当前位置:网站首页>Fundamentals of machine learning (III) -- KNN / naive Bayes / cross validation / grid search
Fundamentals of machine learning (III) -- KNN / naive Bayes / cross validation / grid search
2022-07-05 19:06:00 【Bayesian grandson】
List of articles
- 3. K Nearest neighbor algorithm (KNN)
- 4. Classification model evaluation ( Accuracy and recall )
- 5. Cross validation and grid search
- 6. Naive bayes algorithm
3. K Nearest neighbor algorithm (KNN)
(1)KNN Concept :k The nearest neighbor , That is, each sample can use its closest k A neighbor represents .(K Near Neighbor)
(2) Algorithmic thought : A sample and dataset of k Two samples are the most similar , If this k Most of the samples belong to a certain category , Then the sample also belongs to this category .
(3) Distance metric : Generally, European distance is used ,L2 Norm is enough .
(4)K value The choice of : If you choose smaller Of K value , It is equivalent to predicting in a small neighborhood , The approximation error of learning will be reduced ; shortcoming It is the estimation error of learning that will
increase . If the adjacent point happens to be noise , The prediction will go wrong .K A smaller value means that the overall model becomes more complex , Easy to happen Over fitting .
If you choose more K value , It is equivalent to using a larger neighborhood to predict ; advantage It can reduce the estimation error of learning , But the approximation error will increase ,K Worth increasing means adjusting
The volume model changes Simple .
General algorithm instance flow :
1、 Data set processing
2、 Split the dataset
3、 Standardize data sets
4、estimator Process for classified forecast
3.1 Read data information
import pandas as pd
# Reading data
data = pd.read_csv("./KNN_al/train.csv")
data.head(10)
| row_id | x | y | accuracy | time | place_id | |
|---|---|---|---|---|---|---|
| 0 | 0 | 0.7941 | 9.0809 | 54 | 470702 | 8523065625 |
| 1 | 1 | 5.9567 | 4.7968 | 13 | 186555 | 1757726713 |
| 2 | 2 | 8.3078 | 7.0407 | 74 | 322648 | 1137537235 |
| 3 | 3 | 7.3665 | 2.5165 | 65 | 704587 | 6567393236 |
| 4 | 4 | 4.0961 | 1.1307 | 31 | 472130 | 7440663949 |
| 5 | 5 | 3.8099 | 1.9586 | 75 | 178065 | 6289802927 |
| 6 | 6 | 6.3336 | 4.3720 | 13 | 666829 | 9931249544 |
| 7 | 7 | 5.7409 | 6.7697 | 85 | 369002 | 5662813655 |
| 8 | 8 | 4.3114 | 6.9410 | 3 | 166384 | 8471780938 |
| 9 | 9 | 6.3414 | 0.0758 | 65 | 400060 | 1253803156 |
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 29118021 entries, 0 to 29118020
Data columns (total 6 columns):
# Column Dtype
--- ------ -----
0 row_id int64
1 x float64
2 y float64
3 accuracy int64
4 time int64
5 place_id int64
dtypes: float64(2), int64(4)
memory usage: 1.3 GB
3.2 Processing data
This data is too big , Nearly 30 million , We need to filter the data .
3.2.1 Shrink the data , Query data filtering
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
data.head(10)
| row_id | x | y | accuracy | time | place_id | |
|---|---|---|---|---|---|---|
| 600 | 600 | 1.2214 | 2.7023 | 17 | 65380 | 6683426742 |
| 957 | 957 | 1.1832 | 2.6891 | 58 | 785470 | 6683426742 |
| 4345 | 4345 | 1.1935 | 2.6550 | 11 | 400082 | 6889790653 |
| 4735 | 4735 | 1.1452 | 2.6074 | 49 | 514983 | 6822359752 |
| 5580 | 5580 | 1.0089 | 2.7287 | 19 | 732410 | 1527921905 |
| 6090 | 6090 | 1.1140 | 2.6262 | 11 | 145507 | 4000153867 |
| 6234 | 6234 | 1.1449 | 2.5003 | 34 | 316377 | 3741484405 |
| 6350 | 6350 | 1.0844 | 2.7436 | 65 | 36816 | 5963693798 |
| 7468 | 7468 | 1.0058 | 2.5096 | 66 | 746766 | 9076695703 |
| 8478 | 8478 | 1.2015 | 2.5187 | 72 | 690722 | 3992589015 |
3.2.2 Processing time data
time_value = pd.to_datetime(data['time'], unit='s')
time_value.head()
600 1970-01-01 18:09:40
957 1970-01-10 02:11:10
4345 1970-01-05 15:08:02
4735 1970-01-06 23:03:03
5580 1970-01-09 11:26:50
Name: time, dtype: datetime64[ns]
# Convert the date format to Dictionary format
time_value = pd.DatetimeIndex(time_value)
time_value
DatetimeIndex(['1970-01-01 18:09:40', '1970-01-10 02:11:10',
'1970-01-05 15:08:02', '1970-01-06 23:03:03',
'1970-01-09 11:26:50', '1970-01-02 16:25:07',
'1970-01-04 15:52:57', '1970-01-01 10:13:36',
'1970-01-09 15:26:06', '1970-01-08 23:52:02',
...
