当前位置:网站首页>Youth training camp -- database operation project
Youth training camp -- database operation project
2022-07-02 05:20:00 【Where's huluwa's father】
Time : 5 month 28 Japan 16:00
Course link :https://live.juejin.cn/4354/yc_teacher-hands/preload
PPT: nothing
Learning manual :https://juejin.cn/post/7101135488974585870#heading-21
After class questions :https://juejin.cn/post/7102399708902981663/
Project address :https://github.com/thuyy/ByteYoungDB
:::
Background knowledge ( Study the contents of the manual )
Storage & database
The storage system
- Block storage : Store the underlying system in the software stack , The interface is too simple
- File store : The most widely used storage system , The interface is very friendly , Realize various
- Object storage : Trump products on the public cloud ,immutable Semantic blessing
- key-value Storage : The most flexible form , There are a lot of open source / Black box products
Database system
- Relational type : Based on relation and relational algebra , General support services and SQL visit , Use experience friendly storage products
- Non relational : Flexible structure , Flexible access , There are different targeted products for different scenarios
Distributed architecture
- Data distribution strategy : Determines how data is distributed to multiple physical nodes of the cluster , Is it even , Whether to achieve high performance
- Data replication protocol : influence IO Path performance 、 How to deal with machine failure scenarios
- Distributed transaction algorithm : Multiple database nodes work together to ensure the security of a transaction ACID Characteristic algorithm , Usually based on 2pc The idea of design
2pc: Two-phase commit , The first stage is the voting stage , The second stage is submission / Execution phase . In the first stage, the coordinator sends a transaction preprocessing request to all participants , Participants implement , Return to coordinator yes/no, If it's all yes be commit, If there is one or more no Or there are timeout uncommitted , be rollback
