当前位置:网站首页>Basics of reptile - Scratch reptile
Basics of reptile - Scratch reptile
2022-07-06 07:27:00 【Top Secret】
Catalog
1. scrapy- Environment building
2. scrapy- Climb the web - Transfer files to local
4.1 Scrapy Homework -Scrapy shell
7. pycharm Operating the database
8.1 scrapy startproject doubanmovie
8.2 Edit the container file that saves the data :items.py
8.3 Switch terminal Catalog :cd doubanmovie
8.5 To configure pipelines.py file ( To achieve persistent storage )
8.6 climb :scrapy crawl doubanspider
scrapy Reptiles :
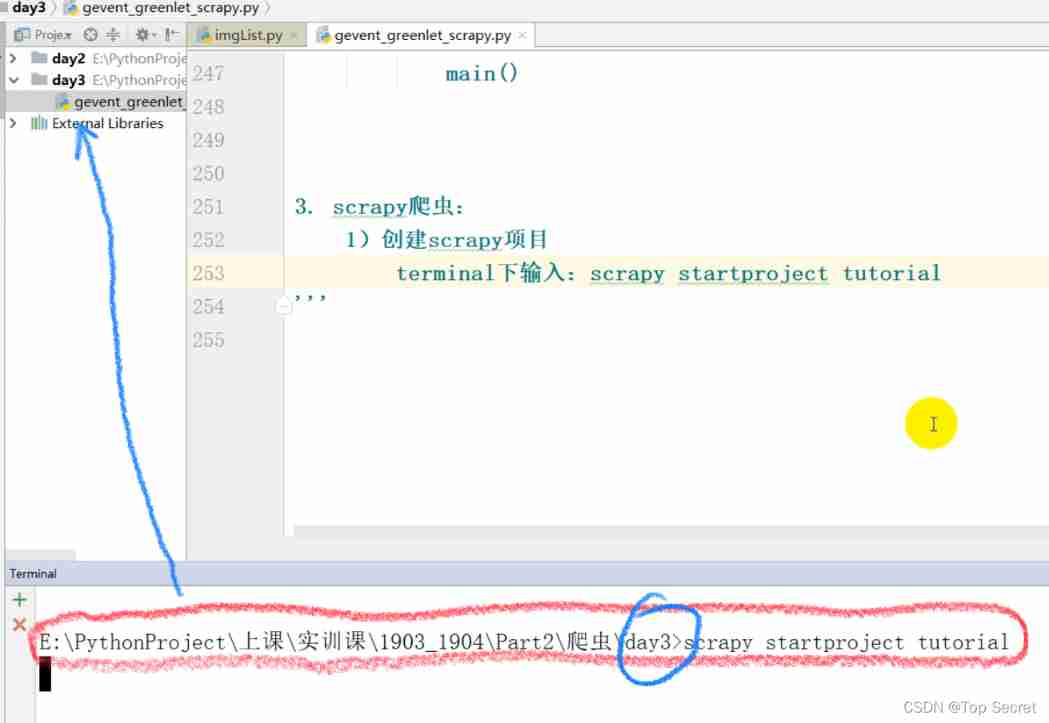
1) establish scrapy project
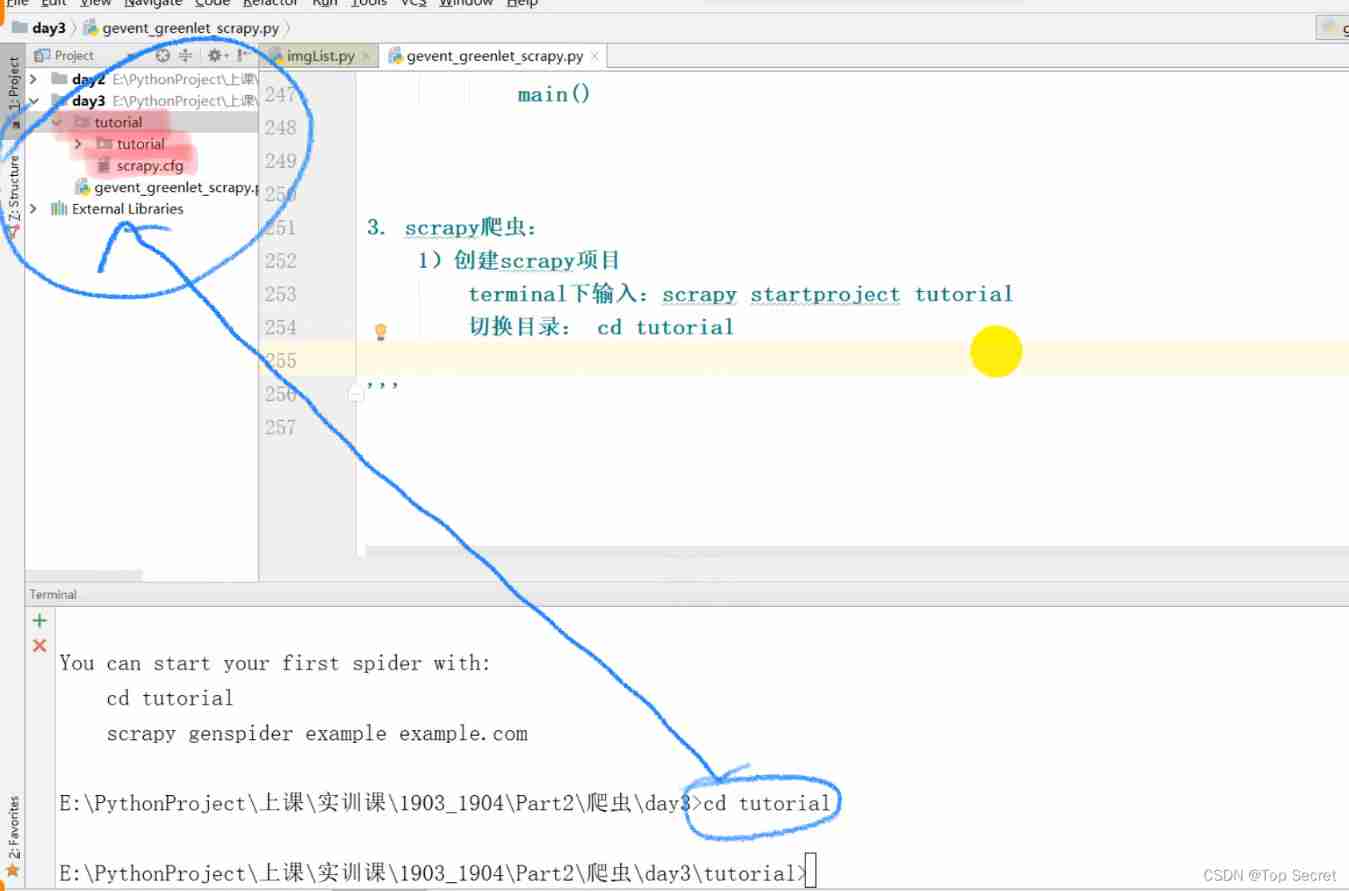
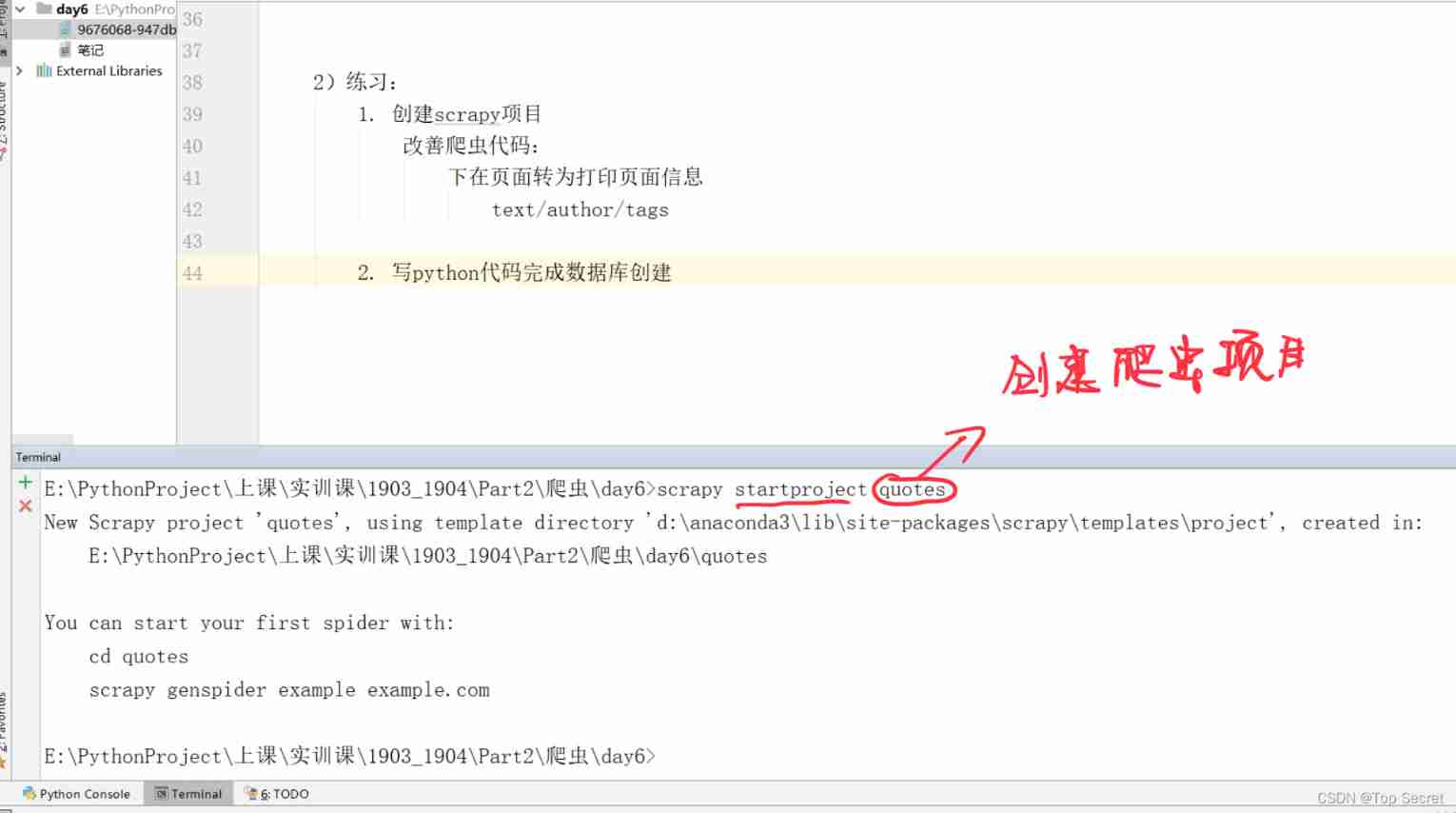
terminal The input :scrapy startproject tutorial
Toggle directory : cd tutorial
After execution of the above order , Automatically created scrapy project
Generated the project directory -tutorial
scrapy.cfg Deployment profile
tutorial/
__init__.py Initialization file , No operation for the time being
items.py Project definition file
middlewares.py Middleware files
pipelines.py Project pipeline file
settings.py Project profile
spiders/ Crawler directory
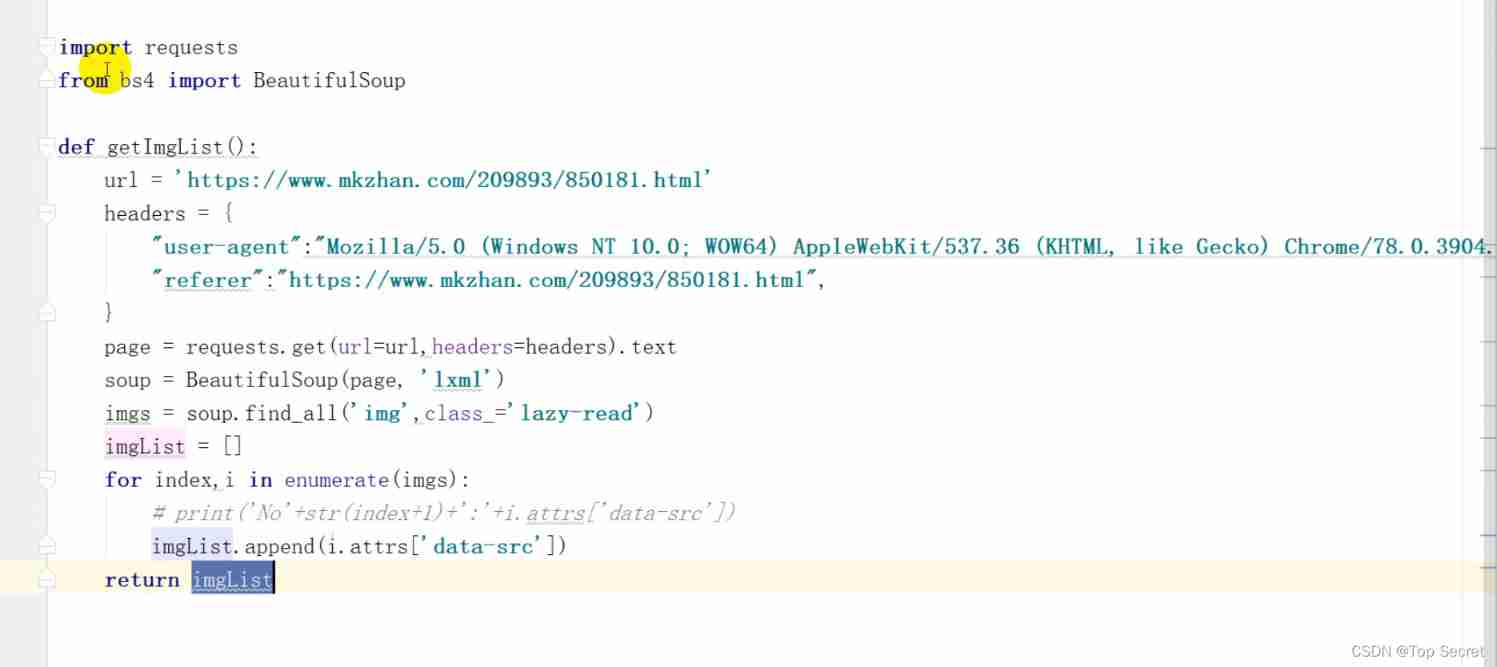

2) Create crawler code
establish \spiders\quotes_spider.py file ( In the crawler directory spiders Create crawler file under quotes_spider.py)
Write the following :
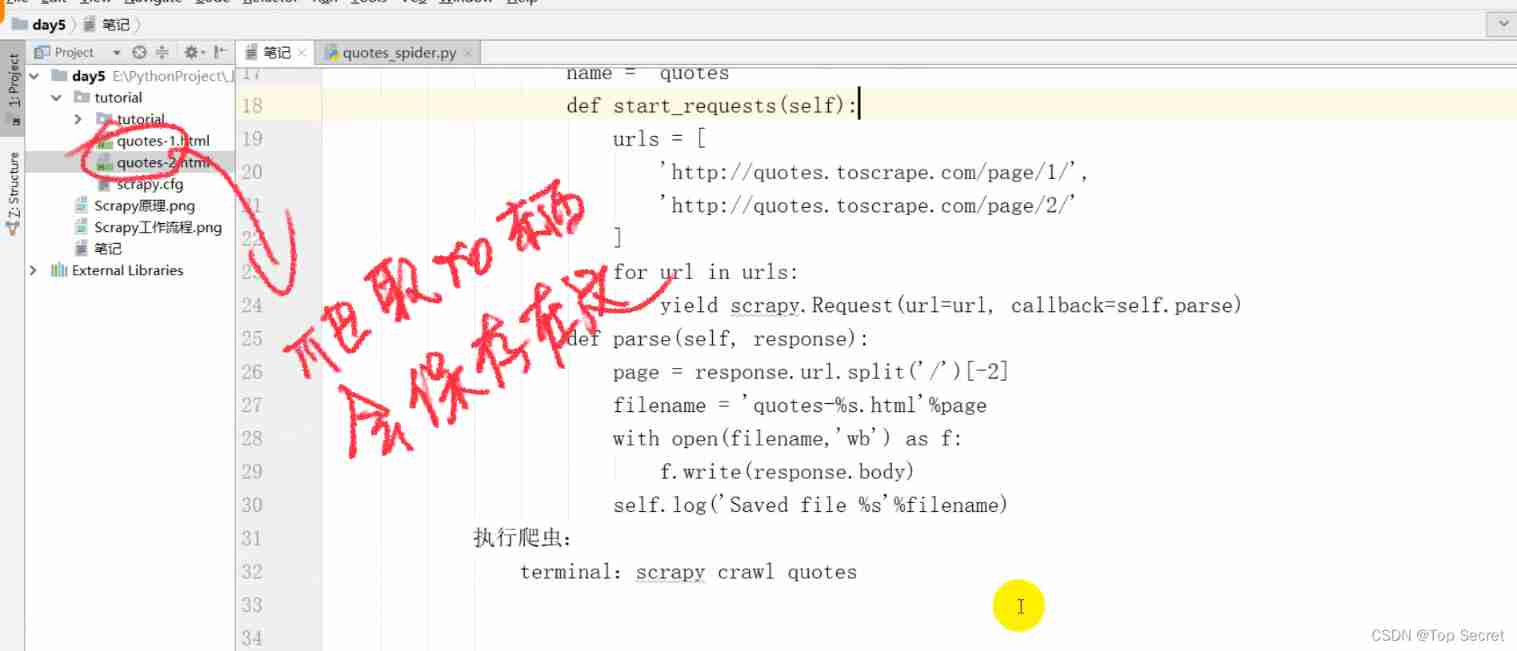
import scrapy
class QuotesSpider(scrapy.Spider):# Must inherit scarpy.Spider class
name = 'quotes' # Crawler item unique identifier
# Create a crawler method
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split('/')[-2]
filename = 'quotes-%s.html'%page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s'%filename)
3) Reptiles :
terminal Next :
