当前位置:网站首页>Idea中运行sparkSQL
Idea中运行sparkSQL
2022-08-02 15:12:00 【我要用代码向我喜欢的女孩表白】
这是一个wordcount例子
1.准备wordcount的文本
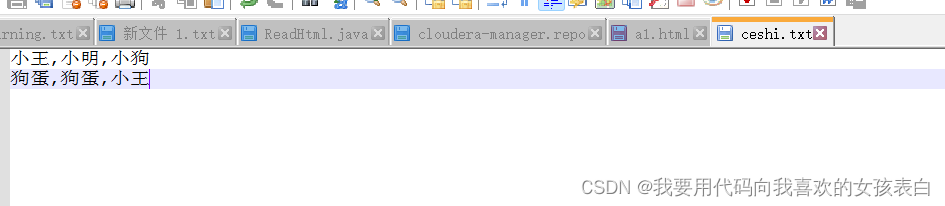
2.hadoop环境搭建
下载

解压,hadoop到某个目录
将hadoop.dll和winutils.exe放入C:\Windows\System32目录下
将hadoop.dll和winutils.exe放入解压后的hadoop\bin目录下
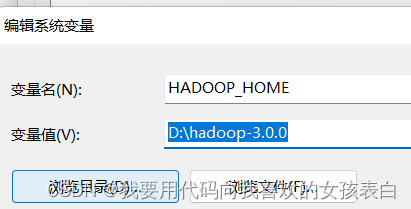
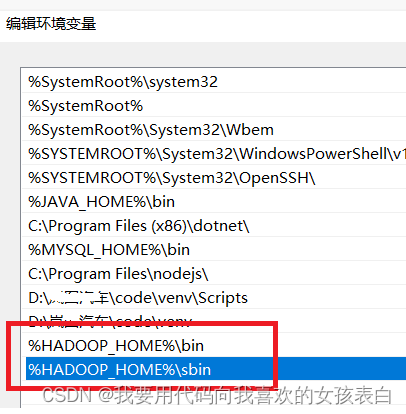
配置环境变量
cmd,输入hadoop -version
成功显示版本
重启IDEA
3.scala环境搭建
离线在idea中安装scala插件_我要用代码向我喜欢的女孩表白的博客-CSDN博客_idea离线安装scala插件
4.spark的相关依赖
4.你很可能会遇到的问题
5.代码部分(最简单)
6.将测试好的代码,打包成jar
7.打包后,想在linux上跑
边栏推荐
猜你喜欢



随机推荐
轻松入门自然语言处理系列 专题8 源码解读──基于HMM的结巴分词
动态权重之多任务不平衡论文 (二) MetaBalance
Azure Kinect(K4A)人体识别跟踪进阶
策略路由下发
从幻核疑似裁撤看如何保证NFT的安全
Brute-force cracking of the latest JVM interview questions of Meituan: unlimited execution
继续来学习有关淘宝的API接口的使用——获得店铺的所有商品 API
leetcode 504. Base 7 七进制数 (简单)
美团面试:如何设计一个注册中心?
MySQL查询
先睹为快!界面控件DevExpress WPF这些功能即将发布
面试官的角度谈谈算法岗面试的过程(岗位涉及到OCR、目标检测、图像分割、语音识别等领域)
Qt | 关于对象树和元对象的相关问题
太帅了!我用炫酷大屏展示爬虫数据!
已经2022下半年了,居然还在说链动2+1!
助力疫情防控,30行代码就能搞定无服务器实时健康码识别!
Based on mobileNet dog breed classification (migration)
Qt | 关于容器类的一些总结
不平衡问题: 深度神经网络训练之殇
QT基础第四天(4)qt事件机制:事件基础概念,常见事件机制,事件处理以及事件的重写