当前位置:网站首页>Kafaka log collection
Kafaka log collection
2022-07-05 13:40:00 【[email protected]】
List of articles
1 Kafka In depth architecture
1.1 Kafka Workflow and file storage mechanism
Kafka Chinese news is based on topic To classify , Producer production message , Consumer consumption news , It's all about topic Of .
topic It's a logical concept , and partition It's a physical concept , Every partition Corresponds to a log file , The log What is stored in the file is producer Production data .Producer Production data will be continuously added to the log End of file , And every data has its own offset. Every consumer in the consumer group , They will record in real time what they have consumed offset, So that when an error recovers , Keep spending from where you were last .
Because the information produced by the producer will continue to be added to log end of file , To prevent log Too large files lead to inefficient data location ,Kafka It adopts fragmentation and indexing mechanism , Each one partition Divided into several segment. Every segment For two files :“.index” Document and “.log” file . These files are in a folder , The naming rule for this folder is :topic name + Zone number . for example ,test This topic There are three divisions , Then the corresponding folder is test-0、test-1、test-2.
index and log File with current segment The first message of offset name .
“.index” Files store a lot of index information ,“.log” Files store a lot of data , The metadata in the index file points to the corresponding data file message The physical offset address of .
Data reliability assurance
To guarantee producer Data sent , Can reliably send to the specified topic,topic Each partition received producer After sending the data , All need to producer send out ack(acknowledgement Acknowledge receipt of ), If producer received ack, The next round will be sent , Otherwise, resend the data .Data consistency issues
LEO: Refers to the largest of each copy offset;
HW: It refers to the biggest consumer can see offset, The smallest of all copies LEO.
(1)follower fault
follower It will be temporarily kicked out after a failure ISR(Leader Maintain a and Leader Keep it in sync Follower aggregate ), To be follower After recovery ,follower Will read the last... Of the local disk record HW, And will log The document is higher than HW Cut off the part of , from HW Began to leader To synchronize . And so on follower Of LEO Greater than or equal to Partition Of HW, namely follower Catch up leader after , You can rejoin ISR 了 .
(2)leader fault
leader After failure , From ISR Choose a new leader, after , To ensure data consistency among multiple copies , The rest follower I'll put my own log The document is higher than HW Cut off the part of , Then from the new leader Synchronous data .
notes : This only ensures data consistency between replicas , There is no guarantee that the data will not be lost or repeated .
ack Response mechanism
For some less important data , The reliability requirement of data is not very high , Able to tolerate a small amount of data loss , So there's no need to wait ISR Medium follower All received successfully . therefore Kafka Three levels of reliability are provided for users , The user makes a trade-off choice according to the requirements of reliability and delay .
When producer towards leader When sending data , Can pass request.required.acks Parameter to set the level of data reliability :
0: It means producer There is no need to wait for the coming from broker And continue to send the next batch of messages . In this case, the data transmission efficiency is the highest , But data reliability is the lowest . When broker It is possible to lose data in case of failure .
1( The default configuration ): It means producer stay ISR Medium leader The data that has been successfully received and confirmed is sent to the next message. If in follower Before synchronization succeeds leader fault , Then data will be lost .
-1( Or is it all):producer Need to wait ISR All in follower After all the data are confirmed to be received, the transmission is completed , Highest reliability . But if follower After synchronization ,broker send out ack Before ,leader failure , It will cause data duplication .
The performance of the three mechanisms decreases in turn , Data reliability increases in turn .
notes : stay 0.11 Before version Kafka, There is nothing we can do about it , It can only guarantee that the data will not be lost , And then downstream consumers do the overall de duplication of data . stay 0.11 And later versions Kafka, Introduced a major feature : Idempotency . The so-called idempotency means Producer No matter to Server How many duplicate data are sent , Server There is only one persistence on each end .
2 Filebeat+Kafka+ELK
1. Deploy Zookeeper+Kafka colony
Reference resources Zookeeper + kafka Concept and deployment
2. Deploy Filebeat
cd /usr/local/filebeat
vim filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/messages
- /var/log/*.log
......
# Add output to Kafka Configuration of
output.kafka:
enabled: true
hosts: ["192.168.16.10:9092","192.168.16.20:9092","192.168.16.30:9092"] # Appoint Kafka Cluster configuration
topic: "filebeat_test" # Appoint Kafka Of topic
# start-up filebeat
./filebeat -e -c filebeat.yml
3. Deploy ELK, stay Logstash Create a new node on the node where the component is located Logstash The configuration file
cd /etc/logstash/conf.d/
vim filebeat.conf
input {
kafka {
bootstrap_servers => "192.168.16.10:9092,192.168.16.20:9092,192.168.16.30:9092"
topics => "filebeat_test"
group_id => "test123"
auto_offset_reset => "earliest"
}
}
output {
elasticsearch {
hosts => ["192.168.80.30:9200"]
index => "filebeat_test-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
# start-up logstash
logstash -f filebeat.conf
4. Browser access http://192.168.16.30:5601 Sign in Kibana, single click “Create Index Pattern” Button to add an index “filebeat_test-*”, single click “create” Button to create , single click “Discover” Button to view chart information and log information .
版权声明
本文为[[email protected]]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/186/202207051335384198.html
边栏推荐
- Go pointer
- 嵌入式软件架构设计-消息交互
- Mmseg - Mutli view time series data inspection and visualization
- Binder communication process and servicemanager creation process
- MMSeg——Mutli-view时序数据检查与可视化
- What happened to the communication industry in the first half of this year?
- mysql获得时间
- 【MySQL 使用秘籍】一网打尽 MySQL 时间和日期类型与相关操作函数(三)
- 百度杯”CTF比赛 2017 二月场,Web:爆破-2
- js判断数组中是否存在某个元素(四种方法)
猜你喜欢

