当前位置:网站首页>Base du réseau neuronal de convolution d'apprentissage profond (CNN)
Base du réseau neuronal de convolution d'apprentissage profond (CNN)
2022-07-05 19:43:00 【Quand la pluie tombe】
Catalogue des articles
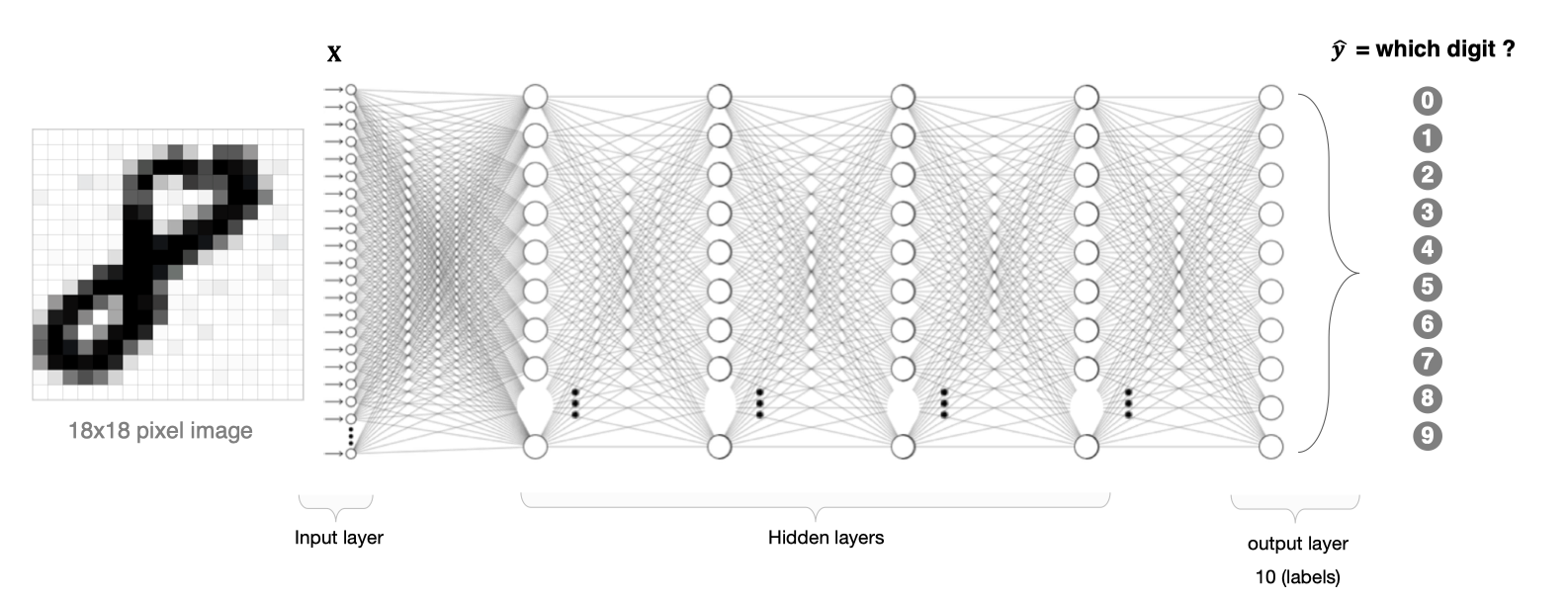
Le traitement d'images à l'aide d'un réseau neuronal entièrement connecté pose deux problèmes:
- Grande quantité de données à traiter,Faible efficacité
Si on s'occupait d'un 1000×1000 Image en pixels,Les paramètres sont les suivants::
1000×1000×3=3,000,000
.Une telle quantité de données consomme beaucoup de ressources
- Il est difficile de conserver les caractéristiques originales de l'image lors de l'ajustement dimensionnel ,La précision du traitement de l'image n'est pas élevée
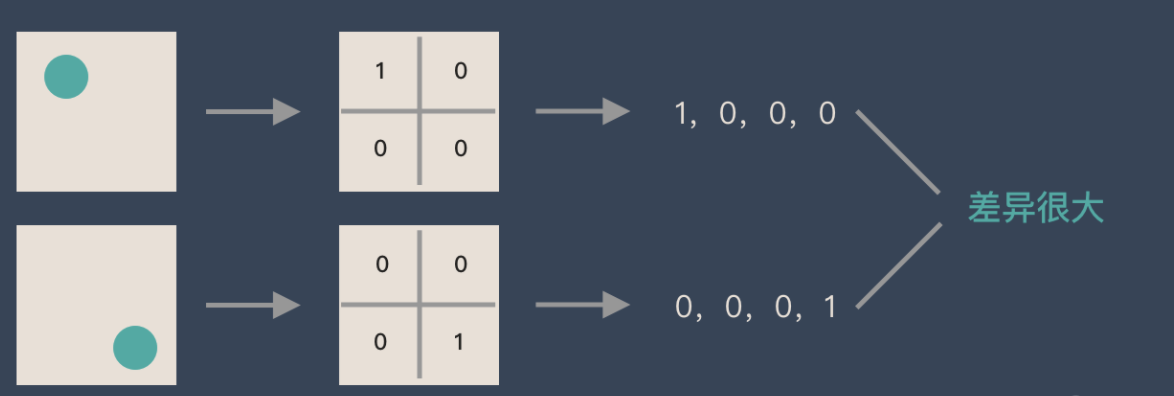
Si un cercle est1,Aucun cercle n'est0,Les différentes positions des cercles produisent des représentations de données complètement différentes. Mais du point de vue de l'image, ,Contenu de l'image(Nature)Il n'y a pas eu de changement.,Il y a eu un changement de position..Donc quand on déplace des objets dans l'image, Les résultats obtenus avec des ascenseurs entièrement connectés varieront considérablement ,Ceci n'est pas conforme aux exigences du traitement d'image.
