当前位置:网站首页>CV learning notes - clustering
CV learning notes - clustering
2022-07-03 10:07:00 【Moresweet cat】
Image clustering
1. summary
1. Classification and clustering
classification : Classification solves the problem of mining patterns from specific data sets , And the process of making judgments .
The main process of classification learning :
(1) Given the training data set , There is a tag number similar to the tag function in the data set , According to the tag number, it is judged that this data set is a data set that needs to play a positive role ( Forward dataset ) Or for data sets that need to be suppressed ( Negative data set ), For example, we need to classify whether the fruit is grape , Then the data sets that are all grapes are positive data sets , Non grape datasets are negative datasets .
(2) Build a training model , And use data sets for learning and training .
(3) Predict the prediction data set through the trained model , And calculate the performance of the results .

clustering : A cluster is a collection of data instances , The data elements in the same cluster are similar to each other , But the elements in different clusters are different from each other , seeing the name of a thing one thinks of its function , Clustering is to gather data and put together data members that are similar in some aspects . The attributes between clustering samples are divided into ordered attributes ( For example, concentration 0.45、0.89) And unordered attributes ( Good melon 、 Bad melon ) Two kinds of .
Because there is no classification or grouping information representing data categories in clustering , That is, the data is not labeled , So clustering is usually classified as Unsupervised learning (Unsupervised Learning).
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-n7d8JugS-1637728886034)(./imgs/image-20211121184225384.png)]](/img/75/978ed631d6b0639ac4819357c68de2.jpg)
The difference between classification and clustering tasks :
- The result of clustering is to gather similar data in a region according to the similarity of data , What are the similarities of this specific category , It needs to be judged artificially .
- Classification learning is to learn and build a model based on the data set of existing categories , Then use the model to predict the process of new data sets .
- The dataset used for classification is labeled , The data set used for clustering is unlabeled , Clustering just separates the data , What are the specific similarities that need to be judged .
Common clustering algorithms :
- Prototype clustering ( A typical :K Mean clustering algorithm )
- Hierarchical clustering
- Density clustering
2. Prototype Clustering Algorithm
1. summary
Prototype clustering algorithm is a kind of hypothetical clustering structure that can pass through a set of prototypes ( Representative points in sample space ) The algorithm of characterization . It is a very common algorithm in real tasks .
2.K-Means clustering
brief introduction : *K-Means Clustering is the most commonly used clustering algorithm , It started with signal processing , The goal is to divide the data points into K Class clusters . The biggest advantage of this algorithm is that it is simple 、 Easy to understand , It's faster , The disadvantage is to specify the number of clusters before clustering .
k-means The algorithm is a prototype clustering algorithm .
K-Means Clustering algorithm flow
- determine K( That is, the number of clusters ) value
- Randomly select... From the dataset K Data points as the centroid (Centroid) Or data center .
- Calculate the distance from each point to each centroid , And divide each point into a group that is closest to the centroid .
- When each center of mass gathers some points , Redefine the algorithm and select a new centroid .( For each cluster , Calculate its mean value , That is, get a new K Centroid point )
- Iteratively perform steps 3 to 4 , Until the iteration termination conditions are met ( The clustering results will not change , The result converges )
Examples of algorithms :
Data sets :
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-6jiWg2ud-1637728886036)(./imgs/image-20211122125817662.png)]](/img/04/ec65d16549ad75c812ea4269d7ff6d.jpg)
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-B8PMCbhl-1637728886037)(./imgs/image-20211122125909599.png)]](/img/36/e8916a9b9a5514795d4338a2df6afc.jpg)
The first round : Set up K by 2, That is, we should divide the data set into two categories , Randomly select two points as the center of mass , Choose here P1 P2, Then calculate the distance from each point to the center of mass , for example P3 To P1 The distance to 10 = 3.16 \sqrt{10} = 3.16 10=3.16, Calculation P3 To P2 The distance to ( 3 − 1 ) 2 + ( 1 − 2 ) 2 = 2.24 \sqrt{(3-1)^2+(1-2)^2}=2.24 (3−1)2+(1−2)2=2.24,P3 leave P2 A more recent , so P3 Join in P2 Cluster of , The calculation of other points is the same .