database structure
You can review MySQL 45. The first section , Note links :https://www.yuque.com/shenjingwa-ev2rj/wfwfwb/xbe3h6
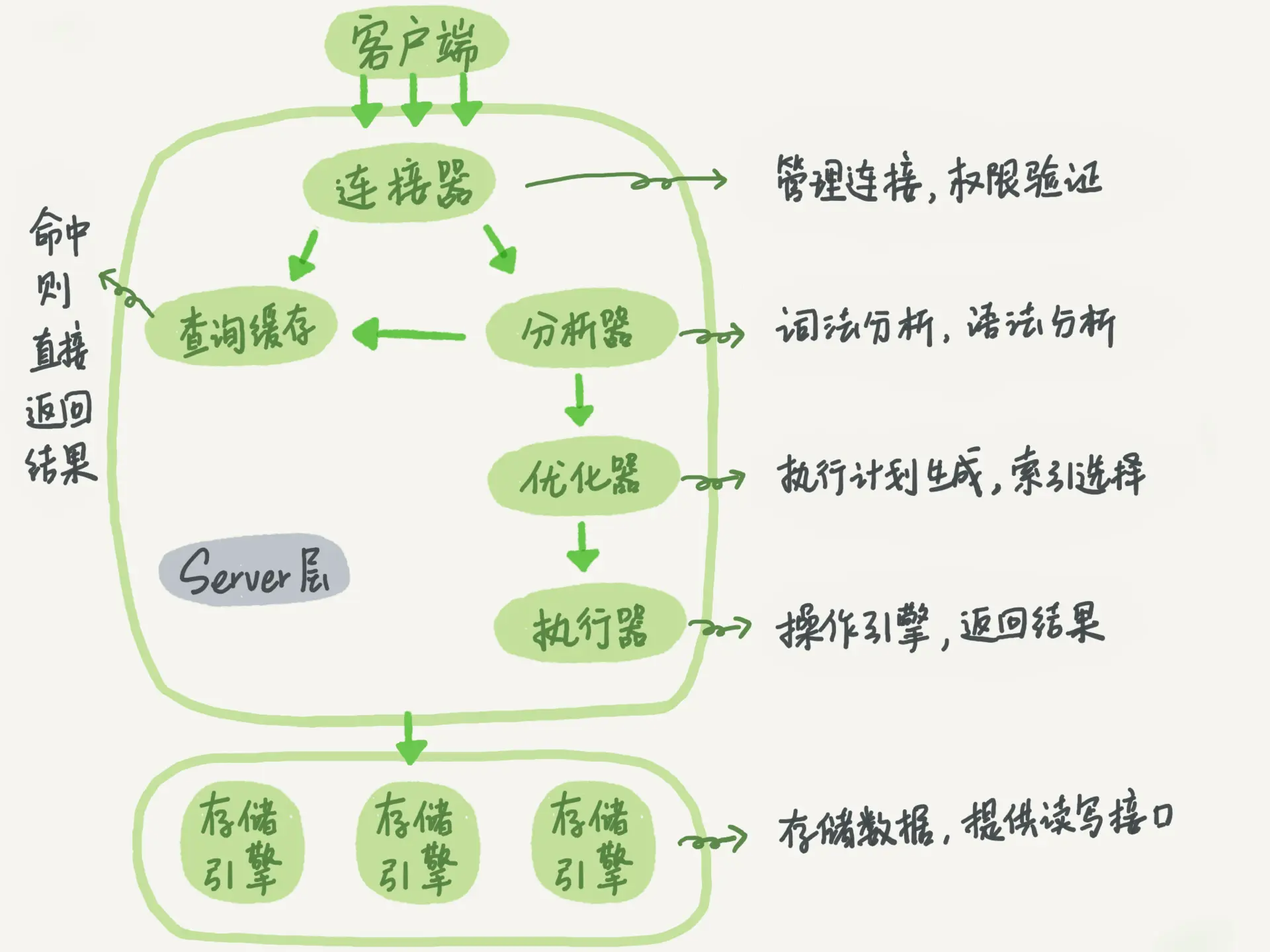

- SQL engine
- Parser: Query resolution , Generate syntax tree , And verify the legitimacy ( Lexical analysis 、 Syntax analysis 、 Semantic analysis )
- Optimizer: Select the optimal execution path according to the syntax tree
- Executor: Query execution process , Real data processing
- Transaction engine
- Implementation of transactions ACID
- Storage engine
- Store the data 、 Indexes 、 journal
- Store the data 、 Indexes 、 journal
Project requirement
Implement a memory database ByteYoungDB, It can support the following operations :
- Create/Drop Table
- Insert、Delete、Update、Select(CRUD)
- Simple equivalent matching conditions
where col = XXX - Support simple transactions Commit,Rollback
Project design
Project breakdown
- Parse user input SQL sentence , And verify the legitimacy ( Lexical analysis 、 Syntax analysis 、 Semantic analysis ):Parser
- User created tables 、 Management of column and other meta information :MetaData
- according to SQL Syntax tree of statements , Generate plan tree :Optimizer
- Query and execute according to the plan tree , Choose here Models of volcanoes :Executor
Volcanic model abstracts every operation in relational algebra into a Operator, Will the whole SQL Build into a Operator Trees , Top down call of query tree next() Interface , Data is pulled from the bottom up .
- Memory data storage structure design :Storage
- Commot/Rollback Transaction support :Transaction
Project file structure :
SQL Engine design
Parser
SQL Language parsing is very complicated , So here “ lazy ”, Go to github Looking for an open source SQL Parser .https://github.com/hyrise/sql-parser
Input is SQL sentence , The output is a syntax tree :
but sql-parser The library can only provide lexical analysis and grammatical analysis , Generate a query tree , Semantic analysis is not possible , That is, validity verification . So we will sql-parser Libraries to encapsulate , Add semantic analysis function :