1. CNNComposition du réseau
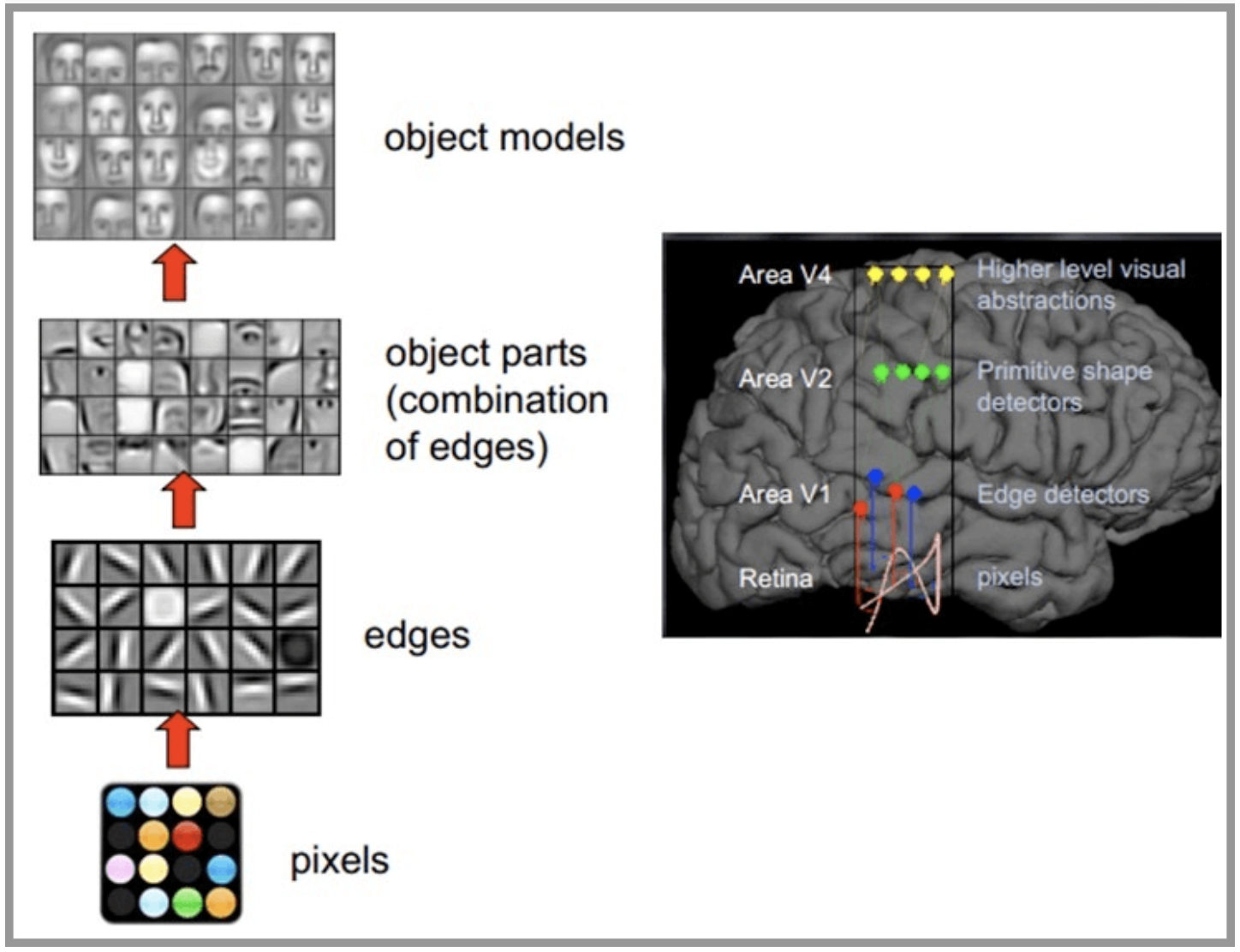
CNN Le réseau s'inspire du système nerveux visuel humain , Les principes de la vision humaine :En commençant par l'ingestion du signal original(Pixels d'ingestion pupillaire Pixels),Ensuite, faites le traitement préliminaire(Certaines cellules du cortex cérébral trouvent des bords et des directions),Puis abstrait(Le cerveau décide,La forme de l'objet devant,C'est circulaire),Et puis plus abstrait( Le cerveau décide en outre que l'objet est un visage humain ).Voici un exemple de reconnaissance faciale par le cerveau humain:
CNN Le réseau se compose principalement de trois parties: :Couche de convolution、 Composition de la couche de mise en commun et de la couche de raccordement complète , Où la couche de convolution est chargée d'extraire les caractéristiques locales de l'image ;La couche de mise en commun est utilisée pour réduire considérablement l'échelle des paramètres(Dimension réduite); Une partie de la couche de connexion complète qui ressemble à un réseau neuronal artificiel ,Utilisé pour produire les résultats souhaités.

ToutCNNLa structure du réseau est illustrée ci - dessous:

2. Couche de convolution
La couche de convolution est le module central du réseau neuronal de convolution , Le but de la couche de convolution est d'extraire les caractéristiques de la carte des caractéristiques d'entrée ,Comme le montre la figure ci - dessous, Le noyau de convolution peut extraire l'information de bord de l'image .

2.1 Méthode de calcul de la convolution
Comment calculer la convolution? ?