The result of a round of calculation is
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-9OJBlw7e-1637728886039)(./imgs/image-20211122131148670.png)]](/img/61/cefc445c58e0a39cab2733d07b65f5.jpg)
Group 1:P1 Group 2:P2、P3、P4、P5、P6
* The second round :* Due to group 1 There is only one point , No need to deal with , Direct selection P1 For the center of mass , Group 2 Set all groups 2 In the middle of x、y Construct a new nonexistent point as a new centroid after finding the mean value of the coordinates ( It is not divided into a group , It is only used as the center of mass ), structure Q( 1 + 3 + 8 + 9 + 10 5 \frac{1+3+8+9+10}{5} 51+3+8+9+10, 2 + 1 + 8 + 10 + 7 5 \frac{2+1+8+10+7}{5} 52+1+8+10+7) That is to say Q(6.2,5.6) and P1(0,0) As a new centroid , Recalculate the distance from each point to the centroid to divide .
The result of a round of calculation is
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-jq4zsvYx-1637728886040)(./imgs/image-20211122131853997.png)]](/img/d2/36d6dd811dfa212dc6901927148815.jpg)
Group 1:P1、P2、P3 Group 2:P4、P5、P6
* The third round :* Still calculate according to the above method , Skip process , New centroid R(1.33,1)、T(9,8.33).
After three rounds of calculation, the result is
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-kT4lv2Iu-1637728886042)(./imgs/image-20211122132139630.png)]](/img/12/1891874a629db4c6506dc690357be8.jpg)
Group 1:P1、P2、P3 Group 2:P4、P5、P6
The comparison results are the same as those of the previous round , It shows that the result converges , End the clustering algorithm .
K-Means Advantages of clustering algorithm :
- It is a classic algorithm to solve the clustering problem , Simple 、 Fast
- For dealing with big data sets , The algorithm maintains high efficiency
- When the result cluster is dense , It works better
K-Means The disadvantages of clustering algorithm :
- It must be given in advance k( The number of clusters to generate )
- Sensitive to noise and outlier data
K-Means Application examples of algorithms :
- Image segmentation
- Image clustering
- Image recognition
We go through K-Means These pixels can be clustered into K A cluster of , Then use the centroid points in each cluster to replace all in the cluster
Pixels of , This can be achieved in Do not change the resolution Quantize the color of the compressed image , Realize image color level segmentation .
3. Hierarchical clustering
1. Method & Category
Method : First, calculate the distance between all samples , Merge the closest point into the same class each time . The advantages are similar to the structure of Huffman tree , After classification , Calculate the distance between classes , Merge the nearest class into a large class . Cycle back and forth until it is merged into a big category .
How to calculate the distance between classes : The shortest distance method 、 The longest distance method 、 Middle distance method 、 Quasi average method, etc .
species : Hierarchical clustering algorithm is divided into according to the order of hierarchical decomposition : Bottom up (bottom-up) And top-down (top-down), They are also called Condensed (agglomerative) Hierarchical clustering algorithm > and Divided (divisive) Hierarchical clustering algorithm .>
2. The process of agglomerative hierarchical clustering algorithm
The strategy of condensed hierarchical clustering is to treat each object as a cluster , And then merge these clusters into larger and larger clusters , Until all right
The elephants are all in a cluster , Or an end condition is met . Most hierarchical clustering belongs to condensed hierarchical clustering , They're just between clusters
The definition of similarity is different .