'1970-01-07 10:03:36', '1970-01-09 11:44:34',
'1970-01-04 08:07:44', '1970-01-04 15:47:47',
'1970-01-08 01:24:11', '1970-01-01 10:33:56',
'1970-01-07 23:22:04', '1970-01-08 15:03:14',
'1970-01-04 00:53:41', '1970-01-08 23:01:07'],
dtype='datetime64[ns]', name='time', length=17710, freq=None)
# Construct some features
data['day'] = time_value.day
data['hour'] = time_value.hour
data['weekday'] = time_value.weekday
data.head()
| row_id | x | y | accuracy | time | place_id | day | hour | weekday | |
|---|---|---|---|---|---|---|---|---|---|
| 600 | 600 | 1.2214 | 2.7023 | 17 | 65380 | 6683426742 | 1 | 18 | 3 |
| 957 | 957 | 1.1832 | 2.6891 | 58 | 785470 | 6683426742 | 10 | 2 | 5 |
| 4345 | 4345 | 1.1935 | 2.6550 | 11 | 400082 | 6889790653 | 5 | 15 | 0 |
| 4735 | 4735 | 1.1452 | 2.6074 | 49 | 514983 | 6822359752 | 6 | 23 | 1 |
| 5580 | 5580 | 1.0089 | 2.7287 | 19 | 732410 | 1527921905 | 9 | 11 | 4 |
# Delete the timestamp feature
data = data.drop(['time'], axis=1)
data.head()
| row_id | x | y | accuracy | place_id | day | hour | weekday | |
|---|---|---|---|---|---|---|---|---|
| 600 | 600 | 1.2214 | 2.7023 | 17 | 6683426742 | 1 | 18 | 3 |
| 957 | 957 | 1.1832 | 2.6891 | 58 | 6683426742 | 10 | 2 | 5 |
| 4345 | 4345 | 1.1935 | 2.6550 | 11 | 6889790653 | 5 | 15 | 0 |
| 4735 | 4735 | 1.1452 | 2.6074 | 49 | 6822359752 | 6 | 23 | 1 |
| 5580 | 5580 | 1.0089 | 2.7287 | 19 | 1527921905 | 9 | 11 | 4 |
# Check in less than n Target locations deleted
place_count = data.groupby('place_id').count()
place_count
# Group by a certain feature , This feature becomes an index index
| row_id | x | y | accuracy | day | hour | weekday | |
|---|---|---|---|---|---|---|---|
| place_id | |||||||
| 1012023972 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1057182134 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1059958036 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| 1085266789 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1097200869 | 1044 | 1044 | 1044 | 1044 | 1044 | 1044 | 1044 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 9904182060 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 9915093501 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 9946198589 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 9950190890 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 9980711012 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
805 rows × 7 columns
# tf It keeps row_id>3 The data of
tf = place_count[place_count.row_id > 3]
tf
| row_id | x | y | accuracy | day | hour | weekday | |
|---|---|---|---|---|---|---|---|
| place_id | |||||||
| 1097200869 | 1044 | 1044 | 1044 | 1044 | 1044 | 1044 | 1044 |
| 1228935308 | 120 | 120 | 120 | 120 | 120 | 120 | 120 |
| 1267801529 | 58 | 58 | 58 | 58 | 58 | 58 | 58 |
| 1278040507 | 15 | 15 | 15 | 15 | 15 | 15 | 15 |
| 1285051622 | 21 | 21 | 21 | 21 | 21 | 21 | 21 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 9741307878 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| 9753855529 | 21 | 21 | 21 | 21 | 21 | 21 | 21 |
| 9806043737 | 6 | 6 | 6 | 6 | 6 | 6 | 6 |
| 9809476069 | 23 | 23 | 23 | 23 | 23 | 23 | 23 |
| 9980711012 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
239 rows × 7 columns
# Then reset the index , Give Way place_id Go back to data features
tf = tf.reset_index()
tf
| place_id | row_id | x | y | accuracy | day | hour | weekday | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1097200869 | 1044 | 1044 | 1044 | 1044 | 1044 | 1044 | 1044 |
| 1 | 1228935308 | 120 | 120 | 120 | 120 | 120 | 120 | 120 |
| 2 | 1267801529 | 58 | 58 | 58 | 58 | 58 | 58 | 58 |
| 3 | 1278040507 | 15 | 15 | 15 | 15 | 15 | 15 | 15 |
| 4 | 1285051622 | 21 | 21 | 21 | 21 | 21 | 21 | 21 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 234 | 9741307878 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| 235 | 9753855529 | 21 | 21 | 21 | 21 | 21 | 21 | 21 |
