当前位置:网站首页>Cif10 actual combat (resnet18)
Cif10 actual combat (resnet18)
2022-07-06 06:54:00 【Programming bear】
Realization 18 Layer depth residual network ResNet18, And in CIFAR10 Training and testing on image datasets . The standard ResNet18 Accept input as 224 × 224 Size picture data , We will ResNet18 Make appropriate adjustments , Make its input size 32 × 32, The output dimension is 10. Adjusted ResNet18 The network structure is shown in the figure :
One 、 Data set loading and data set preprocessing
def preprocess(x, y):
# Map data to -1~1
x = 2 * tf.cast(x, dtype=tf.float32) / 255. - 1
y = tf.cast(y, dtype=tf.int32) # Type conversion
return x, y
(x, y), (x_test, y_test) = load.load_data() # Load data set
y = tf.squeeze(y, axis=1) # Delete unnecessary dimensions
y_test = tf.squeeze(y_test, axis=1) # Delete unnecessary dimensions
print(x.shape, y.shape, x_test.shape, y_test.shape)
train_db = tf.data.Dataset.from_tensor_slices((x, y)) # Build training sets
# Break up randomly , Preprocessing , Mass production
train_db = train_db.shuffle(1000).map(preprocess).batch(512)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # Build test set
# Preprocessing , Mass production
test_db = test_db.map(preprocess).batch(512)
# Take a sample
sample = next(iter(train_db))
All kinds of data set processing are the same as before . Because it is not possible to download data sets online , It uses custom functions to load data . After the data set is loaded , Build the training set test set and carry out the corresponding type conversion , In addition to batch processing, the training set should also be broken up .
Two 、 Network model building
1. BasicBlock
First, realize the middle two convolution layers , Skip Connection 1x1 Residual module of convolution layer
class BasicBlock(layers.Layer):
# Residual module
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
# The first convolution unit
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
# The second convolution unit
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization()
# padding All are same, So only stride=1, The input and output shapes are the same , Otherwise, the height and width will be reduced to the original 1/s
if stride != 1: # adopt 1x1 Convolution is done shape matching
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else: # shape matching , Direct short circuit
self.downsample = lambda x: x
def call(self, inputs, training=None):
# [b, h, w, c], Through the first convolution unit
out = self.conv1(inputs)
out = self.bn1(out)
out = self.relu(out)
# Through the second convolution unit
out = self.conv2(out)
out = self.bn2(out)
# adopt identity modular
identity = self.downsample(inputs)
# 2 Path outputs are added directly
output = layers.add([out, identity])
output = tf.nn.relu(output) # Activation function
return outputadopt build_resblock You can create multiple residual modules at one time
def build_resblock(self, filter_num, blocks, stride=1):
# Auxiliary function , The stack filter_num individual BasicBlock
res_blocks = Sequential()
# Only the first one BasicBlock The step size of may not be 1, Implement downsampling
res_blocks.add(BasicBlock(filter_num, stride))
# Every one of them ResBlock Contains two blocks individual BasicBlock
for _ in range(1, blocks): # other BasicBlock The steps are 1
res_blocks.add(BasicBlock(filter_num, stride=1))
return res_blocks2.ResNet
When designing deep convolution neural network , Generally, according to the height and width of the feature map ℎ/𝑤 Gradually reduce , The channel number 𝑐 A growing rule of thumb . The number of stacking channels can be gradually increased Res Block To achieve high-level feature extraction . Now let's realize the general ResNet A network model .
# General purpose ResNet Implementation class
class ResNet(keras.Model):
def __init__(self, layer_dims, num_classes=10):
# layer_dims:[2, 2, 2, 2] 4 individual ResBlock, Every ResBlock Contains two basicblock num_classes: Number of categories
super(ResNet, self).__init__()
# Root network , Preprocessing
self.stem = Sequential([layers.Conv2D(64, (3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
# The stack 4 individual Block, Every block Contains more than one BasicBlock, The setting step is different
# When designing deep convolution neural network , Generally, according to the height and width of the feature map ℎ/𝑤 Gradually reduce , The channel number 𝑐 A growing rule of thumb .
# Every ResBlock Contains two basicblock
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1], stride=2)
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
# Output :[b, 512, h,w], Undetermined h,w
# adopt Pooling The layer reduces the height and width to 1x1, Due to flattening into a full connection layer
self.avgpool = layers.GlobalAveragePooling2D()
# Finally, connect a full connection layer classification
self.fc = layers.Dense(num_classes)
# Forward calculation
def call(self, inputs, training=None):
# Through the root network
x = self.stem(inputs)
# One pass 4 A module
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# Through the pool layer
x = self.avgpool(x)
# Through the full connectivity layer
x = self.fc(x)
return xBy adjusting each Res Block The number of stacks and channels can produce different ResNet, Such as through 64-64-128-128-256-256-512-512 Channel number configuration , common 8 individual Res Block, available ResNet18 Network model . Every ResBlock Contains 2 There are three main convolution layers , So the number of convolution layers is 8 ∙ 2 = 16, Add the full connection layer at the end of the network , common 18 layer .
Be careful , After the convolution layer, the full connection layer is usually added to vectorize the features , But the fatal weakness of the full connection layer is Parameter quantity is too large , Especially the fully connected layer connected with the last convolution layer . On the one hand, it has increased Training as well as testing Amount of computation , Reduced speed ; On the other hand, too much parameter is easy to fit . Although similar dropout And other means to deal with , Still can't achieve the effect .
The full connection layer expands the convolution layer into a vector , And then for each feature map To classify ,Global Average Pooling Directly complete these two steps .
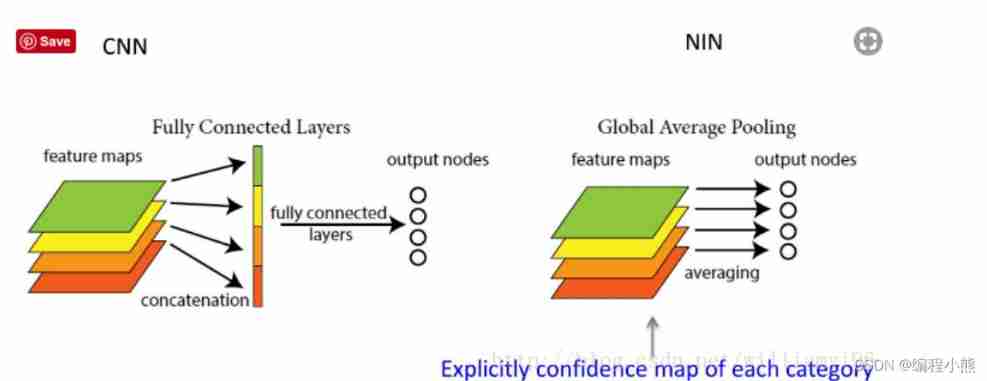
therefore , Here, the convolution layer is followed by GlobalAveragePooling2D, Then connect the whole connection layer . Global average pooling , A layer often used in deep Neural Networks , The dimensions before and after use are [B,H,W,C]->[B,C].
establish ResNet18 and ResNet34 A network model :
def resnet18():
# By adjusting the inside of the module BasicBlock The number and configuration are different ResNet
return ResNet([2, 2, 2, 2])
def resnet34():
# By adjusting the inside of the module BasicBlock The number and configuration are different ResNet
return ResNet([3, 4, 6, 3])
3、 ... and 、 Network assembly
After building the network model , You need to specify the optimizer object used by the network 、 Loss function type , Setting of evaluation indicators, etc , This step is called assembly
model = resnet18() # ResNet18 The Internet
model.build(input_shape=(None, 32, 32, 3))
model.summary() # Statistical network parameters
optimizer = optimizers.Adam(lr=1e-4) # Build optimizer The optimizer mainly uses apply_gradients Method passes in variables and corresponding gradients to iterate over a given variable
Four 、 Calculate the gradient , Cost function and update parameters
Using the automatic derivation function to calculate the gradient , The forward calculation process needs to be placed in tf.GradientTape() Environment , utilize GradientTape Object's gradient() Method automatically solve the gradient of parameters , And make use of optimizers Object update parameters
with tf.GradientTape() as tape:
# [b, 32, 32, 3] => [b, 10], Forward propagation
logits = model(x)
# [b] => [b, 10],one-hot code
y_onehot = tf.one_hot(y, depth=10)
# Calculate cross entropy
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
# Calculate gradient information
grads = tape.gradient(loss, model.trainable_variables)
# Update network parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 50 == 0:
print(epoch, step, 'loss:', float(loss))
5、 ... and 、 test
In the test phase , Because there is no need to record gradient information , Code generally does not need to be written in with tf.GradientTape() as tape Environment . The output of forward calculation goes through softmax After the function , Represents the current picture input of network prediction 𝒙 Belong to the category 𝑖 Probability 𝑃(𝒙 The label is 𝑖|𝑥), 𝑖 ∈ 9 . adopt argmax The function selects the index of the element with the highest probability , As the present 𝒙 Forecast category of , And real annotation 𝑦 Compare , Compare the results through calculation True And sum up to count the number of correctly predicted samples , Finally, divide by the number of total samples , Get the test accuracy of the network
total_num = 0
total_correct = 0
for x, y in test_db:
logits = model(x)
prob = tf.nn.softmax(logits, axis=1)
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch, 'acc:', acc)test result :

ran 2 individual epoch, The accuracy is relatively low , You should be able to reach 80% about .
