当前位置:网站首页>Interviewer soul torture: why does the code specification require SQL statements not to have too many joins?
Interviewer soul torture: why does the code specification require SQL statements not to have too many joins?
2022-07-05 13:26:00 【Hollis Chuang】
Send questions
interviewer : Have been operated Linux Do you ?
I : Yes
interviewer : I want to check the memory usage. What command should I use
I :free perhaps top
interviewer : Then you can use it free What information can be seen in the command
I : that , As shown in the figure below You can see memory and cache usage
total Total memory
used Used memory
free Free memory
buff/cache Used cache
avaiable Available memory

interviewer : Do you know how to clean up the used cache (buff/cache)
I :em... I do not know!
interviewer :sync; echo 3 > /proc/sys/vm/drop_caches You can clean it up buff/cache 了 , Can you tell me if I can execute this command online ?

I :( Send questions , Inner joy ) The benefits are great , Clean up the cache and we have more memory available , Just follow pc above xx Like the guard's little rocket , click , To free up a lot of memory
interviewer :em...., Go back and wait for the announcement
We can talk SQL Join
interviewer : Change the subject , Talk to you about join The understanding of the
I : well ( If you make another mistake, it's over , Seize the opportunity )
review
SQL Medium join According to some conditions, you can combine the specified table with and return the data to the client
join There are
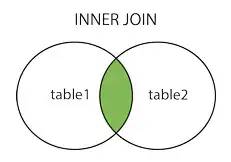
inner joinInternal connection
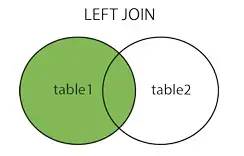
left joinLeft connection
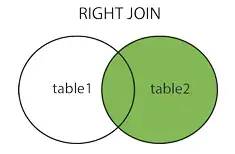
right joinThe right connection
full joinFull connection
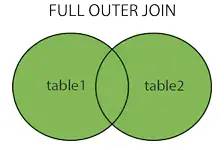
The above picture is from :cnblogs.com/reaptomorrow-flydream/p/8145610.html
interviewer :
If it needs to be used in project development join sentence , How to optimize and improve performance ?
I : There are two cases , Small data size , Large data scale .
interviewer : then ?
I : about
Small data size It's all in memory. Whoa
Large data scale
Can be optimized by adding indexes join Statement execution speed Can be reduced by redundant information join The number of times Minimize the number of table connections , One SQL Do not connect statement tables more than 5 Time
interviewer : It can be summarized as join Statement is relatively cost performance , Am I right? ?
I : Yes
interviewer : Why? ?
buffer
I : In execution join There must be a process of comparison
interviewer : Yes
I : Comparing two tables one by one is slow , So we can read the data from two tables into one in turn Memory block in , With MySQL Of InnoDB Engine as an example , By using the following statements, we can find the relevant memory area show variables like '%buffer%'
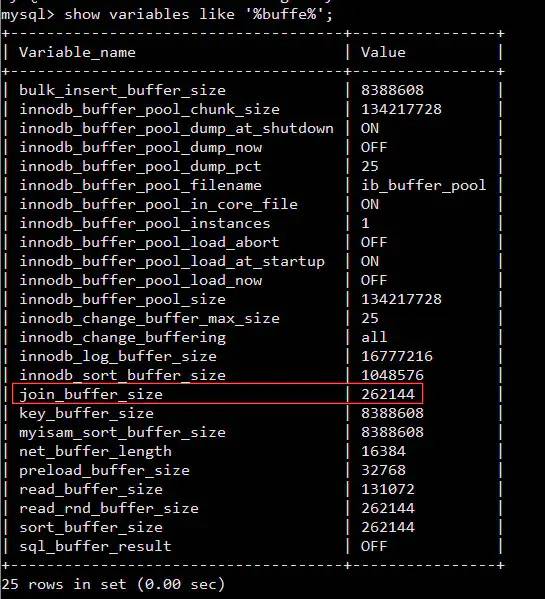
As shown in the figure below join_buffer_size The size of will affect us join Statement execution performance
interviewer : Besides ?
A big premise
I : Any project will go online after all , Data generation is inevitable , The size of the data can't be too small
interviewer : That's true
I : Most of the data in the database will eventually be saved to Hard disk On , And stored as a file .
With MySQL Of InnoDB Engine as an example
InnoDB With
page(page) Basic IO Company , The size of each page is 16KBInnoDB For each table, a
.ibdfile
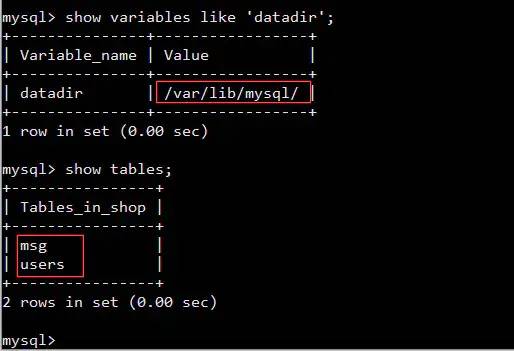
verification
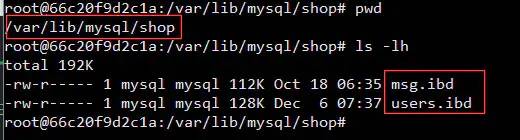
I : This means that we need to read as many files as we have tables to connect , Although the index can be used , But it's still necessary to move the head of the hard disk frequently
interviewer : That is to say, frequent movement of magnetic head will affect performance, right
I : Yes , Don't all open source frameworks like to say that they have greatly improved performance through sequential reading and writing , such as hbase、kafka
interviewer : That's right. , Then you think Linux Is this optimized ? Tips , You can do it again free Order to have a look
I : Strange how the cache is occupied 1.2G many


