当前位置:网站首页>pytorch训练好的模型在加载和保存过程中的问题
pytorch训练好的模型在加载和保存过程中的问题
2022-07-06 08:27:00 【MAR-Sky】
在gpu上训练完成,在cpu上加载
torch.save(model.state_dict(), PATH)# 在gpu上训练后保存
# 在cpu的模型上加载使用
model.load_state_dict(torch.load(PATH, map_location='cpu'))
在cpu上训练完成,在gpu上加载
torch.save(model.state_dict(), PATH)# 在gpu上训练后保存
# 在cpu的模型上加载使用
model.load_state_dict(torch.load(PATH, map_location='cuda:0'))
在使用中需要注意的加载内容
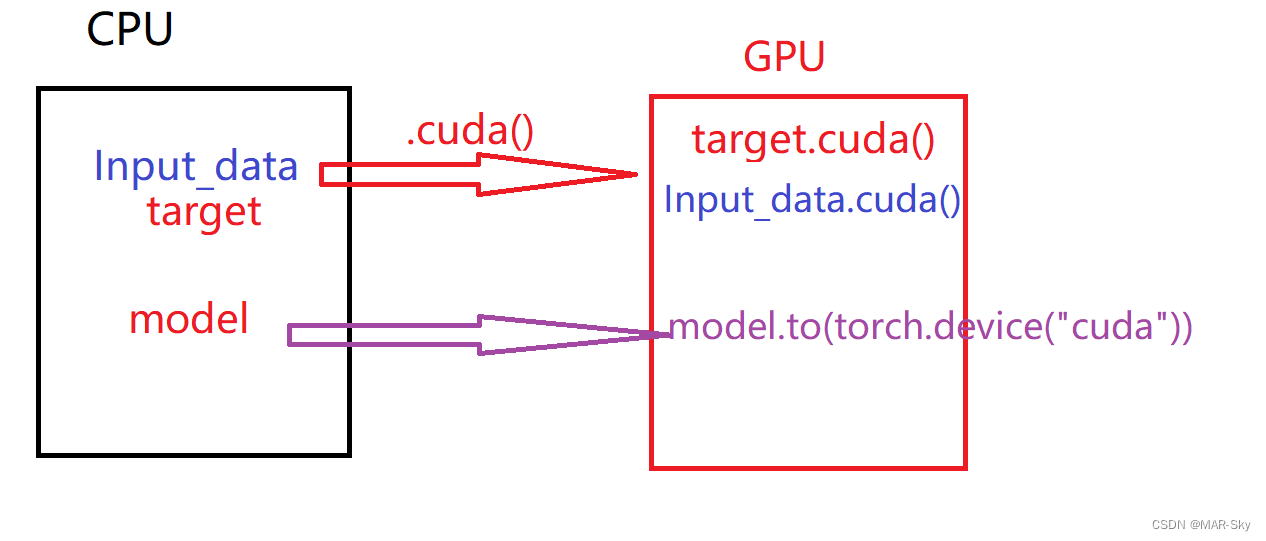
当数据放入GPU,需要训练的模型也要放入GPU
''' data_loader:pytorch中加载数据 '''
for i, sample in enumerate(data_loader): # 对数据进行按批次遍历
image, target = sample # 每一批次加载返回值
if CUDA:
image = image.cuda() # 输入输出传入gpu
target = target.cuda()
# print(target.size)
optimizer.zero_grad() # 优化函数
output = mymodel(image)
mymodel.to(torch.device("cuda"))
多个gpu训练时的加载
参考:https://blog.csdn.net/weixin_43794311/article/details/120940090
import torch.nn as nn
