当前位置:网站首页>Crawling exercise: Notice of crawling Henan Agricultural University
Crawling exercise: Notice of crawling Henan Agricultural University
2022-07-06 07:07:00 【Rong AI holiday】
Notice of Henan Agricultural University
Introduction to reptiles
With the rapid development of network , The world wide web has become the carrier of a lot of information , How to effectively extract and use this information has become a huge challenge . Search engine (Search Engine), For example, the traditional general search engine AltaVista, Baidu ,Yahoo! and Google etc. , As a tool to assist people in retrieving information, it has become an entrance and guide for users to access the World Wide Web . however , These general search engines also have some limitations , Such as :
(1) Different fields 、 Users with different backgrounds often have different retrieval purposes and requirements , The results returned by general search engines contain a large number of web pages that users don't care about .
(2) The goal of general search engines is to maximize the network coverage , The contradiction between limited search engine server resources and unlimited network data resources will be further deepened .
(3) The rich data form of the world wide web and the continuous development of network technology , picture 、 database 、 Audio / Video multimedia and other different data appear in large quantities , General search engines are often powerless to these data with dense information content and certain structure , Can't find and get .
(4) General search engines mostly provide keyword based search , It is difficult to support queries based on semantic information .
In order to solve the above problems , Focused crawlers, which can capture relevant web resources directionally, emerge as the times require . Focus crawler is a program that automatically downloads Web pages , It grabs the target according to the set target , Selective access to web pages and related links on the world wide web , Get the information you need . With universal crawlers (generalpurpose web crawler) Different , Focused crawlers don't seek big coverage , The goal is to capture the web pages related to a particular topic , Preparing data resources for topic oriented user queries .
Crawl Henan Agricultural University notice announcement
Crawling purpose
It's school season , I want to pay attention to the dynamic of the school . See if there is any information about the beginning of school .
Learn the code , The program completes the notice and announcement of Henan Agricultural University
https://www.henau.edu.cn/news/xwgg/index.shtml Data capture and storage
Analysis steps
1. Import library
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
2. Analyze the web
Compare the following links
https://www.henau.edu.cn/news/xwgg/index.shtml
https://www.henau.edu.cn/news/xwgg/index_2.shtml
https://www.henau.edu.cn/news/xwgg/index_3.shtml
It is obvious that the law , In this way, you can use the cycle to crawl
3. Single page analysis

It can be seen that the general structure is consistent , Just select .news_list The information in
4. Save the file
with open(' Notice notice 1.csv', 'w', newline='', encoding='utf-8-sig') as file:
fileWriter = csv.writer(file)
fileWriter.writerow([' date ',' title '])
fileWriter.writerows(info_list)
- with open(‘ Notice notice 1.csv’, ‘w’, newline=’’, encoding=‘utf-8-sig’) as file: This sentence must be written like this to prevent garbled code
Crawling results show
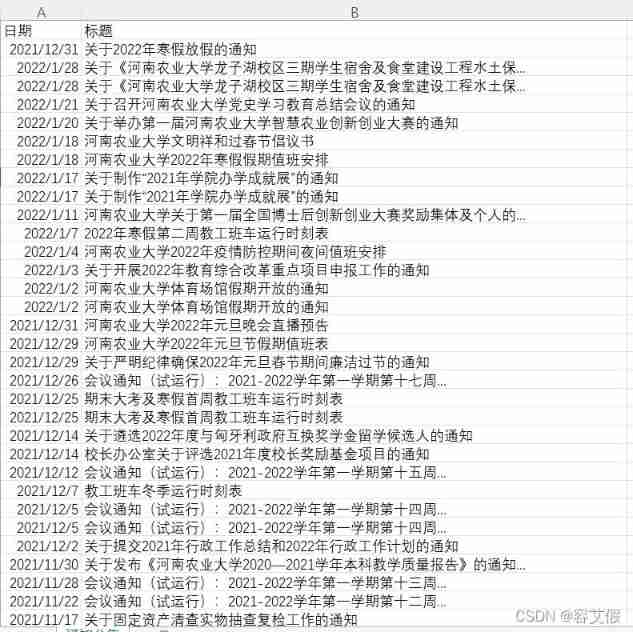
Code
Part of the code explains
t = li.find('span')
if t :
date = t.string
t = li.find('a')
if t :
title = t.string