| 236 | 9806043737 | 6 | 6 | 6 | 6 | 6 | 6 | 6 |
| 237 | 9809476069 | 23 | 23 | 23 | 23 | 23 | 23 | 23 |
| 238 | 9980711012 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
239 rows × 8 columns
# hold data Inside id Is it in tf.place_id Inside , Keep it if you have it .
data = data[data['place_id'].isin(tf.place_id)]
data
| row_id | x | y | accuracy | place_id | day | hour | weekday | |
|---|---|---|---|---|---|---|---|---|
| 600 | 600 | 1.2214 | 2.7023 | 17 | 6683426742 | 1 | 18 | 3 |
| 957 | 957 | 1.1832 | 2.6891 | 58 | 6683426742 | 10 | 2 | 5 |
| 4345 | 4345 | 1.1935 | 2.6550 | 11 | 6889790653 | 5 | 15 | 0 |
| 4735 | 4735 | 1.1452 | 2.6074 | 49 | 6822359752 | 6 | 23 | 1 |
| 5580 | 5580 | 1.0089 | 2.7287 | 19 | 1527921905 | 9 | 11 | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 29100203 | 29100203 | 1.0129 | 2.6775 | 12 | 3312463746 | 1 | 10 | 3 |
| 29108443 | 29108443 | 1.1474 | 2.6840 | 36 | 3533177779 | 7 | 23 | 2 |
| 29109993 | 29109993 | 1.0240 | 2.7238 | 62 | 6424972551 | 8 | 15 | 3 |
| 29111539 | 29111539 | 1.2032 | 2.6796 | 87 | 3533177779 | 4 | 0 | 6 |
| 29112154 | 29112154 | 1.1070 | 2.5419 | 178 | 4932578245 | 8 | 23 | 3 |
16918 rows × 8 columns
3.2.3 Take out the target value and characteristic value
y = data["place_id"]
x = data.drop(["place_id"],axis = 1) # Delete the target value along the direction of the column
3.3 Divide the training set and the test set
from sklearn.datasets import load_iris, fetch_20newsgroups, load_boston
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.25)
data
| row_id | x | y | accuracy | place_id | day | hour | weekday | |
|---|---|---|---|---|---|---|---|---|
| 600 | 600 | 1.2214 | 2.7023 | 17 | 6683426742 | 1 | 18 | 3 |
| 957 | 957 | 1.1832 | 2.6891 | 58 | 6683426742 | 10 | 2 | 5 |
| 4345 | 4345 | 1.1935 | 2.6550 | 11 | 6889790653 | 5 | 15 | 0 |
| 4735 | 4735 | 1.1452 | 2.6074 | 49 | 6822359752 | 6 | 23 | 1 |
| 5580 | 5580 | 1.0089 | 2.7287 | 19 | 1527921905 | 9 | 11 | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 29100203 | 29100203 | 1.0129 | 2.6775 | 12 | 3312463746 | 1 | 10 | 3 |
| 29108443 | 29108443 | 1.1474 | 2.6840 | 36 | 3533177779 | 7 | 23 | 2 |
| 29109993 | 29109993 | 1.0240 | 2.7238 | 62 | 6424972551 | 8 | 15 | 3 |
| 29111539 | 29111539 | 1.2032 | 2.6796 | 87 | 3533177779 | 4 | 0 | 6 |
| 29112154 | 29112154 | 1.1070 | 2.5419 | 178 | 4932578245 | 8 | 23 | 3 |
16918 rows × 8 columns
# At this time, we will not standardize the data , Call directly KNN Algorithm to try how the prediction effect .
def knn_al():
knn = KNeighborsClassifier(n_neighbors = 5)
# fit,predict ,score
knn.fit(x_train,y_train)
# Come up with a prediction
y_predict = knn.predict(x_test)
print(" The predicted target sign in location is :",y_predict)
# Get the accuracy
print(" The accuracy of the prediction :",knn.score(x_test,y_test))
if __name__ == "__main__":
knn_al()
The predicted target sign in location is : [1479000473 2584530303 2946102544 ... 5606572086 1602053545 1097200869]