scrapy crawl quotes
--------------------------------------------------------------------------------------------------------------------------------
( Synthesize the above contents )
1. scrapy- Environment building
2. scrapy- Climb the web - Transfer files to local
1) terminal Next : establish scrapy project -tutorial
scrapy startproject tutorial
Again cd To tutorial
The webpage that crawls data is :
http://quotes.toscrape.com/page/1/
http://quotes.toscrape.com/page/2/
2) In the project directory :
tutorial/
tutorial/
spiders Create a crawler code file under the folder :quotes_spider.py Write unknown crawler code
import scrapy
class QuotesSpider(scrapy.Spider): # Define classes and inherit scrapy.Spider
name = 'quotes'
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/'
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split('/')[-2]
filename = 'quotes-%s.html'%page
with open(filename,'wb') as f:
f.write(response.body)
self.log('Saved file %s'%filename)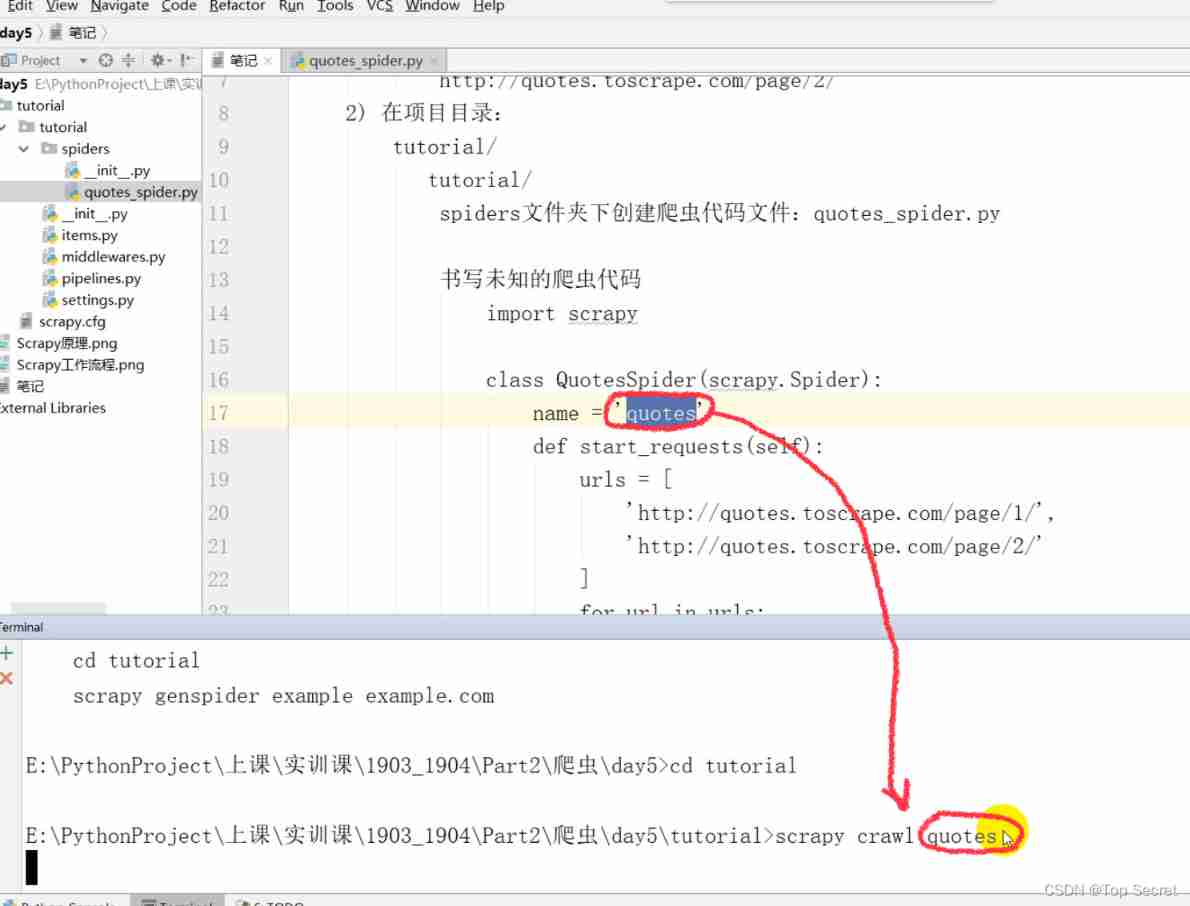
Execute the crawler :
terminal:scrapy crawl quotes
3. scrapy principle
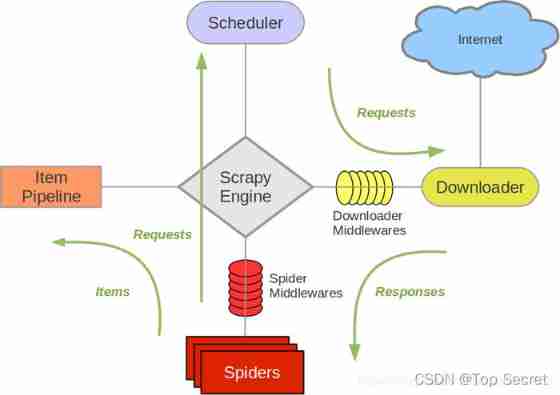
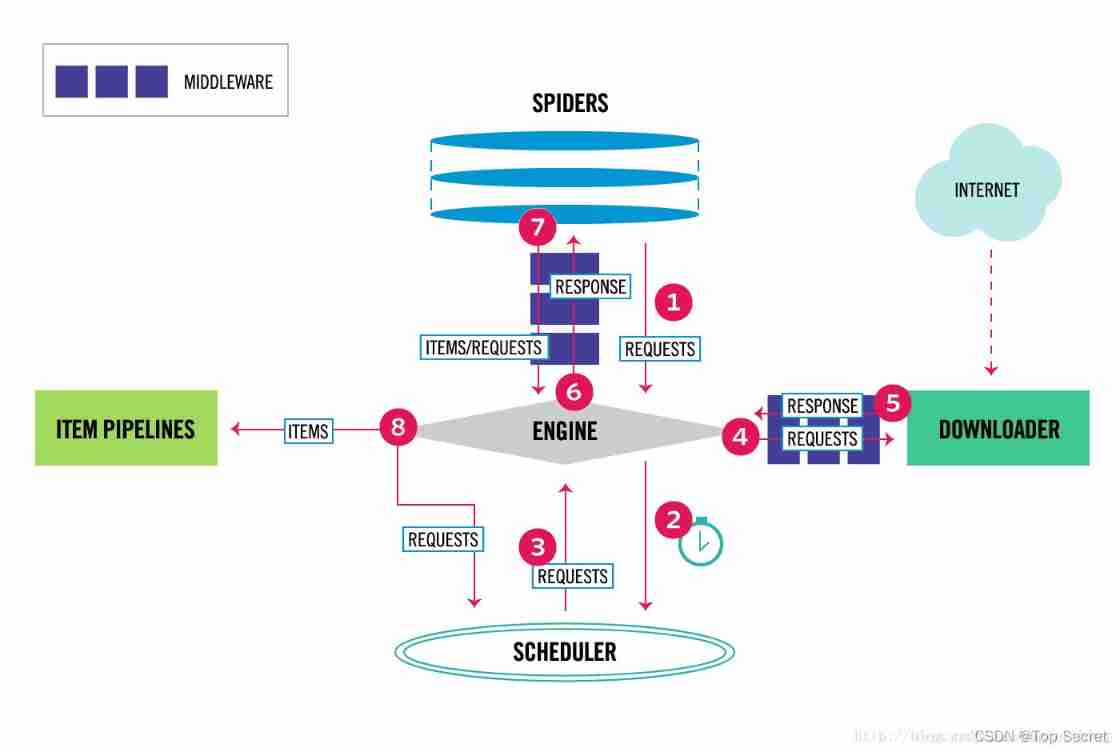
1)Scrapy Engine engine
Be responsible for controlling the flow of data flow in system components , An event is triggered when a specific action occurs
2)Scheduler Scheduler
Receive from the engine request And put them in the team
3)Downloader Downloader
Be responsible for obtaining page data and providing it to the engine , Then provide it to spider
4)Spiders Reptiles
It is Scrapy User written for analysis response And get item Or additional data
5)ItemPiPeline The Conduit
Responsible for Spider The data extracted by the crawler is persisted
6)Downloader Middleware Downloader middleware
