当前位置:网站首页>[AI framework basic technology] automatic derivation mechanism (autograd)
[AI framework basic technology] automatic derivation mechanism (autograd)
2022-07-05 19:14:00 【SenseParrots】

writing @ On condition of anonymity P classmate
0 Preface
The neural network can be regarded as a compound mathematical function , Network structure design determines how multiple basic functions are combined into composite functions , The training process of the network determines all the parameters of the composite function .
In order to get a “ good ” Function of , The training process will be based on a given data set , The function parameters are iteratively modified for many times , Repeat the following steps :
- Forward propagation
- Calculate the loss
- Back propagation ( Calculate the gradient of the parameter )
- Update parameters
Here I 3 The step back propagation process will deduce the gradient of the parameters according to the gradient of the output , The first 4 In this step, the parameters of the neural network will be updated according to these gradients , These two steps are the core of neural network optimization .
In the process of back propagation, the gradients of all parameters need to be calculated , Of course, this can be calculated by the network designer himself and implemented by hard coding , But the network model is complex and diverse , Hard coding for each network to implement parameter gradient calculation will consume a lot of energy .
therefore ,AI It is often implemented in the framework Automatic derivation mechanism , To automatically complete the gradient calculation of parameters , And in each iter Automatically update gradient in , So that network designers can pay attention to the design of network structure , You don't have to worry about how the gradient is calculated .
The content of this article is based on our self-developed AI frame SenseParrots, This paper introduces the implementation of automatic derivation of framework . This sharing will be divided into the following two parts :
- Introduction to automatic derivation mechanism
- SenseParrots Automatic derivation implementation
1 Introduction to automatic derivation mechanism
From a mathematical point of view, the problem of derivation , It also includes first-order derivative and higher-order derivative , The main ways of derivation are : Numerical derivation 、 Sign derivation 、 Automatic derivation ; Among them, automatic derivation is divided into forward mode and reverse mode,AI Automatic derivation in a framework is usually based on reverse mode.
Reverse mode, Based on The chain rule Reverse mode of , It refers to the process of gradient calculation , Start with the last node , Calculate the gradient of each input forward in turn .
be based on reverse mode Do gradient calculation , It can effectively decouple the gradient calculation of each node , You only need to focus on the gradient calculation of the current node in the calculation graph every time .
be based on reverse mode The process of gradient calculation can be divided into three steps , Take the following compound function calculation as an example :
\(y = x_1 + x_2\\ z = y * x_3\)
- First, create a forward calculation diagram :
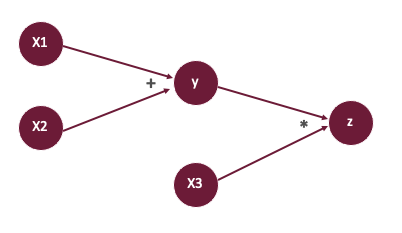
Then calculate the value of forward propagation , namely \(y\)、\(z\).
Based on the forward calculation diagram , Accordingly, the reverse calculation diagram is obtained , In back propagation , Based on the given output \(z\) Gradient of \(dz\), Sequentially calculate :
\(\begin{align*} dy &= \frac{\partial z}{\partial y} = x_3 * dz \\ dx_3 &= \frac{\partial z}{\partial x_3} = y * dz \\ dx_1 &= \frac{\partial z}{\partial x_1} = \frac{\partial z}{\partial y} \frac{\partial y}{\partial x_1} = dy \\ dx_2 &= \frac{\partial z}{\partial x_2} = \frac{\partial z}{\partial y} \frac{\partial y}{\partial x_2} = dy \end{align*} \)
further , stay AI Based on the framework of reverse mode In the automatic derivation mechanism of , According to the construction time of the reverse calculation diagram , It is also divided into automatic derivation based on dual graph and based on tape Automatic derivation of , The derivation method based on dual graph is usually combined with static graph , Using dynamic graphs AI Frameworks are mostly based on tape Automatic derivation of .
1.1 Automatic derivation mechanism based on dual graph
Based on the automatic derivation of dual graph, the construction of its reverse calculation graph is after the construction of the whole forward calculation graph , The way of realization is , First, the forward calculation diagram corresponding to the objective function is obtained by some model analysis methods , Then traverse the forward calculation graph , The reverse calculation graph is constructed by using the reverse operator node corresponding to each forward operator node in the calculation graph , And then realize automatic derivation .
The inverse calculation diagram obtained here is equivalent to the symbolic derivative result of the objective function , No difference from the original function , The reverse calculation diagram can also be represented by a function , Pass in different parameters to call normally .TVM An automatic derivation mechanism is implemented based on dual graph , Here is a code example :
s = (5, 10, 5)t = relay.TensorType((5, 10, 5))x = relay.var("x", t)y = relay.var("y", t)z = x + y fwd_func = run_infer_type(relay.Function([x, y], z))bwd_func = run_infer_type(gradient(fwd_func)) x_data = np.random.rand(*s).astype(t.dtype)y_data = np.random.rand(*s).astype(t.dtype)intrp = relay.create_executor(ctx=ctx, target=target)op_res, (op_grad0, op_grad1) = intrp.evaluate(bwd_func)(x_data, y_data)The realization of automatic derivation mechanism based on dual graph is clear , And there are some advantages :
- You only need to solve the reciprocal of symbols once , Subsequently, you can get the target numerical derivative by calling it several times with different values ;
- The implementation of higher-order derivation is very obvious , Just call the automatic derivation module further on the derivation result function .
