当前位置:网站首页>Chapter 3 of hands on deep learning - (1) linear regression is realized from scratch_ Learning thinking and exercise answers
Chapter 3 of hands on deep learning - (1) linear regression is realized from scratch_ Learning thinking and exercise answers
2022-07-02 17:14:00 【coder_ sure】
List of articles
3.1 Linear regression
author github link : github link
Learning notes
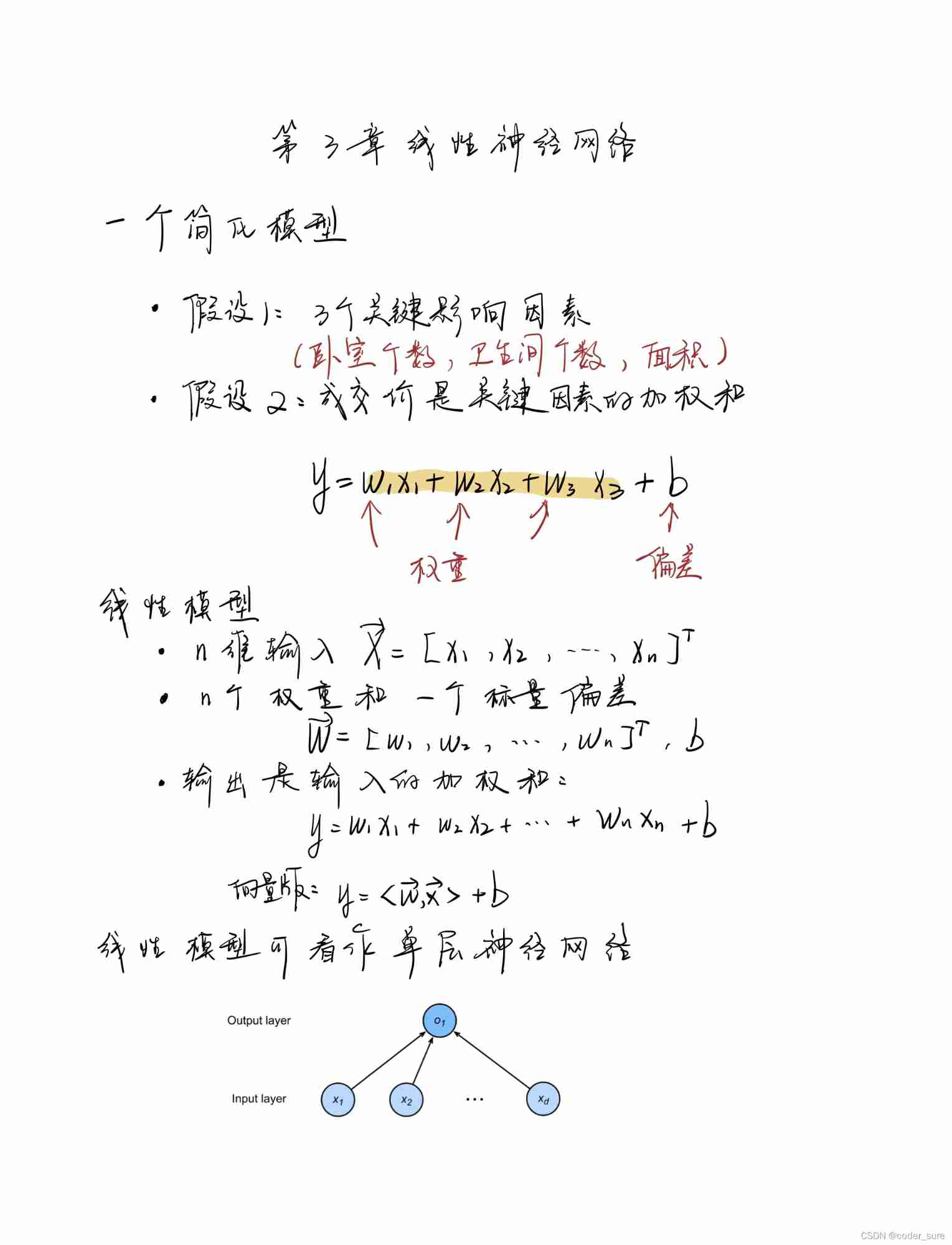