It is a specific component between the engine and the downloader , Have 㔘Downloader Pass it on to the engine response
7)Spider Middleware Spider middleware
Handle spider Input response And output items and requests
4. Scrapy shell
http://quotes.toscrape.com/page/1/
terminal The input :
scrapy shell "http://quotes.toscrape.com/page/1/"
Extract the title
response.css('title')
Extract title text
response.css('title').extract()
Extract title text , Return to the text content list
response.css('title::text').extract()
Text content in string format
response.css('title::text').extract_first()
perhaps
response.css('title::text')[0].extract()
5. Homework :terminal Send the input and output contents under to the mailbox [email protected]
Use scrapy shell Crawl page information
scrapy shell ‘http://quotes.toscrape.com’
1) look for css Content :div label , The property value is quote
2) The content output of the first famous quote
3) The author output of the first famous quote
4.1 Scrapy Homework -Scrapy shell
1)terminal Next :
scrapy shell "http://quotes.toscrape.com/"
response: Response information after request
Get page content :
.css
.xpath
Return to page information :
extract()
extract_first()
Get the page title
response.xpath('//title/text()').extract_first()
The first paragraph
quote = response.css('div.quote')[0]
In the first paragraph - quotes
title = quote.css('span.text::text').extract_first()
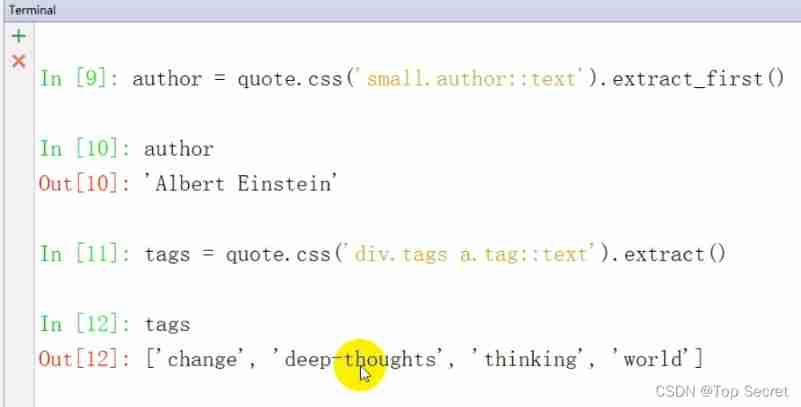
In the first paragraph - author
author = quote.css('small.author::text').extract_first()
In the first paragraph - label
tags = quote.css('div.tags a.tag::text').extract()

Traverse the entire page :
Output each piece of information in turn
In [13]: for quote in response.css('div.quote'):