However, this scheme has strict requirements for the definition of calculation graph and operator nodes , The forward operator node and the reverse operator node basically correspond to each other ; On the other hand , The scheme needs to complete the complete analysis of the forward calculation graph , To start the generation of reverse calculation graph , The whole process is lagging , So it is suitable for static graph based AI frame .
1.2 be based on tape Automatic derivation mechanism
In dynamic graph based AI frame , Such as PyTorch、SenseParrots in , We usually use based on tape Automatic derivation mechanism .
be based on tape Automatic derivation of , The creation of the reverse calculation graph takes place in the forward propagation process , The whole process can be simplified into two steps :
- In the forward propagation process, the reverse calculation diagram is constructed , Contrary to the hysteresis of the automatic derivation mechanism based on dual graph , Here, we can construct the reverse calculation graph in the forward propagation process ;
- Automatic derivation of input based on output gradient information .
be based on tape More details on performing automatic derivation will be expanded in the next chapter .
2 SenseParrots Automatic derivation implementation
2.1 Automatic derivation mechanism component
SenseParrots Is a dynamic graph based AI frame ( The online compilation function is partially static , It does not affect the overall mechanism of automatic derivation ), The automatic derivation mechanism is based on tape Automatic derivation of , In the process of forward propagation , Forward compute graphs are not explicitly constructed , Instead, the forward calculation process is directly executed , Therefore, the calculation diagrams mentioned later are all reverse calculation diagrams .
SenseParrots The whole automatic derivation mechanism mainly depends on the following three parts :
- DArray: Data structure of calculation data , You can imagine it as a multidimensional array , It contains the data involved in the operation 、 Its gradient and its output GradFn.
- Function: A basic arithmetic unit , It includes a forward calculation function of an operation and its reverse calculation function , Each calculation process corresponds to one Function. For example, a ReLU Activate the Function It includes the following two parts :
Class ReLU : Function { DArray forward(const DArray& x) { DArray y = ...; // ReLU Forward calculation process return y; } DArray backward(const DArray& dy) { DArray dx = ...; // ReLU Reverse calculation process return dx; }};GradFn: Calculate the nodes in the graph , Every Function When performing forward calculation, aGradFnobject , Pointer that stores the input and output gradient information 、Function Pointer to determine the function to be called by reverse calculation 、 The subsequent GradFn Node pointer , The object is saved in the Function Output of forward calculationDArrayin .
PS: SenseParrots Fully compatible with PyTorch, Also for the convenience of everyone to understand , The code involved in the following text adopts Torch Interface .
2.2 Control options for automatic derivation mechanism
- DArray Of
requires_gradAttribute indicates whether the data needs gradient .requires_gradSet to True Calculate the gradient , And will generate LeafGradFn(GradFn Subclasses of ) To identify this node as a leaf node , The construction of the computational graph depends on the inputrequires_gradattribute ; - Whether the framework turns on derivation . By default, the framework is on derivation , It also provides an interface for displaying the switch derivation :
torch.no_grad()、torch.enable_grad(), When the derivation function is turned off in the framework , Will not construct a calculation diagram .
2.3 Construct a calculation diagram in the forward propagation process
SenseParrots In forward calculation , According to the user-defined calculation process , Call each one in turn Function To complete the calculation . In calling each Function when , First judgement Is there any gradient in the input :
If the input does not need to calculate the gradient , The calculation diagram will not be constructed , Directly call the function to calculate the output , And the output
requires_gradSet to False;If there is a gradient in the input , Then call the function to calculate the output , And the output
requires_gradSet to True, At the same time, a corresponding GradFn object , And complete the following related work (“ preservation ” It's all aboutshared_ptrThe way ):- Will be Function Record in this GradFn object , To show that in the reverse derivation , use GradFn Recorded in the Function Calculate the gradient by using the inverse calculation function of ;
- Will be Function The input of the forward calculation function DArray The gradient of is recorded in GradFn object , Will be Function Forward calculate the output of the function DArray The gradient of is recorded in GradFn object ;
- Will be Function The input of the forward calculation function DArray As recorded in GradFn Record as GradFn Successor node ;
- Will be GradFn Keep in Function Among all the outputs of the forward calculation function .
From the initial input data ( Leaf node ) Start , Execute sequentially Function, A complete calculation diagram can be constructed .
