i \neq j}\left(\hat{\boldsymbol{A}} \odot\left(\hat{\boldsymbol{Y}} \boldsymbol{U} \hat{\boldsymbol{Y}}^{T}\right)\right)_{i, j}\right] Y^teminE(Y^te,X,A,Ytr)=Y^temin⎣⎡−logp(Y^te∣H)−γi=j∑(A^⊙(Y^UY^T))i,j⎦⎤
其中 Y ^ = \hat{\boldsymbol{Y}}= Y^= concatenate ( Y t r , Y ^ t e ) \left(\boldsymbol{Y}_{t r}, \hat{\boldsymbol{Y}}_{t e}\right) (Ytr,Y^te)。作者在论文中提到了两种推断方法。
3.2.1 推断方法一
最简单的推断方法是不考虑标签间的相关性,即:
y i = arg min y j E ( y i , Y t r , X , A ) = arg min j [ − log ( h i ) − 2 γ A ^ t r Y U T ] j y_{i}=\underset{y_{j}}{\arg \min } E\left(\boldsymbol{y}_{i}, \boldsymbol{Y}_{t r}, \boldsymbol{X}, \boldsymbol{A}\right)=\underset{j}{\arg \min }\left[-\log \left(\boldsymbol{h}_{i}\right)-2 \gamma \hat{\boldsymbol{A}}_{t r} \boldsymbol{Y} \boldsymbol{U}^{T}\right]_{j} yi=yjargminE(yi,Ytr,X,A)=jargmin[−log(hi)−2γA^trYUT]j
3.2.2 推断方法二
第二种方案是使用动态规划方法来寻找最优值。该方法会随机选择一个测试节点作为开始,并随机排序其它测试节点,然后沿着排序测试节点的顺序进行beam search(beam大小为 K K K,即每次可以得到 K K K个最佳集)。将该过程重复 T T T词,然后选择所有搜索结果中的最佳结果,算法总结如下:

四.实验
作者在Cora、Pubmed、Citeseer和PPI四个数据集上进行实验,且较其它baseline取得了比较好的性能,对应结果如下:

结语
参考资料:
边栏推荐
- Nodejs (02) - built in module
- Technologists talk about open source: This is not just using love to generate electricity
- Disable access to external entities in XML parsing
- 【pyinstaller】_get_sysconfigdata_name() missing 1 required positional argument: ‘check_exists‘
- Importation de studio visuel
- 生成二维码
- Determine whether there is an element in the string type
- Pytorch Basics
- 5g market trend in 2020
- Fabric.js 自由绘制矩形
猜你喜欢
2022-2-14 learning xiangniuke project - Section 6 displays login information
Gee data set: export the distribution and installed capacity of hydropower stations in the country to CSV table

Using QA band and bit mask in Google Earth engine

GRBL 软件:简单解释的基础知识

Technologists talk about open source: This is not just using love to generate electricity

RNN recurrent neural network

Fabric. JS gradient

Visual Studio導入

Huawei Hongmeng OS, is it OK?

Cube magique infini "simple"
随机推荐
软件测试答疑篇
Fabric. JS iText superscript and subscript
生成二维码
Reflection of the soul of the frame (important knowledge)
Database batch insert data
Fabric.js 渐变
Online English teaching app open source platform (customized)
Global and Chinese markets of semiconductor laser therapeutics 2022-2028: Research Report on technology, participants, trends, market size and share
Ls1046nfs mount file system
Appnuim environment configuration and basic knowledge
Thunder on the ground! Another domestic 5g chip comes out: surpass Huawei and lead the world in performance?
Pytorch Chinese document
Usage record of vector
线程池批量处理数据
Taskbar explicit / implicit toggle function
idea开发工具常用的插件合集汇总
Gee: explore the change of water area in the North Canal basin over the past 30 years [year by year]
视差特效的原理和实现方法
Two implementation methods of delay queue
ubuntu20.04安装mysql8