bool Parser::parseStatement(std::string query) {
result_ = new SQLParserResult;
SQLParser::parse(query, result_);
if (result_->isValid()) {
return checkStmtsMeta();
} else {
std::cout << "[BYDB-Error] Failed to parse sql statement." << std::endl;
}
return true;
}
Optimizer
According to the generated query tree , Generate the corresponding plan tree . The plan tree is composed of various basic operators , For the scenarios required in this project , The following basic operators are constructed :
Like one UPDATE Inquire about , The corresponding plan tree is as follows :( The project has not been realized index)
Executor
Use volcanic models :
Rely on the plan tree to generate the corresponding execution tree , Every Plan Generate a corresponding Operator.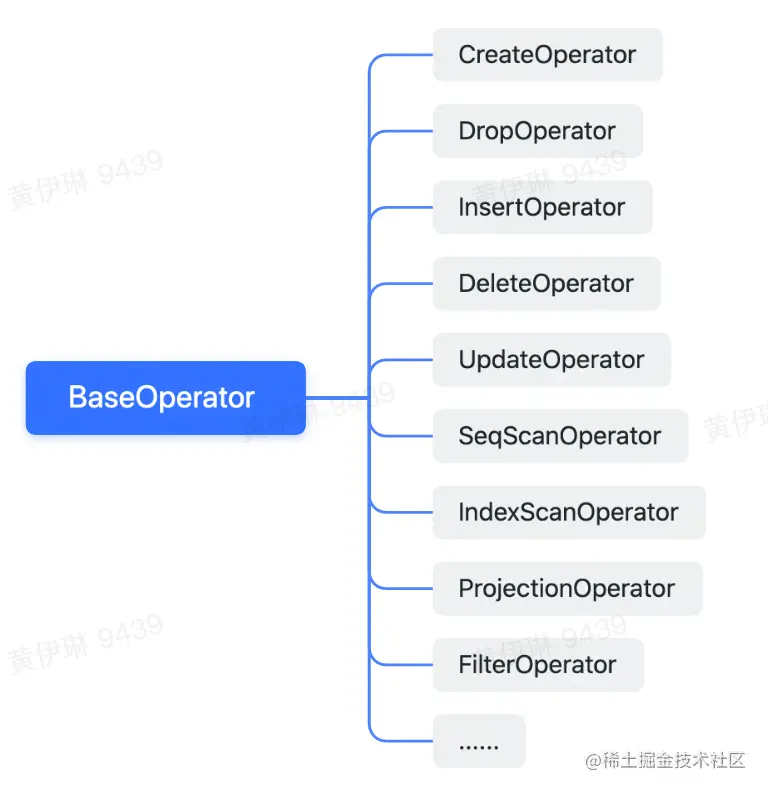
Every Operator call next_.exec() To call the lower layer Operator Generate data :
class BaseOperator {
public:
BaseOperator(Plan* plan, BaseOperator* next) : plan_(plan), next_(next) {
}
~BaseOperator() {
}
virtual bool exec() = 0;
Plan* plan_;
BaseOperator* next_;
};
Storage engine
data structure
Because we are a memory database , So the data structure can be designed simply . Here, a batch of recorded memory is applied for each time , This can reduce the problem of memory fragmentation , Improve memory access efficiency . Then put the memory of this batch of records into FreeList in . When data is inserted , from FreeList Get a piece of memory for writing , And put in DataList. When data is deleted , Take data from DataList Return to FreeList in .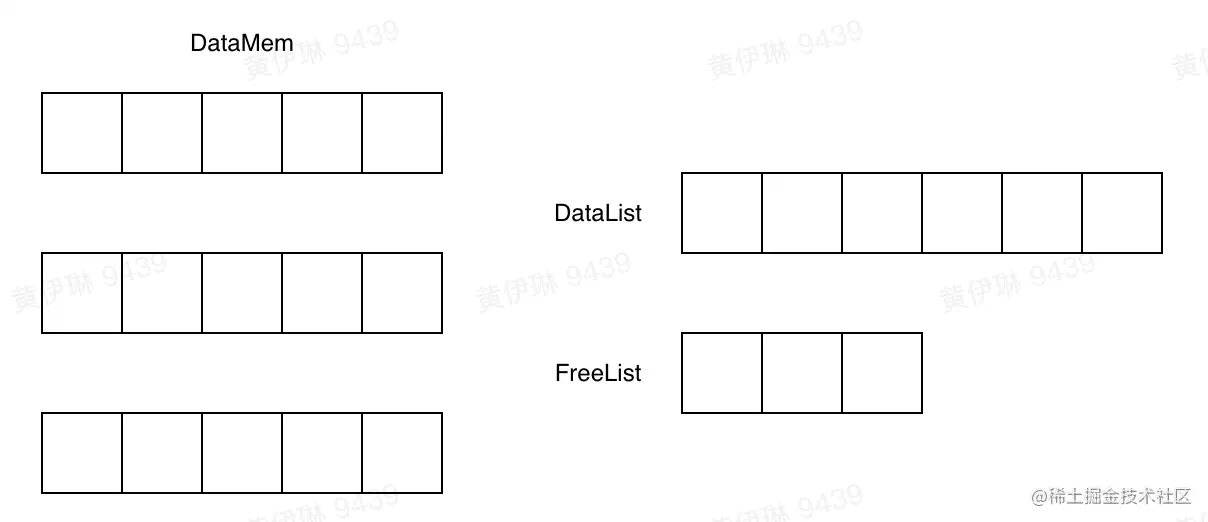
Transaction engine
Without considering concurrency , And the data does not need to be persistent , Our transaction engine design becomes relatively simple . Therefore, there is no need to implement complex MVCC Mechanism , Only need to be able to implement transactions Commit and Rollback Function can be .