The accuracy of the prediction : 0.029787234042553193
# We try to improve the accuracy of the algorithm , Delete first data Medium row_id Characteristics of .
data_del_row_id = data.drop(['row_id'],axis =1)
data_del_row_id
| x | y | accuracy | place_id | day | hour | weekday | |
|---|---|---|---|---|---|---|---|
| 600 | 1.2214 | 2.7023 | 17 | 6683426742 | 1 | 18 | 3 |
| 957 | 1.1832 | 2.6891 | 58 | 6683426742 | 10 | 2 | 5 |
| 4345 | 1.1935 | 2.6550 | 11 | 6889790653 | 5 | 15 | 0 |
| 4735 | 1.1452 | 2.6074 | 49 | 6822359752 | 6 | 23 | 1 |
| 5580 | 1.0089 | 2.7287 | 19 | 1527921905 | 9 | 11 | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 29100203 | 1.0129 | 2.6775 | 12 | 3312463746 | 1 | 10 | 3 |
| 29108443 | 1.1474 | 2.6840 | 36 | 3533177779 | 7 | 23 | 2 |
| 29109993 | 1.0240 | 2.7238 | 62 | 6424972551 | 8 | 15 | 3 |
| 29111539 | 1.2032 | 2.6796 | 87 | 3533177779 | 4 | 0 | 6 |
| 29112154 | 1.1070 | 2.5419 | 178 | 4932578245 | 8 | 23 | 3 |
16918 rows × 7 columns
y = data_del_row_id["place_id"]
x = data_del_row_id.drop(["place_id"],axis = 1) # Delete the target value along the direction of the column
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.25)
if __name__ == "__main__":
knn_al()
The predicted target sign in location is : [1097200869 3312463746 9632980559 ... 3533177779 4932578245 1913341282]
The accuracy of the prediction : 0.0806146572104019
We deleted row_id after , It is found that the accuracy of prediction ranges from 0.0319 To improve the 0.0806
# Next delete day try
y = data_del_row_id["day"]
x = data_del_row_id.drop(["place_id"],axis = 1) # Delete the target value along the direction of the column
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.25)
if __name__ == "__main__":
knn_al()
The predicted target sign in location is : [2 9 4 ... 6 5 9]
The accuracy of the prediction : 0.810401891252955
We deleted day After feature , It is found that the accuracy of prediction ranges from 0.0763 To improve the 0.8104
3.4 Feature Engineering ( Standardization )
Let's go back to the processed data , namely data, Then standardize the eigenvalues .
3.5 Calculation predict and Score
# Take out the eigenvalues and target values in the data
y = data['place_id']
x = data.drop(['place_id'], axis=1)
# Carry out data segmentation, training set, test set
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# Feature Engineering ( Standardization )
std = StandardScaler()
# The eigenvalues of test set and training set are standardized
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
if __name__ == "__main__":
knn_al()
The predicted target sign in location is : [6683426742 1435128522 2327054745 ... 2460093296 1435128522 1097200869]
The accuracy of the prediction : 0.41631205673758864
We Standardization after , It is found that the accuracy of prediction ranges from 0.0763 To improve the 0.41631205673758864.
And then we drop once "row_id" Characteristics of , Try again. .
