当前位置:网站首页>Facebook AI & Oxford proposed a video transformer with "track attention" to perform SOTA in video action recognition tasks
Facebook AI & Oxford proposed a video transformer with "track attention" to perform SOTA in video action recognition tasks
2022-07-06 06:37:00 【I love computer vision】
Official account , Find out CV The beauty of Technology
▊ Write it at the front
In the video Transformer in , The time dimension is usually associated with two spatial dimensions (W and H) In the same way . However , Objects can be moved in the camera or in the scene , In the t The object at one position in the frame may be different from the object at t+k The content of this position in the frame is completely irrelevant . therefore , These time-dependent correspondences should be modeled , In order to understand the dynamic scene .
So , The author proposes a method for video Transformer Of Trajectory attention (trajectory attention) , It gathers information along an implicitly determined motion path . Besides , The author also proposes a new method to solve the secondary dependence of calculation and storage on input size , This is particularly important for high-resolution or long video .
The author will Attention The method is applied to Transformer In the model , And in Kinetics、Something-Something V2 and EpicKitchens In the task of video action recognition on data set SOTA Result .
▊ 1. Thesis and code address

Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers
The paper :https://arxiv.org/abs/2106.05392
Code :https://github.com/facebookresearch/Motionformer▊ 2. Motivation
Transformer Has become a NLP、Vision and Speech The mainstream structure of , The self attention mechanism is suitable for different types of data and cross domain data . However , Its universality and lack of inductive bias also mean Transformer Very large amounts of data or domain specific data enhancements are often required to train , For video data , This phenomenon is particularly serious . Although video carries a wealth of time information , But they can also contain redundant spatial information from adjacent frames , The standard self attention mechanism cannot overcome this redundancy .
therefore , The author provides a variant of self attention , be called Track attention (trajectory attention) , It can better describe the time information contained in the video . Analysis of still images , Spatial locality is probably the most important inductive bias , This motivates the design of convolutional networks and in vision Transformer Spatial coding used in , because Belong to the same 3D The points of the object tend to be projected onto pixels close to each other in the image On .
It's similar in video data , But beyond that , Video data has another property :3D Points move over time , Therefore, it is projected on different parts of the image along a specific two-dimensional trajectory . Existing videos Transformer Method ignores these trajectories , Directly collect information across time dimensions or the whole three-dimensional space-time features . The author thinks that , Pool along the trajectory , It will provide a more natural inductive bias for video data , And allow the network to aggregate information from multiple views of the same object or area , To infer how an object or area moves .
In this paper , The author uses the attention mechanism to find these tracks .RAFT And other methods show that by comparing local features across space and time , Good optical flow estimation can be obtained . therefore , In this work , The author uses the attention mechanism to guide the network to collect information along the motion path .
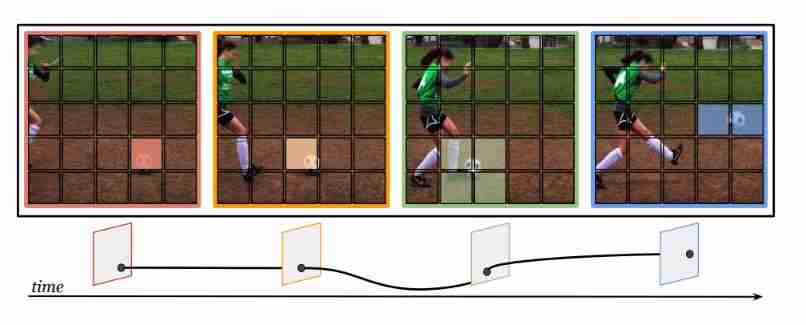
The author also notes that , Vision Transformer It's in the image patch Running on , Therefore, it cannot be assumed that it corresponds to a single 3D spot , To move along a simple one-dimensional trajectory . The picture above depicts “ play football ” The action of , According to the specific video frame , The ball can span up to four patch. Besides , these patch Include foreground ( The ball ) Mixing with background objects , So there are at least two different movements . therefore , The trajectory attention mechanism proposed in this paper , Make the model from all relevant “ Ball area ” Assemble a motion feature in .
▊ 3. Method
The goal of this article is to modify Transformer Attention mechanism in , To better capture the information contained in the video . Represent the input video as , Like the current video Transformer equally , Firstly, the video sequence is preprocessed into ST individual token Sequence , The spatial resolution is , The time resolution is , In this process, the author uses three-dimensional embedding Method , That is, the disjoint space-time cube features are linearly projected to .