mymodel = nn.DataParallel(mymodel)
pytorch中的nn模块使用nn.DataParallel将模型加载到多个GPU,需要注意,这种加载方式保存的权重参数会比不使用nn.DataParallel加载模型保存的权重参数的关键字前多一个"module."。是否使用nn.DataParallel加载模型,会导致下次再加载模型的时候可能会出现下图的问题,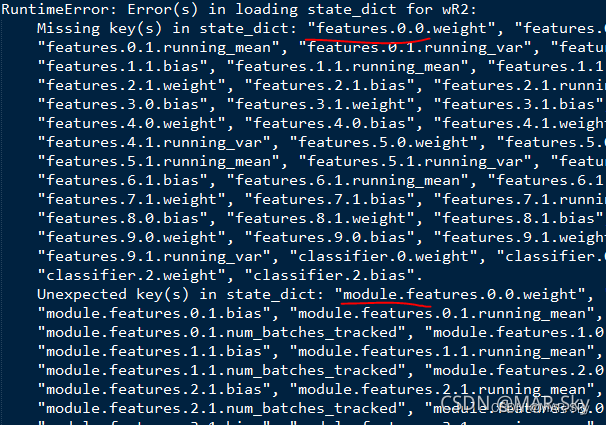
当权重参数前面多一个“module."时,最简单的方式就是使用nn.DataParallel对模型加载,
边栏推荐
- leetcode刷题 (5.28) 哈希表
- [secretly kill little partner pytorch20 days -day01- example of structured data modeling process]
- IOT -- interpreting the four tier architecture of the Internet of things
- Nacos Development Manual
- 升级 TiDB Operator
- 1. Color inversion, logarithmic transformation, gamma transformation source code - miniopencv from zero
- On the inverse order problem of 01 knapsack problem in one-dimensional state
- 从 CSV 文件迁移数据到 TiDB
- [brush questions] top101 must be brushed in the interview of niuke.com