...: text = quote.css('span.text::text').extract_first()
...: author = quote.css('small.author::text').extract_first()
...: tags = quote.css('div.tags a.tag::text').extract()
...: print(dict(text=text,author=author,tags=tags))
Exit interactive mode :
exit
2) practice :
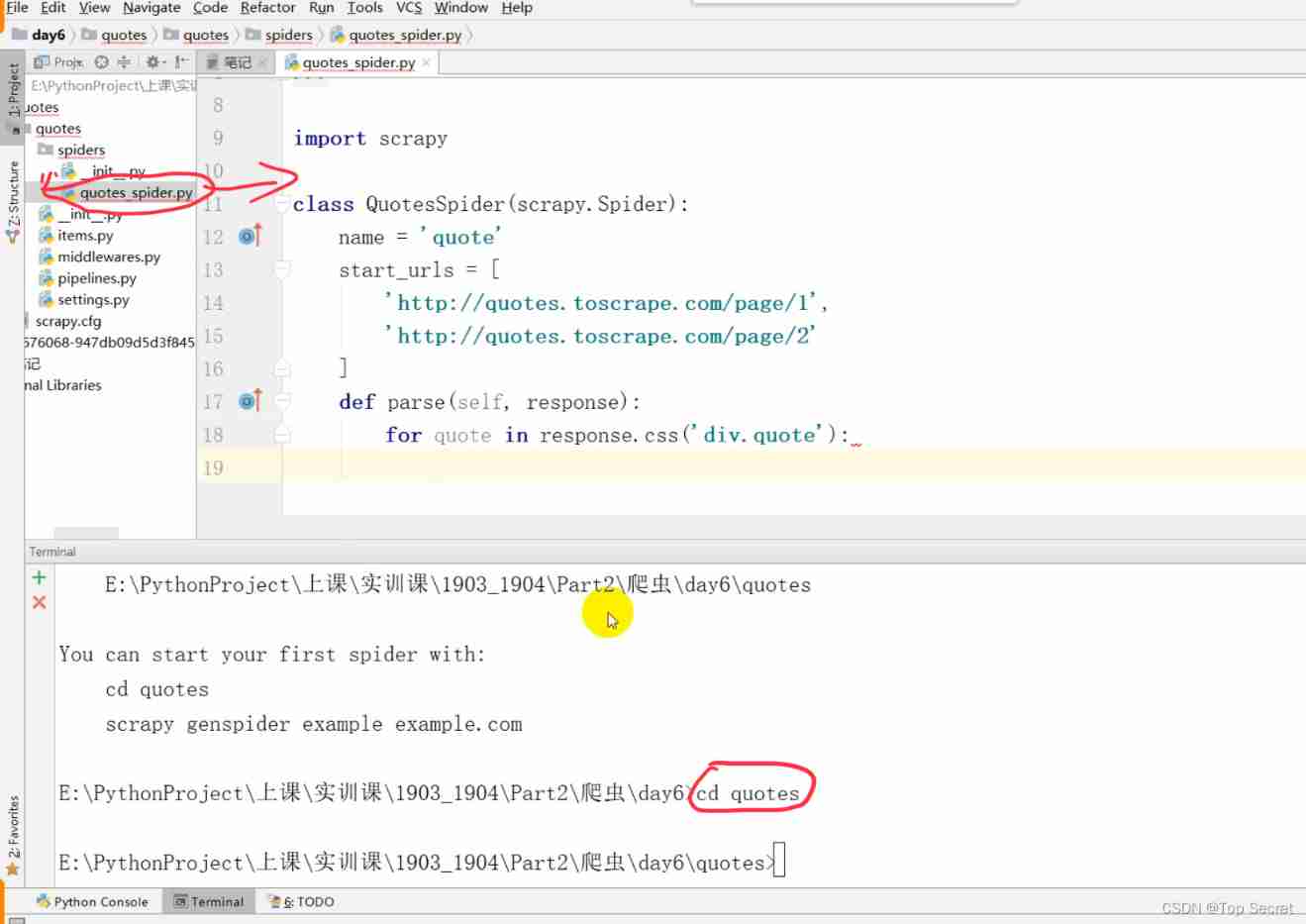
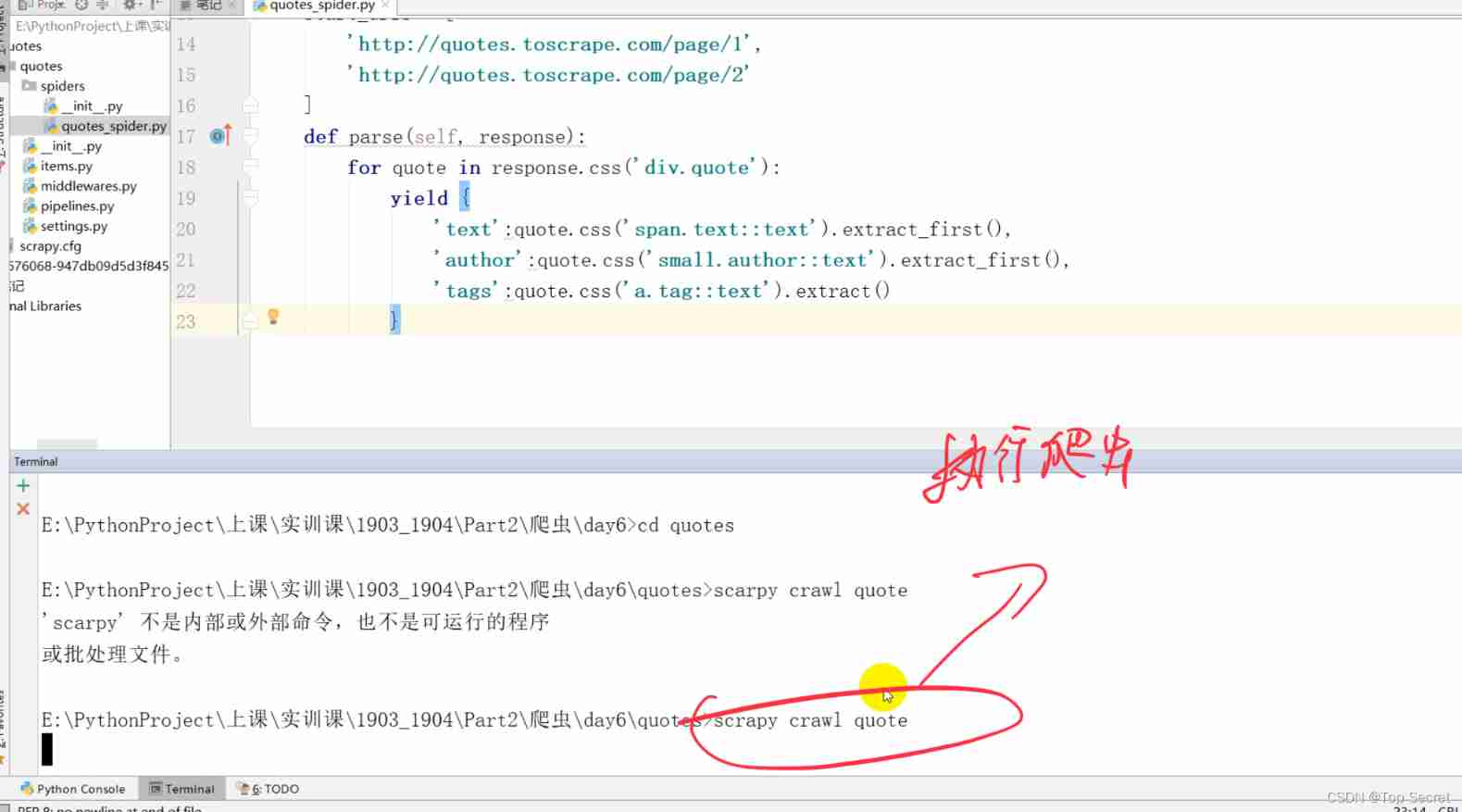
1. establish scrapy project
Improve crawler code :
The next page turns to print page information
text/author/tags
Code :
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quote'
start_urls = [
'http://quotes.toscrape.com/page/1',
'http://quotes.toscrape.com/page/2'
]
def parse(self, response): # Parsing the page
for quote in response.css('div.quote'):
yield {
'text':quote.css('span.text::text').extract_first(),
'author':quote.css('small.author::text').extract_first(),
'tags':quote.css('a.tag::text').extract()
}
2. Write python The code completes the database creation
import pymysql
con = pymysql.connect(
host = 'localhost',
user = 'root',
passwd = '123456',
charset = 'utf8'
)
cur = con.cursor()
cur.execute('CREATE DATABASE doubanmovie CHARACTER set utf8')
cur.execute('USE doubanmovie')
cur.execute("""
CREATE TABLE doubantop250(
ID INT (3) PRIMARY KEY NOT NULL AUTO_INCREMENT,
title VARCHAR (100),
movieinfo VARCHAR (1000),
star FLOAT (3,1) NOT NULL ,
quote VARCHAR (300) NOT NULL
)
CHARACTER SET utf8;
""")
con.commit()
cur.close()
con.close()scrapy Official documents :
https://www.osgeo.cn/scrapy/topics/downloader-middleware.html
5. scrapy Command line tools
2. scrapy Command line tools
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
------------------------------------------------------------
1)scrapy startproject project_name