then , The learnable location coding is added to the video embedding in spatial and temporal dimensions respectively , To get . Last , Classify a learnable token Add to token In sequence , As an overall explanation of the video .
video Transformer Structure , And ViT equally , Including layer normalization (LN) operation 、 Attention, bulls (MHA)、 Residual connection and feedforward network (MLP):
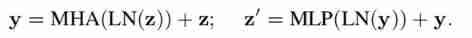
3.1 Video self-attention
Self attention operation first requires a set of query-key-value vector , Every spatio-temporal location in the video st Corresponding to a vector . These vectors are obtained by linear projection of the input , namely
402 Payment Required
, The projection matrix is . Pay attention across time and space ( Joint space-time attention ) The calculation of is expressed as :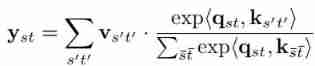
One problem with this formula is , It has quadratic complexity in space and time , namely . Another way is to limit attention to space or time , It's called separating spatiotemporal attention :
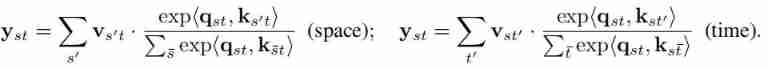
This reduces the complexity to and , However, only models are allowed to model time and space dimensions independently .
Different from these two methods , The author pays attention along the track . For every space-time location ( The trajectory “ Reference point ”) And the corresponding query , The author constructs a set of trajectories token . The trajectory token Extend to the duration of the video sequence , Its trajectory at different times token The calculation is as follows :
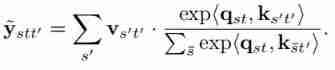
In this formula Attention It is applied in space , And applied to each frame independently , Then sum the dimensions in space (pooling), So only the time dimension is left , Represents the trajectory “ Reference point ” Trajectories at different times .
Once these trajectories are calculated , They need to be further pooled across time . So , The trajectory token Projected onto a new set of queries, keys and values On :
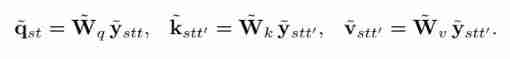
Same as before , The updated query corresponds to the track reference point , And contains information from the spatial collection of all frames . This new query passes at a new time ( The trajectory ) Pool on the dimension to obtain one-dimensional attention :
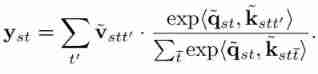
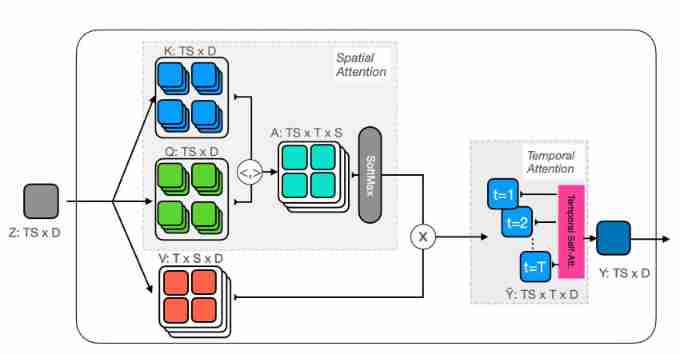
Like joint space-time attention , The method in this paper has quadratic complexity in space and time , Therefore, there is no computational advantage , And it's slower than separating time and space . However , The method in this paper has better accuracy than the combined and separated spatiotemporal attention mechanism . The schematic diagram of attention trajectory in this paper is as follows :
3.2 Approximating attention
In order to get faster running speed , An approximate scheme is proposed to speed up the calculation . take query-key-value The matrix is expressed as , Each vector inside is expressed as .
In order to obtain the effective decomposition of the attention operator , The author uses a probability formula to rewrite it . Set as a classified random variable , Indicates the second input () Whether to assign to the output (), among . The attention operator uses a parametric model of the event probability based on polynomial logic function , namely softmax operator :
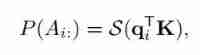
among , Subscript : The input tensor in the slice represents the complete tensor . Then introduce potential variables , It also indicates whether the input is assigned to the prototype , The auxiliary vector of the representation . therefore , It can be obtained by using the formula of full probability and the formula of conditional probability :
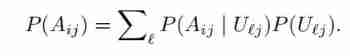
among , Potential variables are independent of input . Even under the parametric model , The corresponding real distribution is also difficult to deal with . therefore , The author uses an approximate parametric model to approximate the conditional probability :
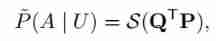
among , Represents the result of horizontally splicing all query vectors . therefore , Sort out all the above equations , You can get :
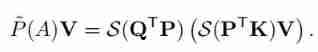
Computational efficiency
An important feature of approximation in the equation is , It can be divided into Two step calculation . First , take value Multiply by one prototypes-keys attention matrix , It's much smaller than the full attention matrix , because .
therefore , The amount of calculation is much smaller than the original calculation . This avoids the secondary dependence of full attention on the size of input and output , As long as it remains the same , The approximate calculation uses linear complexity .
3.3 The Motionformer model