- Think of each object as a class , Calculate the minimum distance between objects ;
- Merge the two classes with the smallest distance into a new class ;
- Recalculate the distance between the new class and all classes ;
- Repeat steps 2 to 3 , Until all classes are merged into one big class .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-eJ1qXmVO-1637728886043)(./imgs/image-20211124120504948.png)]](/img/b7/39bf5cfdf9b74d652b15bedea937b4.jpg)
The calculation process matrix in the above figure is :
[ choose in close and class other A choose in close and class other B class between most Small distance leave new class in element plain individual Count 0 3 0 2 4 5 1.15470054 3 1 2 2.23606798 2 6 7 4.00832467 5 ] \left[ \begin{matrix} Select the merge category A& Select the merge category B& Minimum distance between classes & The number of elements in the new class \\ 0&3&0&2\\ 4&5&1.15470054&3\\ 1&2&2.23606798&2\\ 6&7&4.00832467&5 \end{matrix} \right] ⎣⎢⎢⎢⎢⎡ choose in close and class other A0416 choose in close and class other B3527 class between most Small distance leave 01.154700542.236067984.00832467 new class in element plain individual Count 2325⎦⎥⎥⎥⎥⎤
Be careful :0 and 3 The merged new class uses 5 Number , The original medium is 0~4, Others follow this rule .
Tree view classification judgment : The above clustering process , The aggregated categories have different combinations according to different stages , So how to judge the category , In real tasks, data sets are often divided into several categories .
Want to be divided into two categories , Cut when there are two vertical lines from top to bottom , Then what is connected under the corresponding vertical line is a class
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-89ZmuAqd-1637728886045)(./imgs/image-20211124122404981.png)]](/img/02/b00d9d53464ed123629ee8b0be9baa.jpg)
When you want to divide into three categories , Cut when there are three vertical lines from top to bottom , Then what is connected under the corresponding vertical line is a class
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-FVSzNjTv-1637728886046)(./imgs/image-20211124122437684.png)]](/img/25/07a7d73ecbf4ca8c96bfea1123403c.jpg)
3. Characteristics of condensed hierarchical clustering
- Unlike K-Means In that case, we need to consider selecting the initial point , There is no problem of local minima (K-Means It is possible to converge to local minima ), Agglomerative hierarchical clustering is not similar K The global objective function of the mean .
- The merge operation cannot be undone , be faithful to one 's husband unto death
- Computing storage costs are high (*)
4. Advantages and disadvantages of hierarchical clustering
advantage :
- The similarity between distance and rule is easy to define , Less restrictions ;
- There is no need to set the number of clusters in advance ;
- You can find the hierarchical relationship of classes ;
- Can be clustered into other shapes
shortcoming :
- The computational complexity is too high ;
- Singular values can also have a big impact ;
- The algorithm is likely to cluster into chains
4. Density clustering
1. Algorithm description
Density clustering (DBSCAN)
Two parameters are required :ε (eps) And the minimum number of points needed to form a high density area (minPts)
- It starts with an arbitrary point that is not accessed , And then explore the point of ε- Neighborhood , If ε- There are enough points in the neighborhood , Then a new cluster is established , Otherwise, this point is labeled noise .
- Be careful , This noise point may be found at other points after ε- Neighborhood , And the ε- There may be enough points in the neighborhood , Then this point will be added to the cluster .
2. Advantages and disadvantages of density clustering
advantage :
- Insensitive to noise ;
- It can find clusters of arbitrary shape
shortcoming :
- But the result of clustering has a lot to do with the parameters ;
- Identify clusters with fixed parameters , But when the sparse degree of clustering is different , The same criteria may destroy the natural structure of clustering , That is to say, the sparse clusters will be divided into multiple clusters or the clusters with higher density and closer to each other will be merged into one cluster .
5. Spectral clustering
1. Algorithm flow description
- Construct a... Based on the data The graph structure (Graph) ,Graph Each node of the corresponds to a data point , General
Like points connected , And the weight of the edge is used to represent the similarity between the data . Put this Graph Use adjacency moment
In the form of a matrix , Write it down as W . - hold W Each column of elements adds up to N Number , Put them on the diagonal ( The rest is zero ),
Form a N * N Matrix , Write it down as D . And order L = D-W . - Find out L Before k Eigenvalues , And the corresponding eigenvector .