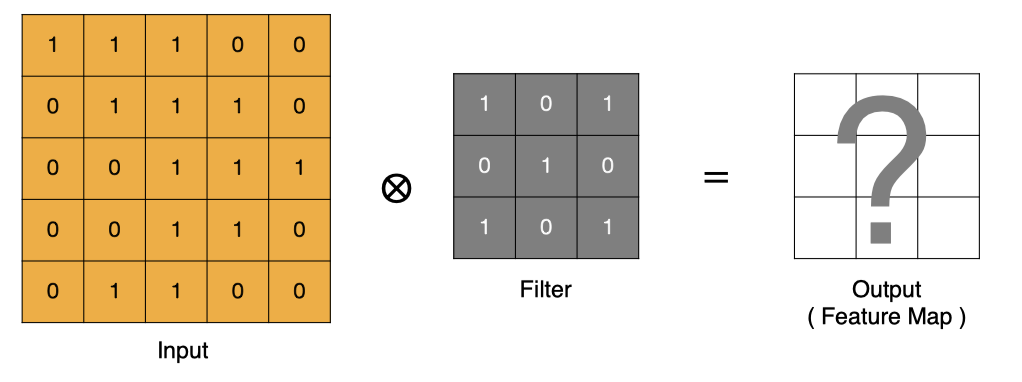
.L'opération de convolution consiste essentiellement à faire un produit ponctuel entre la zone locale du filtre et les données d'entrée .
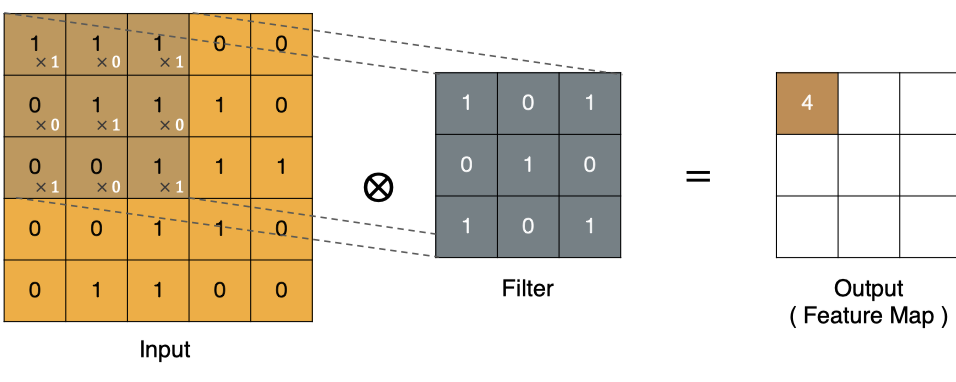
Méthode de calcul du coin supérieur gauche :
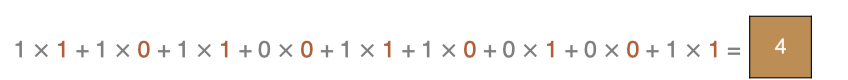
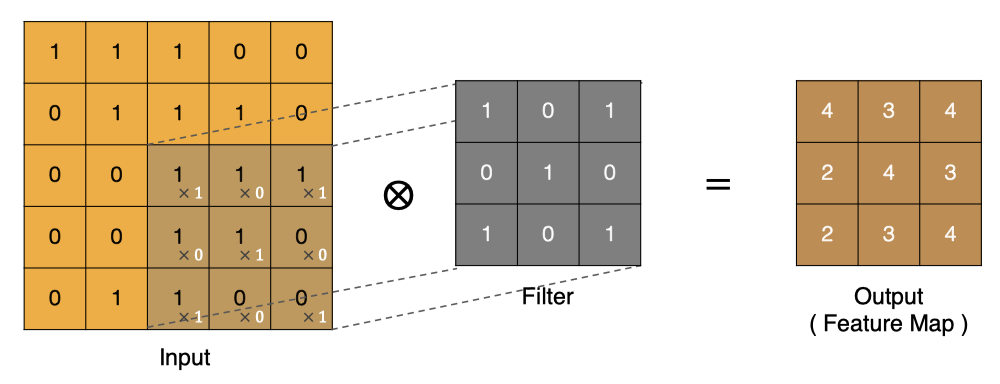
D'autres points peuvent être calculés de la même manière , Obtenir le résultat final de la convolution ,
Le dernier point est calculé comme suit: :
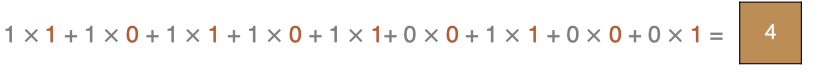
2.2 padding
Dans le processus de convolution décrit ci - dessus , Le graphique des caractéristiques est beaucoup plus petit que le graphique original , On peut faire le tour de l'image originale padding, Pour s'assurer que la taille de la carte caractéristique reste la même pendant le processus de convolution .
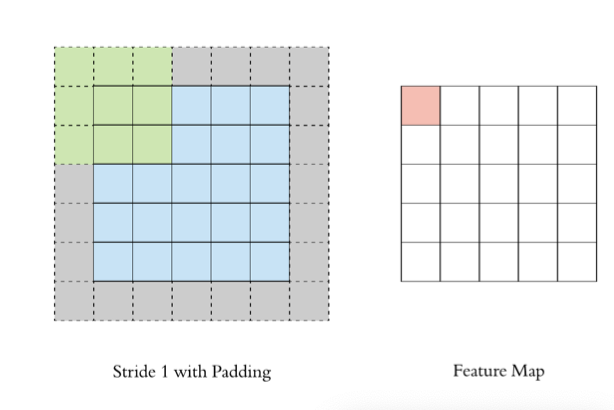
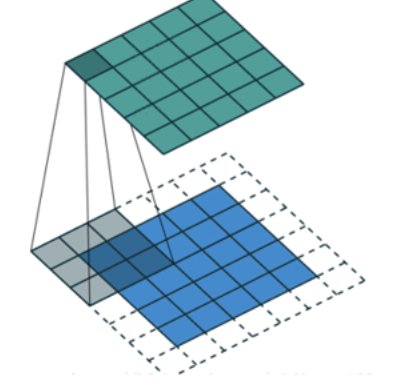
2.3 stride
Par paliers1 Pour déplacer le noyau de convolution , Les caractéristiques calculées sont les suivantes: :

Si nous mettonsstrideAugmentation,Par exemple, régler à2, Il est également possible d'extraire des graphiques de caractéristiques ,Comme le montre la figure ci - dessous:

2.4 Convolution multicanale
En réalité, les images sont composées de plusieurs canaux , Comment calculer la convolution ?