The whole program
resnet.py file
# -*- codeing = utf-8 -*-
# @Time : 13:21
# @Author:Paranipd
# @File : resnet.py
# @Software:PyCharm
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, Sequential
class BasicBlock(layers.Layer):
# Residual module
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
# The first convolution unit
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
# The second convolution unit
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization()
# padding All are same, So only stride=1, The input and output shapes are the same , Otherwise, the height and width will be reduced to the original 1/s
if stride != 1: # adopt 1x1 Convolution is done shape matching
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else: # shape matching , Direct short circuit
self.downsample = lambda x: x
def call(self, inputs, training=None):
# [b, h, w, c], Through the first convolution unit
out = self.conv1(inputs)
out = self.bn1(out)
out = self.relu(out)
# Through the second convolution unit
out = self.conv2(out)
out = self.bn2(out)
# adopt identity modular
identity = self.downsample(inputs)
# 2 Path outputs are added directly
output = layers.add([out, identity])
output = tf.nn.relu(output) # Activation function
return output
# General purpose ResNet Implementation class
class ResNet(keras.Model):
def __init__(self, layer_dims, num_classes=10):
# layer_dims:[2, 2, 2, 2] 4 individual ResBlock, Every ResBlock Contains two basicblock num_classes: Number of categories
super(ResNet, self).__init__()
# Root network , Preprocessing
self.stem = Sequential([layers.Conv2D(64, (3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
# The stack 4 individual Block, Every block Contains more than one BasicBlock, The setting step is different
# When designing deep convolution neural network , Generally, according to the height and width of the feature map ℎ/𝑤 Gradually reduce , The channel number 𝑐 A growing rule of thumb .
# Every ResBlock Contains two basicblock
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1], stride=2)
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
# Output :[b, 512, h,w], Undetermined h,w
# adopt Pooling The layer reduces the height and width to 1x1, Due to flattening into a full connection layer
self.avgpool = layers.GlobalAveragePooling2D()
# Finally, connect a full connection layer classification
self.fc = layers.Dense(num_classes)
# Forward calculation
def call(self, inputs, training=None):
# Through the root network
x = self.stem(inputs)
# One pass 4 A module
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# Through the pool layer
x = self.avgpool(x)
# Through the full connectivity layer
x = self.fc(x)
return x
def build_resblock(self, filter_num, blocks, stride=1):
# Auxiliary function , The stack filter_num individual BasicBlock
res_blocks = Sequential()
# Only the first one BasicBlock The step size of may not be 1, Implement downsampling
res_blocks.add(BasicBlock(filter_num, stride))
# Every one of them ResBlock Contains two blocks individual BasicBlock
for _ in range(1, blocks): # other BasicBlock The steps are 1
res_blocks.add(BasicBlock(filter_num, stride=1))
return res_blocks
def resnet18():
# By adjusting the inside of the module BasicBlock The number and configuration are different ResNet
return ResNet([2, 2, 2, 2])
def resnet34():
# By adjusting the inside of the module BasicBlock The number and configuration are different ResNet
return ResNet([3, 4, 6, 3])
mian.py
# -*- codeing = utf-8 -*-
# @Time : 14:22
# @Author:Paranipd
# @File : resnet18_train.py
# @Software:PyCharm
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
import os
from resnet import resnet18
import load
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
tf.random.set_seed(2345)
def preprocess(x, y):
# Map data to -1~1
x = 2 * tf.cast(x, dtype=tf.float32) / 255. - 1
y = tf.cast(y, dtype=tf.int32) # Type conversion
return x, y