In this paper, the Video Transformer Build on previous work . As shown in the table above . Author use ViT Model as infrastructure , use TimeSformer Independent spatial and temporal location coding , as well as ViViT 3D image in tokenization Strategy .
▊ 4. experiment
4.1 Ablation studies
Input: tokenization
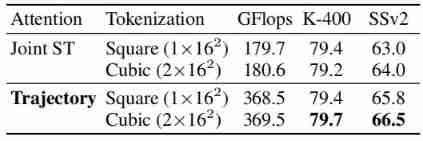
The table above shows the different tokenization Experimental results of the method , It can be seen that ,Cubic In a way comparable to Square For better performance .
Input: positional encoding
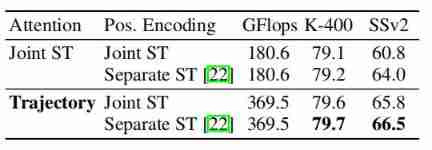
The table above shows the different positional encoding Experimental results of the method , It can be seen that ,Separate ST In a way comparable to Joint ST For better performance .
Attention block: comparisons

The table above shows the different Attention The experimental performance of the module is compared , It can be seen that the trajectory attention module in this paper can achieve better performance than other attention modules .
4.2 Orthoformer approximated attention
Approximation comparisons
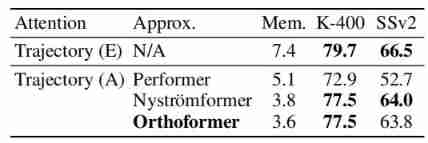
The table above shows Orthoformer Approximate calculation of trajectory , Can occupy less video memory than other methods .
Prototype selection
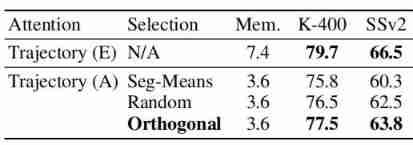
Orthoformer It's the prototype selection process , The above table shows the experimental results of different prototype selection strategies .
Number of prototypes
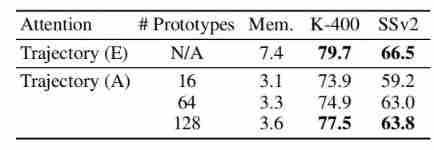
The above table shows the experimental results of different prototype numbers .
Temporally-shared prototypes
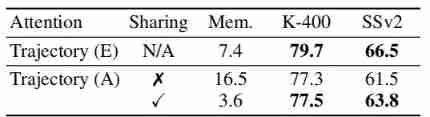
The above table shows the results of whether the prototype is shared , It can be seen that , Sharing prototypes can not only reduce video memory , It also improves performance .
4.3 Comparison to the state-of-the-art
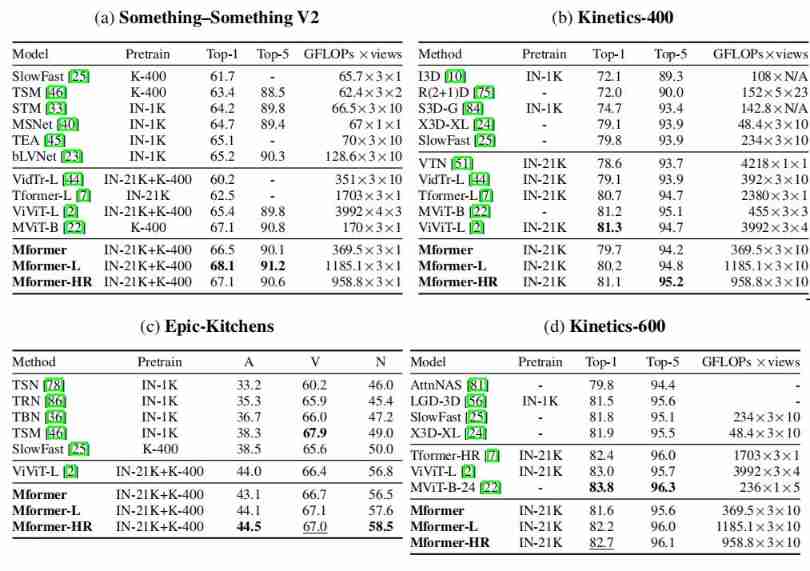
The above table shows the application of this method on multiple data sets and others SOTA The comparison results of the methods are , It can be seen that , This paper implements... On multiple data sets SOTA Performance of .
▊ 5. summary
In this paper , The author puts forward a kind of General video data attention block , It gathers information along an implicitly determined trajectory , It provides a realistic inductive bias for the model . Besides , The author uses a kind of Pay attention to the approximation algorithm It further solves the problem of its secondary dependence on the input size , The algorithm significantly reduces the demand for video memory . Through these designs , The authors have obtained... On several benchmark data sets SOTA Result .
For all that , The method in this paper inherits Transformer Many limitations of the model , Training speed and poor efficiency . The trajectory attention proposed in this paper has higher computational complexity than the recent work , Although the approximation algorithm weakens this point , Significantly reduce the amount of video memory and Computing , However, this step cannot be done in parallel , Make it run very slowly .
▊ Author's brief introduction
research field :FightingCV Official account operator , The research direction is multimodal content understanding , Focus on solving the task of combining visual modality and language modality , promote Vision-Language Field application of the model .
You know / official account :FightingCV