stay scrapy Under project directory establish project_name engineering
2)scrapy genspider name domain
Create a crawler under the current folder , among name Is the name of the reptile
domain Used to generate crawler file properties allowd_domain as well as start_urls
scrapy genspider -l
Call the crawler template
Available templates:
basic
crawl
csvfeed
xmlfeed
scrapy genspider example example.com
Created spider 'example' using template 'basic' in module:
myProject.spiders.example
3)scrapy crawl spider_name
Start crawling
4)scrapy check
Check for errors
5)scrapy list
List the available crawler codes in the current project , Press the line
6) scrapy edit spider_name
Edit or debug crawler code
7)scrapy fetch url
Use scrapy Downloader for a given url Output content
8)scrapy view url
Open the given... In the browser url
9)scrapy parse url
Page parsing , The parsing result passes callback Option delivery
10)scrapy runspider spider_file.py
Run the crawler file
11)scrapy version
View version number
12)scrapy bench
Run a quick benchmark
6.Spider Folder
2. Spider Folder : What are the operations completed by the crawler ? Grab Web Information Extract formatted data What needs to be done in the framework ? 1) Generate Royal grab url Then specify the corresponding callback function under the request mode start_requests(): It specifies url,callback Parameter assignment parse Method parse(): Get page data 2) The callback function parses the web page , Returns... With extracted data Item object , Request Request object , And then execute scrapy download 3) Use... In callback functions parse Method resolution 4) Return data from item Persistence in the project
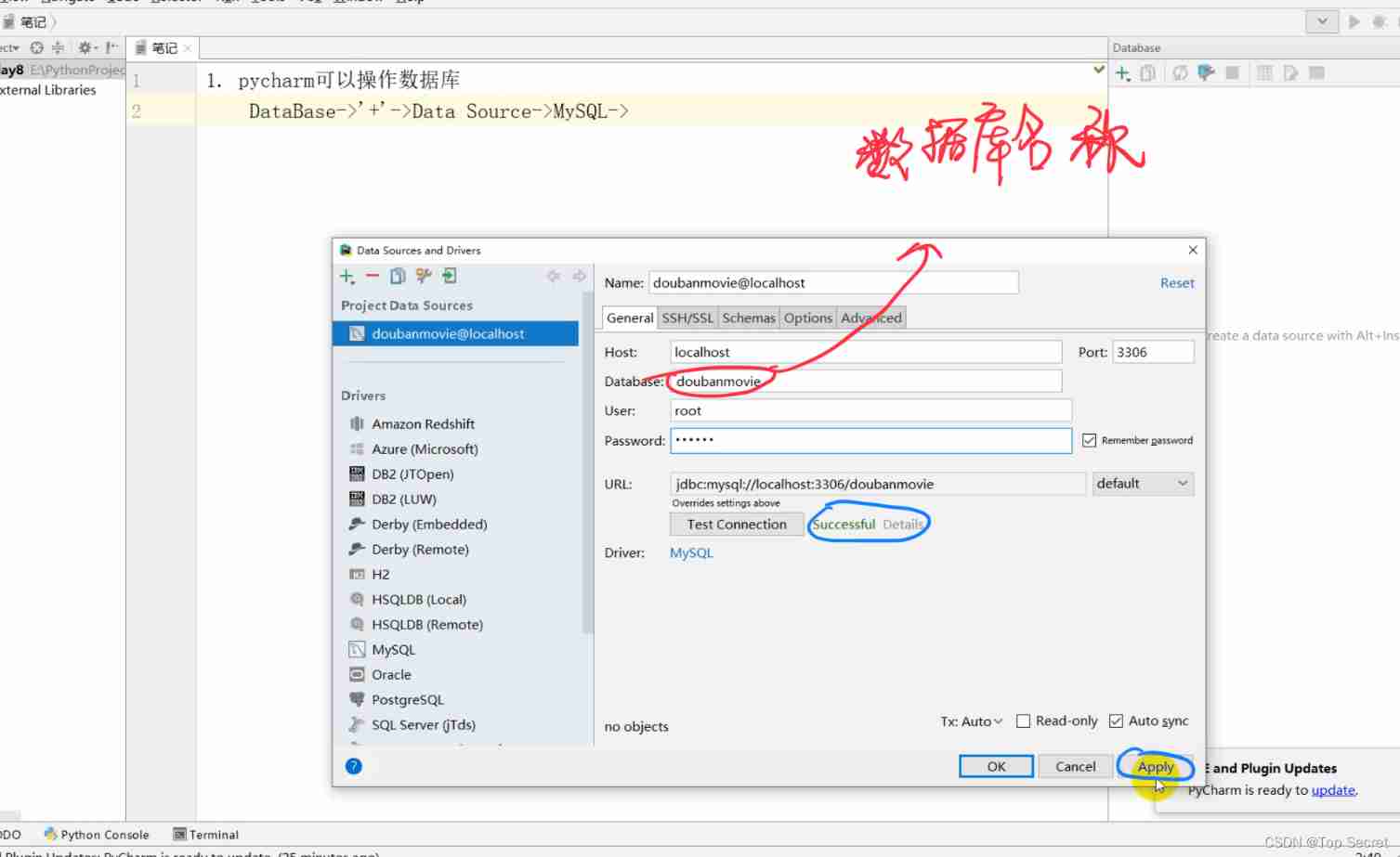
7. pycharm Operating the database
pycharm You can manipulate the database