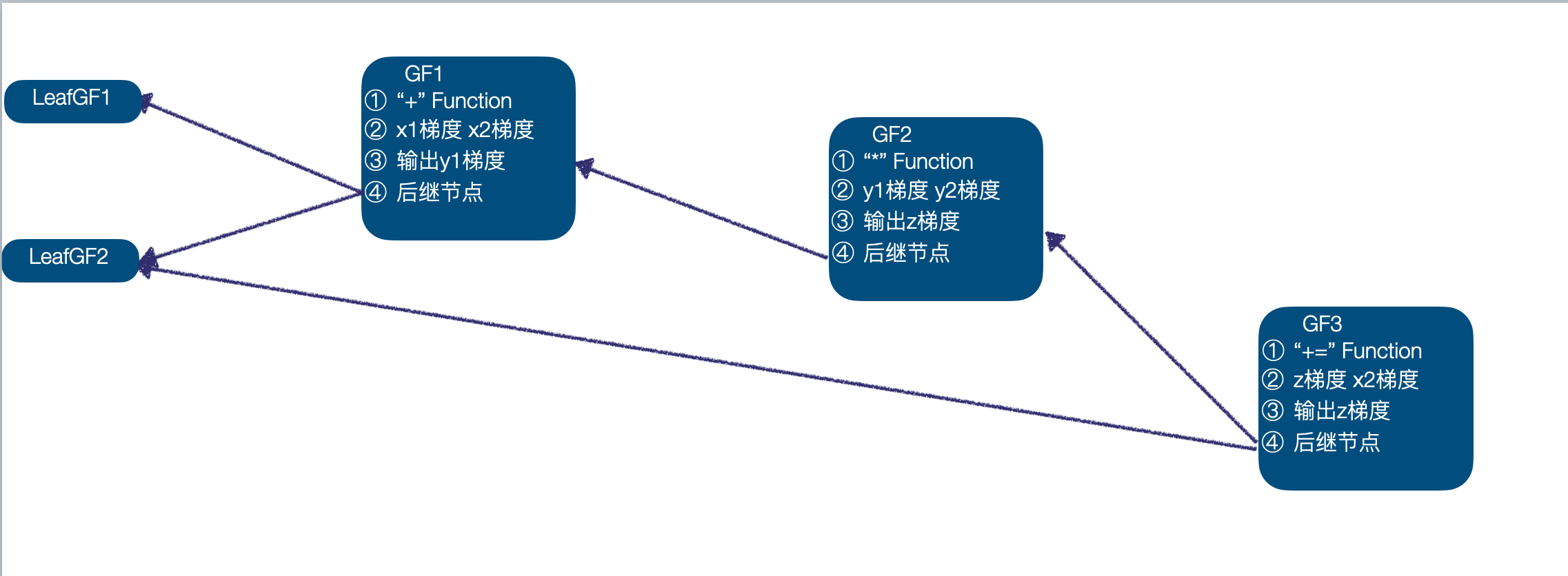
The following example introduces the construction process of the calculation diagram ( When the derivation function is enabled by default in the framework ):
import torchx1 = torch.randn((2,3,4), requires_grad=True)x2 = torch.randn((2,3,4), requires_grad=True)x3 = torch.randn((2,3,4))x4 = torch.randn((2,3,4)) y1 = x1 + x2y2 = x3 + x4z = y1 * y2z += x2- First, we calculate the input data as x1、x2、x3、x4, In the current calculation diagram x1、x2 You need to calculate the gradient , Created LeafGradFn node , and x3、x4 Of GradFn Are null pointers , therefore , The original calculation diagram contains two nodes , namely x1、x2 Of LeafGF1、LeafGF2.

- With x1、x2 As input , call "+" Function Forward calculation function of , Get the output y1, because x1、x2 You need to calculate the gradient , Set up y1 Of
requires_grad=True, Simultaneous generation GradFn GF1, take "+" Function It was recorded that GF1 in , Enter x1、x2 The gradient of is recorded to GF1 in , Will output y The gradient of is recorded in GF1 in , take x1、x2 Of GradFn Record as GradFn Successor node , take GF1 Save in y1 in ; There are 3 Nodes :LeafGF1、LeafGF2、GF1.
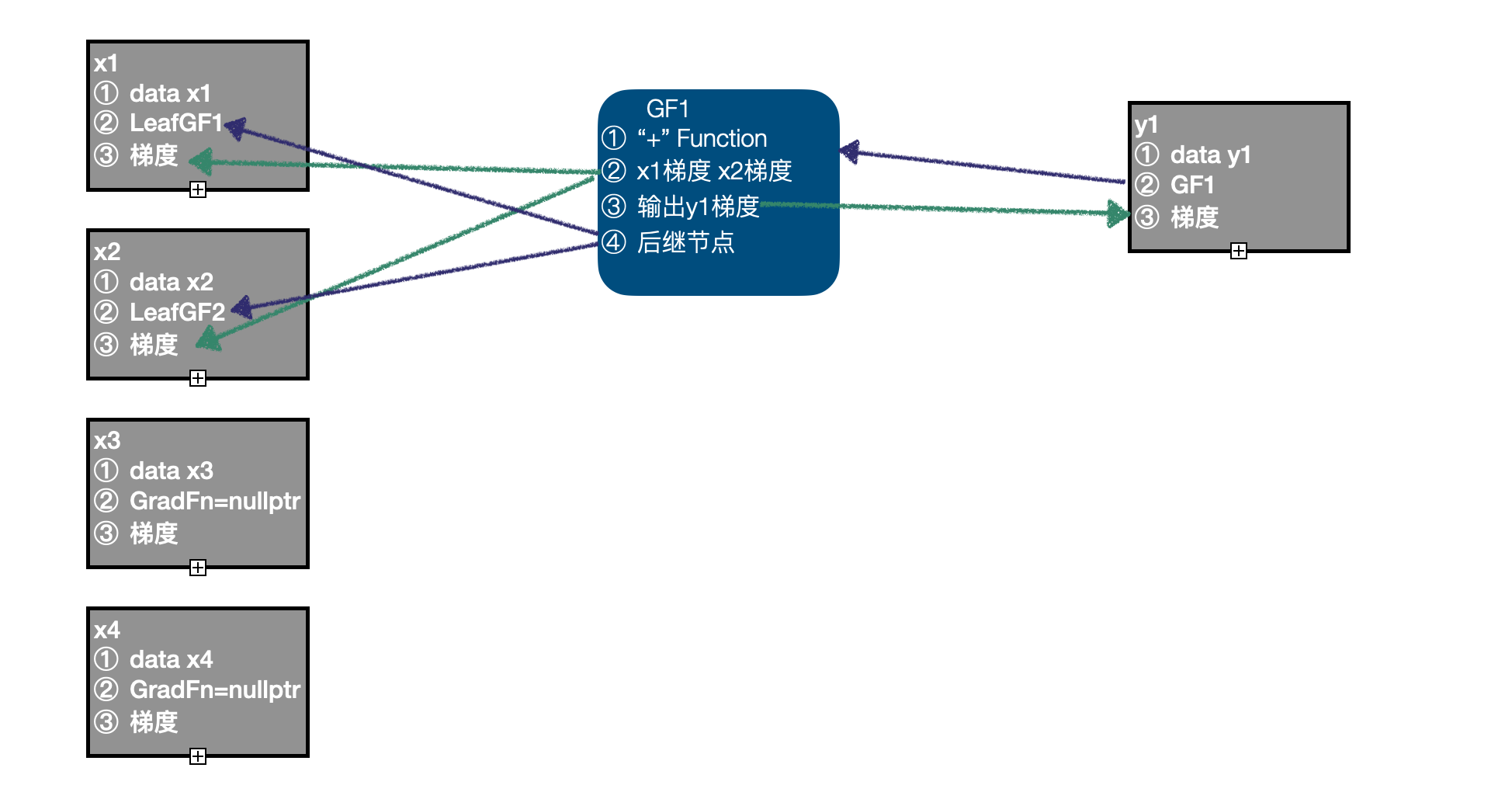
- With x3、x4 As input , call "+" Function Forward calculation function of , Get the output y2, because x3、x4 There is no need to calculate the gradient ,y2 Of
requires_grad=False, At this time, there is still only 3 Nodes :LeafGF1、LeafGF2、GF1.
