当前位置:网站首页>python_scrapy_房天下
python_scrapy_房天下
2020-11-08 08:04:00 【osc_x4ot1joy】
scrapy-讲解
xpath选取节点常用的标签元素如下。
| 标记 | 描述 |
|---|---|
| extract | 提取内容转换为Unicode字符串,返回数据类型为list |
| / | 从根节点选取 |
| // | 匹配选择的当前节点选择文档中的节点 |
| . | 节点 |
| @ | 属性 |
| * | 任何元素节点 |
| @* | 任何属性节点 |
| node() | 任何类型的节点 |
爬取房天下-前奏
分析
1、网址:url:https://sh.newhouse.fang.com/house/s/。
2、确定爬取哪些数据:1)网页地址:page。2)所在位置名称:name。3)价格:price。4)地址:address。5)电话号码:tel
2、对网页进行分析。
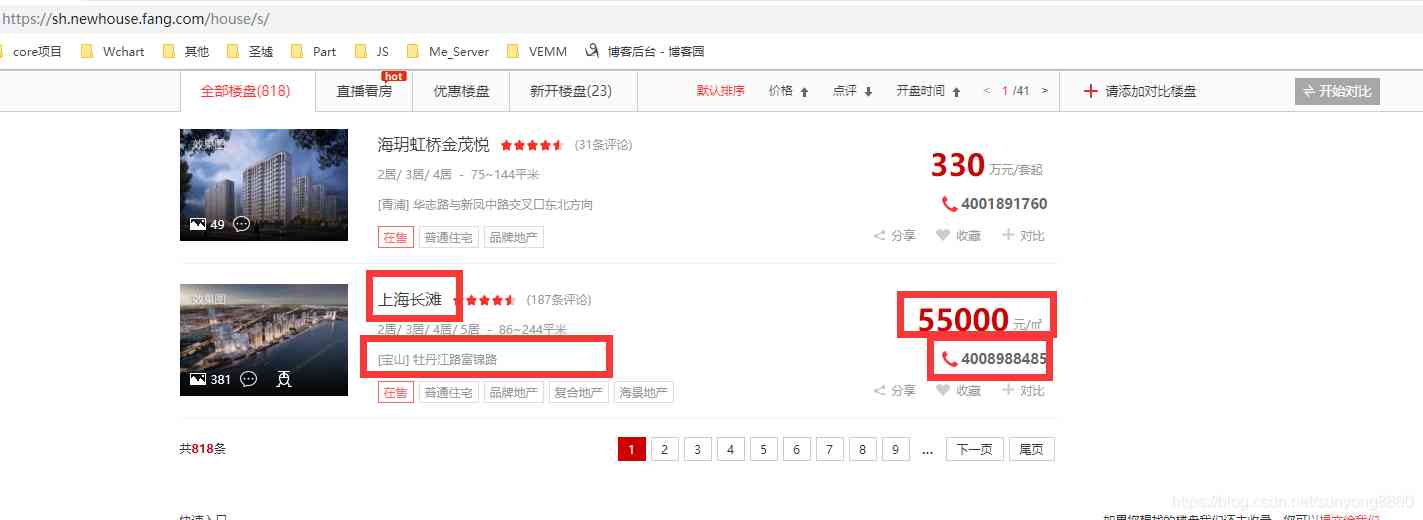
打开url后,可以看到我们需要的数据,然后可以看下面还是有分页的。
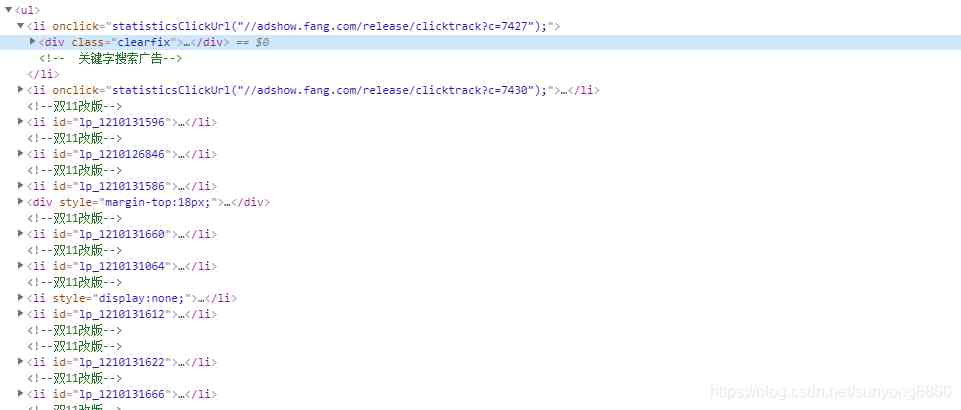
可以看到打开url后查看网页元素,我们所要的数据都在一对ul标签内。
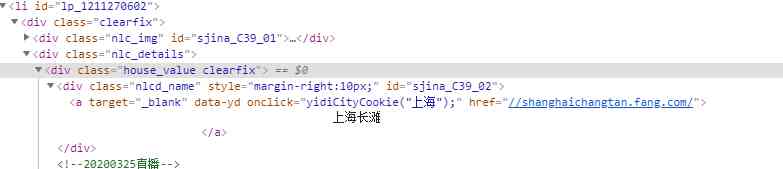
打开li一对标签,我们需要的name是在a标签下面的,而且在文本左右有不清楚的空格换行等需要特殊处理。
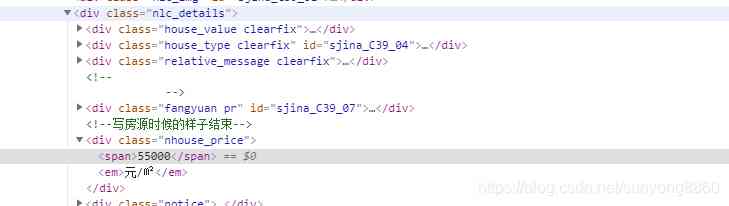
我们需要的price是在55000标签下面,注意,有的房子被买完了就没有价格显示,这个坑小心踩了。
一次类推我们可以找到对应的address和tel。
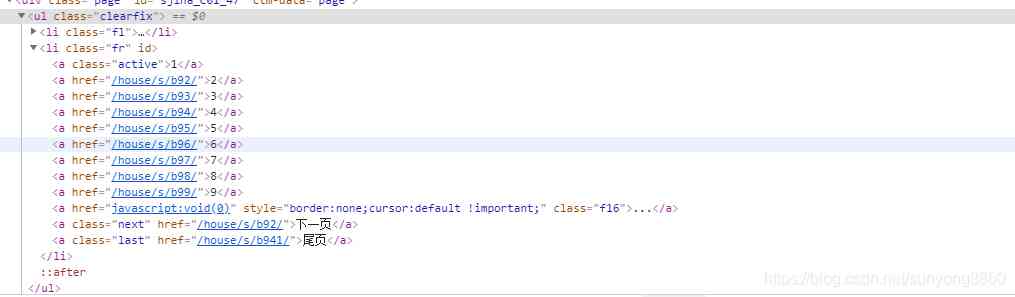
分页标签元素可以看到,当前页面的的a的class="active"。在打开主页面是a的文本是1,表示第一页。
爬取房天下-前具体实现过程
先新建scrapy项目
1)切换到项目文件夹:Terminal控制台上面输入 scrapy startproject hotel,hotel是演示的项目名称,可以根据自己需要自定义。
2)根据需要在items.py文件夹下配置参数。在分析中可知需要用到五个参数,分别是:page,name,price,address,tel。配置代码如下:
class HotelItem(scrapy.Item):
# 这里的参数要与爬虫实现的具体参数一一对应
page = scrapy.Field()
name = scrapy.Field()
price = scrapy.Field()
address = scrapy.Field()
tel = scrapy.Field()
3)新建我们的爬虫分支。切换到spiders文件夹,Terminal控制台上面输入 scrapy genspider house sh.newhouse.fang.comhouse是项目的爬虫名称,可以自定义,sh.newhouse.fang.com是爬取的区域选择。
在spider文件夹下面就有我们创建的house.py文件了。
代码实现与解释如下
import scrapy
from ..items import *
class HouseSpider(scrapy.Spider):
name = 'house'
# 爬取区域限制
allowed_domains = ['sh.newhouse.fang.com']
# 爬取的主页面
start_urls = ['https://sh.newhouse.fang.com/house/s/',]
def start_requests(self):
for url in self.start_urls:
# 回掉函数传的模块名称,没有括号。这是一种约定。
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
items = []
# 获取当前页面显示的值
for p in response.xpath('//a[@class="active"]/text()'):