DataBase->'+'->Data Source->MySQL->
Parameter configuration :
HOST
Database
User
Password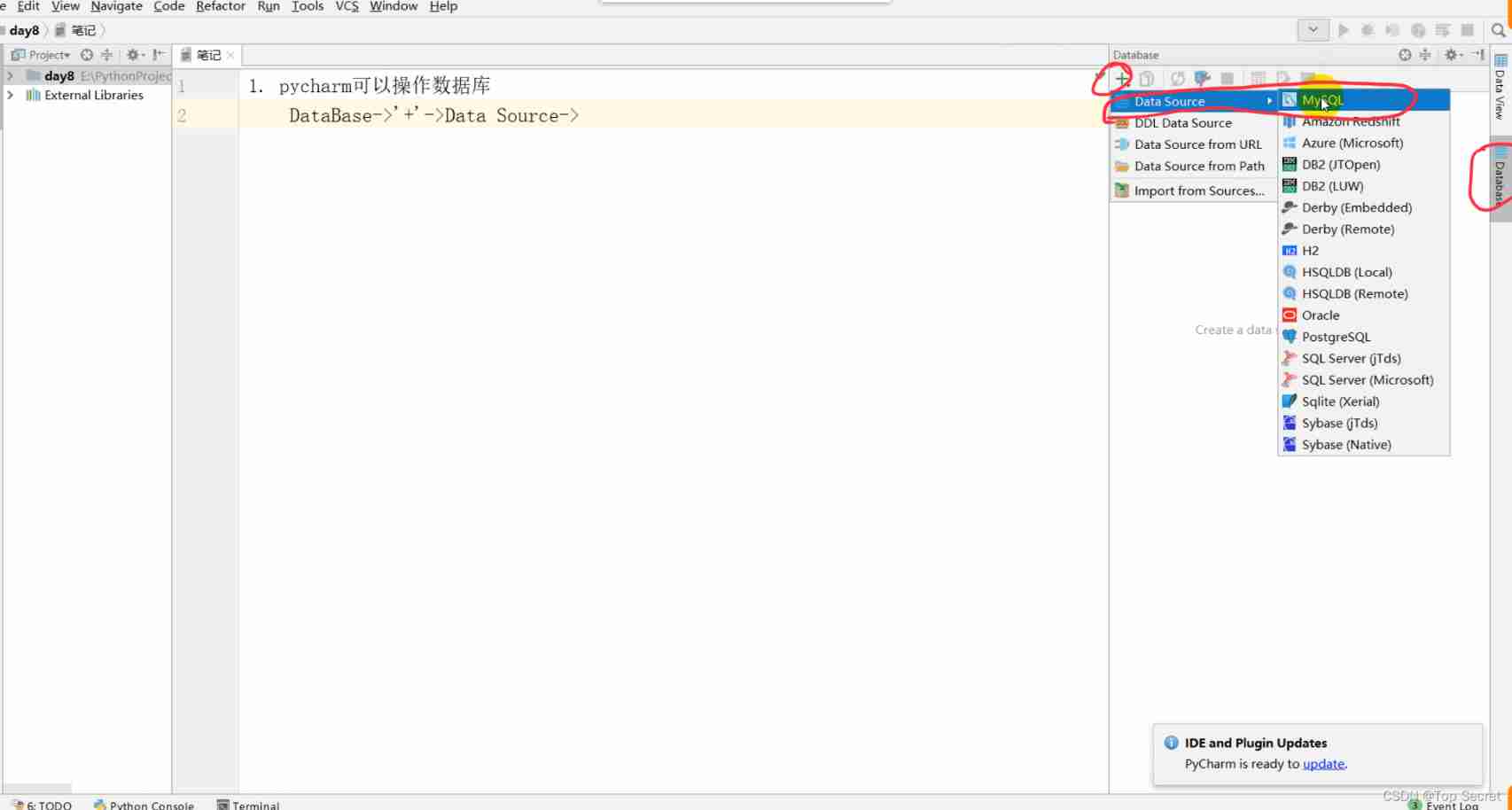
8. scrapy Climb Douban
8.1 scrapy startproject doubanmovie
Switch terminal Catalog :cd doubanmovie
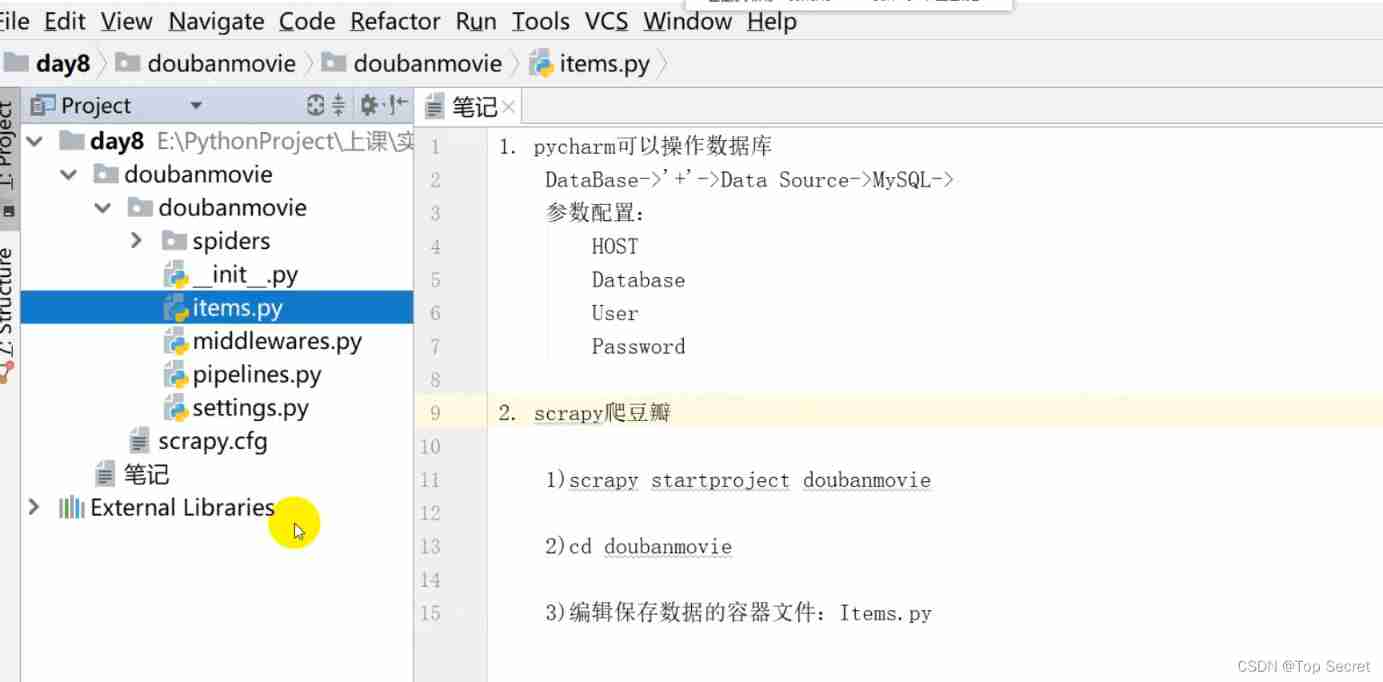
8.2 Edit the container file that saves the data :items.py
import scrapy
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # The movie name
movieinfo = scrapy.Field() # Movie description information
star = scrapy.Field() # Movie ratings
quote = scrapy.Field() # jurassic park
pass
8.3 Switch terminal Catalog :cd doubanmovie
Create crawler file (terminal Run under )
scrapy genspider doubanspider douban.com( domain name )
Edit the crawler file :doubanspider.py
import scrapy
from scrapy.http import Request # The module that sent the request
from scrapy.selector import Selector # Module method of parsing response - Selectors
from doubanmovie.items import DoubanmovieItem # Import container
from urllib.parse import urljoin # url Complement function
# The object to crawl
class DoubanspiderSpider(scrapy.Spider):
name = 'doubanspider'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
item = DoubanmovieItem() # Create a container
selector = Selector(response) # Create selector # analysis
Movies = selector.xpath('') # The area of the whole movie in the page ('' The middle is a big box xpath)
# Get each movie information in the loop
for eachMovie in Movies:
# Analyze the four pieces of information collected from each movie
title = eachMovie.xpath('').extract()
movieinfo = eachMovie.xpath('').extract()
star = eachMovie.xpath('').extract()
quote = eachMovie.xpath('').extract()
if quote:
quote = quote[0]
else:
quote = ''