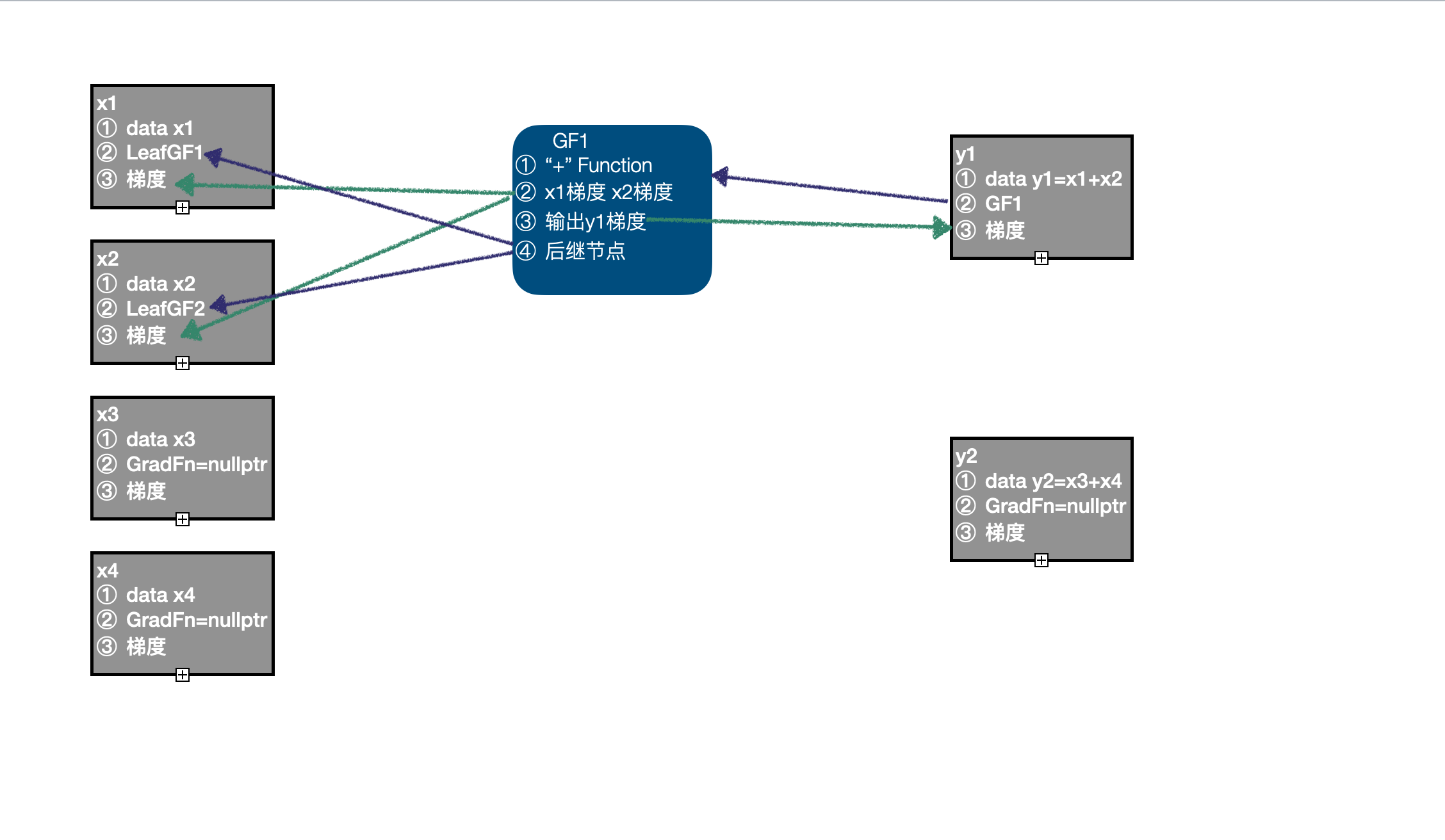
- With y1、y2 As input , call "*" Funtcion Forward calculation function of , Get the output z, Because of the input y1 You need to calculate the gradient , Set up z Of
requires_grad=True, Simultaneous generation GradFn GF2, And complete the correlation of corresponding information , There are 4 Nodes :LeafGF1、LeafGF2、GF1、GF2.