# extract使提取内容转换为Unicode字符串,返回数据类型为list
currentpage=p.extract()
# 确定最后一页
for last in response.xpath('//a[@class="last"]/text()'):
lastpage=last.extract()
# 切换到最近一层的标签。//从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 /从根节点选取
for each in response.xpath('//div[@class="nl_con clearfix"]/ul/li/div[@class="clearfix"]/div[@class="nlc_details"]'):
item=HotelItem()
# 名称
name=each.xpath('//div[@class="house_value clearfix"]/div[@class="nlcd_name"]/a/text()').extract()
# 价格
price=each.xpath('//div[@class="nhouse_price"]/span/text()').extract()
# 地址
address=each.xpath('//div[@class="relative_message clearfix"]/div[@class="address"]/a/@title').extract()
# 电话
tel=each.xpath('//div[@class="relative_message clearfix"]/div[@class="tel"]/p/text()').extract()
# 所有item里面参数要与我们items里面参数意义对应
item['name'] = [n.replace(' ', '').replace("\n", "").replace("\t", "").replace("\r", "") for n in name]
item['price'] = [p for p in price]
item['address'] = [a for a in address]
item['tel'] = [s for s in tel]
item['page'] = ['https://sh.newhouse.fang.com/house/s/b9'+(str)(eval(p.extract())+1)+'/?ctm=1.sh.xf_search.page.2']
items.append(item)
print(item)
# 当爬取到最后一页,类标签last就自动切换成首页
if lastpage=='首页':
pass
else:
# 如果不是最后一页,继续爬取下一页数据,知道爬完所有数据
yield scrapy.Request(url='https://sh.newhouse.fang.com/house/s/b9'+(str)(eval(currentpage)+1)+'/?ctm=1.sh.xf_search.page.2', callback=self.parse)
4)在spiders下运行爬虫,Terminal控制台上面输入 scrapy crawl house。
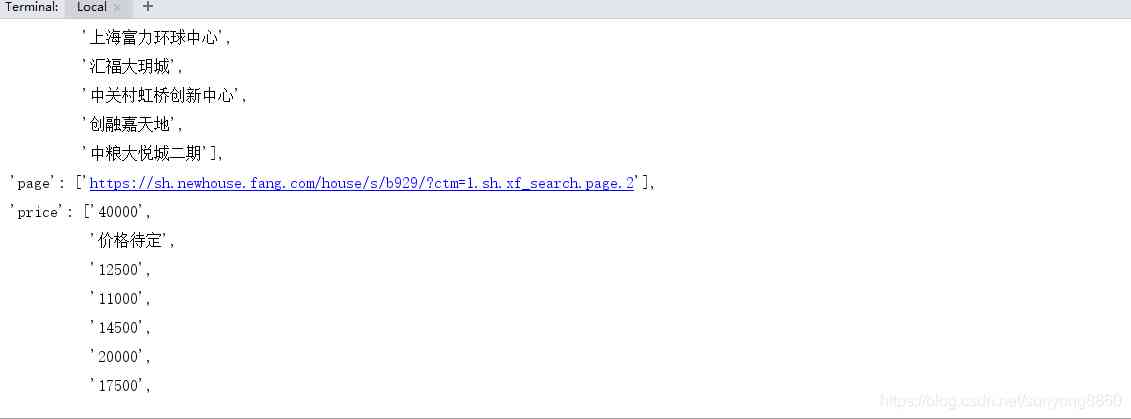
结果如下图所示
整体项目结构如右图tts文件夹是我这边用于存储数据的的txt文件。本项目里面可以不需要。

如有发现错误请联系微信:sunyong8860
python的路上爬着前行
版权声明
本文为[osc_x4ot1joy]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4383219/blog/4707854
边栏推荐
- The real-time display of CPU and memory utilization rate by Ubuntu
- Macquarie Bank drives digital transformation with datastex enterprise (DSE)
