当前位置:网站首页>一文读懂简单查询代价估算
一文读懂简单查询代价估算
2022-07-05 18:33:00 【InfoQ】
查询代价估算——如何选择一条最优的执行路径
- 词法分析:描述词法分析器的*.l文件经Lex工具编译生成lex.yy.c, 再由C编译器生成可执行的词法分析器。基本功能就是将一堆字符串根据设定的保留关键字和非保留关键字,转化成相应的标识符(Tokens)。
- 语法分析:语法规则描述文件*.y经YACC工具编译生成gram.c,再由C编译器生成可执行的语法分析器。基本功能就是将一堆标识符(Tokens)根据设定的语法规则,转化成原始语法树。
- 分析重写:查询分析将原始语法树转换为查询语法树(各种transform);查询重写根据pg_rewrite中的规则改写表和视图,最终得到查询语法树。
- 查询优化:经过逻辑优化和物理优化(生成最优路径)。
- 查询计划生成:将最优的查询路径转化为查询计划。
- 查询执行:通过执行器去执行查询计划生成查询的结果集。
为何需要这些统计信息,有了这些够不够?
- 是不是空数组
- 是不是常量数组
- 是不是唯一无重复
- 是不是有序
- 是不是单调的,等差,等比
- 出现次数最多的数字有哪些
- 数据的分布规律(打点方式描绘数据增长趋势)
如何依据统计信息估算查询代价
- 统计信息只来自部分采样数据,不能精准描述全局特征。
- 统计信息是历史数据,实际数据随时可能在变化。
最简单的表的行数估算(使用relpages和reltuples)
SELECT relpages, reltuples FROM pg_class WHERE relname = 'tenk1'; ---采样估算有358个页面,10000条元组
relpages | reltuples
----------+-----------
358 | 10000
EXPLAIN SELECT * FROM tenk1; ---查询估算该表有10000条元组
QUERY PLAN
-------------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..458.00 rows=10000 width=244)- 先通过表物理文件的大小计算实际页面数actual_pages = file_size / BLOCKSIZE
- 计算页面的元组密度
- a. 如果relpages大于0,密度= reltuples / (double) relpages
- b. 如果relpages为空,density = (BLCKSZ - SizeOfPageHeaderData) / tuple_width, 页面大小 / 元组宽度。
- 估算表元组个数 = 页面元组密度 * 实际页面数 = density * actual_pages
最简单的范围比较(使用直方图)
SELECT histogram_bounds FROM pg_stats WHERE tablename='tenk1' AND attname='unique1';
histogram_bounds
------------------------------------------------------
{0,993,1997,3050,4040,5036,5957,7057,8029,9016,9995}
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 1000; ---估算小于1000的有1007条
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=24.06..394.64 rows=1007 width=244)
Recheck Cond: (unique1 < 1000)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..23.80 rows=1007 width=0)
Index Cond: (unique1 < 1000)选择率 = (前面桶的总数 + 目标值在当前桶中的范围 / 当前桶的区间范围) / 桶的总数
selectivity = (1 + (1000 - bucket[2].min) / (bucket[2].max - bucket[2].min)) / num_buckets
= (1 + (1000 - 993) / (1997 - 993)) / 10
= 0.100697
估算元组数 = 基表元组数 * 条件选择率
rows = rel_cardinality * selectivity
= 10000 * 0.100697
= 1007 (rounding off)最简单的等值比较(使用MCV)
SELECT null_frac, n_distinct, most_common_vals, most_common_freqs FROM pg_stats WHERE tablename='tenk1' AND attname='stringu1';
null_frac | 0
n_distinct | 676
most_common_vals | {EJAAAA,BBAAAA,CRAAAA,FCAAAA,FEAAAA,GSAAAA,JOAAAA,MCAAAA,NAAAAA,WGAAAA}
most_common_freqs | {0.00333333,0.003,0.003,0.003,0.003,0.003,0.003,0.003,0.003,0.003}
EXPLAIN SELECT * FROM tenk1 WHERE stringu1 = 'CRAAAA'; ---
QUERY PLAN
----------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..483.00 rows=30 width=244)
Filter: (stringu1 = 'CRAAAA'::name)CRAAAA位于MCV中的第3项,占比是0.003
selectivity = mcf[3]
= 0.003
rows = 10000 * 0.003
= 30EXPLAIN SELECT * FROM tenk1 WHERE stringu1 = 'xxx'; ---查找不存在于MCV中的值
QUERY PLAN
----------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..483.00 rows=15 width=244)
Filter: (stringu1 = 'xxx'::name)selectivity = (1 - sum(mvf)) / (num_distinct - num_mcv)
= (1 - (0.00333333 + 0.003 + 0.003 + 0.003 + 0.003 + 0.003 +
0.003 + 0.003 + 0.003 + 0.003)) / (676 - 10)
= 0.0014559
