当前位置:网站首页>18.多级页表与快表
18.多级页表与快表
2022-07-06 06:39:00 【PacosonSWJTU】
【README】
1.本文内容总结自 B站 《操作系统-哈工大李治军老师》,内容非常棒,墙裂推荐;
2.操作系统内存管理:分页机制+多级页表+快表来实现;
【0】分页的问题
1)分页的问题(大页表):为了提高内存利用率,页应该小,页小了,页表项就多了,页表就大了;(页是4K,每个段最多浪费4K)
- 问题:页表大了不利于查找,且大页表占用内存多;
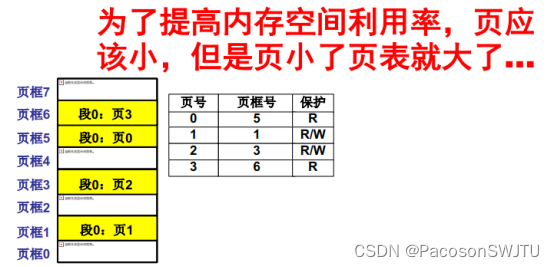
【例】页表结构与大页表
页号 | 页框号 | 保护 |
0 | 5 | R |
1 | 1 | R/W |
2 | 3 | R/W |
3 | 6 | R |
- 如总内存大小2^32=4G,每页大小4K,则页表项数量=4G/4K=1M 即100万个页表项;
- 又每个页表项占用4个字节,所以含有100万个页表项的页表占用的总内存为 4M;
- 又若系统并发执行10个进程,每个进程页表项4M,所以需要40M;那如果系统并发100个进程,则需要400M存储页表,这会导致内存利用率低;
【1】大页表的解决方法1(只是尝试):只存放用到的页
1)页表只存放用到的页(页表号不连续)
实际上,大部分逻辑地址不会用到;
把不会用到的逻辑页号从页表中删除,从而减少了当前进程的页表大小;即,用到的逻辑页才有页表项;
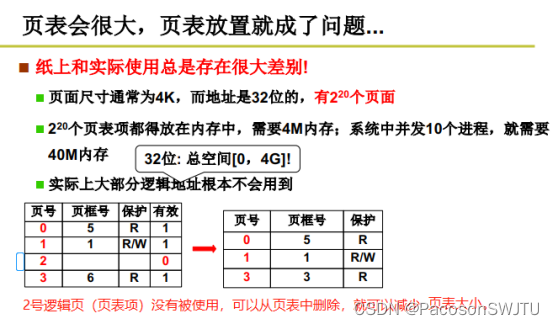
2) 用到的逻辑页才有页表项
因为删除了不使用的逻辑页号,所以页号是不连续的(页号0 1 3 )。如下。
页号 | 页框号 | 保护 |
0 | 5 | R |
1 | 1 | R/W |
3 | 3 | R |
在计算页基址时,需要从页表中根据页号查找页框号,进而计算出该页的物理内存基址。
3)如何根据页号查找页框号?
- 顺序查找,折半查找都比较慢;
- 如总内存大小为4M,页表项个数为4M/4K=1K;采用顺序查找需要1K次,采用折半需要 log(2^10)=10次;也就是说每执行一条指令都需要10次访存,1次主存访问耗费约200ns,则10次需要2us;这会严重影响指令执行速度;
【小结】
- 页号必须要连续,这样才可以立即定位到页表项。如页表项基址+3就可以得到页号为3的页表项(而不用顺序或折半查找);
- 这又回到了刚开始的问题,即32位地址空间 + 4K页面 + 页号必须连续 => 导致了2^20个页表项 => 导致了大页表占用过多内存,造成浪费;
所以解决方法1中的尝试是失败的。