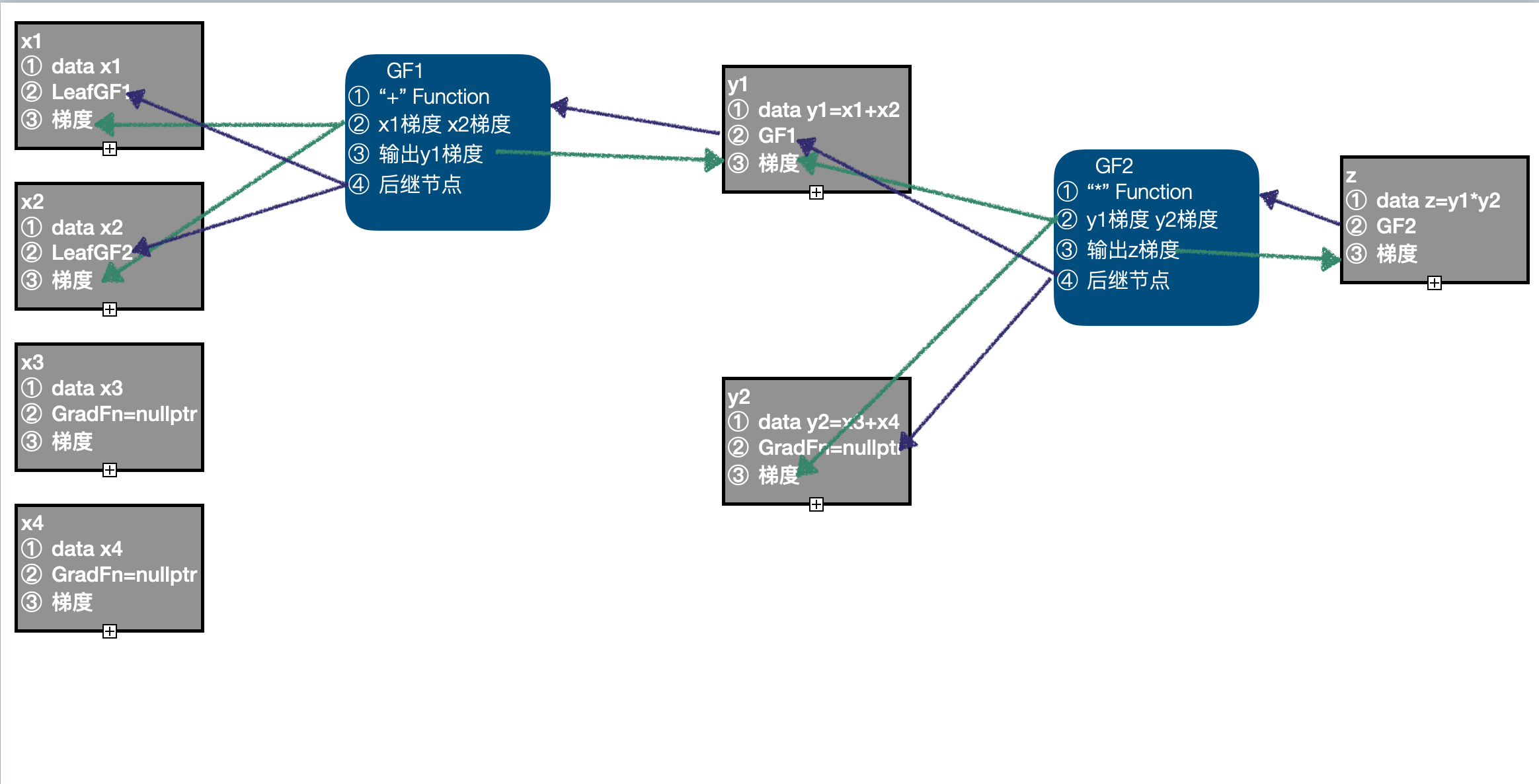
- It should be noted that , The last calculation "+=" It's a inplace The calculation of , That is to z、x2 For input , The result of the calculation is z, Processing inplace When calculating , Still follow the same GradFN The construction method is ok , Simultaneously construct GF3, take "+=" Function、 Input x1 gradient 、z gradient 、 Output z gradient 、 The subsequent nodes GF2、LeafGF1 Record in GF3, It should be noted that , There will be z Medium GradFn Updated to GF3, And it turns out z Stored in the GF2 As GF3 The successor node of , At this time, there is 5 Nodes :LeafGF1、LeafGF2、GF1、GF2、GF3.

Thus, a complete calculation diagram is obtained , And completed the correlation of relevant information , The complete calculation diagram is as follows :
2.4 Automatic derivation of input based on output gradient information
z.backward(torch.ones_like(z)) In dynamic graph based AI In the frame , The reverse derivation process is usually performed by the above .backward ( gradient ) Function triggered . SenseParrots The reverse derivation process of , First, according to the given output gradient , Update the gradient value of the final output ; Then the nodes in the calculation graph are topologically sorted , Get the GradFn Execution order of ; Execute sequentially GradFn As recorded in Function Inverse calculation function of , According to the gradient of the output , Calculate and update the input gradient .