# Take out the eigenvalues and target values in the data
x = data.drop("place_id",axis = 1)
x
| row_id | x | y | accuracy | day | hour | weekday | |
|---|---|---|---|---|---|---|---|
| 600 | 600 | 1.2214 | 2.7023 | 17 | 1 | 18 | 3 |
| 957 | 957 | 1.1832 | 2.6891 | 58 | 10 | 2 | 5 |
| 4345 | 4345 | 1.1935 | 2.6550 | 11 | 5 | 15 | 0 |
| 4735 | 4735 | 1.1452 | 2.6074 | 49 | 6 | 23 | 1 |
| 5580 | 5580 | 1.0089 | 2.7287 | 19 | 9 | 11 | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 29100203 | 29100203 | 1.0129 | 2.6775 | 12 | 1 | 10 | 3 |
| 29108443 | 29108443 | 1.1474 | 2.6840 | 36 | 7 | 23 | 2 |
| 29109993 | 29109993 | 1.0240 | 2.7238 | 62 | 8 | 15 | 3 |
| 29111539 | 29111539 | 1.2032 | 2.6796 | 87 | 4 | 0 | 6 |
| 29112154 | 29112154 | 1.1070 | 2.5419 | 178 | 8 | 23 | 3 |
16918 rows × 7 columns
# Carry out data segmentation, training set, test set
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# Feature Engineering ( Standardization )
std = StandardScaler()
# The eigenvalues of test set and training set are standardized
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
if __name__ == "__main__":
knn_al()
The predicted target sign in location is : [5270522918 1097200869 3312463746 ... 1097200869 5606572086 1097200869]
The accuracy of the prediction : 0.40803782505910163
# We will have a drop features :“day”
#
x_no_row_id = x.drop(["row_id"],axis =1)
x_no_row_id_and_no_day = x_no_row_id.drop(["day"],axis =1)
x_no_row_id_and_no_day
| x | y | accuracy | hour | weekday | |
|---|---|---|---|---|---|
| 600 | 1.2214 | 2.7023 | 17 | 18 | 3 |
| 957 | 1.1832 | 2.6891 | 58 | 2 | 5 |
| 4345 | 1.1935 | 2.6550 | 11 | 15 | 0 |
| 4735 | 1.1452 | 2.6074 | 49 | 23 | 1 |
| 5580 | 1.0089 | 2.7287 | 19 | 11 | 4 |
| ... | ... | ... | ... | ... | ... |
| 29100203 | 1.0129 | 2.6775 | 12 | 10 | 3 |
| 29108443 | 1.1474 | 2.6840 | 36 | 23 | 2 |
| 29109993 | 1.0240 | 2.7238 | 62 | 15 | 3 |
| 29111539 | 1.2032 | 2.6796 | 87 | 0 | 6 |
| 29112154 | 1.1070 | 2.5419 | 178 | 23 | 3 |
16918 rows × 5 columns
y
600 6683426742
957 6683426742
4345 6889790653
4735 6822359752
5580 1527921905
...
29100203 3312463746
29108443 3533177779
29109993 6424972551
29111539 3533177779
29112154 4932578245
Name: place_id, Length: 16918, dtype: int64
## 3.5
# Carry out data segmentation, training set, test set
x_train, x_test, y_train, y_test = train_test_split(x_no_row_id_and_no_day, y, test_size=0.25)
# Feature Engineering ( Standardization )
std = StandardScaler()
# The eigenvalues of test set and training set are standardized
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
knn = KNeighborsClassifier(n_neighbors = 5)
# fit,predict ,score
knn.fit(x_train,y_train)
# Come up with a prediction
y_predict = knn.predict(x_test)
print(" The predicted target sign in location is :",y_predict)
# Get the accuracy
print(" The accuracy of the prediction :",knn.score(x_test,y_test))
The predicted target sign in location is : [6399991653 3533177779 1097200869 ... 2327054745 3992589015 6683426742]
The accuracy of the prediction : 0.48699763593380613
3.6 KNN Algorithm is summarized
k The value is very small , Susceptible to outliers .
k It's worth a lot , Easy to bear k Value quantity ( Category ) Influence .
4. Classification model evaluation ( Accuracy and recall )
estimator.score()
Generally, the most common use is Accuracy rate , That is, the correct percentage of predicted results :
A c c u r a c y = T P + T N T P + F P + F N + T N Accuracy = \frac{TP+TN}{TP+FP+FN+TN} Accuracy=TP+FP+FN+TNTP+TN
Confusion matrix : In the classification task , Predicted results (Predicted Condition) With the right mark (True Condition) There are four different combinations , Make up the confusion matrix ( It's suitable for multiple categories )
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-kZbQHN9e-1656744456611)(attachment:image-2.png)]
Accuracy (Precision) And recall rate (Recall)
Accuracy : The predicted result is the proportion of real positive cases in positive samples ( Check it out )
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-mL6R4695-1656744456612)(attachment:image.png)]
P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP+FP} Precision=TP+FPTP
Recall rate : The proportion of real positive samples with positive prediction results ( Check the whole , The ability to distinguish positive samples )
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-1ST5eaks-1656744456613)(attachment:image-3.png)]
R e c a l l = T P T P + F N Recall = \frac{TP}{TP+FN} Recall=TP+FNTP
Other classification criteria ,F1-score, It reflects the robustness of the model
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-zfkzyqJe-1656744456613)(attachment:image-3.png)]
Classification model evaluation API
sklearn.metrics.classification_report
sklearn.metrics.classification_report(y_true, y_pred, target_names=None)
y_true: True target value
y_pred: The estimator predicts the target value
target_names: Target category name
return: Accuracy rate and recall rate of each category
5. Cross validation and grid search
on top , We divide the data into training sets and test sets . Now let's put aside the test set , Divide the training set .
The training set is divided into training set and verification set .
