当前位置:网站首页>MySql COUNT statistics function explanation
MySql COUNT statistics function explanation
2022-08-02 06:44:00 【hungry very hungry】
MySql统计函数COUNT详解
1. COUNT()函数概述
COUNT() 是一个聚合函数,返回指定匹配条件的行数.开发中常用来统计表中数据,全部数据,不为NULL数据,或者去重数据.
2. COUNT()参数说明
COUNT(1):统计不为NULL 的记录.
COUNT(*):统计所有的记录(包括NULL).
COUNT(字段):统计该"字段"不为NULL 的记录.
1.如果这个字段是定义为not null的话,一行行地从记录里面读出这个字段,判断不能为null,按行累加.
2.如果这个字段定义允许为null的话,判断到有可能是null,还要把值取出来在判断一下,不是null才累加.
COUNT(DISTINCT 字段):统计该"字段"去重且不为NULL 的记录.
-- MySql统计函数count测试
-- 创建用户表,新增测试数据
CREATE TABLE `user` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID主键',
`name` varchar(64) DEFAULT NULL COMMENT '姓名',
`sex` varchar(8) DEFAULT NULL COMMENT '性别',
`age` int(4) DEFAULT NULL COMMENT '年龄',
`born` date DEFAULT NULL COMMENT '出生日期',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC COMMENT='用户表';
INSERT INTO `category`.`user`(`id`, `name`, `sex`, `age`, `born`) VALUES (1, '%张三%', '男', 22, '2022-04-22');
INSERT INTO `category`.`user`(`id`, `name`, `sex`, `age`, `born`) VALUES (2, '李四', '女', 12, '2022-04-01');
INSERT INTO `category`.`user`(`id`, `name`, `sex`, `age`, `born`) VALUES (3, '王小二', '女', 12, '2022-04-28');
INSERT INTO `category`.`user`(`id`, `name`, `sex`, `age`, `born`) VALUES (4, '赵四', '男', 23, '2022-04-28');
INSERT INTO `category`.`user`(`id`, `name`, `sex`, `age`, `born`) VALUES (5, '', '女', 23, '2022-04-28');
INSERT INTO `category`.`user`(`id`, `name`, `sex`, `age`, `born`) VALUES (6, NULL, '女', 60, '2022-04-28');
INSERT INTO `category`.`user`(`id`, `name`, `sex`, `age`, `born`) VALUES (7, NULL, '女', 61, '2022-04-28');
select * from user;
-- 统计数据:7条数据,统计所有的记录(包括NULL).
select count(*) from user;
-- 统计数据:7条数据,统计不为NULL 的记录.
select count(1) from user;
-- 统计数据:5条数据,COUNT(字段):统计该"字段"不为NULL 的记录,注意是null不是空''字符串
select count(name) from user;
-- 统计数据:5条数据,COUNT(DISTINCT 字段):统计该"字段"去重且不为NULL 的记录.
select count(distinct name) from user;
3. COUNT()判断存在
SQL不再使用count,而是改用LIMIT 1,让数据库查询时遇到一条就返回,不要再继续查找还有多少条了,业务代码中直接判断是否非空即可.
select 1 from emp LIMIT 1;效率是最高的,尤其是需要limit限制行数,很容易忽略.
-- SQL查找是否"存在"
-- 员工表,存在则进行删除
drop table if EXISTS emp;
create table emp(
id int unsigned primary key auto_increment,
empno mediumint unsigned not null default 0,
empname varchar(20) not null default "",
job varchar(9) not null default "",
mgr mediumint unsigned not null default 0,
hiredate datetime not null,
sal decimal(7,2) not null,
comn decimal(7,2) not null,
depno mediumint unsigned not null default 0
);
-- 新增cehsi数据
测试数据:https://blog.csdn.net/m0_37583655/article/details/124385347
-- cahxun
select * from emp ;
-- 时间:1.082s,数据:5000000
explain select count(*) from emp;
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
1 SIMPLE Select tables optimized away
-- 时间:1.129s,数据:5000000
explain select count(1) from emp;
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
1 SIMPLE Select tables optimized away
-- 时间:1.695s,数据:5000000
explain select 1 from emp;
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
1 SIMPLE emp idx_emp_depno 3 4981060 100.00 Using index
-- SQL不再使用count,而是改用LIMIT 1,让数据库查询时遇到一条就返回,不要再继续查找还有多少条了,业务代码中直接判断是否非空即可
-- 时间:0.001s,数据:5000000
explain select 1 from emp LIMIT 1;
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
1 SIMPLE emp idx_emp_depno 3 4981060 100.00 Using index
4. COUNT()阿里开发规范
1.【强制】不要使用 count(列名)或 count(常量)来替代 count(),count()是 SQL92 定义的标 准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关. 说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行.
2.【强制】count(distinct col) 计算该列除 NULL 之外的不重复行数,注意 count(distinct col1, col2) 如果其中一列全为 NULL,那么即使另一列有不同的值,也返回为 0.

先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在.深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小.自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前.因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担.添加下方名片,即可获取全套学习资料哦
边栏推荐
猜你喜欢

npm does not recognize the "npm" item as the name of a cmdlet, function, script file, or runnable program.Please check the spelling of the name, and if the path is included, make sure the path is corr
25K test old bird's 6-year experience in interviews, four types of companies, four types of questions...

51 MCU Peripherals: Infrared Communication

The advantages of making web3d dynamic product display

npm、nrm两种方式查看源和切换镜像

npm、cnpm的安装

Shuttle + Alluxio 加速内存Shuffle起飞

Analysis of port 9848 error at startup of Nacos client (non-version upgrade problem)
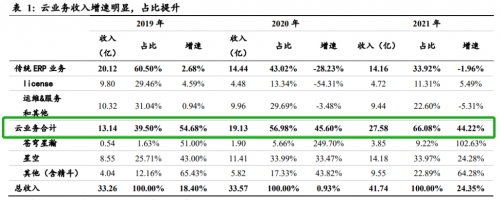
金蝶国际:半年亏掉去年一年,疯狂烧钱的商业模式如何持续

金山云团队分享 | 5000字读懂Presto如何与Alluxio搭配
随机推荐
Stress testing and performance analysis of node projects
DNS的解析流程
zabbix自动发现和自动注册
Point Density-Aware Voxels for LiDAR 3D Object Detection 论文笔记
路由规划中级篇
leetcode一步解决链表反转问题
秒杀系统小demo
关于鸿蒙系统 JS UI 框架源码的分析
Redis(十一) - 异步优化秒杀
Meta公司新探索 | 利用Alluxio数据缓存降低Presto延迟
Leetcode parentheses matching problem -- 32. The longest parentheses effectively
股价屡创新低 地产SaaS巨头陷入困境 明源云该如何转型自救?
MySQL联合查询(多表查询)
leetcode一步解决链表合并问题
Nacos安装详细过程
Differences between i++ and ++i in loops in C language
How to install the specified version package with NPM and view the version number
npm ---- install yarn
nacos registry
pytorch基本操作:使用神经网络进行分类任务