Wonderful express | Tencent cloud database June issue
![[深度学习论文笔记]UCTransNet:从transformer的通道角度重新思考U-Net中的跳跃连接](/img/b6/f9da8a36167db10c9a92dabb166c81.png)
[深度学习论文笔记]UCTransNet:从transformer的通道角度重新思考U-Net中的跳跃连接
![[server data recovery] a case of RAID5 data recovery stored in a brand of server](/img/04/c9bcf883d45a1de616c4e1b19885a5.png)
[server data recovery] a case of RAID5 data recovery stored in a brand of server
Interviewer soul torture: why does the code specification require SQL statements not to have too many joins?
Write API documents first or code first?
TortoiseSVN使用情形、安装与使用

"Baidu Cup" CTF competition in September, web:upload
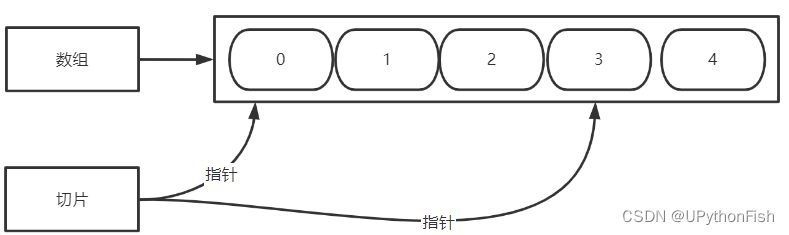
go 数组与切片

【每日一题】1200. 最小绝对差

Laravel框架运行报错:No application encryption key has been specified
随机推荐
STM32 reverse entry
Idea remote debugging agent
一文详解ASCII码,Unicode与utf-8
"Baidu Cup" CTF competition in September, web:sql
ELK 企业级日志分析系统
百度杯”CTF比赛 2017 二月场,Web:爆破-2
【MySQL 使用秘籍】一網打盡 MySQL 時間和日期類型與相關操作函數(三)
Multi person cooperation project to see how many lines of code each person has written
Laravel framework operation error: no application encryption key has been specified
FPGA 学习笔记:Vivado 2019.1 添加 IP MicroBlaze
Fragmented knowledge management tool memos
Reflection and imagination on the notation like tool
Catch all asynchronous artifact completable future
Solve the problem of invalid uni app configuration page and tabbar
Shuttle INKWELL & ink components
What are the private addresses
Wonderful express | Tencent cloud database June issue
[public class preview]: basis and practice of video quality evaluation
Summary and arrangement of JPA specifications
山东大学暑期实训一20220620