rows = 10000 * 0.0014559
= 15 (rounding off)复杂一点的范围比较(同时使用MCV和直方图)
SELECT null_frac, n_distinct, most_common_vals, most_common_freqs FROM pg_stats WHERE tablename='tenk1' AND attname='stringu1';
null_frac | 0
n_distinct | 676
most_common_vals | {EJAAAA,BBAAAA,CRAAAA,FCAAAA,FEAAAA,GSAAAA,JOAAAA,MCAAAA,NAAAAA,WGAAAA}
most_common_freqs | {0.00333333,0.003,0.003,0.003,0.003,0.003,0.003,0.003,0.003,0.003}
SELECT histogram_bounds FROM pg_stats WHERE tablename='tenk1' AND attname='stringu1';
histogram_bounds
--------------------------------------------------------------------------------
{AAAAAA,CQAAAA,FRAAAA,IBAAAA,KRAAAA,NFAAAA,PSAAAA,SGAAAA,VAAAAA,XLAAAA,ZZAAAA}
EXPLAIN SELECT * FROM tenk1 WHERE stringu1 < 'IAAAAA'; ---查找一个不存在于MCV中的值
QUERY PLAN
------------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..483.00 rows=3077 width=244)
Filter: (stringu1 < 'IAAAAA'::name)selectivity = sum(relevant mvfs)
= 0.00333333 + 0.003 + 0.003 + 0.003 + 0.003 + 0.003
= 0.01833333selectivity = mcv_selectivity + histogram_selectivity * histogram_fraction
= 0.01833333 + ((2 + ('IAAAAA'-'FRAAAA')/('IBAAAA'-'FRAAAA')) / 10) * (1 - sum(mvfs))
= 0.01833333 + 0.298387 * 0.96966667
= 0.307669
rows = 10000 * 0.307669
= 3077 (rounding off)复制多条件联合查询的例子
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 1000 AND stringu1 = 'xxx';
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=23.80..396.91 rows=1 width=244)
Recheck Cond: (unique1 < 1000)
Filter: (stringu1 = 'xxx'::name)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..23.80 rows=1007 width=0)
Index Cond: (unique1 < 1000)selectivity = selectivity(unique1 < 1000) * selectivity(stringu1 = 'xxx')
= 0.100697 * 0.0014559
= 0.0001466
rows = 10000 * 0.0001466
= 1 (rounding off)一个使用JOIN的例子
EXPLAIN SELECT * FROM tenk1 t1, tenk2 t2
WHERE t1.unique1 < 50 AND t1.unique2 = t2.unique2;
QUERY PLAN
--------------------------------------------------------------------------------------
Nested Loop (cost=4.64..456.23 rows=50 width=488)
-> Bitmap Heap Scan on tenk1 t1 (cost=4.64..142.17 rows=50 width=244)
Recheck Cond: (unique1 < 50)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..4.63 rows=50 width=0)
Index Cond: (unique1 < 50)
-> Index Scan using tenk2_unique2 on tenk2 t2 (cost=0.00..6.27 rows=1 width=244)
Index Cond: (unique2 = t1.unique2)selectivity = (0 + (50 - bucket[1].min)/(bucket[1].max - bucket[1].min))/num_buckets
= (0 + (50 - 0)/(993 - 0))/10
= 0.005035
rows = 10000 * 0.005035
= 50 (rounding off)SELECT tablename, null_frac,n_distinct, most_common_vals FROM pg_stats
WHERE tablename IN ('tenk1', 'tenk2') AND attname='unique2';
tablename | null_frac | n_distinct | most_common_vals
-----------+-----------+------------+------------------
tenk1 | 0 | -1 |
tenk2 | 0 | -1 |【*】选择率 = 两边的非空概率相乘,再除以最大JOIN条数。
selectivity = (1 - null_frac1) * (1 - null_frac2) * min(1/num_distinct1, 1/num_distinct2)
= (1 - 0) * (1 - 0) / max(10000, 10000)
= 0.0001
【*】JOIN的函数估算就是两边输入数量的笛卡尔积,再乘以选择率
rows = (outer_cardinality * inner_cardinality) * selectivity
= (50 * 10000) * 0.0001
= 50更详细的信息
边栏推荐
- 在通达信上做基金定投安全吗?