- China Light conveyor belt in-depth research and investment strategy report (2022 Edition)
猜你喜欢
![[research materials] 2021 Research Report on China's smart medical industry - Download attached](/img/c8/a205ddc2835c87efa38808cf31f59e.jpg)
[research materials] 2021 Research Report on China's smart medical industry - Download attached
Hungry for 4 years + Ali for 2 years: some conclusions and Thoughts on the road of research and development
From monomer structure to microservice architecture, introduction to microservices
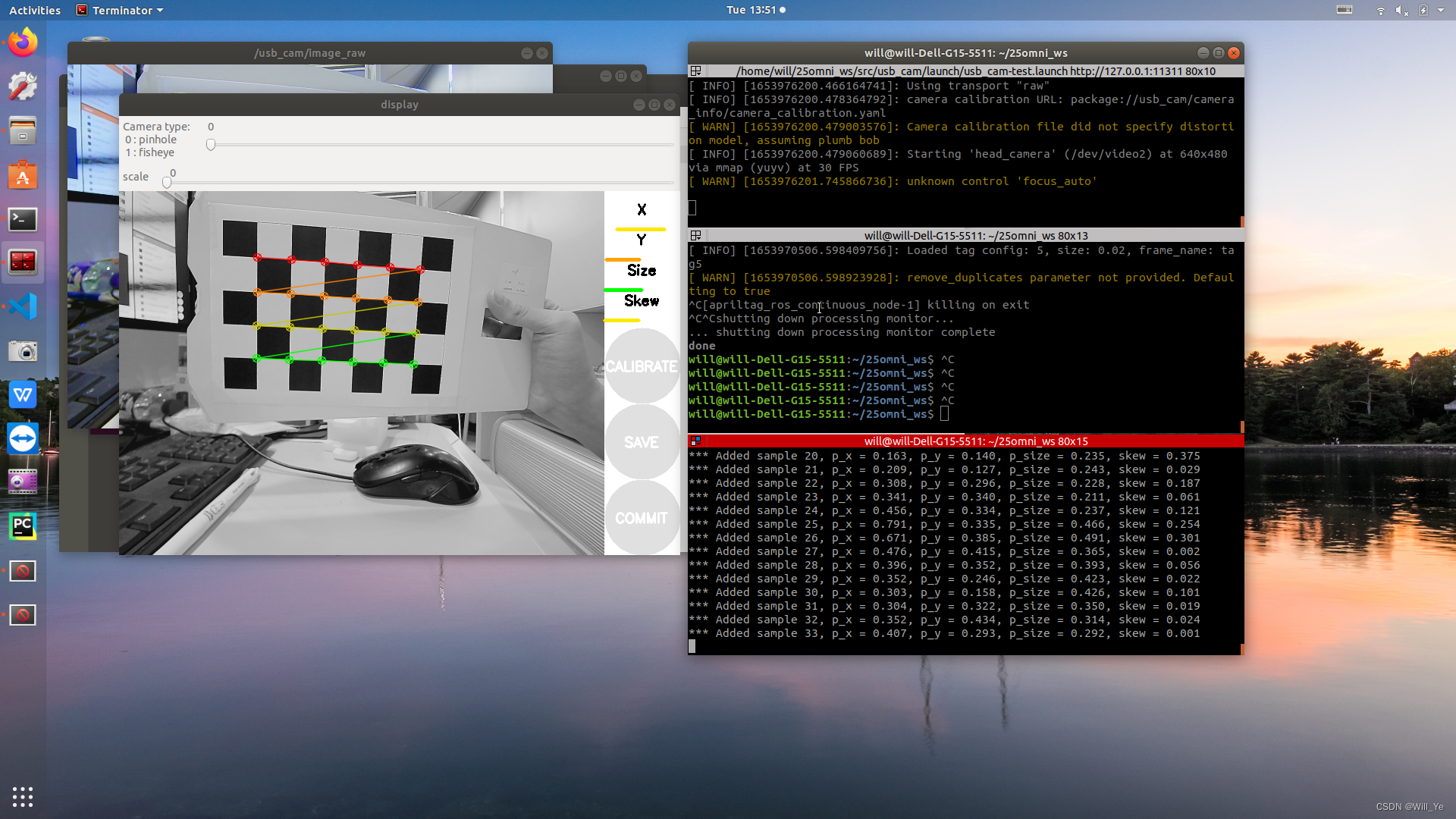
【ROS】usb_cam相机标定

Roguelike游戏成破解重灾区,如何破局?

On the day of resignation, jd.com deleted the database and ran away, and the programmer was sentenced

化不掉的钟薛高,逃不出网红产品的生命周期
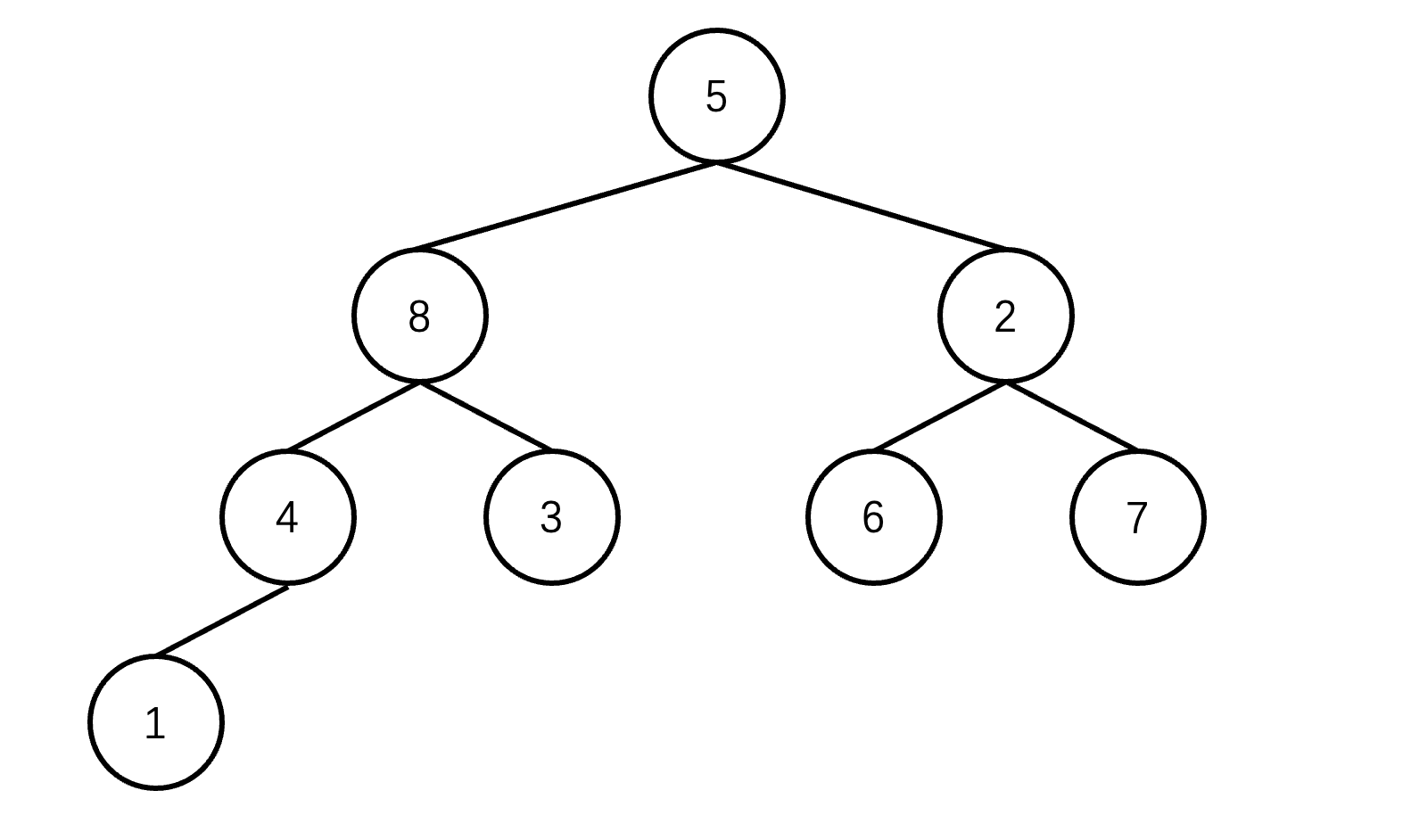
堆排序详解

Chinese Remainder Theorem (Sun Tzu theorem) principle and template code
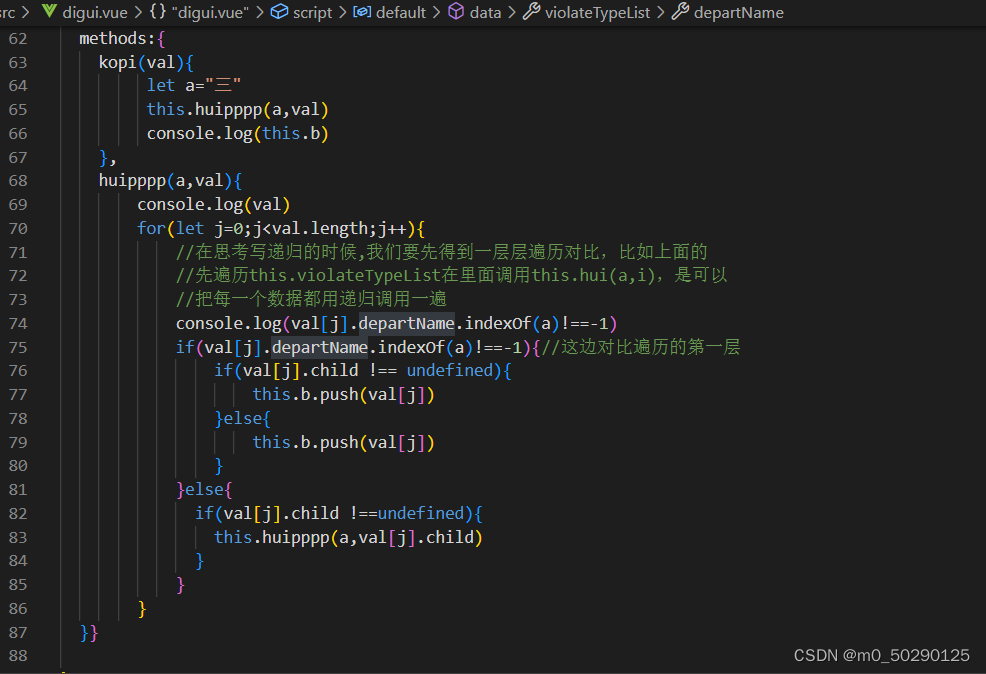
Precise query of tree tree
随机推荐
logback1.3. X configuration details and Practice
Browser thread
C language custom type: struct
[2022 Guangdong saim] Lagrange interpolation (multivariate function extreme value divide and conquer NTT)
tree树的精准查询
Let the bullets fly for a while
Leetcode skimming (5.29) hash table
Research Report on supply and demand and development prospects of China's high purity aluminum market (2022 Edition)
Bottom up - physical layer
Synchronized solves problems caused by sharing
MySQL learning records 12jdbc operation transactions
Migrate data from CSV files to tidb
指针进阶---指针数组,数组指针
使用 TiUP 升级 TiDB
延迟初始化和密封类
IOT -- interpreting the four tier architecture of the Internet of things
hcip--mpls
Tidb backup and recovery introduction
Cisp-pte practice explanation
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower