当前位置:网站首页>动手学深度学习_AlexNet
动手学深度学习_AlexNet
2022-08-04 15:53:00 【CV小Rookie】
深度卷积网络的开山鼻祖应该就是 AlexNet ,虽然在我们看来仅仅是比 LeNet 也就是多了那么几层卷积等等,但架不住一下就在 ImageNet 比赛上大放光彩,当然其中还有其他的一些贡献也非常重要。
啥是 ImageNet 呢?ImageNet项目是一个用于视觉对象识别软件研究的大型可视化数据库。超过1400万的图像URL被ImageNet手动注释,以指示图片中的对象;在至少一百万个图像中,还提供了边界框。ImageNet包含2万多个类别; [2]一个典型的类别,如“气球”或“草莓”,包含数百个图像。第三方图像URL的注释数据库可以直接从ImageNet免费获得;但是,实际的图像不属于ImageNet。自2010年以来,ImageNet项目每年举办一次软件比赛,即ImageNet大规模视觉识别挑战赛(ILSVRC),软件程序竞相正确分类检测物体和场景。 ImageNet挑战使用了一个“修剪”的1000个非重叠类的列表。2012年在解决ImageNet挑战方面取得了巨大的突破,被广泛认为是2010年的深度学习革命的开始。(来自百度百科,不多赘述,直接看网络结构与实现)
AlexNet
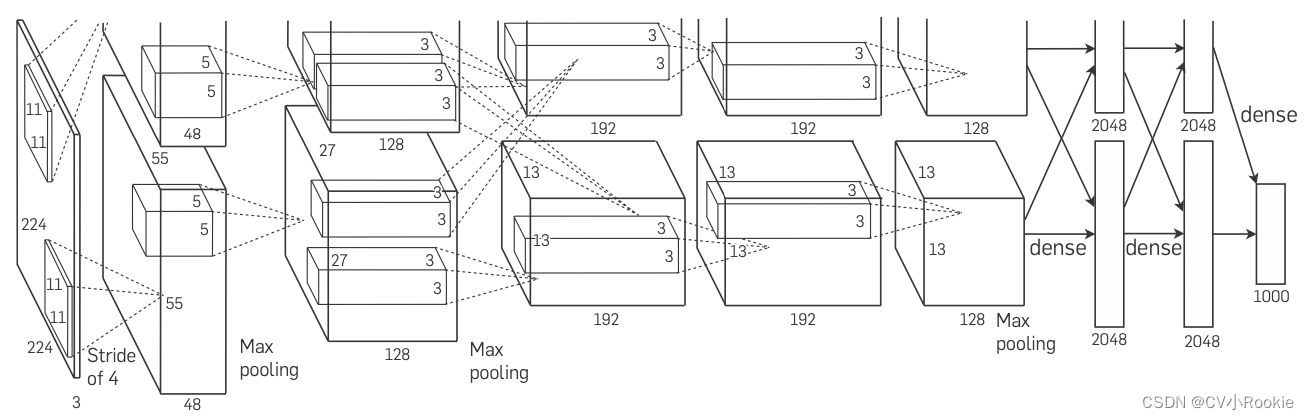
图中上下两条“路”,因为 AlexNet 作者 Alex Krizhevsky 和 Ilya Sutskever 意识到卷积神经网络中的计算瓶颈:卷积和矩阵乘法,都是可以在硬件上并行化的操作。 于是,他们使用两个显存为3GB的NVIDIA GTX580 GPU实现了快速卷积运算。这上下两路也就是放在不同GPU上进行运算,在这里我们仅仅做一个简单版的 AlexNet 。
ReLU 激活函数
AlexNet 将 sigmoid 激活函数改为更简单的 ReLU 激活函数。 一方面,ReLU 激活函数的计算更简单,它不需要如 sigmoid 激活函数那般复杂的求幂运算。 另一方面,当使用不同的参数初始化方法时,ReLU 激活函数使训练模型更加容易。 当 sigmoid 激活函数的输出非常接近于 0 或 1 时,这些区域的梯度几乎为 0 ,因此反向传播无法继续更新一些模型参数。 相反,ReLU 激活函数在正区间的梯度总是 1 。 因此,如果模型参数没有正确初始化,sigmoid 函数可能在正区间内得到几乎为 0 的梯度,从而使模型无法得到有效的训练。
Dropout
LexNet通过 Dropout 控制全连接层的模型复杂度,而 LeNet 只使用了权重衰减。 为了进一步扩充数据,AlexNet 在训练时增加了大量的图像增强数据,如翻转、裁切和变色。 这使得模型更健壮,更大的样本量有效地减少了过拟合。
# 作者 :CV小Rookie
# 创建时间: 2022/8/4 13:52
# 文件名: train.py
import torch
from torch import nn
from d2l import torch as d2l
from download_datas import *
def get_default_device():
if torch.cuda.is_available():
return 'cuda'
elif getattr (torch.backends, 'mps', None) is not None and torch.backends.mps.is_available():
return 'mps'
else:
return 'cpu'
device = get_default_device()
net = nn.Sequential(
# 这里,我们使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))
X = torch.rand(size=(1, 1, 224, 224), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)
print(net)
batch_size = 256
train_iter, test_iter = load_data_mnist(batch_size=batch_size, resize=224)
# train_iter, test_iter = load_data_fashion_mnist(batch_size=batch_size)
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
