当前位置:网站首页>CUDA中的线程层次
CUDA中的线程层次
2022-07-02 06:12:00 【扫地的小何尚】
线程层次
为方便起见,threadIdx 是一个 3 分量向量,因此可以使用一维、二维或三维的线程索引来识别线程,形成一个一维、二维或三维的线程块,称为block。 这提供了一种跨域的元素(例如向量、矩阵或体积)调用计算的方法。
线程的索引和它的线程 ID 以一种直接的方式相互关联:对于一维块,它们是相同的; 对于大小为(Dx, Dy)的二维块,索引为(x, y)的线程的线程ID为(x + y*Dx); 对于大小为 (Dx, Dy, Dz) 的三维块,索引为 (x, y, z) 的线程的线程 ID 为 (x + y*Dx + z*Dx*Dy)。
例如,下面的代码将两个大小为NxN的矩阵A和B相加,并将结果存储到矩阵C中:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
每个块的线程数量是有限制的,因为一个块的所有线程都应该驻留在同一个处理器核心上,并且必须共享该核心有限的内存资源。在当前的gpu上,一个线程块可能包含多达1024个线程。
但是,一个内核可以由多个形状相同的线程块执行,因此线程总数等于每个块的线程数乘以块数。
块被组织成一维、二维或三维的线程块网格(grid),如下图所示。网格中的线程块数量通常由正在处理的数据的大小决定,通常超过系统中的处理器数量。
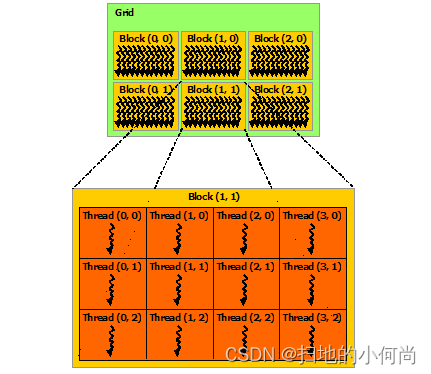
<<<...>>> 语法中指定的每个块的线程数和每个网格的块数可以是 int或 dim3 类型。如上例所示,可以指定二维块或网格。
网格中的每个块都可以由一个一维、二维或三维的惟一索引标识,该索引可以通过内置的blockIdx变量在内核中访问。线程块的维度可以通过内置的blockDim变量在内核中访问。
扩展前面的MatAdd()示例来处理多个块,代码如下所示。
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
线程块大小为16x16(256个线程),尽管在本例中是任意更改的,但这是一种常见的选择。网格是用足够的块创建的,这样每个矩阵元素就有一个线程来处理。为简单起见,本例假设每个维度中每个网格的线程数可以被该维度中每个块的线程数整除,尽管事实并非如此。
程块需要独立执行:必须可以以任何顺序执行它们,并行或串行。 这种独立性要求允许跨任意数量的内核以任意顺序调度线程块,如下图所示,使程序员能够编写随内核数量扩展的代码。

块内的线程可以通过一些共享内存共享数据并通过同步它们的执行来协调内存访问来进行协作。 更准确地说,可以通过调用 __syncthreads() 内部函数来指定内核中的同步点; __syncthreads() 充当屏障,块中的所有线程必须等待,然后才能继续。 Shared Memory 给出了一个使用共享内存的例子。 除了 __syncthreads() 之外,Cooperative Groups API 还提供了一组丰富的线程同步示例。
为了高效协作,共享内存是每个处理器内核附近的低延迟内存(很像 L1 缓存),并且 __syncthreads() 是轻量级的。
边栏推荐
- Contest3147 - game 38 of 2021 Freshmen's personal training match_ E: Listen to songs and know music
- The difference between session and cookies
- Mock simulate the background return data with mockjs
- 锐捷EBGP 配置案例
- Frequently asked questions about jetpack compose and material you
- LeetCode 78. subset
- 日志(常用的日志框架)
- 社区说|Kotlin Flow 的原理与设计哲学
- Bgp Routing preference Rules and notice Principles
- Is there a really free applet?
猜你喜欢

