当前位置:网站首页>自定义UDF函数
自定义UDF函数
2022-08-02 14:05:00 【大学生爱编程】
一.自定义UDF函数以及加载到Linux上运行
1.引入依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
注意:可能会出现引入依赖失败的情况,在settings文件中修改镜像
tab键与空格键的问题,此处用的是tab键开头,此点可能影响打包
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>spring-plugin</name>
<url>https://maven.aliyun.com/repository/spring-plugin</url>
</mirror>
2.写代码,继承UDF,导包,实现逻辑,在文件夹中把jar包上传到Linux上
3.打jar包上传到Linux (后面跟jar包的完整路径)
add jar /usr/local/soft/jars/HiveUDF2-1.0.jar;
4.使用jar包资源注册一个临时函数
create temporary function 函数名 as ‘主类名’;
create temporary function fxxx1 as 'MyUDF';
5.使用所起的函数名处理数据
二.实现函数永久生效
(继上面3步骤进行)
把jar包放到HDFS上,不用手动add jar 直接使用函数
1.hdfs上创建一个文件夹存放jar包,将jar包上传至该目录
2.在hive shell中执行命令
三个参数分别为:永久函数名,主类名,jar包在hdfs上的路径
create function hxudf as 'com.shujia.hivefun.MyUDF' using jar 'hdfs:/shujia/bigdata17/jar/hive-udf1.jar';
3.退出hive,执行函数进行测试
边栏推荐
猜你喜欢

