当前位置:网站首页>内存墙简介
内存墙简介
2022-07-27 09:17:00 【黄昏贩卖机】
内存墙
以下内容摘录自 一流科技网站
- 近几年CV NLP 语音识别领域的运算量以每两年15倍的速度增长,促进了AI硬件发展
- 通信带宽瓶颈:芯片内部、芯片间、AI硬件之间的通信,称为不少AI应用的瓶颈
- 模型大小平均每两年翻240倍,但是AI硬件的内存大小仅仅每两年翻2倍
- 训练AI模型所需的内存比一般模型的参数量还要多几倍
内存墙不仅和内存容量相关,也包括内存的传输带宽。
- 涉及多个级别的内存数据的传输:
例如,在计算逻辑单元和片上内存之间,或在计算逻辑单元和主存之间,或跨不同插槽上的不同处理器之间的数据传输
上述所有情况中,容量和数据传输的速度都大大落后于硬件计算能力
- 采用分布式的策略将训练扩展到多个AI硬件上,从而突破于当个硬件内存容量和带宽带来的限制。 AI硬件会遇到通信瓶颈,比片上数据搬运更慢
- 分布式策略的横向扩展仅在通信量和数据传输量很少的情况下,才适合解决计算密集型问题
有希望打破内存墙的解决方案
为了继续创新和 “打破内存墙”,我们需要重新思考人工智能模型的设计。这里有几个要点:
- 当前人工智能模型的设计方法大多是临时的,或者仅依赖非常简单的放大规则。(我不太明白)
- 需要更有效的数据方法训练AI模型,当前网络训练非常低效。学要大量数据和数十万次的迭代
- 现有的优化和训练方法,需要大量调整参数,在设置好参数而训练成功前需要数以百计次的试错。
- SOTA类网络规模非常大,光部署她们就极具挑战性。AI硬件涉及主要集中在提高算例,而较少关注改善内存。
训练算法
- 困难:暴力探索式调参
- 微软关于 Zero 论文中介绍了一个很有前景的工作:可以通过删除/切分冗余优化器状态参数[21, 3],在保持内存消耗量不变的前提下,训练8倍大的模型。如果这些高阶方法的引入的 overhead 问题可以得到解决,那么可以显著降低训练大型模型的总成本。
- 提高优化算法的本地属性,并减少内存占用,但是会增加计算量
- 设计足够稳健的、使用与低精度训练的优化算法
高效部署
- 剪枝掉模型中冗余的参数
- 量化,降低精度
结论
目前 NLP 中的 SOTA Transformer 类模型的算力需求,以每两年750倍的速率增长,模型参数数量则以每两年240倍的速率增长。相比之下,硬件算力峰值的增长速率为每两年3.1倍。DRAM 还有硬件互连带宽增长速率则都为每两年1.4倍,已经逐渐被需求甩在身后。深入思考这些数字,过去20年内硬件算力峰值增长了90000倍,但是DRAM/硬件互连带宽只增长了30倍。在这个趋势下,数据传输,特别是芯片内或者芯片间的数据传输会迅速成为训练大规模 AI 模型的瓶颈。所以我们需要重新思考 AI 模型的训练,部署以及模型本身,还要思考,如何在这个越来越有挑战性的内存墙下去设计人工智能硬件。
边栏推荐
- Linux Installation and remote connection MySQL records
- Some practical, commonly used and increasingly efficient kubernetes aliases
- Music experience ceiling! Emotional design details of 14 Netease cloud music
- 二叉树遍历
- async/await的执行顺序以及宏任务和微任务
- Is the operation of assigning values to int variables atomic?
- 【每日算法Day 96】腾讯面试题:合并两个有序数组
- Activation functions commonly used in deep learning
- Nut joke based on arkui ETS
- Openharmony Mengxin contribution Guide
猜你喜欢

MySQL transaction
JS call and apply

Cross domain and processing cross domain

Special exercises for beginners of C language to learn code for the first time
Explanation of common basic controls for C # form application (suitable for Mengxin)
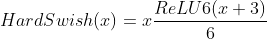
A survey of robust lidar based 3D object detection methods for autonomous driving paper notes

CUDA programming-05: flows and events
Restful

Antdesign a-modal user-defined instruction realizes dragging and zooming in and out

async/await的执行顺序以及宏任务和微任务
随机推荐
Understand various IOU loss functions in target detection
ArkUI中的显式动画
二叉树讲解
qt中使用sqlite同时打开多个数据库文件
Explicit animation in arkui
【云驻共创】华为云:全栈技术创新,深耕数字化,引领云原生
Ztree custom title attribute
[C language - zero basis _ study _ review _ lesson 5] operational properties of basic operators
PVT's spatial reduction attention (SRA)
Is the operation of assigning values to int variables atomic?
NPM install error forced installation
How to upload dynamic GIF map in blog
[cloud native kubernetes practice] deploy the rainbow platform under the kubernetes cluster
Intel, squeezed by Samsung and TSMC, finally put down its body to customize chip technology for Chinese chips
二叉树遍历
巴比特 | 元宇宙每日必读:广州南沙发布“元宇宙九条”措施,平台最高可获得2亿元资金支持...
Full Permutation recursive thought sorting
Detailed explanation of two methods of Sqlalchemy
Five kinds of 2D attention finishing (non local, criss cross, Se, CBAM, dual attention)
[C language - zero foundation lesson 11] rotate the pointer of the big turntable