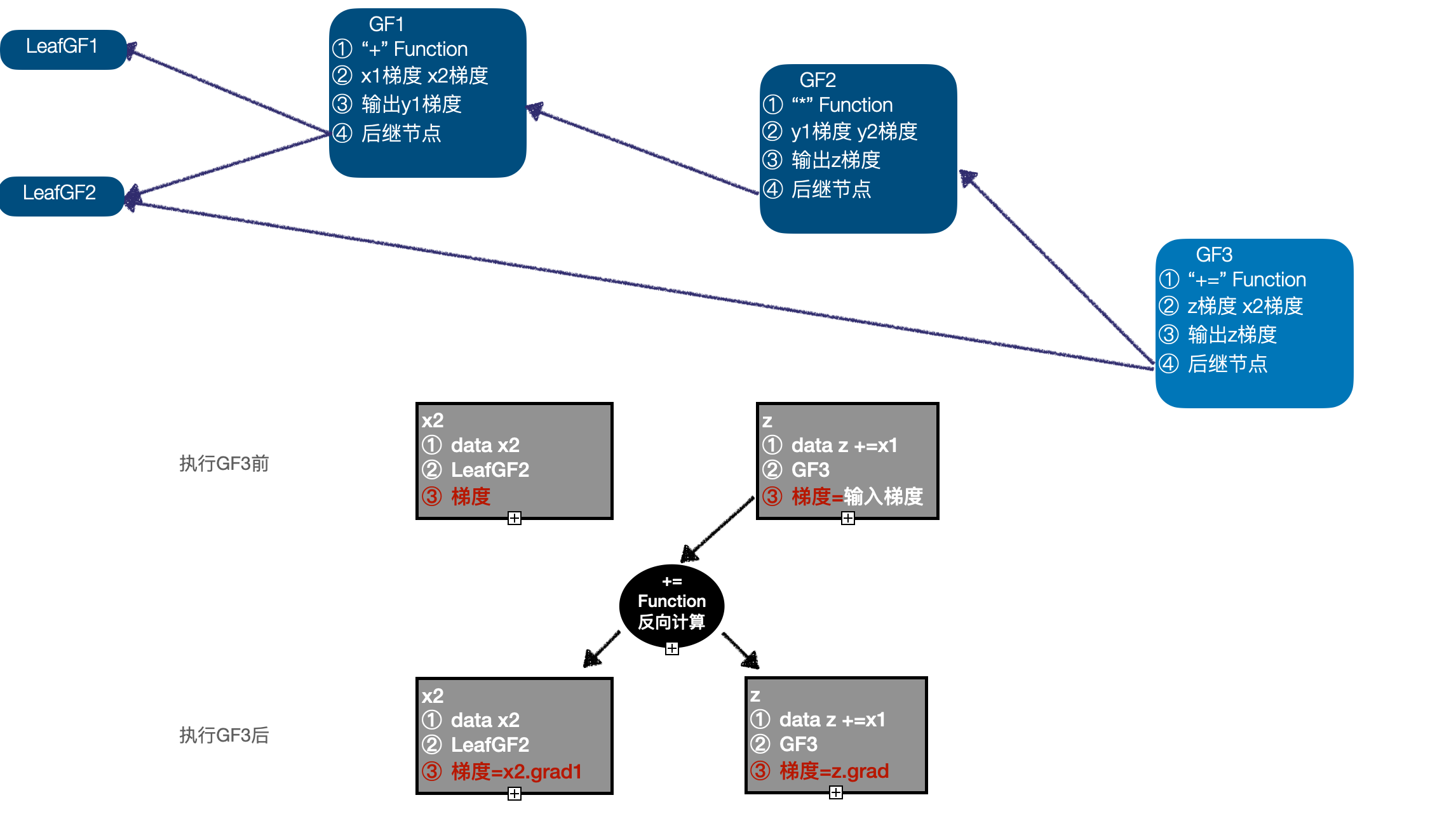
First, let's take a look at the above example , among x1 Only with one GradFn relevant , Its gradient will only be calculated once , This input only affects a single output , Is the simplest case of reverse derivation ;x2 With two GradFn relevant , This is in reverse derivation , One input affects multiple direct outputs , We need to pay attention to , Input x2 The gradient of will also be calculated twice , When the gradient is updated , You need to accumulate the gradient obtained by multiple calculations ;z Our calculation involves inplace operation , We are 2.3 Of the 5 Step explains how to deal with this situation . The reverse derivation process of the above example is introduced below :
- Based on a given z Gradient information , to update z Gradient value in ;
- Topological sorting based on calculation graph , get GradFn Execution queue of ( One possible sequence is :GF3 -> GF2 -> GF1 -> LeafGF1 -> LeafGF2);
- Start reverse derivation , First, execute GF3,GF3 It's a inplace operation , With z As input , call "+=" Function Inverse calculation function of , Calculate and update z、x2 Gradient of , At this time, the execution queue is (GF2 -> GF1 -> LeafGF1 -> LeafGF2);
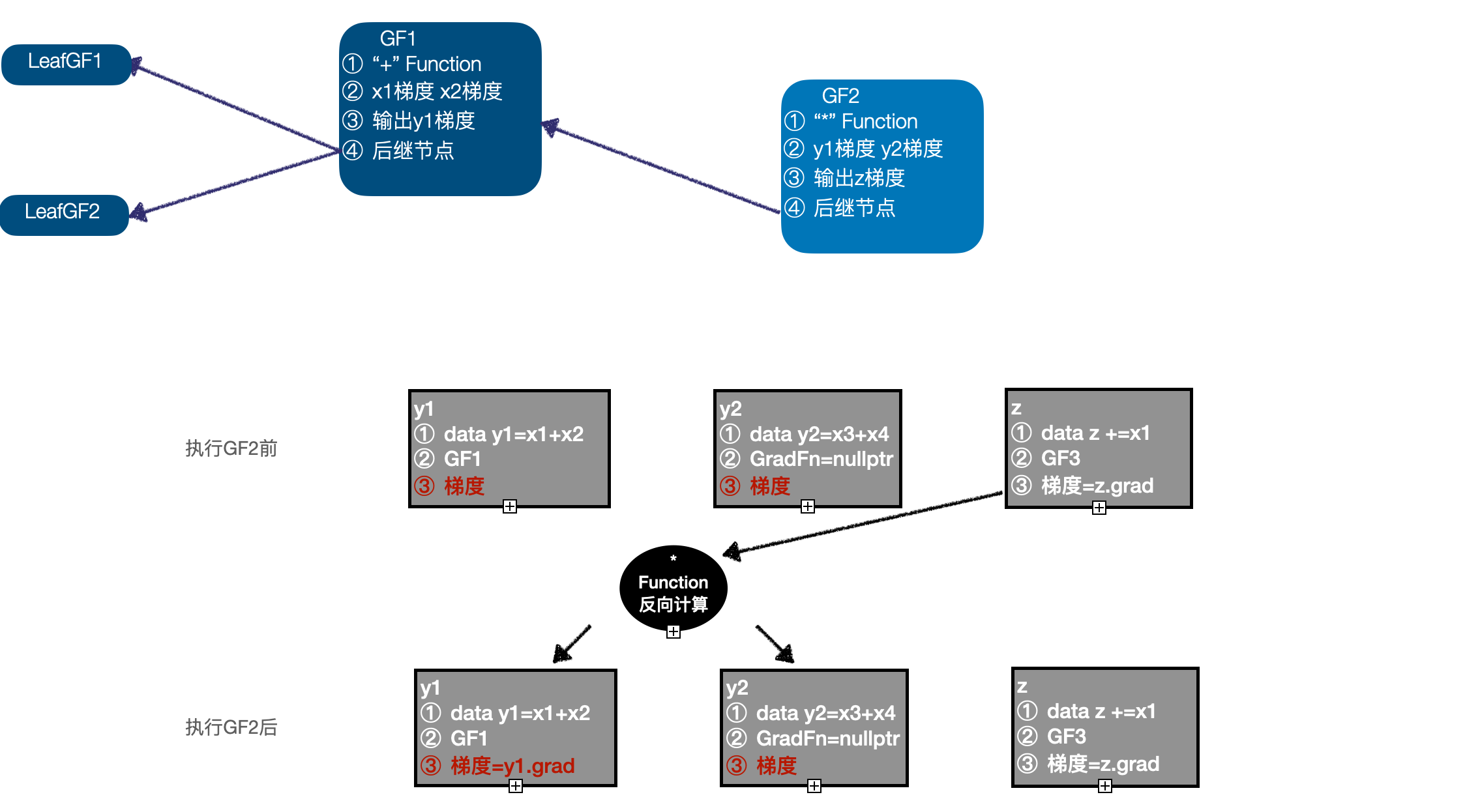
- perform GF2, With GF3 After calculation z As input , call "*" Function Inverse calculation function of , Calculation y1、y2 Gradient of , to update y1 Gradient of , because y2 You don't need to find gradients , So its gradient information is discarded , At this time, the execution queue is (GF1 -> LeafGF1 -> LeafGF2);
- perform GF1, With y1 As input , call "+" Function Inverse calculation function of , Calculation x1、x2 Gradient of , to update x1 Gradient of , and x2 The gradient information of needs to be accumulated on the basis of the previous calculation results , At this time, the execution queue is (LeafGF1 -> LeafGF2);

- Execute sequentially LeafGF1、LeafGF2.

- The execution queue is empty , The reverse derivation process ends , By default, the calculation chart will be cleared , Gradient information of non leaf nodes is cleared .
Thus, the required computational gradient is obtained .
Thank you for reading , Welcome to leave a message in the comment area ~
P.S. If you like this article , Please do more give the thumbs-up , Let more people see us :D
Focus on official account 「SenseParrots」, Obtain the dynamic thinking framework of AI in the industry .
边栏推荐
- UWB超宽带定位技术,实时厘米级高精度定位应用,超宽带传输技术
- uniapp获取微信头像和昵称
- [detailed explanation of AUTOSAR 14 startup process]
- cf:B. Almost Ternary Matrix【对称 + 找规律 + 构造 + 我是构造垃圾】
- C# 语言的基本语法结构
- Interviewer: what is the difference between redis expiration deletion strategy and memory obsolescence strategy?
- Debezium系列之:IDEA集成词法和语法分析ANTLR,查看debezium支持的ddl、dml等语句
- Tupu software digital twin smart wind power system
- Mysql database indexing tutorial (super detailed)
- UDF implementation of Dameng database
猜你喜欢
Tianyi cloud understands enterprise level data security in this way

开源 SPL 消灭数以万计的数据库中间表
#夏日挑战赛#数据库学霸笔记,考试/面试快速复习~
word如何转换成pdf?word转pdf简单的方法分享!