![[ROS] (05) ROS Communication - Node, Nodes & Master](/img/f5/c541259b69a0db3dc15a61e87f0415.png)
随机推荐
每周招聘|PostgreSQL专家,年薪60+,高能力高薪资
数据的表示方法和转换(二进制、八进制、十进制、十六进制)
verilog学习|《Verilog数字系统设计教程》夏宇闻 第三版思考题答案(第十四章)
ABP,kendo后台接口,新增,查询
重新学习编程day1 【初始c语言】【c语言编写出计算两个数之和的代码】
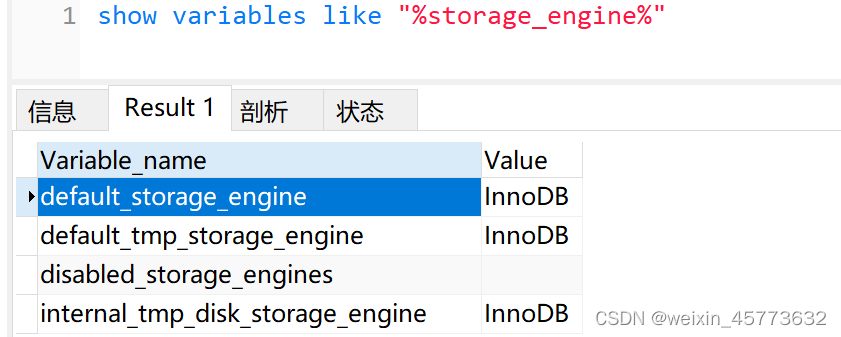
MySQL知识总结 (八) InnoDB的MVCC实现机制
uni-app页面、组件视图数据无法刷新问题的解决办法
Implementation of redis distributed lock and watchdog
C语言日记 6 基本输入/输出
鼠标右键菜单栏太长如何减少
执行栈和执行上下文
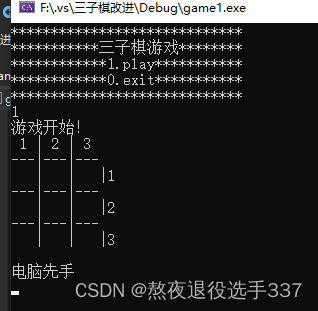
【c】小游戏---扫雷雏形
jwt (json web token)
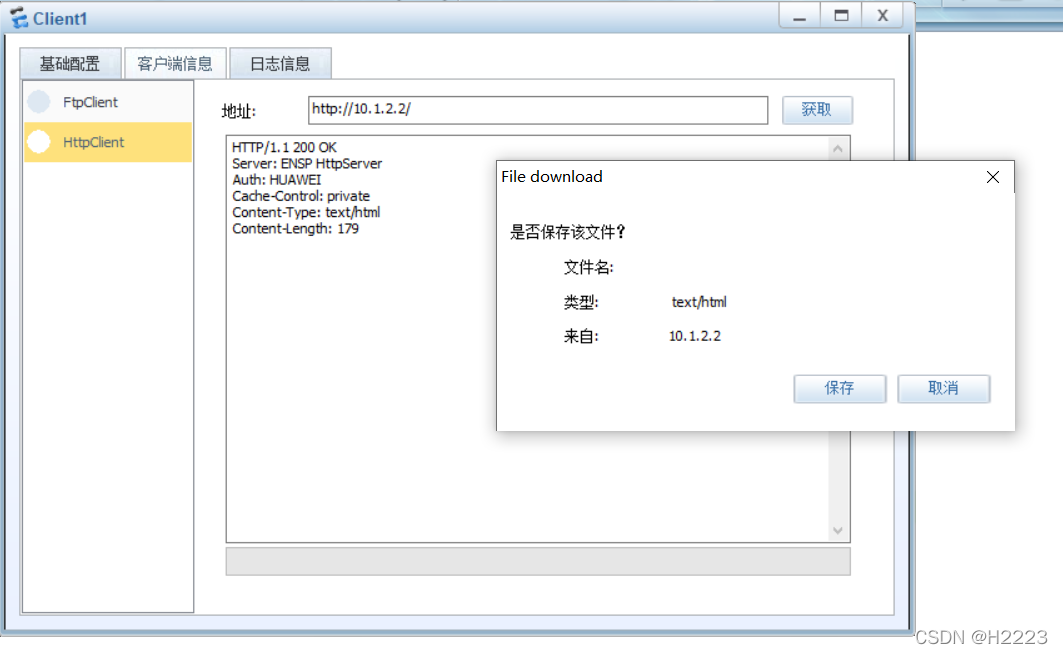
华为防火墙
MySQL知识总结 (十) 一条 SQL 的执行过程详解
Steps to connect the virtual machine with xshell_establish a network connection between the host and the vm virtual machine
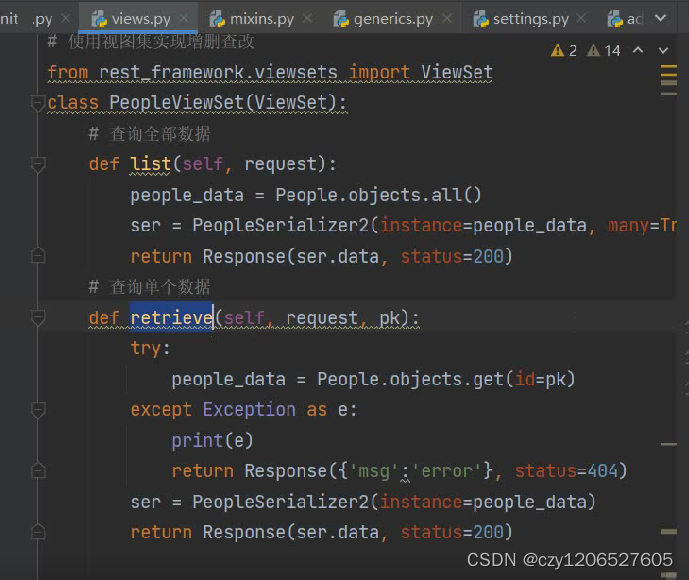
Unit 14 Viewsets and Routing
8580 Merge linked list
什么是 Web 3.0:面向未来的去中心化互联网
Tornado framework routing system introduction and (IOloop.current().start()) start source code analysis