# The parsed content is saved to the container
item['title'] = title
item['movieinfo'] = movieinfo
item['star'] = star
item['quote'] = quote
yield item
# Parse multiple pages
nextLink = selector.xpath('').extract()
if nextLink:
nextLink = nextLink[0]
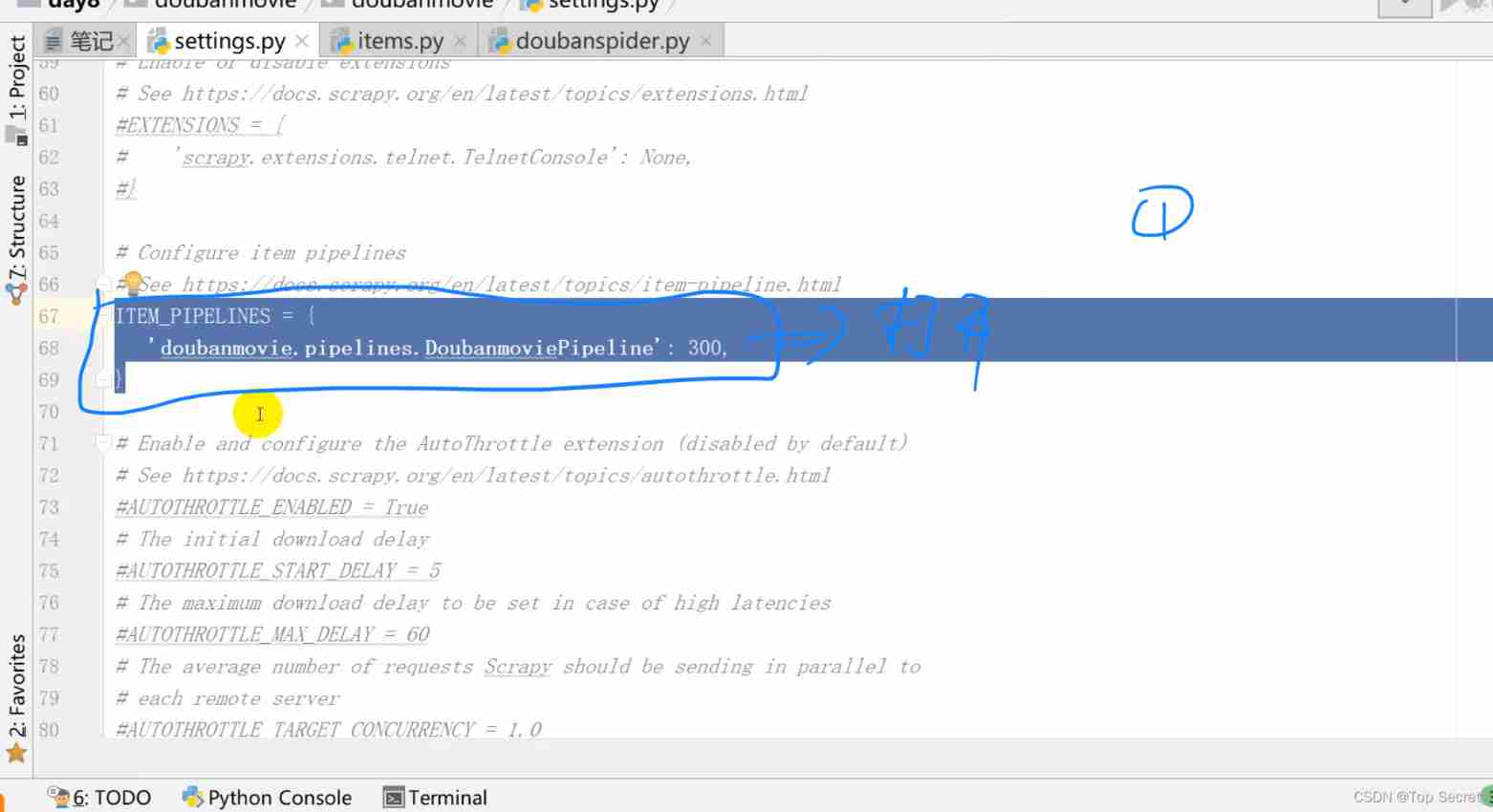
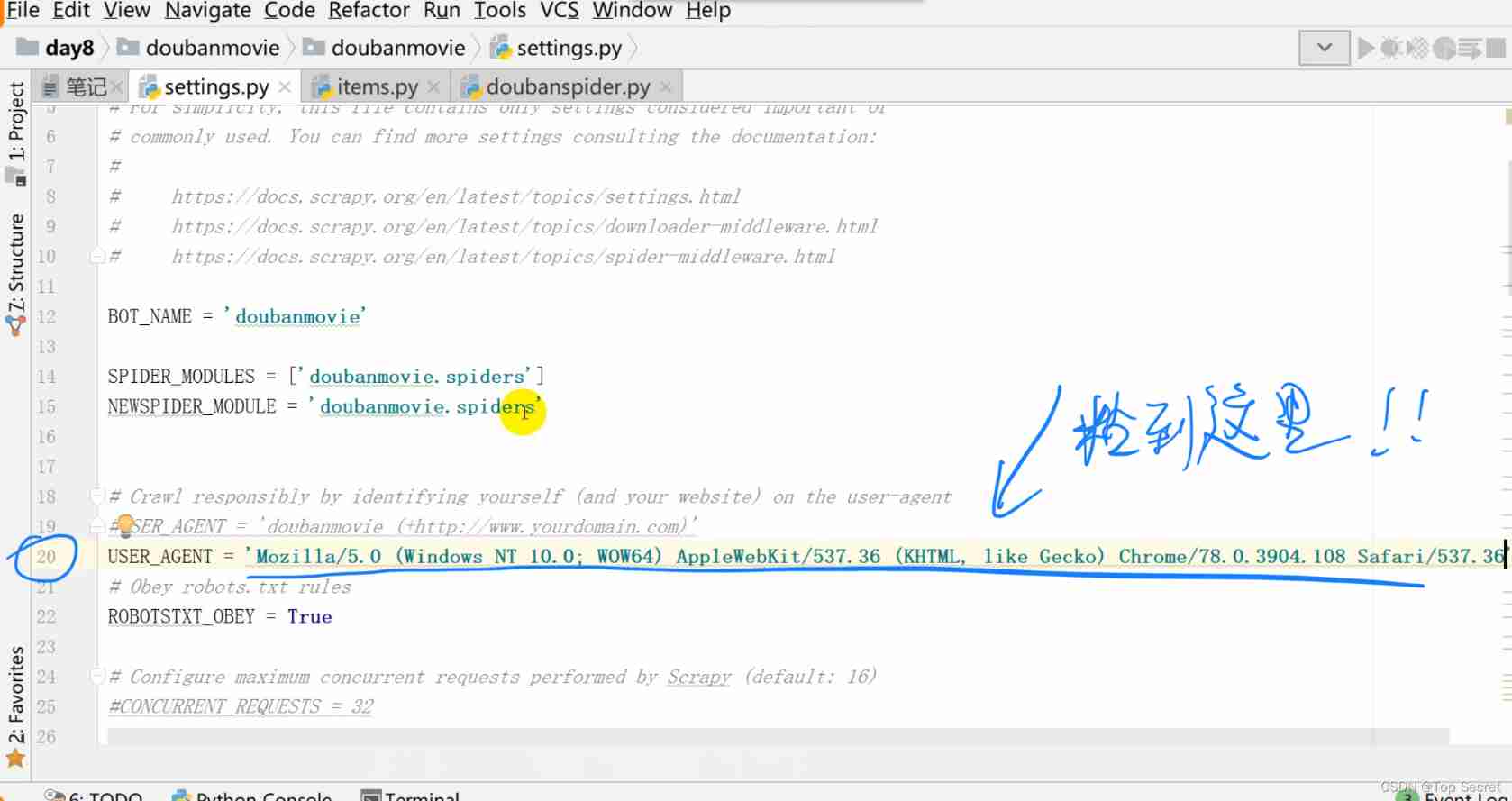
yield Request(urljoin(response.url, nextLink), callback=self.parse)8.4 settings.py file
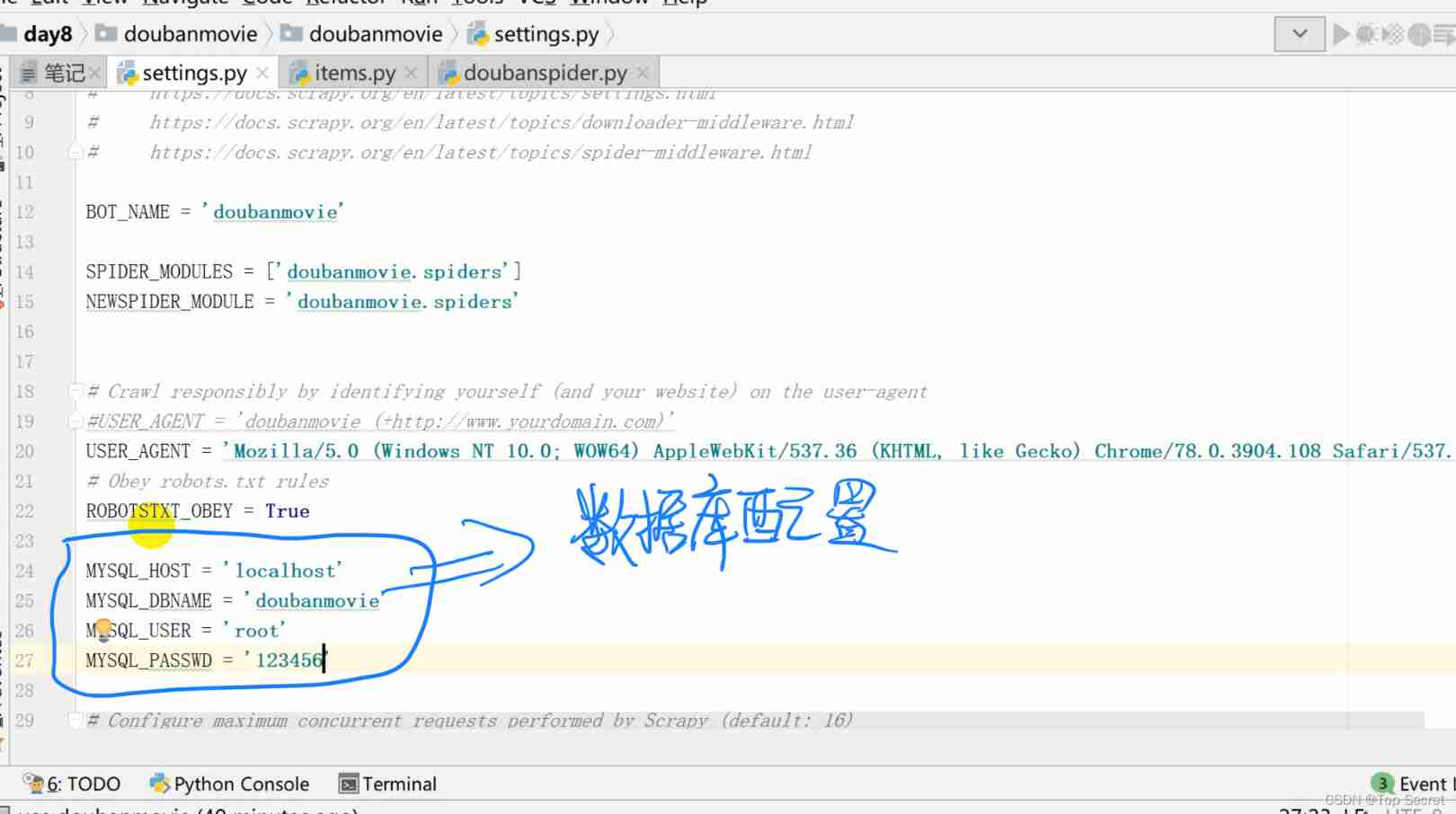
Add browser proxy configuration 、 Database configuration 、 Data transmission configuration
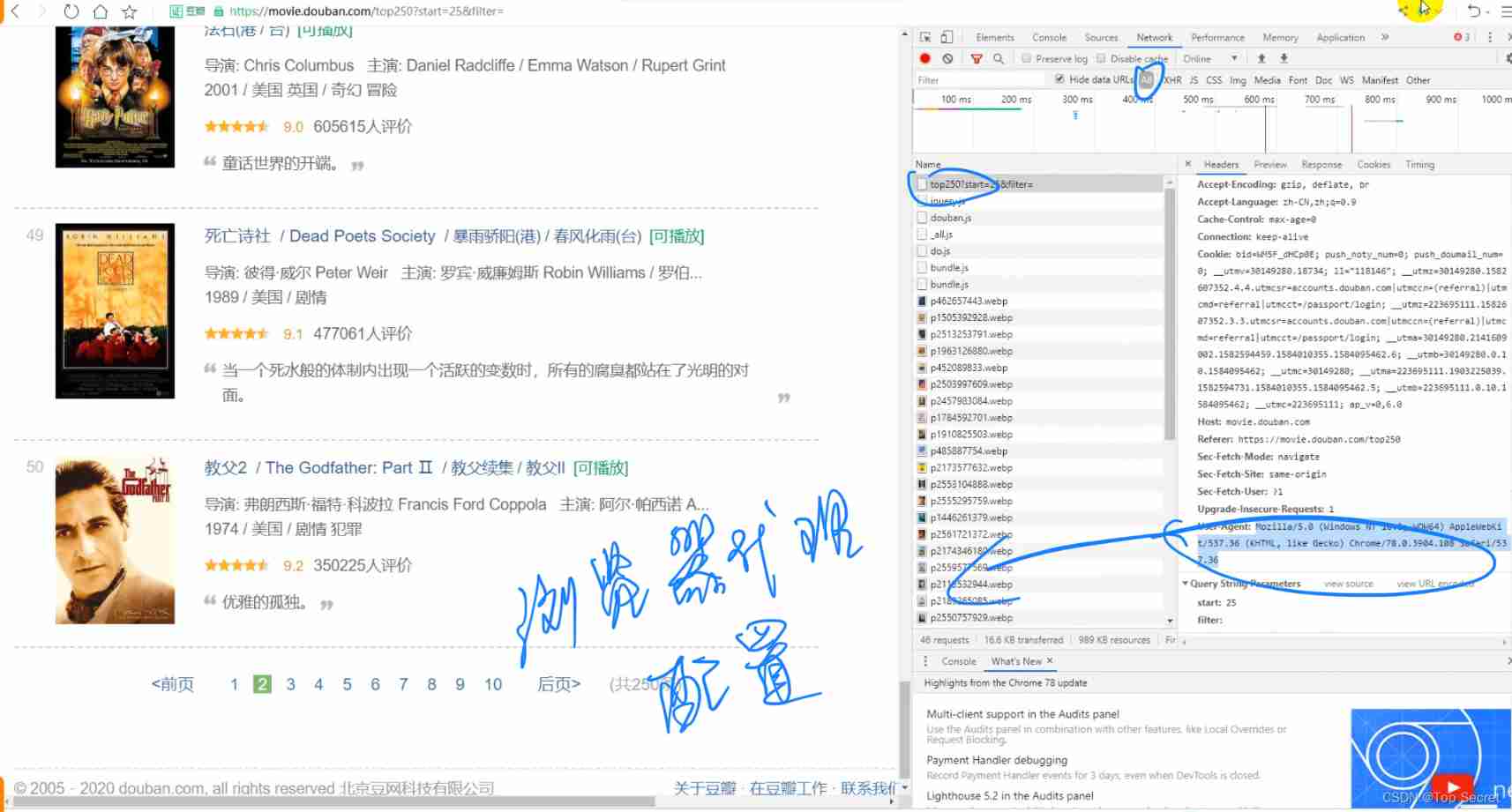
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
Database configuration :
MYSQL_HOST = 'localhost'
MYSQL_DBNAME = 'doubanmovie'
MYSQL_USER = 'root'
MYSQL_PASSWD = '123456'
Pipeline file configuration :
ITEM_PIPELINES = {
'doubanmovie.pipelines.DoubanmoviePipeline': 300,
}
8.5 To configure pipelines.py file ( To achieve persistent storage )
# Connect to database , Import settings.py Database configuration in
import pymysql
from doubanmovie import settings
class DoubanmoviePipeline(object):
def __init__(self):
# Create connection object properties , The read parameters come from settings.py
self.connect = pymysql.connect(
host = settings.MYSQL_HOST,
db = settings.MYSQL_DBNAME,
user = settings.MYSQL_USER,
passwd = settings.MYSQL_PASSWD,
charset = 'utf8',
use_unicode = True # unicode code
)
self.cursor = self.connect.cursor() # Create cursors
# Configuration of persistent storage
def process_item(self, item, spider):
try:
self.cursor.execute("""
insert into doubantop250(title, movieinfo, star, quote)
value (%s,%s,%s,%s)
""",(
item['title'],item['movieinfo'],item['star'],item['quote']
))
self.connect.commit()
except Exception as e:
print(e)