Usually , There are many parameters that need to be specified manually ( Such as k- In the nearest neighbor algorithm K value ), This is called superparameter . But the manual process is complicated , So we need to preset several super parameter combinations for the model . Each group of super parameters was evaluated by cross validation . Finally, the optimal combination of parameters is selected to establish the model .
Super parameter search - The grid search API: sklearn.model_selection.GridSearchCV
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
estimator: Estimator objects
param_grid: Estimator parameters (dict){“n_neighbors”:[1,3,5]}
cv: Specify a few fold cross validation
fit: Input training data
score: Accuracy rate
Result analysis :
best_score_: The best results tested in cross validation
best_estimator_: The best parametric model
cv_results_: Test set accuracy results and training set accuracy results after each cross validation
from sklearn.model_selection import train_test_split, GridSearchCV
# Construct the values of some parameters to search
param = {
"n_neighbors": [1,3,5,7,10]}
# Do a grid search
gc = GridSearchCV(knn, param_grid=param, cv=2)
gc.fit(x_train, y_train)
# Prediction accuracy
print(" Accuracy on the test set :", gc.score(x_test, y_test))
print(" The best result in cross validation :", gc.best_score_)
print(" Choosing the best model is :", gc.best_estimator_)
print("*"*100)
print(" The result of each cross validation of each super parameter :", gc.cv_results_)
Accuracy on the test set : 0.4955082742316785
The best result in cross validation : 0.45917402269861285
Choosing the best model is : KNeighborsClassifier(n_neighbors=10)
****************************************************************************************************
The result of each cross validation of each super parameter : {'mean_fit_time': array([0.00385594, 0.00366092, 0.00310779, 0.00316703, 0.003443 ]), 'std_fit_time': array([4.26769257e-04, 5.06877899e-04, 7.70092010e-05, 4.99486923e-05,
2.91109085e-04]), 'mean_score_time': array([0.19389665, 0.20236516, 0.21587265, 0.22173393, 0.23718596]), 'std_score_time': array([0.00897849, 0.00262308, 0.00137246, 0.00043309, 0.00201011]), 'param_n_neighbors': masked_array(data=[1, 3, 5, 7, 10],
mask=[False, False, False, False, False],
fill_value='?',
dtype=object), 'params': [{'n_neighbors': 1}, {'n_neighbors': 3}, {'n_neighbors': 5}, {'n_neighbors': 7}, {'n_neighbors': 10}], 'split0_test_score': array([0.41456494, 0.42307692, 0.44435687, 0.44656368, 0.45176545]), 'split1_test_score': array([0.4186633 , 0.43332282, 0.45412989, 0.4612232 , 0.4665826 ]), 'mean_test_score': array([0.41661412, 0.42819987, 0.44924338, 0.45389344, 0.45917402]), 'std_test_score': array([0.00204918, 0.00512295, 0.00488651, 0.00732976, 0.00740858]), 'rank_test_score': array([5, 4, 3, 2, 1], dtype=int32)}
6. Naive bayes algorithm
P ( C ∣ W ) = P ( W ∣ C ) P ( C ) P ( W ) P(C|W)=\frac{P(W|C)P(C)}{P(W)} P(C∣W)=P(W)P(W∣C)P(C)
notes :w Is the characteristic value of a given document ( frequency statistic , The forecast document provides ),c For document category
𝑃(𝐶): The probability of each document category ( Number of words in a document category / Total number of document words )
𝑃(𝑊│𝐶): Characteristics under a given category ( The words in the predicted document ) Probability
computing method :𝑃(𝐹1│𝐶)=𝑁𝑖/𝑁 ( In the training document to calculate )
𝑁𝑖 For the sake of 𝐹1 Words in C The number of times a category appears in all documents
𝑁 Is the category C The number of times all words appear and
6.1 Laplacian smoothing
𝛼 The coefficient specified for is generally 1,m It is the number of feature words in the training document
P ( F 1 ∣ C ) = N i + α N + α m P(F1|C)=\frac{N_i+\alpha}{N+\alpha m} P(F1∣C)=N+αmNi+α
6.2 sklearn Naive Bayesian implementation API
sklearn.naive_bayes.MultinomialNB
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
naive bayesian classification
α \alpha α: Laplace smoothing coefficient
6.3 Naive Bayesian algorithm case
Problem description :
(1)sklearn20 News category ;
(2)20 A newsgroup dataset contains 20 A theme 18000 Newsgroup posts
Naive Bayesian case flow
1、 load 20 Class news data , And split it up
2、 Generate characteristic words of the article
3、 Naive Bayes estimator Process to estimate
def naviebayes():
""" Naive Bayes for text classification :return: None """
news = fetch_20newsgroups(subset='all')
# Data segmentation
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
# Feature extraction of data set
tf = TfidfVectorizer()
# Count the importance of each article according to the list of words in the training set ['a','b','c','d']
x_train = tf.fit_transform(x_train)
print(tf.get_feature_names_out())
print("*"*50)
x_test = tf.transform(x_test)
# The prediction of naive Bayesian algorithm
mlt = MultinomialNB(alpha=1.0)
print(x_train.toarray())
print("*"*50)
mlt.fit(x_train, y_train)
y_predict = mlt.predict(x_test)
print(" The predicted article category is :", y_predict)
print("*"*50)
# Get the accuracy
print(" Accuracy rate is :", mlt.score(x_test, y_test))
print("*"*50)
print(" Accuracy rate and recall rate of each category :", classification_report(y_test, y_predict, target_names=news.target_names))
print("*"*50)
return None
if __name__ =="__main__":
naviebayes()
['00' '000' '0000' ... 'óáíïìåô' 'ýé' 'ÿhooked']
**************************************************
[[0. 0.02654538 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]
...