进一步的,我们得出需要解决的问题是:
- 页号连续,且页表占用内存少;
- 用书的章目录和节目录来类比思考;
【2】 大页表的解决方法2(尝试):多级页表
【2.1】多级页表
由单级页表转为多级页表;
即多级页表,页目录表(章)+页表(节);
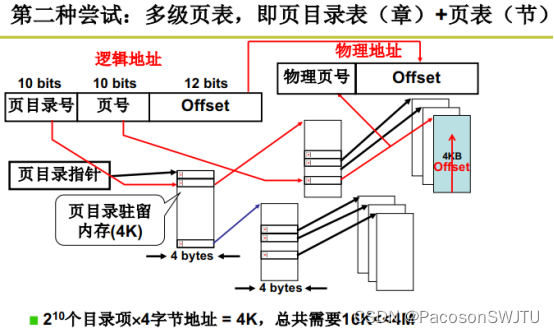
1)多级页表具体分配
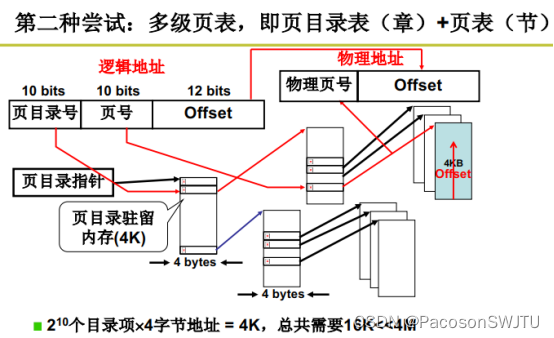
指令中的逻辑地址结构如下:
10 bits | 10 bits | 12 bits |
页目录号 | 页号 | Offset偏移量 |
- 步骤1:根据页目录号从页目录表中查询到页表基址;
- 步骤2:根据页号从页表(通过页表基址确定)中查询到页框号(物理内存页号);
- 步骤3:根据页框号可以计算出物理内存页基址(具体是页框号乘以4K),用页基址加上逻辑地址偏移量得到物理内存地址;
因为页目录号,页号都是连续的,所以页目录号及页号的查询时间复杂度是O(1);
2)利用多级分页的地址翻译步骤
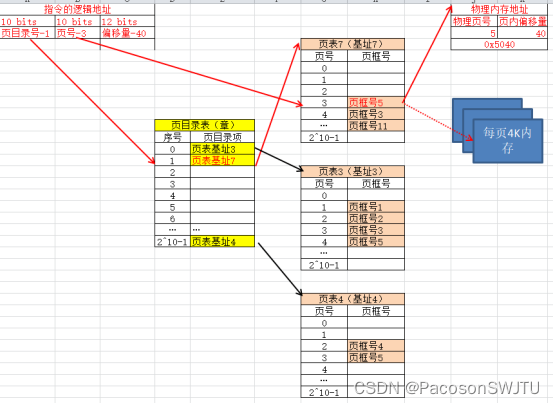
【说明】图解说明:
- 说明1)1个页目录项(章)指向1k个内存页,每个内存页4K,所以1个页目录项指向4M内存;所以1K个页目录项就可以映射容量为4G的内存空间;
- 说明2)页目录表中,进程使用了3个页目录项,即使用了4G内存中的12M内存;页目录表与页表占用的总内存大小=1K*4 + 3 * 1K*4 = 16K;(每个页目录项与每个页表项均占用4个字节,因为32位地址空间)
- 说明3)需要注意的是,如果内存使用单级分页,需要4G/4K=1M个页表项,每个页表项占用4个字节,则单级分页下的页表占用内存大小为4M;
【小结】
- 在内存总大小4G的基础上,占用12M内存的程序,采用多级分页时页表占用16K 远远小于 单级分页时的4M;
【2.2】多级页表优缺点
1)多级页表优点:
- 多级页表既保证了页表表项的连续性,使得查找起来非常快(时间复杂度O(1));
- 又保证了内存中存储的页表少了,减少了内存浪费,提高了内存使用率;
2)多级页表缺点
- 多级页表增加了访存速度,特别64位系统(因为64位系统的多级页表有5,6级);
- 多级页表,每增加一级,访存次数就会加1; 所以 64位系统的多级页表访存次数约为5,6次;
- 多级页表的级数越多,访存越多,效率越低(级数越多,类比书的多层目录),这会造成指令执行效率低;
针对多级页表缺点,引入了快表;
【3】 快表(指的是TLB寄存器)
1)快表:
- 也叫TLB,TLB是一组相联快速存储,是寄存器;
- TLB,即Translation lookaside buffer,又称为翻译后备缓冲区寄存器;
- 通过TLB可以快速找到最近使用的逻辑页映射的物理页号;
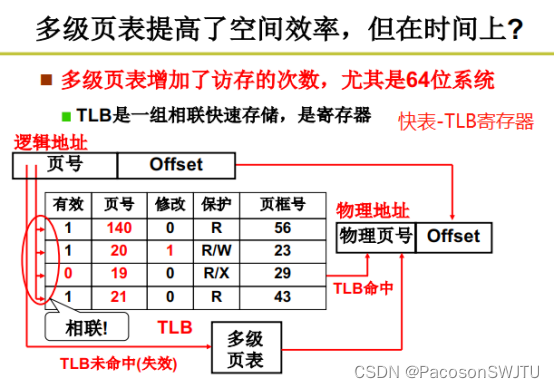
2)TLB存储的内容(记录的是最近使用的逻辑页映射的物理页号)如下:
有效 | 页号(无序) | 修改 | 保护 | 页框号(物理页号) |
1 | 140 | 0 | R | 56 |
1 | 20 | 1 | R/W | 23 |
0 | 19 | 0 | R/W | 29 |
1 | 21 | 0 | R | 43 |
因为寄存器访问速度快,可以设计 TLB寄存器的硬件逻辑,使得可以一次访存就可以根据页号查询出页框号(物理页号),最后得到物理地址;
【3.1】基于快表的地址翻译
1)基于快表的地址翻译步骤
- 步骤1: 根据逻辑地址的页号,查询一次TLB寄存器就可以得到页框号(物理页号);
- 步骤2: 若快表TLB不存在页框号(未命中),则查询多级页表,并把查询结果送入TLB存储作为缓冲用于后续地址翻译;
小结:快表+多级页表合在一起形成的结构,保证了查询(翻译物理地址)时间快,页表项连续,减少了内存资源浪费;
2)这也充分体现了操作系统折中思想;通过把一些技术组合在一起,使得访问时间不错,空间利用也不错;具体是:
- 多级页表是减少了空间浪费,降低了空间复杂度,访问时间还可以,但还想提高页表查询速度;
- TLB是提高了页表查询速度,降低了时间复杂度;
- TLB可以弥补多级页表(特别64位系统)访存耗时,慢的缺点;
【3.2】TLB如何保证高命中率
1)TLB得以发挥作用的原因:保证高命中率;

