当前位置:网站首页>[machine learning notes] several methods of splitting data into training sets and test sets
[machine learning notes] several methods of splitting data into training sets and test sets
2022-07-05 13:49:00 【Weichi Begonia】
Problem description :
In general , We are used to referring to 80% As a training set , 20% As test set ( When the amount of data is large enough , Can also be 10% As test set . Small data volume , If the training set is randomly divided every time , After many exercises , The model may be acquired, and the completion is the data set . This is what we want to avoid .
There are several solutions to the above problems :
- Save the test set and training set generated by the first run , In the follow-up training , First load the saved training set and test set data
- Set up random_state, Ensure that the test set allocated each time is the same
- These two methods , When the original data set is increased , There will still be the problem of mixing test data and training data , So when raw data sets continue to increase , You can convert a field in the dataset into an identifier , Then convert the identifier to a hash value , If Hashi is worth < Maximum hash value * 20%, Will be put into the test set
Method 2 The corresponding code is as follows :
from sklearn.model_selection import train_test_split
# Set the test set size to 20% Raw data , Set up random_state It can ensure that every time you perform training , The split training set and test set are the same , random_state It can be set to any integer , As long as the value used in each training is the same
train_test_split(data, test_size=0.2, random_state=42)
Or use numpy Generate random unordered sequences , To divide the test set and the training set
def split_train_test(data, test_ratio):
np.random.seed(42)
shuffled_indices = np.random.permutation(len(data)) # Generate an unordered index of the same length as the original data
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
Method 3 The corresponding code is as follows :
# Divide the training set and the test set - Method 3
# Data currently selected as the test set , After adding data , To ensure that it will not be selected as a training set
# A unique identifier can be created based on a stable feature , such as id
def test_set_check(identifier, test_ratio):
return crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2 ** 32
def split_train_test_by_id(data, test_ratio, id_column):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio))
return data.loc[~in_test_set], data.loc[in_test_set]
Problem description :
For example, we want to do a sampling survey , The proportion of men and women in the known population is 47% : 53%, Then the proportion of men and women in our sampling data also needs to maintain this proportion , The above random sampling method is obviously dissatisfied with meeting this demand . Divide the population into uniform subsets , Each subset is called a layer , Then extract the correct amount of data from each layer , To ensure that the test set represents the proportion of the total population , This process is Stratified sampling .
# For example, the following example predicts house prices , We know that income is strongly related to house prices , But income is a continuous value , We first divide the income data into 5 files .
from matplotlib import pyplot as plt
housing['income_cat'] = pd.cut(housing['median_income'], bins=[0., 1.5, 3.0, 4.5, 6., np.inf], labels=[1, 2, 3, 4, 5]) # Divide the revenue data into 5 files
housing['income_cat'].hist() # Draw a histogram
plt.show()
# n_splits=1 To divide into 1 Share , The test set size is 20%, random_state=42 Ensure that the test set and training set generated by each training model are unchanged
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing['income_cat']): # Classify according to income category
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
# View the proportion distribution of revenue categories in the test set
print(' The proportion distribution of income categories by stratified sampling :')
print(strat_test_set['income_cat'].value_counts() / len(strat_test_set))
print(' The proportion distribution of income categories in the original data :')
print(housing['income_cat'].value_counts() / len(housing))
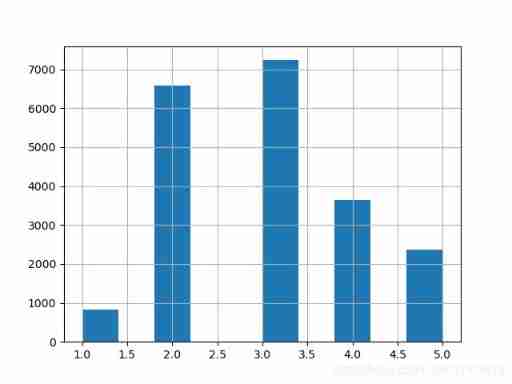
It can be seen that the proportion of each income category after stratified sampling is consistent with the original data
The proportion distribution of income categories by stratified sampling :
3 0.350533
2 0.318798
4 0.176357
5 0.114583
1 0.039729
Name: income_cat, dtype: float64
The proportion distribution of income categories in the original data :
3 0.350581
2 0.318847
4 0.176308
5 0.114438
1 0.039826
Name: income_cat, dtype: float64
边栏推荐
- Wechat app payment callback processing method PHP logging method, notes. 2020/5/26
- Catch all asynchronous artifact completable future
- leetcode 10. Regular expression matching regular expression matching (difficult)
- 这18个网站能让你的页面背景炫酷起来
- About the problem and solution of 403 error in wampserver
- redis6事务和锁机制
- 网络安全-HSRP协议
- Jasypt configuration file encryption | quick start | actual combat
- [cloud resources] what software is good for cloud resource security management? Why?
- What is a network port
猜你喜欢
Win10——轻量级小工具

The real king of caching, Google guava is just a brother

French scholars: the explicability of counter attack under optimal transmission theory

Mmseg - Mutli view time series data inspection and visualization

Attack and defense world web WP
![[server data recovery] a case of RAID5 data recovery stored in a brand of server](/img/04/c9bcf883d45a1de616c4e1b19885a5.png)
[server data recovery] a case of RAID5 data recovery stored in a brand of server

【公开课预告】:视频质量评价基础与实践
Jasypt configuration file encryption | quick start | actual combat
ZABBIX monitoring
The development of speech recognition app with uni app is simple and fast.
随机推荐
Assembly language - Beginner's introduction
The real king of caching, Google guava is just a brother
Data Lake (VII): Iceberg concept and review what is a data Lake
kafaka 日志收集
Operational research 68 | the latest impact factors in 2022 were officially released. Changes in journals in the field of rapid care
Laravel框架运行报错:No application encryption key has been specified
stm32逆向入门
Programmer growth Chapter 8: do a good job of testing
Solve the problem of "unable to open source file" xx.h "in the custom header file on vs from the source
web3.eth. Filter related
French scholars: the explicability of counter attack under optimal transmission theory
53. 最大子数组和:给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
Internal JSON-RPC error. {"code":-32000, "message": "execution reverted"} solve the error
ELFK部署
With 4 years of working experience, you can't tell five ways of communication between multithreads. Dare you believe it?
PHP character capture notes 2020-09-14
redis6事务和锁机制
mysql获得时间
Solution to the prompt of could not close zip file during phpword use
Integer ==比较会自动拆箱 该变量不能赋值为空