- Put this k Features ( Column ) The vectors are arranged together to form a N * k Matrix , Think of each line as k
A vector in dimensional space , And use K-means The algorithm clustering . The class to which each row in the clustering result belongs
Don't be the original Graph The node in is also the original N Data points belong to different categories .
Simple abstract spectral clustering process , There are two main steps :
- Composition , The sampling point data is constructed into a network diagram .
- Cutaway , It is constructed in the first step according to certain trimming criteria , Cut into different graphs , And different subgraphs , That is, we are right
Corresponding clustering results .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-zaTEvk9j-1637728886048)(./imgs/image-20211124123903669.png)]](/img/b5/b17f445e2e5c37db3f6dfc9ab602d0.jpg)
Personal study notes , Only exchange learning , Reprint please indicate the source !
边栏推荐
- Positive and negative sample division and architecture understanding in image classification and target detection
- QT setting suspension button
- (1) What is a lambda expression
- Gpiof6, 7, 8 configuration
- QT self drawing button with bubbles
- 51 MCU tmod and timer configuration
- Yocto Technology Sharing Phase 4: Custom add package support
- Toolbutton property settings
- Opencv notes 17 template matching
- 03 fastjason solves circular references
猜你喜欢

2. Elment UI date selector formatting problem
![[combinatorics] Introduction to Combinatorics (combinatorial idea 3: upper and lower bound approximation | upper and lower bound approximation example Remsey number)](/img/19/5dc152b3fadeb56de50768561ad659.jpg)