链表(线性结构)
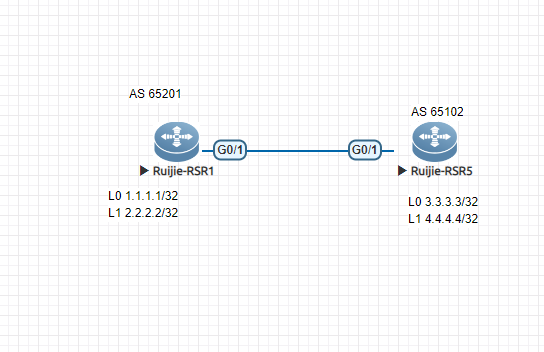
Ruijie ebgp configuration case
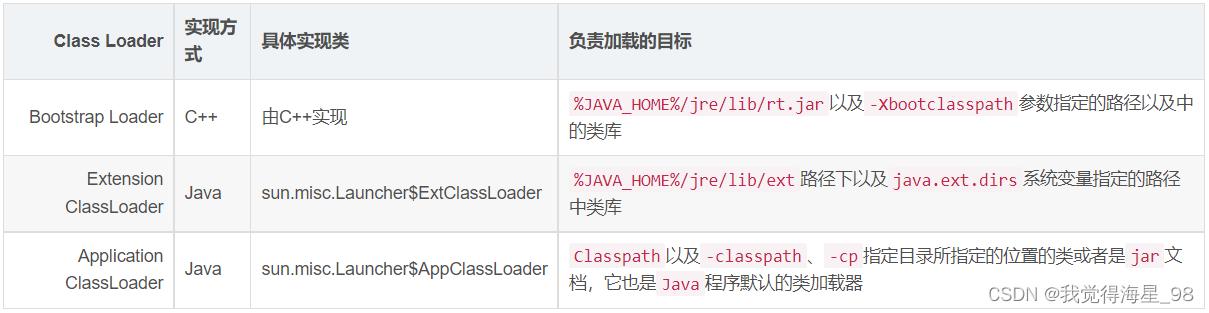
深入学习JVM底层(五):类加载机制

Current situation analysis of Devops and noops

VRRP之监视上行链路

Shenji Bailian 3.54-dichotomy of dyeing judgment
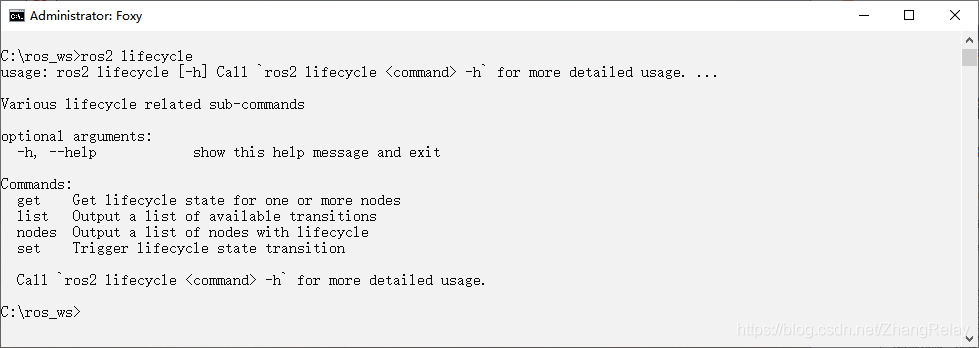
Ros2 --- lifecycle node summary

Sudo right raising

Invalid operation: Load into table ‘sources_orderdata‘ failed. Check ‘stl_load_errors‘ system table

Linear DP (split)
随机推荐
网络相关知识(硬件工程师)
Web page user step-by-step operation guide plug-in driver js
Singleton mode compilation
Flutter hybrid development: develop a simple quick start framework | developers say · dtalk
On Web server
LeetCode 27. 移除元素
加密压缩文件解密技巧
Sumo tutorial Hello World
Ti millimeter wave radar learning (I)
I/o multiplexing & event driven yyds dry inventory
BGP 路由优选规则和通告原则
Invalid operation: Load into table ‘sources_orderdata‘ failed. Check ‘stl_load_errors‘ system table
Lucene Basics
Cookie plugin and localforce offline storage plugin
Deep learning classification network -- vggnet
队列(线性结构)
I/o impressions from readers | prize collection winners list
深入了解JUC并发(一)什么是JUC
CNN visualization technology -- detailed explanation of cam & grad cam and concise implementation of pytorch
Spark overview