END
Welcome to join 「Transformer」 Exchange group notes :TFM

边栏推荐
- The whole process realizes the single sign on function and the solution of "canceltoken" of undefined when the request is canceled
- 翻译公司证件盖章的价格是多少
- Play video with Tencent video plug-in in uni app
- Simulation volume leetcode [general] 1219 Golden Miner
- 论文摘要翻译,多语言纯人工翻译
- LeetCode - 152 乘积最大子数组
- Py06 字典 映射 字典嵌套 键不存在测试 键排序
- 今日夏至 Today‘s summer solstice
- 端午节快乐Wish Dragon Boat Festival is happy
- Making interactive page of "left tree and right table" based on jeecg-boot
猜你喜欢

我的创作纪念日
Private cloud disk deployment
Error getting a new connection Cause: org. apache. commons. dbcp. SQLNestedException
Summary of leetcode's dynamic programming 4

The internationalization of domestic games is inseparable from professional translation companies
基于JEECG-BOOT的list页面的地址栏参数传递
Convert the array selected by El tree into an array object
ECS accessKey key disclosure and utilization

The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower

生物医学英文合同翻译,关于词汇翻译的特点
随机推荐
oscp raven2靶机渗透过程
What are the commonly used English words and sentences about COVID-19?
Wish Dragon Boat Festival is happy
Private cloud disk deployment
What are the characteristics of trademark translation and how to translate it?
利用快捷方式-LNK-上线CS
Address bar parameter transmission of list page based on jeecg-boot
ECS accessKey key disclosure and utilization
Remember the implementation of a relatively complex addition, deletion and modification function based on jeecg-boot
国产游戏国际化离不开专业的翻译公司
Simulation volume leetcode [general] 1249 Remove invalid parentheses
基於JEECG-BOOT的list頁面的地址欄參數傳遞
Chinese English comparison: you can do this Best of luck
keil MDK中删除添加到watch1中的变量
org.activiti.bpmn.exceptions.XMLException: cvc-complex-type.2.4.a: 发现了以元素 ‘outgoing‘ 开头的无效内容
Simulation volume leetcode [general] 1218 Longest definite difference subsequence
今日夏至 Today‘s summer solstice
Day 246/300 ssh连接提示“REMOTE HOST IDENTIFICATION HAS CHANGED! ”
How effective is the Chinese-English translation of international economic and trade contracts
CS passed (cdn+ certificate) PowerShell online detailed version