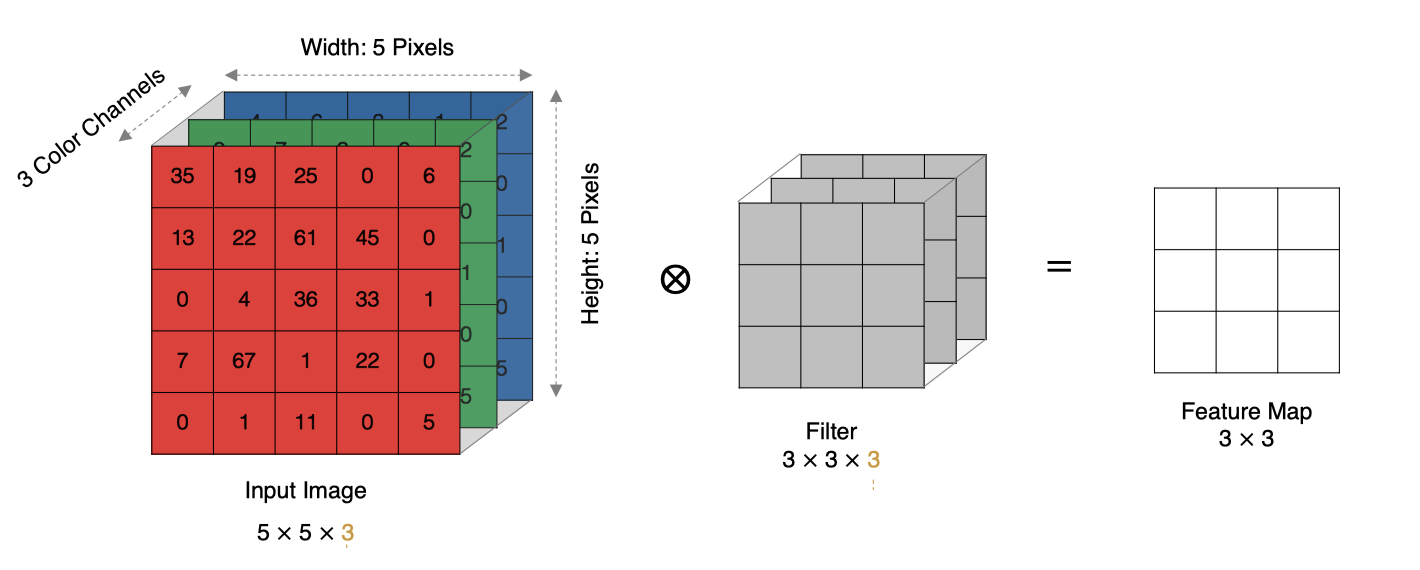
La méthode de calcul est la suivante:: Lorsque l'entrée a plusieurs canaux (channel)Heure( Par exemple, une image peut avoir RGB Trois canaux), Le noyau convolutif doit avoir le même channelNombre,Chaque noyau de convolution channel Correspondance avec la couche d'entrée channel Convolution,Chaque channel Les résultats de convolution sont additionnés bitwise pour obtenir le résultat final Feature Map
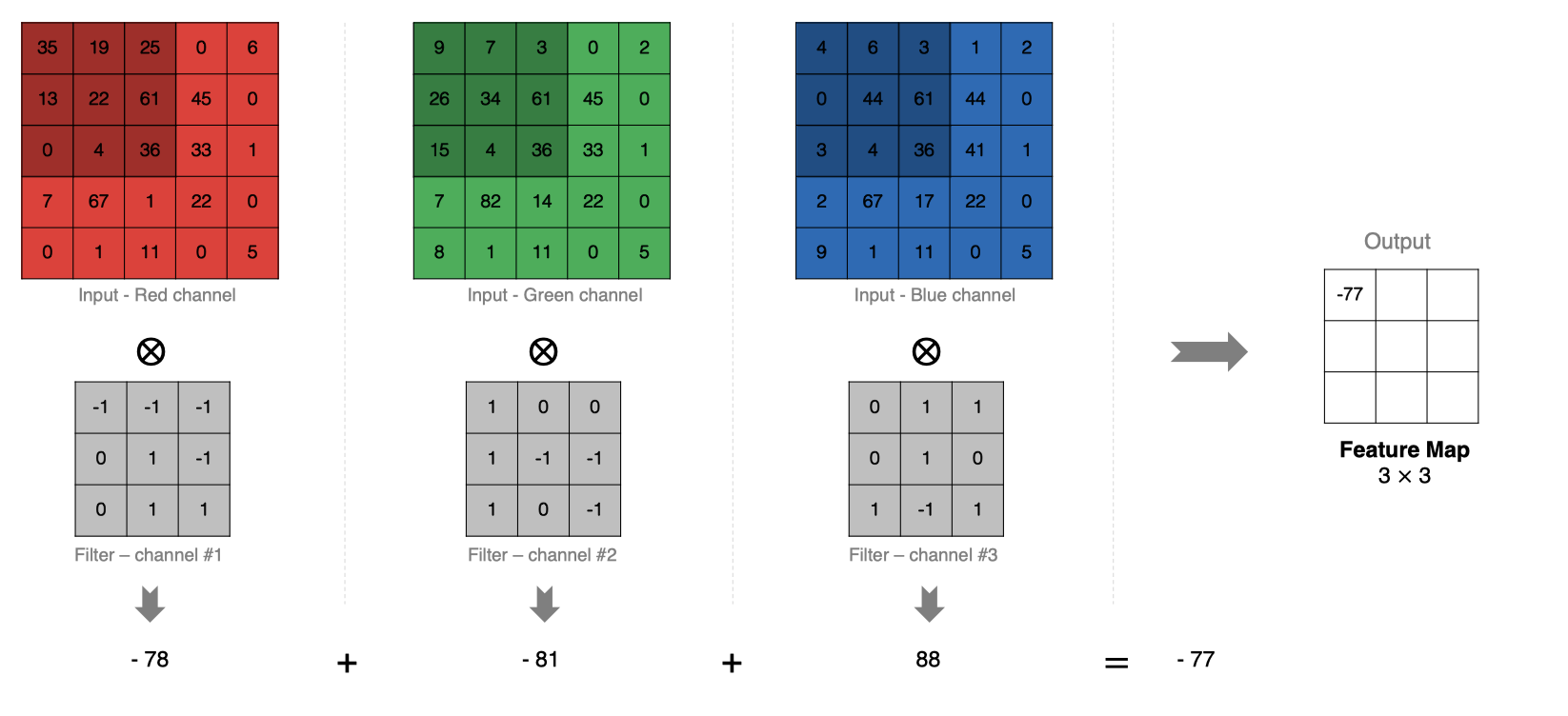
2.5 Convolution du noyau Multi - convolution
Comment calculer s'il y a plus d'un noyau de convolution ? Quand il y a plusieurs noyaux de convolution , Chaque noyau de convolution apprend des caractéristiques différentes , La génération correspondante contient plusieurs channel De Feature Map, Par exemple, il y a deux filter,Alors... output Il y en a deux. channel.