- 接口
- sed之查找替换
- Blazor 准备好为企业服务了吗?
- Android Basics - RadioButton (radio button)
- 你的主机中的软件中止了一个已建立的连接。解决方法
- 0.计算机简史
- 16. File transfer protocol, vsftpd service
- [solution] distributed timing task solution
猜你喜欢

C / C + + Programming Notes: what are the advantages of C compared with other programming languages?

2020-11-07:已知一个正整数数组,两个数相加等于N并且一定存在,如何找到两个数相乘最小的两个数?
Wechat nickname Emoji expression, special expression causes the list not to be displayed, export excel error report and other problems solved!
QT hybrid Python development technology: Python introduction, hybrid process and demo
Hand tearing algorithm - handwritten singleton mode
leetcode之判断路径是否相交
数据科学面试应关注的6个要点
Privacy violation and null dereference of fortify vulnerability
GoLand writes a program with template

More than 50 object detection datasets from different industries
随机推荐
解决RabbitMQ消息丢失与重复消费问题
Visual studio 2015 unresponsive / stopped working problem resolution
What details does C + + improve on the basis of C
Solve the problem of rabbitmq message loss and repeated consumption
C++基础知识篇:C++ 基本语法
Problems of Android 9.0/p WebView multi process usage
Judging whether paths intersect or not by leetcode
The software in your host has terminated an established connection. resolvent
Adobe Prelude /Pl 2020软件安装包(附安装教程)
C/C++编程笔记:C语言相比其他编程语言,有什么不一样的优势?
什么你的电脑太渣?这几招包你搞定! (Win10优化教程)
China Telecom announces 5g SA commercial scale in 2020
Web Security (4) -- XSS attack
Get tree menu list
Application of bidirectional LSTM in outlier detection of time series
Summary of knowledge points of Jingtao project
Cryptography - Shangsi Valley
IOS learning note 2 [problems and solutions encountered during the installation and use of cocopods] [update 20160725]
双向LSTM在时间序列异常值检测的应用
Data structure and sorting algorithm