Be sure to use find, Because there's only one span Elements , Out-of-service find_all function , In addition, judge t If there is a value , Otherwise there will be problems
for i in tqdm(range(1,5)):
if i==1 :
url = base_url + "index.shtml"
else:
str = "index_%s.shtml" % (i)
url = base_url + str
The core code for paging crawling
All the code
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
def get_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
resp = requests.get(url,headers)
resp.encoding = resp.status_code
resp.encoding = resp.apparent_encoding
#resp.encoding = 'utf-8'
page_text = resp.text
r = BeautifulSoup(page_text,'lxml')
lists = r.select('.news_list ul li')
#print(lists)
info_list_page = []
for li in lists:
t = li.find('span')
if t :
date = t.string
t = li.find('a')
if t :
title = t.string
info = [date,title]
info_list_page.append(info)
return info_list_page
def main():
info_list = []
base_url = "https://www.henau.edu.cn/news/xwgg/"
print(" Topic crawling ...........")
for i in tqdm(range(1,5)):
if i==1 :
url = base_url + "index.shtml"
else:
str = "index_%s.shtml" % (i)
url = base_url + str
#print()
info_page = get_page(url)
#print(info_page)
info_list+=info_page
print(" Climb to success !!!!!!!!!!")
with open(' Notice notice 1.csv', 'w', newline='', encoding='utf-8-sig') as file:
fileWriter = csv.writer(file)
fileWriter.writerow([' date ',' title '])
fileWriter.writerows(info_list)
if __name__ == "__main__" :
main()
If this article is helpful to my friends , I hope you can give me some praise and support ~ Thank you very much. ~
边栏推荐
- Raspberry pie serial port login and SSH login methods
- Thought map of data warehouse construction
- Bitcoinwin (BCW): the lending platform Celsius conceals losses of 35000 eth or insolvency
- Applied stochastic process 01: basic concepts of stochastic process