Here we implement a undo stack The mechanism of , Update one row of data each time , Just take the old version of this line of data push To undo stack in . If the transaction rolls back , Then from undo stack The old version of the data one by one pop come out , Restore to the original data .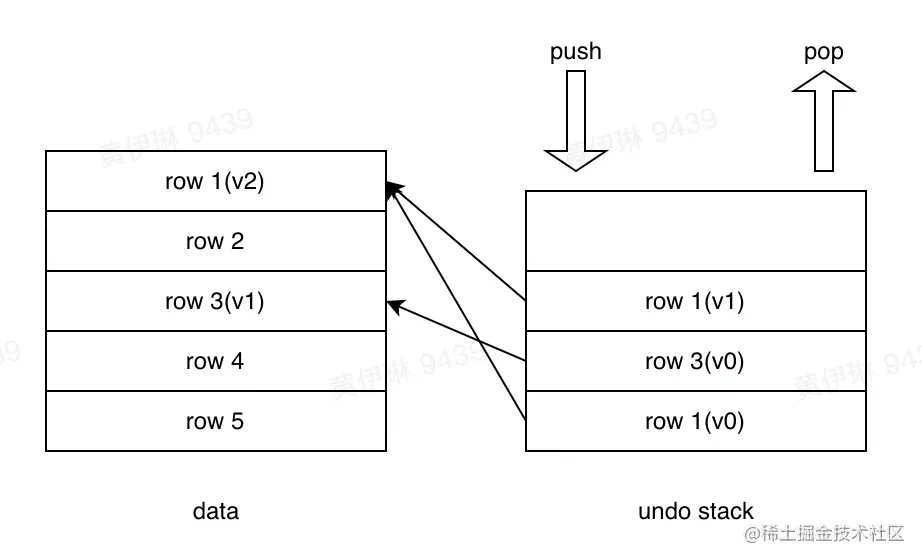
Index design
Because it only requires equivalent matching , So you can use the simplest hash Indexes .
Project library
Project structures,
Use large C/C++ The most commonly used CMake Tools .CMake It's a cross platform compilation tool .CMake Mainly write CMakeLists.txt File by cmake The order will CMakeLists.txt File to make The required Makefile file , Last use make Command compilation source code to generate executable program or library file .