【说明】公式说明:
- 有效访问时间等于命中时的访问时间 + 没有命中时的访问时间;
- 上图有效访问时间式子中的符号解释:
- HitR 表示 命中率;
- (1-HitR)表示 未命中率;
- TLB 表示访问寄存器的时间;通常为10ns (当然图中给出的是20ns,数量级相同)
- MA表示访问内存的实际; 通常为 200ns (图中给出的是100ns,数量级相同)
- 可以看到: 命中率越高,则访问时间才接近于1次访存的时间;
2)如何提高TLB命中率
- TLB越大越好, 但TLB很贵,折中处理是 TLB可以存储的页表项数量范围是 [64,1024];
3)为什么 TLB存储的页表项数量可以在 64~1024之间 ?
原因:
- 程序的地址访问存在局部性;
- 因为访问局部性,所以程序用的是固定的那几个逻辑页号;
- 最近访问的逻辑页与物理页映射关系会送入TLB存储,所以TLB的命中率会很高;
- 补充:程序多体现在循环,顺序结构;

边栏推荐
- MySQL high frequency interview 20 questions, necessary (important)
- [ 英语 ] 语法重塑 之 英语学习的核心框架 —— 英语兔学习笔记(1)
- How to reconstruct the class explosion caused by m*n strategies?
- Fedora/rehl installation semanage
- 英语论文翻译成中文字数变化
- The registration password of day 239/300 is 8~14 alphanumeric and punctuation, and at least 2 checks are included
- Attributeerror: can 't get attribute' sppf 'on < module' models. Common 'from' / home / yolov5 / Models / comm
- Lesson 7 tensorflow realizes convolutional neural network
- 钓鱼&文件名反转&office远程模板
- The internationalization of domestic games is inseparable from professional translation companies
猜你喜欢

How to do a good job in financial literature translation?
Machine learning plant leaf recognition

女生学软件测试难不难 入门门槛低,学起来还是比较简单的
Traffic encryption of red blue confrontation (OpenSSL encrypted transmission, MSF traffic encryption, CS modifying profile for traffic encryption)
Address bar parameter transmission of list page based on jeecg-boot

Facebook AI & Oxford proposed a video transformer with "track attention" to perform SOTA in video action recognition tasks

Chinese English comparison: you can do this Best of luck

How to convert flv file to MP4 file? A simple solution

What are the characteristics of trademark translation and how to translate it?
Market segmentation of supermarket customers based on purchase behavior data (RFM model)
随机推荐
Day 239/300 注册密码长度为8~14个字母数字以及标点符号至少包含2种校验
How to translate biomedical instructions in English
Reflex WMS中阶系列3:显示已发货可换组
SQL Server manager studio(SSMS)安装教程
[English] Verb Classification of grammatical reconstruction -- English rabbit learning notes (2)
[ 英语 ] 语法重塑 之 动词分类 —— 英语兔学习笔记(2)
Redis Foundation
Tms320c665x + Xilinx artix7 DSP + FPGA high speed core board
云服务器 AccessKey 密钥泄露利用
Difference between backtracking and recursion
同事上了个厕所,我帮产品妹子轻松完成BI数据产品顺便得到奶茶奖励
Apache DolphinScheduler源码分析(超详细)
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
Day 248/300 thoughts on how graduates find jobs
26岁从财务转行软件测试,4年沉淀我已经是25k的测开工程师...
Leetcode - 152 product maximum subarray
Fedora/rehl installation semanage
SSO流程分析
What are the commonly used English words and sentences about COVID-19?
钓鱼&文件名反转&office远程模板