[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]]
**************************************************
The predicted article category is : [ 5 2 17 ... 1 13 7]
**************************************************
Accuracy rate is : 0.8612054329371817
**************************************************
Accuracy rate and recall rate of each category : precision recall f1-score support
alt.atheism 0.88 0.80 0.84 200
comp.graphics 0.88 0.79 0.83 241
comp.os.ms-windows.misc 0.89 0.78 0.83 254
comp.sys.ibm.pc.hardware 0.76 0.87 0.81 245
comp.sys.mac.hardware 0.84 0.90 0.86 229
comp.windows.x 0.90 0.85 0.88 245
misc.forsale 0.93 0.67 0.78 241
rec.autos 0.91 0.92 0.92 263
rec.motorcycles 0.94 0.95 0.94 265
rec.sport.baseball 0.94 0.95 0.95 237
rec.sport.hockey 0.91 0.98 0.94 238
sci.crypt 0.79 0.98 0.88 259
sci.electronics 0.91 0.82 0.86 238
sci.med 0.98 0.90 0.94 239
sci.space 0.87 0.97 0.92 249
soc.religion.christian 0.62 0.98 0.76 260
talk.politics.guns 0.80 0.95 0.87 230
talk.politics.mideast 0.92 0.98 0.95 230
talk.politics.misc 1.00 0.65 0.79 196
talk.religion.misc 0.97 0.23 0.37 153
accuracy 0.86 4712
macro avg 0.88 0.85 0.85 4712
weighted avg 0.88 0.86 0.86 4712
**************************************************
边栏推荐
- 一文读懂简单查询代价估算
- 【历史上的今天】7 月 5 日:Google 之母出生;同一天诞生的两位图灵奖先驱
- You can have both fish and bear's paw! Sky wing cloud elastic bare metal is attractive!
- Summary of six points of MySQL optimization
- 2022 latest intermediate and advanced Android interview questions, [principle + practice + Video + source code]
- 视频自监督学习综述
- C# 语言的高级应用
- 如何快速进阶自动化测试?听听这3位BAT大厂测试工程师的切身感想....