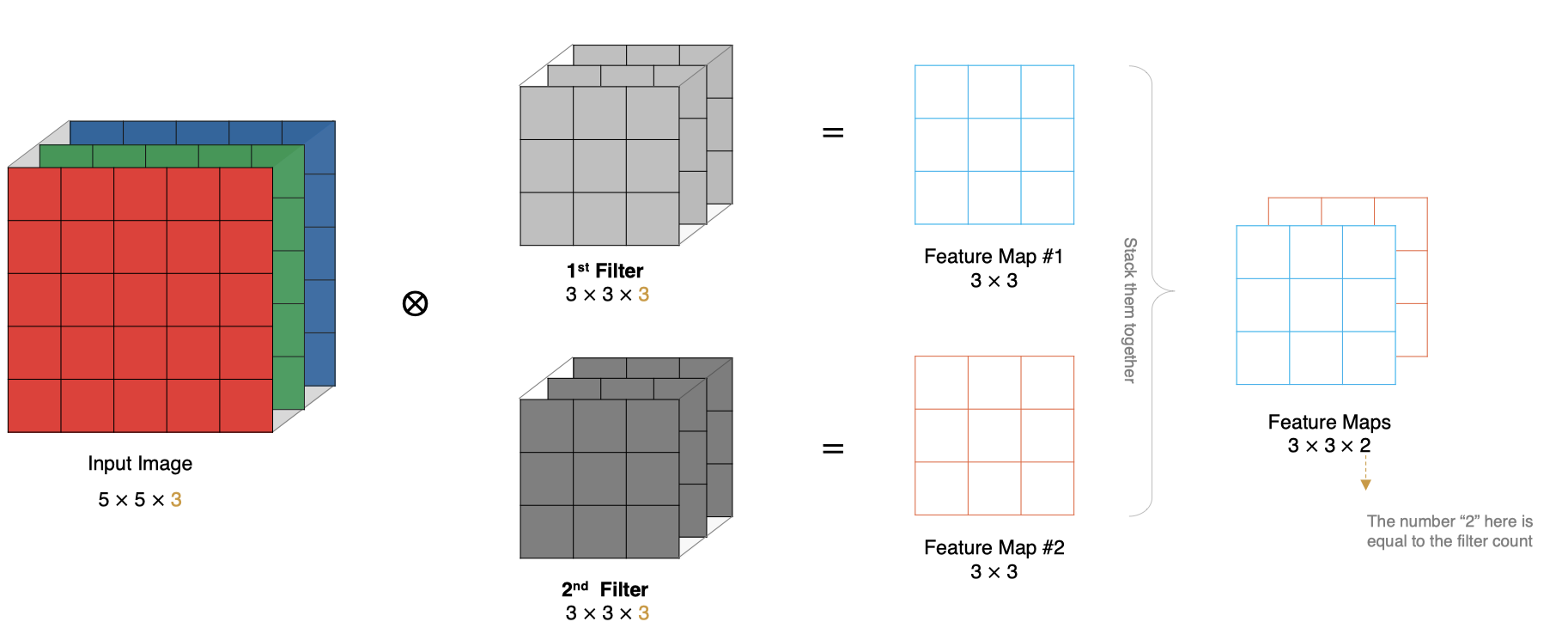
2.6 Taille de la carte des caractéristiques
La taille des caractéristiques de sortie dépend des paramètres suivants : * size:Noyau de convolution/Taille du filtre, Normalement sélectionné comme impair ,Par exemple, il y a1 * 1, 3 * 3, 5 * 5 * padding: Mode de remplissage zéro * stride:Étapes
La méthode de calcul est la suivante: :

Le diagramme des caractéristiques d'entrée est 5x5,Le noyau de convolution est3x3,Pluspadding Pour1, La taille de sortie est :
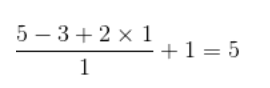
Comme le montre la figure ci - dessous:
Intf.keras Réalisation et utilisation du noyau de convolution moyen
tf.keras.layers.Conv2D(
filters, kernel_size, strides=(1, 1), padding='valid',
activation=None
)
Les principaux paramètres sont décrits comme suit::

3. Couche de mise en commun(Pooling)
La couche de mise en commun se dirige vers une réduction de la dimension d'entrée de la couche réseau suivante , Réduire la taille du modèle ,Augmenter la vitesse de calcul,Et a augmentéFeature Map Robustesse,Prévention de l'ajustement excessif,
Il échantillonne principalement les caractéristiques apprises de la couche de convolution (subsampling)Traitement,Il se compose principalement de deux
3.1 Mise en commun maximale
Max Pooling, Prend la valeur maximale dans la fenêtre comme sortie , Cette méthode est largement utilisée .