def train(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
torch.save(net.state_dict(), "module-{0}.pth".format(epoch))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
lr, num_epochs = 0.01, 10
train(net, train_iter, test_iter, num_epochs, lr, device)Conv2d output shape: torch.Size([1, 96, 54, 54])
ReLU output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Conv2d output shape: torch.Size([1, 256, 26, 26])
ReLU output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 256, 12, 12])
ReLU output shape: torch.Size([1, 256, 12, 12])
MaxPool2d output shape: torch.Size([1, 256, 5, 5])
Flatten output shape: torch.Size([1, 6400])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
再次强调如果想用 ImageNet 训练的话,最后的线性层改为 1000 即可,这里用了 MNIST 进行训练,所以改成了 10 分类。
边栏推荐
猜你喜欢
MySQL当前读、快照读、MVCC
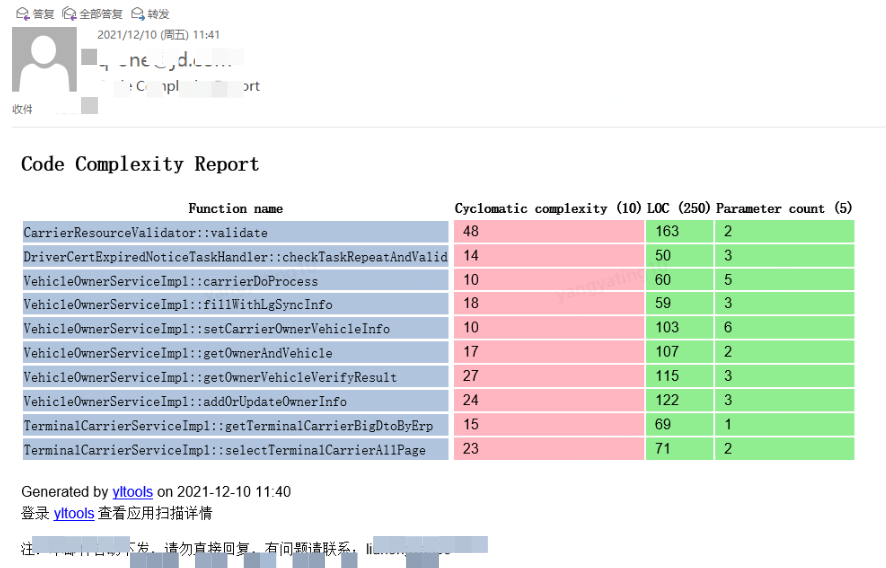
重构指标之如何监控代码圈复杂度
JVM调优-GC基本原理和调优关键分析
What is the difference between ITSM software and a work order system?

NFT blind box mining system dapp development NFT chain game construction
Manacher(求解最长回文子串)
remote: Check Access Error, please check your access right or username and password!fatal: Authenti
js判断一个对象是否在一个对象数组中
解决dataset.mnist无法加载进去的情况
JVM Tuning-GC Fundamentals and Tuning Key Analysis
随机推荐
Real-Time Rendering 4th related resource arrangement (no credit required)
《2022 年上半年全球独角兽企业发展研究报告》发布——DEMO WORLD世界创新峰会圆满落幕
Go 事,如何成为一个Gopher ,并在7天找到 Go 语言相关工作,第1篇
Xi'an Zongheng Information × JNPF: Adapt to the characteristics of Chinese enterprises, fully integrate the cost management and control system
软考 --- 软件工程(2)软件开发方法
可视化大屏丑?这篇文章教你如何做美观大屏!
项目里的各种配置,你都了解吗?
你一定从未看过如此通俗易懂的YOLO系列(从v1到v5)模型解读
numpy入门详细代码
一文解答DevOps平台的制品库是什么
JVM调优-GC基本原理和调优关键分析
C#命令行解析工具
ITSM软件与工单系统的区别是什么?
HyperBDR云容灾深度解析一:云原生跨平台容灾,让数据流转更灵活
有哪些好用的IT资产管理平台?
学 Go,最常用的技能是什么?打日志
LeetCode·每日一题·1403.非递增顺序的最小子序列·贪心
【Gopher 学个函数】边学边练,简单为 Go 上个分
5 基本引用类型
Crawler Xiaobai Notes (yesterday's supplement to pay attention to parsing data)