- 《ClickHouse原理解析与应用实践》读书笔记(5)
- node_ Exporter memory usage is not displayed
- Maximum artificial island [how to make all nodes of a connected component record the total number of nodes? + number the connected component]
- Einstein sum einsum
- 图片数据不够?我做了一个免费的图像增强软件
- How to choose the most formal and safe external futures platform?
- 解决 contents have differences only in line separators
- SAP 特征 特性 说明
- Share: ZTE Yuanhang 30 Pro root unlock BL magick ZTE 7532n 8040n 9041n brush mask original brush package root method Download
猜你喜欢

Introduction to the development function of Hanlin Youshang system of Hansheng Youpin app
技术分享 | 常见接口协议解析
瀚升优品app翰林优商系统开发功能介绍
彻底理解为什么网络 I/O 会被阻塞?
@Extension, @spi annotation principle

第十一届中国云计算标准和应用大会 | 华云数据成为全国信标委云计算标准工作组云迁移专题组副组长单位副组长单位
About Estimation with Cross-Validation
Failed to virtualize table with JMeter
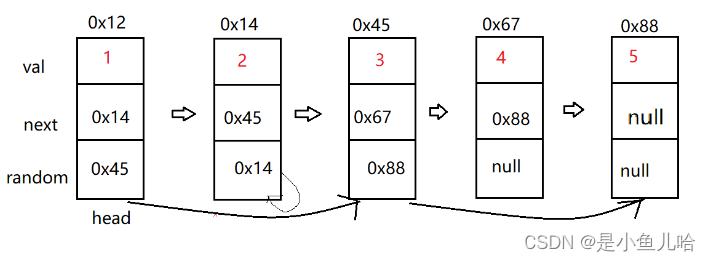
Copy the linked list with random pointer in the "Li Kou brush question plan"
吳恩達團隊2022機器學習課程,來啦
随机推荐
Linear table - abstract data type
FCN: Fully Convolutional Networks for Semantic Segmentation
The origin of PTS, DTS and duration of audio and video packages
MYSQL中 find_in_set() 函数用法详解
Copy the linked list with random pointer in the "Li Kou brush question plan"
U-Net: Convolutional Networks for Biomedical Images Segmentation
瞅一瞅JUC提供的限流工具Semaphore
Nacos distributed transactions Seata * * install JDK on Linux, mysql5.7 start Nacos configure ideal call interface coordination (nanny level detail tutorial)
Clickhouse (03) how to install and deploy Clickhouse
怎么自动安装pythn三方库
【在優麒麟上使用Electron開發桌面應】
Find in MySQL_ in_ Detailed explanation of set() function usage
The 11th China cloud computing standards and Applications Conference | cloud computing national standards and white paper series release, and Huayun data fully participated in the preparation
The 2022 China Xinchuang Ecological Market Research and model selection evaluation report released that Huayun data was selected as the mainstream manufacturer of Xinchuang IT infrastructure!
Various pits of vs2017 QT
如何写出好代码 - 防御式编程
Writing writing writing
案例分享|金融业数据运营运维一体化建设
Multithreading (I) processes and threads
Introduction to VC programming on "suggestions collection"