Intf.keras La méthode mise en œuvre dans :
tf.keras.layers.MaxPool2D(
pool_size=(2, 2), strides=None, padding='valid'
)
Paramètres:
pool_size: Taille de la fenêtre de mise en commun
strides: L'étape du déplacement de la fenêtre ,Par défaut1
padding: Si le remplissage est effectué , La valeur par défaut n'est pas remplie
3.2 Mise en commun moyenne
Avg Pooling, Prenez la moyenne de toutes les valeurs dans la fenêtre comme sortie
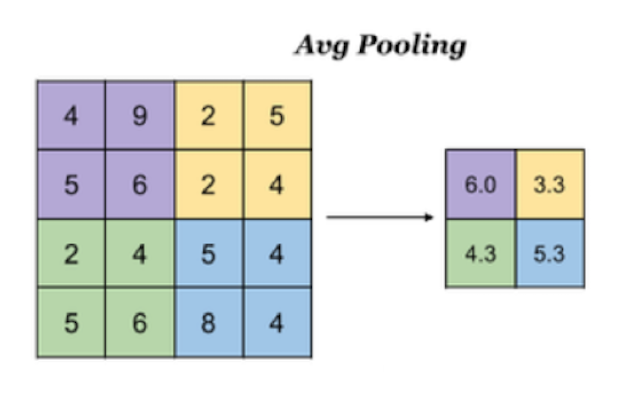
Intf.keras La méthode de mise en commun est la suivante: :
tf.keras.layers.AveragePooling2D(
pool_size=(2, 2), strides=None, padding='valid'
)
4. Couche de connexion complète
La couche de connexion complète est située à CNN Fin du réseau , Après extraction des caractéristiques de la couche de convolution et réduction des dimensions de la couche de mise en commun , L'opération de conversion d'un graphique caractéristique en vecteur unidimensionnel dans une couche de connexion complète pour la classification ou la régression .
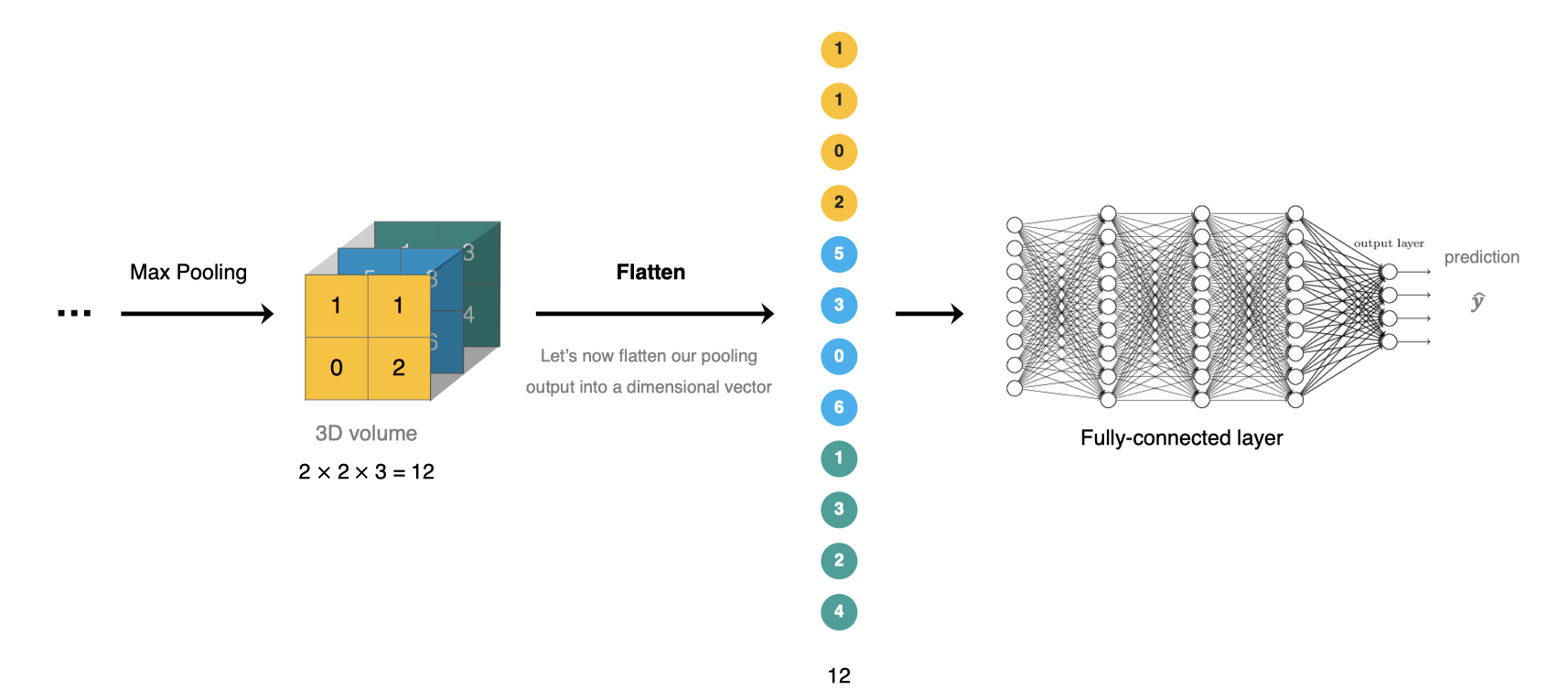
Intf.keras Utilisation de la couche de connexion moyenne complète tf.keras.denseRéalisation.