cmake_minimum_required(VERSION 3.8)
project(ByteYoungDB)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_COMPILER "g++")
set(CMAKE_CXX_FLAGS "-g -Wall -Werror -std=c++17")
// O0 No optimization ,O2 Can do optimization
set(CMAKE_CXX_FLAGS_DEBUG "-O0")
set(CMAKE_CXX_FLAGS_RELEASE "-O2 -DNDEBUG ")
set(CMAKE_INSTALL_PREFIX "install")
set(CMAKE_LIBRARY_OUTPUT_DIRECTORY
${CMAKE_BINARY_DIR}/lib)
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY
${CMAKE_BINARY_DIR}/bin)
include_directories(${CMAKE_SOURCE_DIR}/sql-parser/include)
add_subdirectory(src/main)
add_subdirectory(src/sql-parser-test)
Reference study materials :
《CMake Cookbook Chinese version 》 - Bookset
Code store
compile
linux The system follows README.md Chinese compiler
Not linux Environmental Science , download sql-parser Library code ,make Generate libsqlparser.so, Replace the ByteYoungDB/sql-parser/lib/libsqlparser.so Under the table of contents
Harvest
parser
The parser supports lexical analysis 、 Syntax analysis 、 Semantic analysis . Lexical analysis and grammatical analysis rely on sql-parser Open source project implementation , This project realizes semantic analysis based on it
Optimzer
If there is where Conditions , Will generate filter A filtered plan tree
If the table structure is a,b,c The order of , But specify b,c,a Output , Then the optimizer will generate the corresponding plan tree as required
Because it does not support very complex queries , So there is nothing optimized
Executor
The actuator will be initialized first , According to the generated by the analyzer plan Structure generates corresponding operator Structure , Depth first traversal , Sir becomes the lowest , And then generate up
The lowest level actuator calls the interface of the storage engine to scan the table for table operation
The actuator executes according to the generated operator structure , Use volcanic models , Pass from top to bottom next() Function to call the lower level , Then return the result from the bottom up
Storage engine
The storage engine implements two linked lists , As in the data structure above
The structure of a piece of data is actually getting longer char Array , Then apply for the memory size according to the calculation 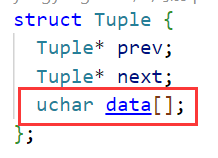
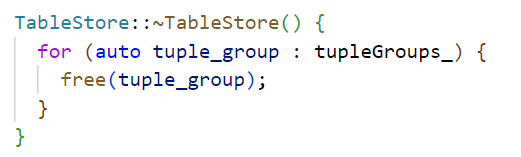
Every time you apply for memory, it will be saved to tupleGroups, It is convenient to release the memory in a unified way 
Business
Design three undo type : Additions and deletions , It's a stack data structure
Input begin, Open transaction 
With insert Operation as an example , In the storage engine , Will judge whether it is within the transaction , If it is , Then add undo
If the user makes rollback, Will undo Stack pop, To recover data
delete Operation carried out undo When restoring data, you need to put the corresponding memory into freelist For later operation
边栏推荐
- Fabric. JS background is not affected by viewport transformation
- Gee data set: export the distribution and installed capacity of hydropower stations in the country to CSV table
- Global and Chinese market of insulin pens 2022-2028: Research Report on technology, participants, trends, market size and share
- Find the subscript with and as the target from the array
- Fabric.js 3个api设置画布宽高
- Pyechart1.19 national air quality exhibition
- 青训营--数据库实操项目
- 函数中使用sizeof(arr) / sizeof(arr[0])求数组长度不正确的原因
- Preparation for writing SAP ui5 applications using typescript
- 创新永不止步——nVisual网络可视化平台针对Excel导入的创新历程
猜你喜欢
7.TCP的十一种状态集
![Gee: explore the change of water area in the North Canal basin over the past 30 years [year by year]](/img/7b/b9ef76cee8b32204331a9c3c21b5c2.jpg)
Gee: explore the change of water area in the North Canal basin over the past 30 years [year by year]
创新永不止步——nVisual网络可视化平台针对Excel导入的创新历程

Fabric.js IText设置指定文字的颜色和背景色

Black Horse Notes - - set Series Collection

Fabric. JS activation input box

The El cascader echo only selects the questions that are not displayed
青训营--数据库实操项目

MySQL foundation --- query (learn MySQL foundation in 1 day)
黑马笔记---Set系列集合
随机推荐
函数中使用sizeof(arr) / sizeof(arr[0])求数组长度不正确的原因
Preparation for writing SAP ui5 applications using typescript
Gee series: Unit 1 Introduction to Google Earth engine
國產全中文-自動化測試軟件Apifox
6. Network - Foundation
Two implementation methods of delay queue
Case sharing | intelligent Western Airport
Fabric.js IText 手动设置斜体
Fabric. JS centered element
paddle: ValueError:quality setting only supported for ‘jpeg‘ compression
Global and Chinese markets of semiconductor laser therapeutics 2022-2028: Research Report on technology, participants, trends, market size and share
Ls1046nfs mount file system
Fabric.js 渐变
Database batch insert data
Creation and destruction of function stack frames
About PROFIBUS: communication backbone network of production plant
Using QA band and bit mask in Google Earth engine
7.1模擬賽總結
Go implements leetcode rotation array
数据的储存