- 医疗软件检测机构怎么找,一航软件测评是专家
- UWA pipeline version 2.2.1 update instructions
- Pymongo gets a list of data
- ROS学习_基础
- What is the difference between int (1) and int (10)? Senior developers can't tell!
- You deserve this high-value open-source third-party Netease cloud music player
猜你喜欢

UWA pipeline version 2.2.1 update instructions
Entity Developer数据库应用程序的开发
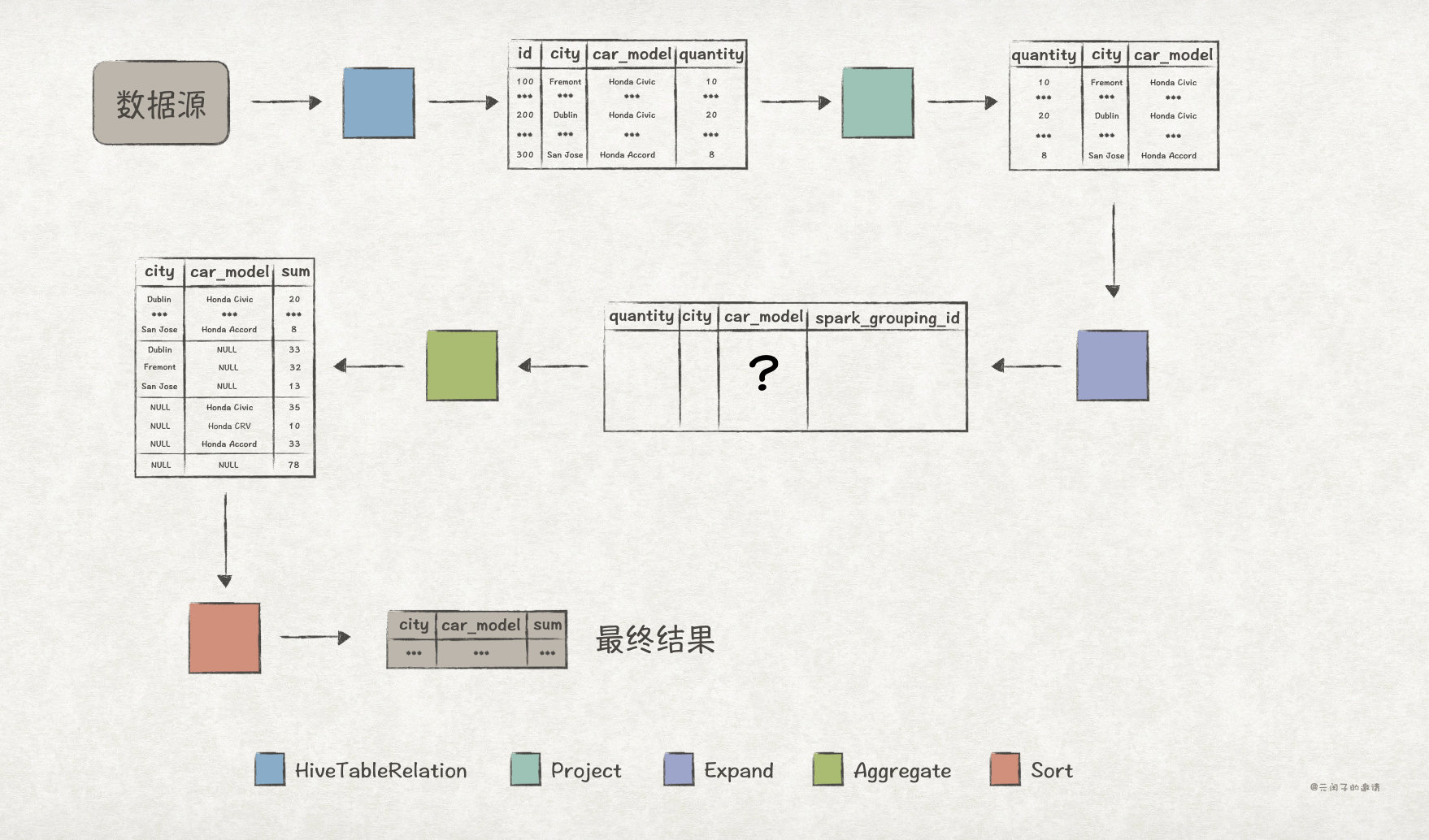
Explain in detail the functions and underlying implementation logic of the groups sets statement in SQL

Simple use of MySQL database: add, delete, modify and query
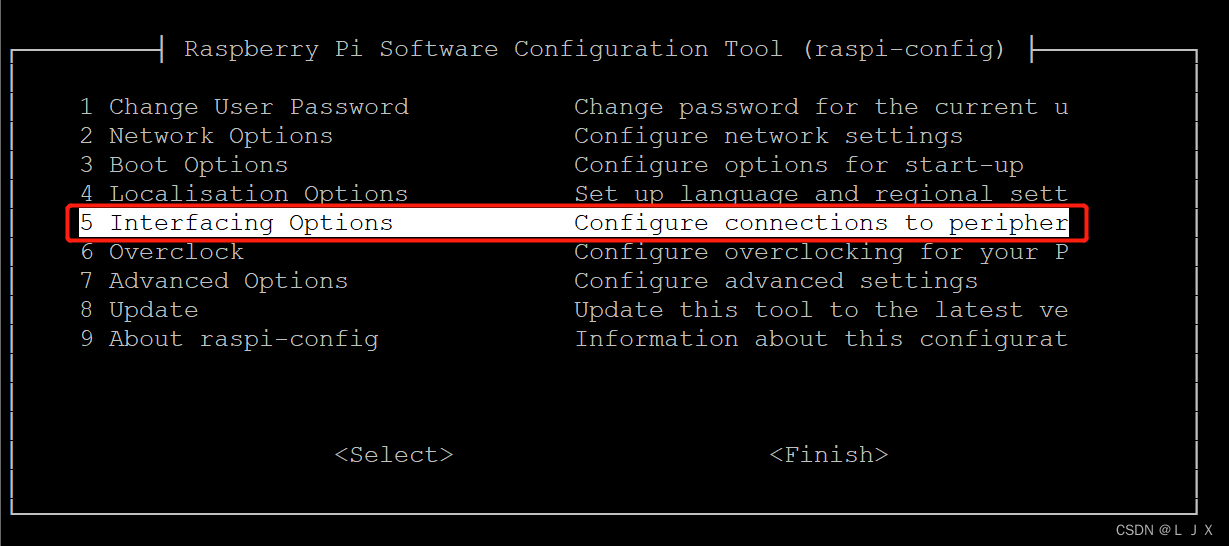
树莓派串口登录与SSH登录方法
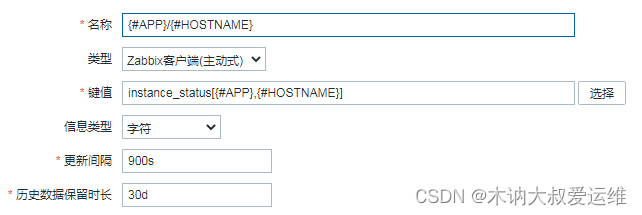
Missing monitoring: ZABBIX monitors the status of Eureka instance
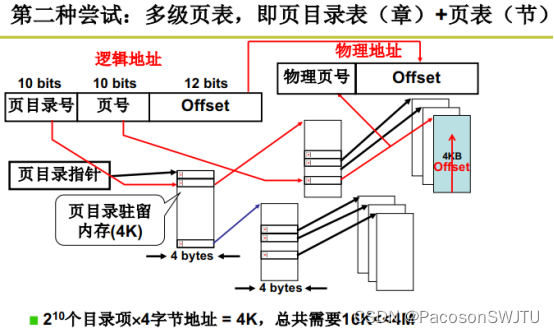
18. Multi level page table and fast table

Hydra common commands

巴比特 | 元宇宙每日必读:中国互联网企业涌入元宇宙的群像:“只有各种求生欲,没有前瞻创新的雄心”...
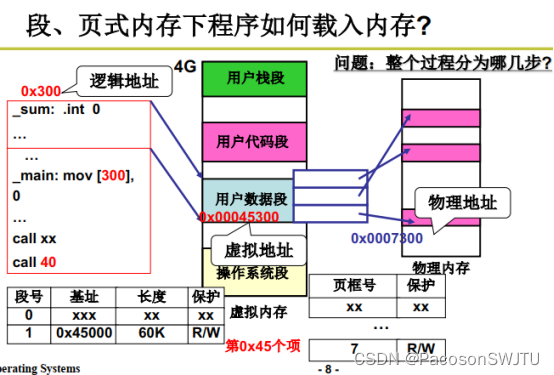
19.段页结合的实际内存管理
随机推荐
Missing monitoring: ZABBIX monitors the status of Eureka instance
Configure raspberry pie access network
【服务器数据恢复】IBM服务器raid5两块硬盘离线数据恢复案例
CDN acceleration and cracking anti-theft chain function
因高额网络费用,Arbitrum 奥德赛活动暂停,Nitro 发行迫在眉睫
How to find a medical software testing institution? First flight software evaluation is an expert
ROS learning_ Basics
Visitor tweets about how you can layout the metauniverse
MVVM of WPF
Blue Bridge Cup zero Foundation National Championship - day 20
BIO模型实现多人聊天
ROS学习_基础
LeetCode 78:子集
What is the difference between int (1) and int (10)? Senior developers can't tell!
Top test sharing: if you want to change careers, you must consider these issues clearly!
ROS2安装及基础知识介绍
Leetcode59. spiral matrix II (medium)
UNIPRO Gantt chart "first experience": multi scene exploration behind attention to details
Misc of BUU (update from time to time)
kubernetes集群搭建Zabbix监控平台