exercises
- If we initialize the weight to zero , What's going to happen . Is the algorithm still valid ?
- Suppose you are George · Simon · ohm , This paper attempts to establish a model for the relationship between voltage and current . Can you use automatic differentiation to learn the parameters of the model ?
- You can be based on Planck's law Use spectral energy density to determine the temperature of an object ?
- If you want to calculate the second derivative, what problems may you encounter ? How would you solve these problems ?
- Why is it
squared_lossYou need to use... In the functionreshapefunction ? - Try using different learning rates , Observe how fast the value of the loss function decreases .
- If the number of samples cannot be divided by the batch size ,
data_iterWhat happens to the behavior of functions ?
Problem solving
1. If we initialize the weight to zero , What's going to happen . Is the algorithm still valid ?
Experiments show that the algorithm is still effective , It looks better
whole 0 Initialization is also a common choice , Compared with normal distribution initialization, it may move towards different local optima , The algorithm is still effective .
# w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
w = torch.zeros((2,1) ,requires_grad=True)
epoch 1, loss 0.036967
epoch 2, loss 0.000132
epoch 3, loss 0.000050
4. If you want to calculate the second derivative, what problems may you encounter ? How would you solve these problems ?
The calculation formula of first-order derivative function cannot be obtained directly . resolvent : Find the first derivative and save the calculation diagram .
Example : y = x 3 + c o s x , x = π 2 , π y=x^3+cosx,x=\frac{\pi}{2},\pi y=x3+cosx,x=2π,π, Find the first derivative and the second derivative respectively
Reference resources
import torch
import math
import numpy as np
x = torch.tensor([math.pi / 2, math.pi], requires_grad=True)
y = x ** 3 + torch.cos(x)
true_dy = 3 * x ** 2 - torch.sin(x)
true_d2y = 6 * x - torch.cos(x)
# Find the first derivative , After saving the calculation diagram , To find the second derivative
dy = torch.autograd.grad(y, x,
grad_outputs=torch.ones(x.shape),
create_graph=True,
retain_graph=True) # Keep the calculation diagram for calculating the second derivative
# After the tensor, add .detach().numpy() Only tensor values can be output
print(" First derivative true value :{} \n First derivative calculation value :{}".format(true_dy.detach().numpy(), dy[0].detach().numpy()))
# Find the second derivative . above dy The first element of is the first derivative
d2y = torch.autograd.grad(dy, x,
grad_outputs=torch.ones(x.shape),
create_graph=False # No more calculation charts , Destroy the previous calculation diagram
)
print("\n Second order conduction true value :{} \n Second derivative calculation value :{}".format(true_d2y.detach().numpy(), d2y[0].detach().numpy()))
5. Why is it squared_loss You need to use... In the function reshape function ?
y ^ \hat{y} y^ It's a column vector , y y y It's a row vector
6. Try using different learning rates , Observe how fast the value of the loss function decreases .
Try it on your own :
- Low learning rate loss The decline is relatively slow
- Excessive learning rate loss Unable to converge
7. If the number of samples cannot be divided by the batch size ,data_iter What happens to the behavior of functions ?
The number of samples left at the end of execution cannot be divided , Will report a mistake
边栏推荐
- Soul, a social meta universe platform, rushed to Hong Kong stocks: Tencent is a shareholder with an annual revenue of 1.28 billion
- A case study of college entrance examination prediction based on multivariate time series
- 宝宝巴士创业板IPO被终止:曾拟募资18亿 唐光宇控制47%股权
- C语言中sprintf()函数的用法
- 配置基于接口的ARP表项限制和端口安全(限制用户私自接入傻瓜交换机或非法主机接入)
- P6774 [noi2020] tears in the era (block)
- 一年頂十年
- Changwan group rushed to Hong Kong stocks: the annual revenue was 289million, and Liu Hui had 53.46% voting rights
- 人生的开始
- Tech Talk 活动预告 | 基于Amazon KVS打造智能视觉产品
猜你喜欢

默认浏览器设置不了怎么办?

Day 18 of leetcode dynamic planning introduction
【Leetcode】14. 最長公共前綴
Digital IC hand tearing code -- voting device

Easy language ABCD sort
剑指 Offer 27. 二叉树的镜像

Sword finger offer 25 Merge two sorted linked lists

宝宝巴士创业板IPO被终止:曾拟募资18亿 唐光宇控制47%股权
Geoserver: publishing PostGIS data sources

Serial port controls steering gear rotation
随机推荐
Dgraph: large scale dynamic graph dataset
深度之眼(二)——矩阵及其基本运算
你想要的宏基因组-微生物组知识全在这(2022.7)
R及RStudio下载安装教程(超详细)
Yolov5 practice: teach object detection by hand
Cell:清华程功组揭示皮肤菌群的一种气味挥发物促进黄病毒感染宿主吸引蚊虫...
Ap和F107数据来源及处理
Changwan group rushed to Hong Kong stocks: the annual revenue was 289million, and Liu Hui had 53.46% voting rights
uboot的作用和功能
[leetcode] 14. Préfixe public le plus long
L'explosion de John utilise l'encodage d'entrée par défaut: UTF - 8 Loaded 1 password Hash (bcrypt [blowfish 32 / 64 X3])
剑指 Offer 21. 调整数组顺序使奇数位于偶数前面
有赞和腾讯云、阿里云一同摘得“中国企业云科技服务商50强”[通俗易懂]
Does digicert SSL certificate support Chinese domain name application?
Youzan won the "top 50 Chinese enterprise cloud technology service providers" together with Tencent cloud and Alibaba cloud [easy to understand]
How to transfer business data with BorgWarner through EDI?
The computer comes with software to make the background color of the picture transparent (matting white background)
LSF basic command
A case study of college entrance examination prediction based on multivariate time series
剑指 Offer 25. 合并两个排序的链表