5.Construction d'un réseau neuronal convolutif
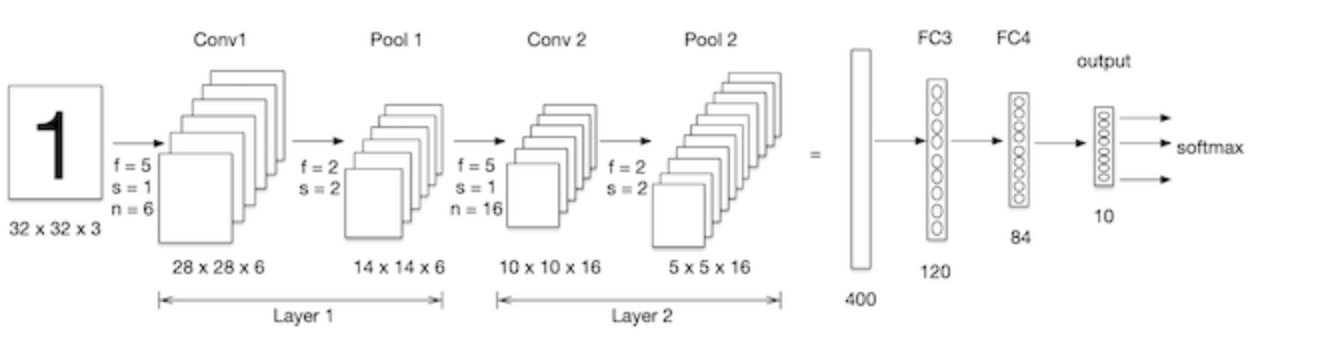
Nous construisons un réseau neuronal convolutif mnist Traitement sur un ensemble de données ,Comme le montre la figure ci - dessous:LeNet-5C'est un réseau neuronal convolutif plus simple, Image 2D saisie, Passe d'abord par deux couches de convolution ,Couche de mise en commun,Et à travers toute la couche de connexion,Utilisation finalesoftmaxClassification comme couche de sortie.
Importer un kit:
import tensorflow as tf
# Ensemble de données
from tensorflow.keras.datasets import mnist
5.1 Chargement des données
Compatible avec le cas du réseau neuronal ,Charger d'abord l'ensemble de données:
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
5.2 Traitement des données
Les exigences d'entrée pour les réseaux neuronaux convolutifs sont :NHWC ,Nombre d'images,Hauteur de l'image, Largeur de l'image et canal de l'image , Parce que c'est un graphique gris ,Le canal est1.
# Traitement des données:num,h,w,c
# Données de l'ensemble de formation
train_images = tf.reshape(train_images, (train_images.shape[0],train_images.shape[1],train_images.shape[2], 1))
print(train_images.shape)
# Données de l'ensemble d'essai
test_images = tf.reshape(test_images, (test_images.shape[0],test_images.shape[1],test_images.shape[2], 1))
Les résultats sont les suivants::
(60000, 28, 28, 1)
5.3 Modélisation
Lenet-5 Image 2D entrée du modèle , Passe d'abord par deux couches de convolution ,Couche de mise en commun,Et à travers toute la couche de connexion,Utilisation finalesoftmaxClassification comme couche de sortie, Le modèle est construit comme suit :
# Construction de modèles
net = tf.keras.models.Sequential([
# Couche de convolution:6- Oui.5*5Noyau de convolution,Activation ouisigmoid
tf.keras.layers.Conv2D(filters=6,kernel_size=5,activation='sigmoid',input_shape= (28,28,1)),
# Mise en commun maximale
tf.keras.layers.MaxPool2D(pool_size=2, strides=2),
# Couche de convolution:16- Oui.5*5Noyau de convolution,Activation ouisigmoid
tf.keras.layers.Conv2D(filters=16,kernel_size=5,activation='sigmoid'),
# Mise en commun maximale
tf.keras.layers.MaxPool2D(pool_size=2, strides=2),
# Dimension ajustée à 1Données dimensionnelles
tf.keras.layers.Flatten(),
# Lamination complète,Activationsigmoid
tf.keras.layers.Dense(120,activation='sigmoid'),
# Lamination complète,Activationsigmoid
tf.keras.layers.Dense(84,activation='sigmoid'),
# Lamination complète,Activationsoftmax
tf.keras.layers.Dense(10,activation='softmax')
])
Nous passonsnet.summary()Voir la structure du réseau:
Model: "sequential_11"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 24, 24, 6) 156
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 12, 12, 6) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 16) 2416
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 4, 4, 16) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 256) 0
_________________________________________________________________
dense_25 (Dense) (None, 120) 30840
_________________________________________________________________
dense_26 (Dense) (None, 84) 10164
dense_27 (Dense) (None, 10) 850
=================================================================
Total params: 44,426
Trainable params: 44,426
Non-trainable params: 0
______________________________________________________________
La taille de l'image d'entrée numérique manuscrite est 28x28x1,Comme le montre la figure ci - dessous:, Regardons les paramètres de la couche de convolution inférieure :
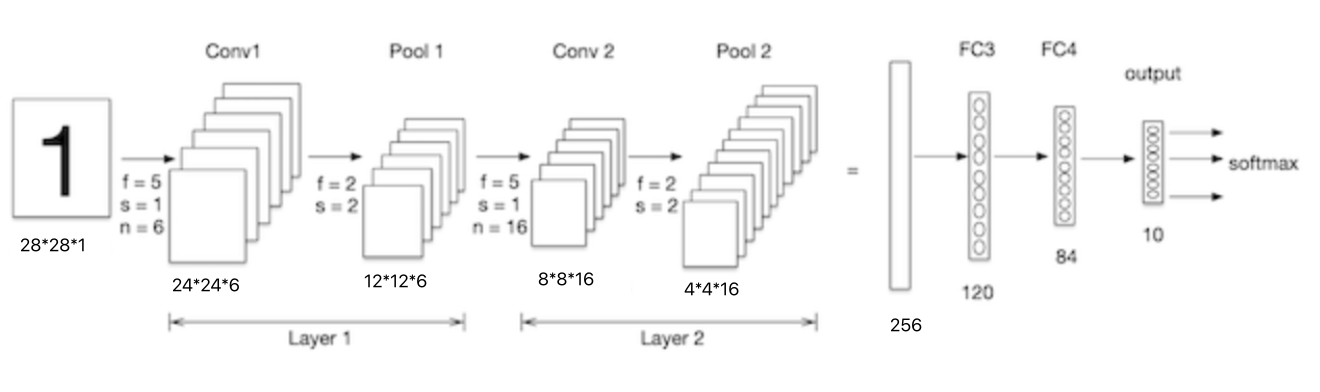
conv1 Le noyau de convolution est 5x5x1,Le nombre de noyaux de convolution est6, Chaque noyau de convolution a un bias, Donc la quantité de paramètre est :5x5x1x6+6=156.