picture source :https://www.linuxatemyram.com/
interviewer : Have you ever thought about it
buff/cacheWhat's in it ,?Why?
buff/cacheTake up so much memory , Available memory isavaillablealso1.1G?Why can you clean it up with two orders
buff/cacheMemory footprint , And want to releaseusedIt can only be done by ending the process ?
product , Your delicacies
After thinking for a few minutes
I : It's so easy to let go buff/cache Memory used , That means it doesn't matter , Clearing it will not affect the operation of the system
interviewer : Not exactly
I : Is it ? Remember 《CSAPP》( Deep understanding of computer systems ) There's a word in it
The essence of memory hierarchy is , Each tier of storage device is the cache of the lower tier devices

Adult translation , That is to say Linux Think of memory as the cache of hard disk
Related information :http://tldp.org/LDP/sag/html/buffer-cache.html
interviewer : Now you know how to answer that question
I : I ....

Join Algorithm
interviewer : Give you another chance , If you can do it Join What would you do with the algorithm ?
I : Without index , Nested loop is over . If there is an index , Index can be used to improve performance .
interviewer : Back to join_buffer Do you think join_buffer What is stored in it ?
I : During scanning , The database will select a table to put it Data to be returned and compared with other tables In the join_buffer
interviewer : How to handle with index ?
I : This is a little bit easier , Just read the index tree of two tables and compare them , Let me introduce the processing method without index
Nested Loop Join
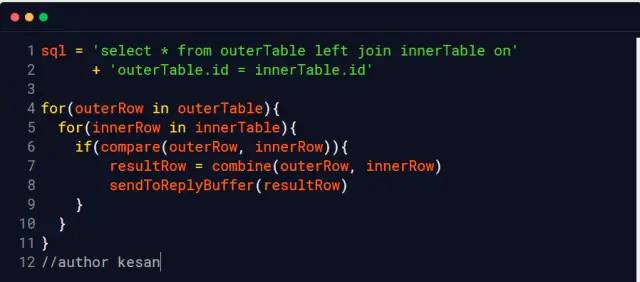
Nested loop , Read only one row of data in the table at a time , That is to say if outerTable Yes 10 Ten thousand rows of data , innerTable Yes 100 Row data , Read required 10000000 Time ( Suppose the files of these two tables are not cached in memory by the operating system , We call it the cold data sheet )
Of course, no database engine uses this algorithm now ( Too slow )
Block nested loop
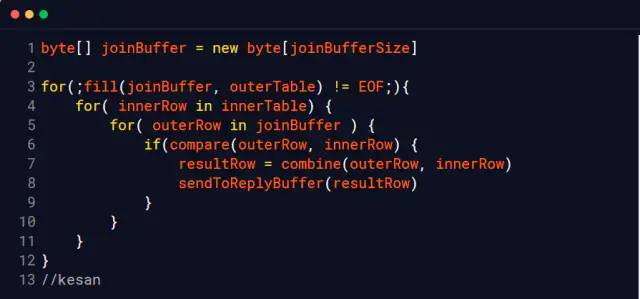
Block block , That is to say, every time a piece of data is taken to memory to reduce I/O The cost of
When no index is available ,MySQL InnoDB That's how it works
Consider the following two tables t_a and t_b
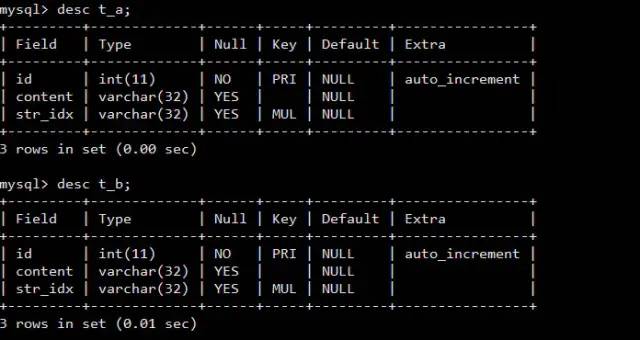
When index execution is not possible join During operation ,InnoDB Will be used automatically Block nested loop Algorithm