(x, y), (x_test, y_test) = load.load_data() # Load data set
y = tf.squeeze(y, axis=1) # Delete unnecessary dimensions
y_test = tf.squeeze(y_test, axis=1) # Delete unnecessary dimensions
print(x.shape, y.shape, x_test.shape, y_test.shape)
train_db = tf.data.Dataset.from_tensor_slices((x, y)) # Build training sets
# Break up randomly , Preprocessing , Mass production
train_db = train_db.shuffle(1000).map(preprocess).batch(512)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # Build test set
# Preprocessing , Mass production
test_db = test_db.map(preprocess).batch(512)
# Take a sample
sample = next(iter(train_db))
def main():
# [b, 32, 32, 3] => [b, 1, 1, 512]
model = resnet18() # ResNet18 The Internet
model.build(input_shape=(None, 32, 32, 3))
model.summary() # Statistical network parameters
optimizer = optimizers.Adam(lr=1e-4) # Build optimizer
for epoch in range(100): # Training epoch
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape:
# [b, 32, 32, 3] => [b, 10], Forward propagation
logits = model(x)
# [b] => [b, 10],one-hot code
y_onehot = tf.one_hot(y, depth=10)
# Calculate cross entropy
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
# Calculate gradient information
grads = tape.gradient(loss, model.trainable_variables)
# Update network parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 50 == 0:
print(epoch, step, 'loss:', float(loss))
total_num = 0
total_correct = 0
for x, y in test_db:
logits = model(x)
prob = tf.nn.softmax(logits, axis=1)
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch, 'acc:', acc)
if __name__ == '__main__':
main()
边栏推荐
- Biomedical English contract translation, characteristics of Vocabulary Translation
- (practice C language every day) reverse linked list II
- [ 英語 ] 語法重塑 之 動詞分類 —— 英語兔學習筆記(2)
- What are the characteristics of trademark translation and how to translate it?
- RichView TRVStyle 模板样式的设置与使用
- Supporting title of the book from 0 to 1: ctfer's growth road (Zhou Geng)
- [Yu Yue education] Dunhuang Literature and art reference materials of Zhejiang Normal University
- P5706 [deep foundation 2. Example 8] redistributing fat house water -- February 13, 2022
- AttributeError: Can‘t get attribute ‘SPPF‘ on <module ‘models. common‘ from ‘/home/yolov5/models/comm
- When my colleague went to the bathroom, I helped my product sister easily complete the BI data product and got a milk tea reward
猜你喜欢
Attributeerror: can 't get attribute' sppf 'on < module' models. Common 'from' / home / yolov5 / Models / comm

Visitor tweets about how you can layout the metauniverse

Bitcoinwin (BCW): 借贷平台Celsius隐瞒亏损3.5万枚ETH 或资不抵债

The internationalization of domestic games is inseparable from professional translation companies
Prefix and array series

Supporting title of the book from 0 to 1: ctfer's growth road (Zhou Geng)

女生学软件测试难不难 入门门槛低,学起来还是比较简单的
攻防世界 MISC中reverseMe简述
机器人类专业不同层次院校课程差异性简述-ROS1/ROS2-
Explain in detail the functions and underlying implementation logic of the groups sets statement in SQL
随机推荐
PCL实现选框裁剪点云
My creation anniversary
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
Due to high network costs, arbitrum Odyssey activities are suspended, and nitro release is imminent
Database basics exercise part 2
P5706 [deep foundation 2. Example 8] redistributing fat house water -- February 13, 2022
接口自动化测试实践指导(上):接口自动化需要做哪些准备工作
【Hot100】739. Daily temperature
前缀和数组系列
Biomedical English contract translation, characteristics of Vocabulary Translation
Leetcode daily question (1997. first day where you have been in all the rooms)
18.多级页表与快表
Introduction and underlying analysis of regular expressions
女生学软件测试难不难 入门门槛低,学起来还是比较简单的
MySQL high frequency interview 20 questions, necessary (important)
Day 248/300 关于毕业生如何找工作的思考
[unity] how to export FBX in untiy
Day 245/300 JS forEach 多层嵌套后数据无法更新到对象中
Py06 dictionary mapping dictionary nested key does not exist test key sorting
Office doc add in - Online CS