conv2 Le noyau de convolution est 5x5x6,Le nombre de noyaux de convolution est16, Chaque noyau de convolution a un bias, Donc la quantité de paramètre est :5x5x6x16+16 = 2416.
5.4 Compilation du modèle
Définir les fonctions d'optimisation et de perte:
# Optimizer
optimizer = tf.keras.optimizers.SGD(learning_rate=0.9)
# Compilation du modèle:Fonction de perte, Optimiseurs et indicateurs d'évaluation
net.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
5.5 Formation sur modèle
Formation sur modèle:
# Formation sur modèle
net.fit(train_images, train_labels, epochs=5, validation_split=0.1)
Processus de formation:
Epoch 1/5
1688/1688 [==============================] - 10s 6ms/step - loss: 0.8255 - accuracy: 0.6990 - val_loss: 0.1458 - val_accuracy: 0.9543
Epoch 2/5
1688/1688 [==============================] - 10s 6ms/step - loss: 0.1268 - accuracy: 0.9606 - val_loss: 0.0878 - val_accuracy: 0.9717
Epoch 3/5
1688/1688 [==============================] - 10s 6ms/step - loss: 0.1054 - accuracy: 0.9664 - val_loss: 0.1025 - val_accuracy: 0.9688
Epoch 4/5
1688/1688 [==============================] - 11s 6ms/step - loss: 0.0810 - accuracy: 0.9742 - val_loss: 0.0656 - val_accuracy: 0.9807
Epoch 5/5
1688/1688 [==============================] - 11s 6ms/step - loss: 0.0732 - accuracy: 0.9765 - val_loss: 0.0702 - val_accuracy: 0.9807
5.6 Évaluation du modèle
# Évaluation du modèle
score = net.evaluate(test_images, test_labels, verbose=1)
print('Test accuracy:', score[1])
Les résultats sont les suivants::
313/313 [==============================] - 1s 2ms/step - loss: 0.0689 - accuracy: 0.9780
Test accuracy: 0.9779999852180481
Comparé à l'utilisation d'un réseau entièrement connecté , Beaucoup plus de précision .
边栏推荐
- [hard core dry goods] which company is better in data analysis? Choose pandas or SQL
- The problem of returning the longtext field in MySQL and its solution
- 软件测试工程师是做什么的?待遇前景怎么样?
- 众昂矿业:2022年全球萤石行业市场供给现状分析
- [untitled]
- 【合集- 行业解决方案】如何搭建高性能的数据加速与数据编排平台
- Zhongang Mining: analysis of the current market supply situation of the global fluorite industry in 2022
- Hiengine: comparable to the local cloud native memory database engine
- Recommended collection, my Tencent Android interview experience sharing
- How to safely and quickly migrate from CentOS to openeuler
猜你喜欢
【obs】QString的UTF-8中文转换到blog打印 UTF-8 char*
Password reset of MariaDB root user and ordinary user

UWB超宽带定位技术,实时厘米级高精度定位应用,超宽带传输技术
![[untitled]](/img/51/c89d35c855e299b02137d676790eb6.png)
[untitled]

IBM has laid off 40 + year-old employees in a large area. Mastering these ten search skills will improve your work efficiency ten times
Mysql如何对json数据进行查询及修改
word如何转换成pdf?word转pdf简单的方法分享!

Inventory of the most complete low code / no code platforms in the whole network: Jiandao cloud, partner cloud, Mingdao cloud, Qingliu, xurong cloud, Jijian cloud, treelab, nailing · Yida, Tencent clo

Common - Hero Minesweeper
大厂面试必备技能,2022Android不死我不倒

随机推荐
JAD installation, configuration and integration idea
redis集群模拟消息队列
Hiengine: comparable to the local cloud native memory database engine
什么是面上项目
深度学习 卷积神经网络(CNN)基础
[AI framework basic technology] automatic derivation mechanism (autograd)
openh264解码数据流向分析
[Collection - industry solutions] how to build a high-performance data acceleration and data editing platform
打新债在哪里操作开户是更安全可靠的呢
Oracle fault handling: ora-10873:file * needs to be either taken out of backup or media recovered
XaaS 陷阱:万物皆服务(可能)并不是IT真正需要的东西
MySql中的longtext字段的返回问题及解决
How to safely and quickly migrate from CentOS to openeuler
Successful entry into Baidu, 35K monthly salary, 2022 Android development interview answer
Notion 类生产力工具如何选择?Notion 、FlowUs 、Wolai 对比评测
中国银河证券开户安全吗 证券开户
UWB ultra wideband positioning technology, real-time centimeter level high-precision positioning application, ultra wideband transmission technology
HAC cluster modifying administrator user password
The binary string mode is displayed after the value with the field type of longtext in MySQL is exported
【无标题】