summary
At school , Database teachers like database paradigm best , I didn't learn to be performance oriented until I went to work , Redundancy means redundancy , There's no redundancy join If join It really affects performance . Try to get your join_buffer_size, Or replace the SSD .
author : Corsane Go
juejin.cn/post/6844904041382674440
End
Previous recommendation

Redis Distributed lock failure , I can't help being rude ...
How to prevent your jar Decompiled ?
There is Tao without skill , It can be done with skill ; No way with skill , Stop at surgery
Welcome to pay attention Java Road official account

Good article , I was watching ️
边栏推荐
- Flutter 3.0更新后如何应用到小程序开发中
- 【Hot100】34. 在排序数组中查找元素的第一个和最后一个位置
- 关于 Notion-Like 工具的反思和畅想
- Clock cycle
- 聊聊异步编程的 7 种实现方式
- Jenkins installation
- [notes of in-depth study paper]transbtsv2: wider instead of deep transformer for medical image segmentation
- 私有地址有那些
- 蜀天梦图×微言科技丨达梦图数据库朋友圈+1
- Principle and configuration of RSTP protocol
猜你喜欢
Fragmented knowledge management tool memos
Android本地Sqlite数据库的备份和还原
jenkins安装
Principle and configuration of RSTP protocol
Pycharm installation third party library diagram
FPGA learning notes: vivado 2019.1 add IP MicroBlaze

ASEMI整流桥HD06参数,HD06图片,HD06应用

Shu tianmeng map × Weiyan technology - Dream map database circle of friends + 1
![[notes of in-depth study paper]uctransnet: rethink the jumping connection in u-net from the perspective of transformer channel](/img/b6/f9da8a36167db10c9a92dabb166c81.png)
[notes of in-depth study paper]uctransnet: rethink the jumping connection in u-net from the perspective of transformer channel
Don't know these four caching modes, dare you say you understand caching?
随机推荐
4年工作经验,多线程间的5种通信方式都说不出来,你敢信?
Go string operation
Clock cycle
CAN和CAN FD
Difference between avc1 and H264
Go pointer
Nantong online communication group
Yyds dry goods inventory # solve the real problem of famous enterprises: move the round table
Sorry, we can't open xxxxx Docx, because there is a problem with the content (repackaging problem)
Although the volume and price fall, why are the structural deposits of commercial banks favored by listed companies?
js判断数组中是否存在某个元素(四种方法)
【MySQL 使用秘籍】一網打盡 MySQL 時間和日期類型與相關操作函數(三)
Pandora IOT development board learning (HAL Library) - Experiment 7 window watchdog experiment (learning notes)
53. 最大子数组和:给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
Write macro with word
Cf:a. the third three number problem
Write API documents first or code first?
ASEMI整流桥HD06参数,HD06图片,HD06应用
Backup and restore of Android local SQLite database
百度杯”CTF比赛 2017 二月场,Web:爆破-2