Fuzor 2020软件安装包下载及安装教程
![[performance test] jmeter+grafana+influxdb deployment practice](/img/32/f07792734d040829398a90a2040146.png)
[performance test] jmeter+grafana+influxdb deployment practice
Tutoriel de téléchargement et d'installation du progiciel fuzor 2020
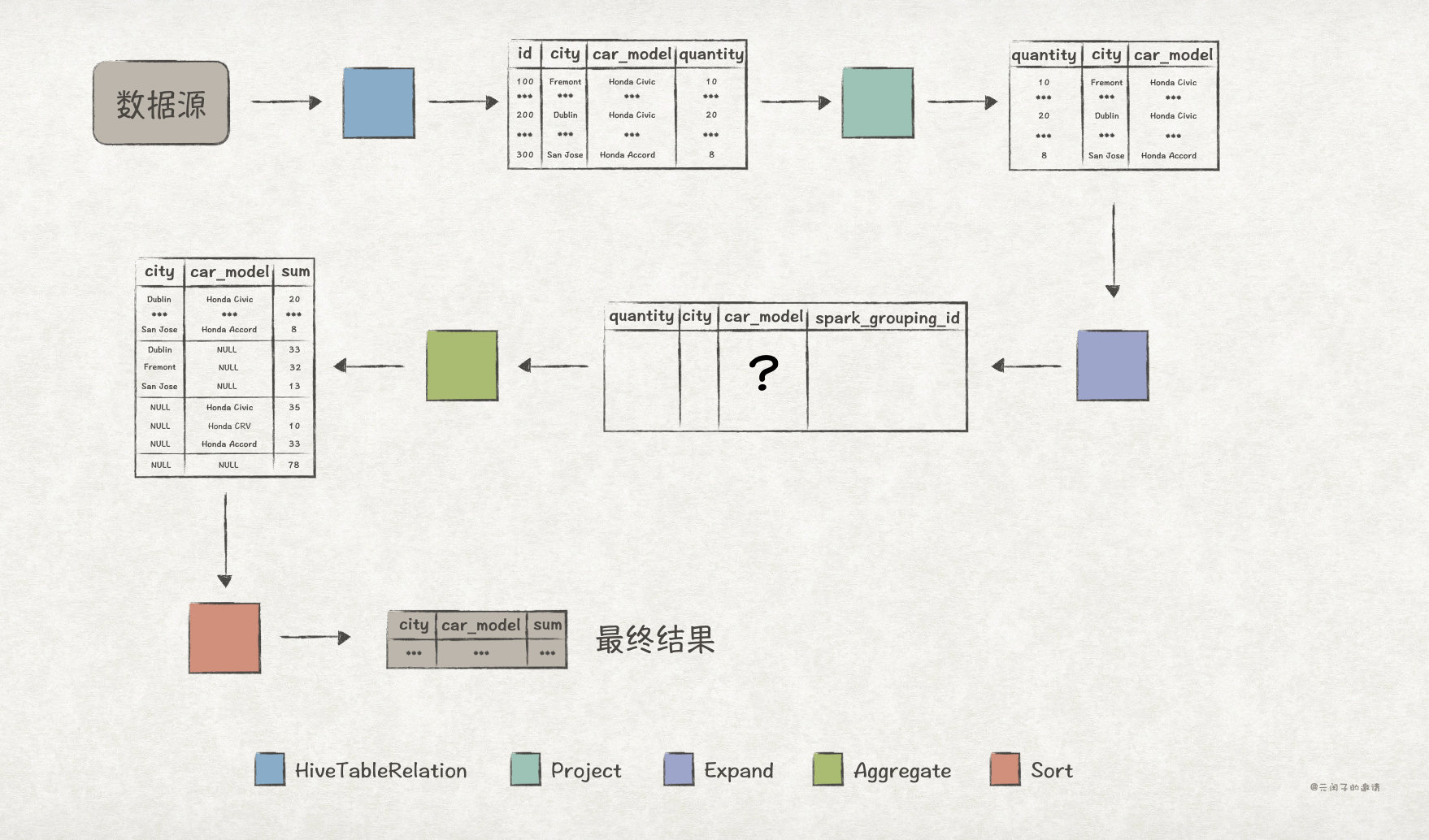
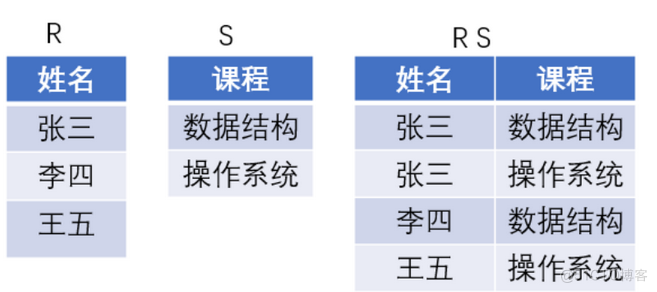
详解SQL中Groupings Sets 语句的功能和底层实现逻辑
Postman核心功能解析 —— 参数化和测试报告
Analysis of postman core functions - parameterization and test report
随机推荐
Teach you to deal with JS reverse picture camouflage hand in hand
从外卖点单浅谈伪需求
Cf:b. almost Terry matrix [symmetry + finding rules + structure + I am structural garbage]
5. Data access - entityframework integration
[today in history] July 5: the mother of Google was born; Two Turing Award pioneers born on the same day
Windows Oracle open remote connection Windows Server Oracle open remote connection
HAC集群修改管理员用户密码
How to convert word into PDF? Word to PDF simple way to share!
出海十年:新旧接力,黑马崛起
Can Leica capture the high-end market offered by Huawei for Xiaomi 12s?
Debezium系列之:记录mariadb数据库删除多张临时表debezium解析到的消息以及解决方法
Fundamentals of machine learning (III) -- KNN / naive Bayes / cross validation / grid search
Golang through pointer for Range implements the change of the value of the element in the slice
PHP利用ueditor实现上传图片添加水印
Shell编程基础(第8篇:分支语句-case in)
C# 语言的高级应用
The road of enterprise digital transformation starts from here
Benefits of automated testing
1亿单身男女撑起一个IPO,估值130亿
Django使用mysqlclient服务连接并写入数据库的操作过程