return item8.6 climb :scrapy crawl doubanspider
边栏推荐
- 【mysql学习笔记29】触发器
- #systemverilog# 可綜合模型的結構總結
- TypeScript接口与泛型的使用
- [window] when the Microsoft Store is deleted locally, how to reinstall it in three steps
- 多线程和并发编程(二)
- How to delete all the words before or after a symbol in word
- If Jerry's Bluetooth device wants to send data to the mobile phone, the mobile phone needs to open the notify channel first [article]
- JDBC学习笔记
- 杰理之普通透传测试---做数传搭配 APP 通信【篇】
- 数字IC设计笔试题汇总(一)
猜你喜欢
Markdown 中设置图片图注
You deserve this high-value open-source third-party Netease cloud music player
SSM学习
TS 类型体操 之 extends,Equal,Alike 使用场景和实现对比
SSM learning

杰理之BLE【篇】
Related operations of Excel
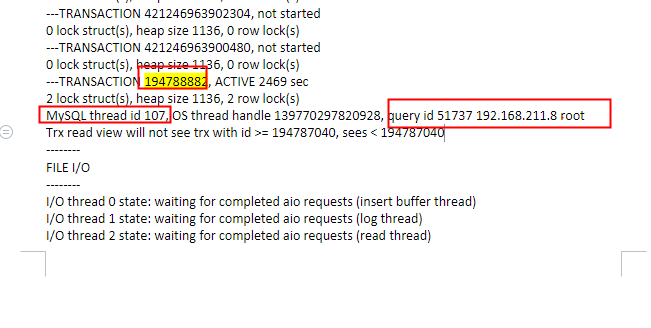
【线上问题处理】因代码造成mysql表死锁的问题,如何杀掉对应的进程

The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
![If Jerry needs to send a large package, he needs to modify the MTU on the mobile terminal [article]](/img/57/12a97ab3d2dabfaf06bbe1788450cf.png)
If Jerry needs to send a large package, he needs to modify the MTU on the mobile terminal [article]

随机推荐
软件测试界的三无简历,企业拿什么来招聘你,石沉大海的简历
剪映的相关介绍
Ble of Jerry [chapter]
TS 体操 &(交叉运算) 和 接口的继承的区别
Three no resumes in the software testing industry. What does the enterprise use to recruit you? Shichendahai's resume
智能终端设备加密防护的意义和措施
Bit operation XOR
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
QT color is converted to string and uint
Project GFS data download
Jerry's ad series MIDI function description [chapter]
Week6 weekly report
OpenJudge NOI 2.1 1661:Bomb Game
You deserve this high-value open-source third-party Netease cloud music player
Openjudge noi 2.1 1749: Digital Square
Force buckle day31
TypeScript 变量作用域
Relevant introduction of clip image
C语言 简单易懂的高精度加法
杰理之如若需要大包发送,需要手机端修改 MTU【篇】