- 100million single men and women supported an IPO with a valuation of 13billion
- MySQL优化六个点的总结
猜你喜欢
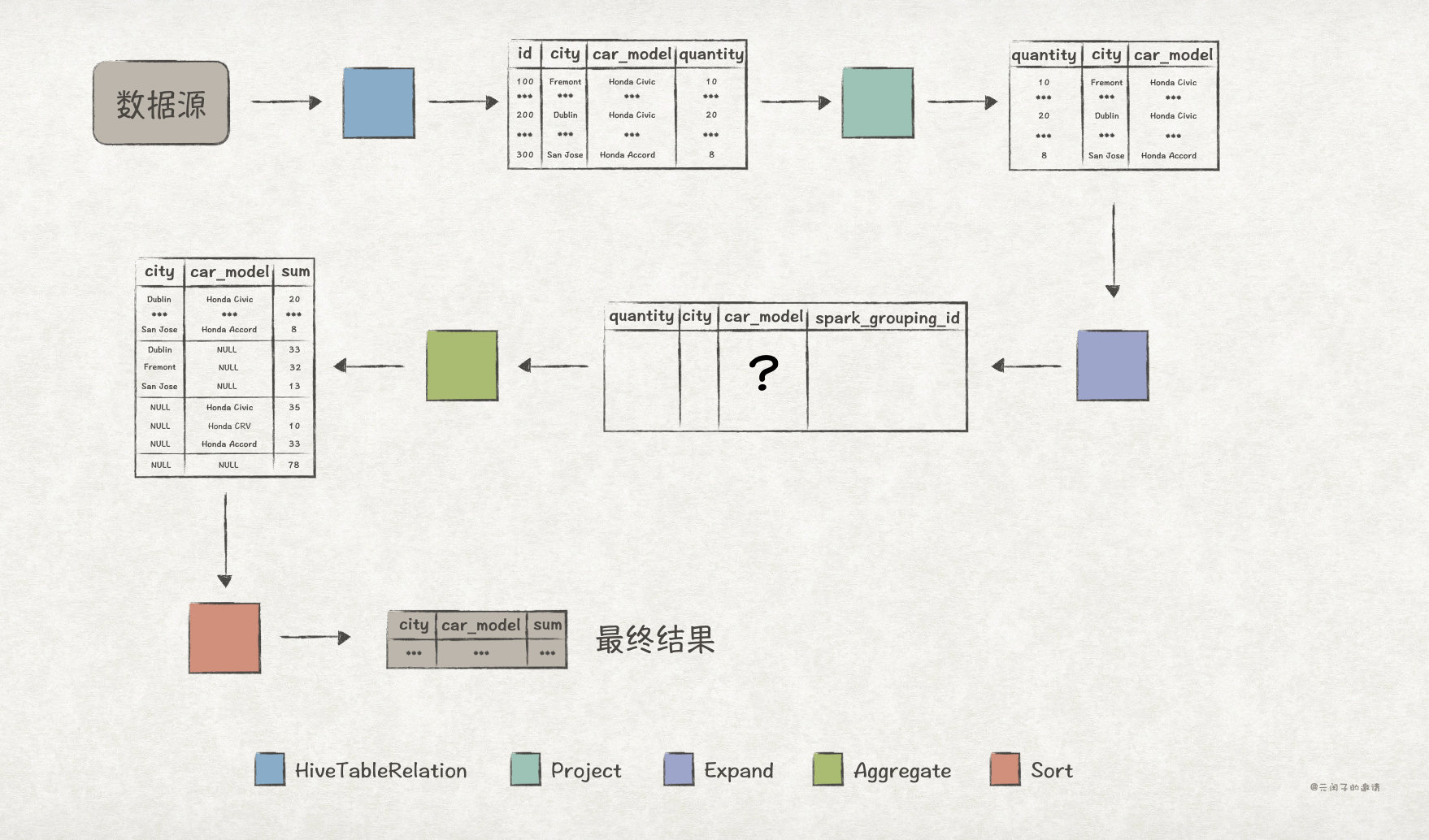
详解SQL中Groupings Sets 语句的功能和底层实现逻辑

Isprs2020/ cloud detection: transferring deep learning models for cloud detection between landsat-8 and proba-v
图扑软件数字孪生 | 基于 BIM 技术的可视化管理系统

AI open2022 | overview of recommendation systems based on heterogeneous information networks: concepts, methods, applications and resources
MySQL数据库索引教程(超详细)
2022全网最全的腾讯后台自动化测试与持续部署实践【万字长文】
Mariadb root用户及普通用户的密码 重置
Interprocess communication (IPC): shared memory
Windows Oracle open remote connection Windows Server Oracle open remote connection
ELK分布式日志分析系统部署(华为云)
随机推荐
[detailed explanation of AUTOSAR 14 startup process]
数学分析_笔记_第9章:曲线积分与曲面积分
使用文件和目录属性和属性
企业级数据安全,天翼云是这样理解的
Isprs2020/ cloud detection: transferring deep learning models for cloud detection between landsat-8 and proba-v
【AI 框架基础技术】自动求导机制 (Autograd)
What are the cache interfaces of nailing open platform applet API?
在线协作产品哪家强?微软 Loop 、Notion、FlowUs
Go语言 | 03 数组、指针、切片用法
机器学习基础(三)——KNN/朴素贝叶斯/交叉验证/网格搜索
flume系列之:拦截器过滤数据
ICML2022 | 长尾识别中分布外检测的部分和非对称对比学习
5. Data access - entityframework integration
#夏日挑战赛#数据库学霸笔记,考试/面试快速复习~
公司破产后,黑石们来了
华律网牵手观测云,上线系统全链路可观测平台
China law network joins hands to observe the cloud, and the online system is a full link observable platform
输油管的布置数学建模matlab,输油管布置的数学模型
Ant group open source trusted privacy computing framework "argot": open and universal
Teach you to deal with JS reverse picture camouflage hand in hand