[combinatorics] Introduction to Combinatorics (combinatorial idea 3: upper and lower bound approximation | upper and lower bound approximation example Remsey number)

Leetcode 300 longest ascending subsequence

Of course, the most widely used 8-bit single chip microcomputer is also the single chip microcomputer that beginners are most easy to learn
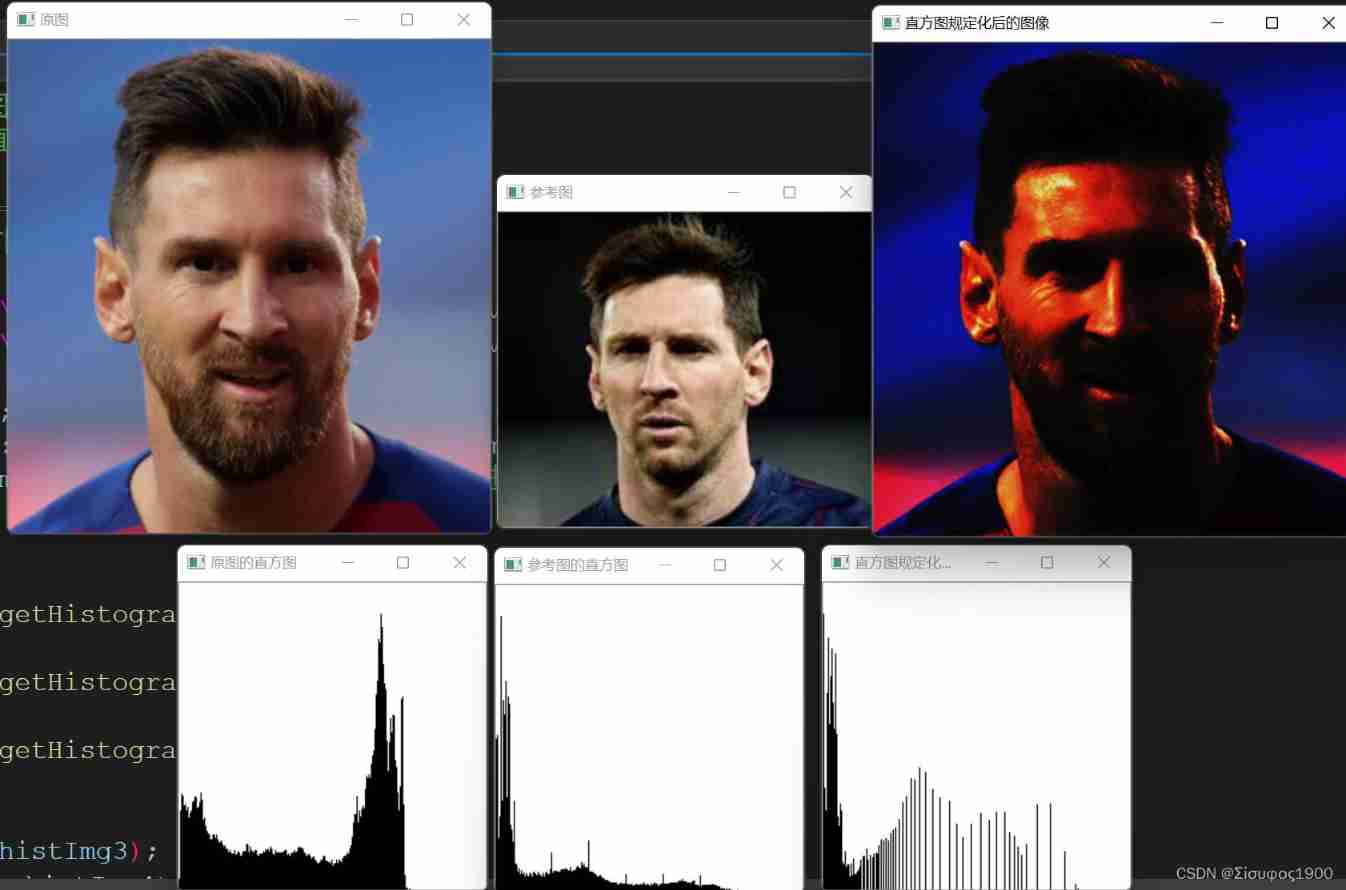
Opencv gray histogram, histogram specification

Opencv note 21 frequency domain filtering
LeetCode - 1670 設計前中後隊列(設計 - 兩個雙端隊列)
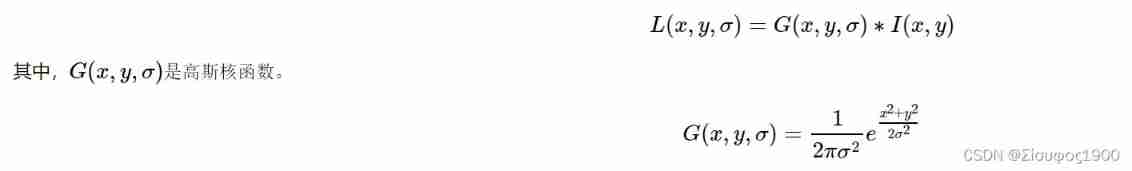
Opencv feature extraction sift

I didn't think so much when I was in the field of single chip microcomputer. I just wanted to earn money to support myself first

In third tier cities and counties, it is difficult to get 10K after graduation
随机推荐
Screen display of charging pile design -- led driver ta6932
When the reference is assigned to auto
LeetCode - 673. Number of longest increasing subsequences
LeetCode - 460 LFU 缓存(设计 - 哈希表+双向链表 哈希表+平衡二叉树(TreeSet))*
2020-08-23
Simulate mouse click
2020-08-23
2021-10-27
ADS simulation design of class AB RF power amplifier
Openeuler kernel technology sharing - Issue 1 - kdump basic principle, use and case introduction
STM32 general timer output PWM control steering gear
使用密钥对的形式连接阿里云服务器
Opencv feature extraction sift
My notes on the development of intelligent charging pile (III): overview of the overall design of the system software
2.Elment Ui 日期选择器 格式化问题
Installation and removal of MySQL under Windows
Leetcode - 895 maximum frequency stack (Design - hash table + priority queue hash table + stack)*
Connect Alibaba cloud servers in the form of key pairs
Yocto technology sharing phase IV: customize and add software package support
(2) New methods in the interface