当前位置:网站首页>Transformer structure analysis and the principle of blocks in it
Transformer structure analysis and the principle of blocks in it
2022-07-03 20:41:00 【SaltyFish_ Go】
transformer The architecture of
Bit by bit feedforward network
Transformer It's a use encoder-decoder framework , Pure use attention Attention mechanism , There are many in encoder and decoder transformer block , Multiple attention is used in each block , And use a bit by bit feedforward network , and layer-norm Layer normalization (batchnorm Not suitable for nlp, Because the sentences are not the same length , Different dimensions and characteristics ).
Long attention

A collection of methods through different attention mechanisms concat, That is, use the same pair key,value,query Extract different information , Then the matrix is fully connected , The dimension of the output is determined by the last fully connected output .
transformer The architecture of

The first one in the decoder masked-multi-head-attention yes self-attention structure , The second long attention is not self-attention,attention Of key,value The input is the output of the encoder .
query From the target sequence
Bit by bit feedforward network
Bit by bit feedforward network in the architecture , It can be seen as a full connection layer for changing dimensions .

Layer normalization

Each sentence layernorm, Not like an image , Each channel or feature batchnorm( On the full connection layer or convolution layer )
边栏推荐
- 同花顺开户注册安全靠谱吗?有没有风险的?
- Global and Chinese markets of polyimide tubes for electronics 2022-2028: Research Report on technology, participants, trends, market size and share
- 2022 high voltage electrician examination and high voltage electrician reexamination examination
- Camera calibration (I): robot hand eye calibration
- Upgrade PIP and install Libraries
- In 2021, the global revenue of thick film resistors was about $1537.3 million, and it is expected to reach $2118.7 million in 2028
- jvm jni 及 pvm pybind11 大批量数据传输及优化
- Assign the CMD command execution result to a variable
- MySQL 8.0 data backup and recovery
- 4. Data splitting of Flink real-time project
猜你喜欢

JVM JNI and PVM pybind11 mass data transmission and optimization

浅议.NET遗留应用改造

How to modify the network IP addresses of mobile phones and computers?

XAI+网络安全?布兰登大学等最新《可解释人工智能在网络安全应用》综述,33页pdf阐述其现状、挑战、开放问题和未来方向

Interval product of zhinai sauce (prefix product + inverse element)

Test panghu was teaching you how to use the technical code to flirt with girls online on Valentine's Day 520
Virtual machine installation deepin system
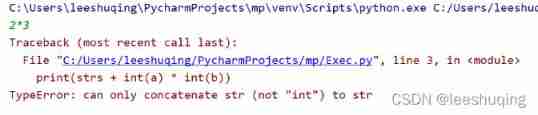
2.6 formula calculation

Example of peanut shell inner net penetration
【愚公系列】2022年7月 Go教学课程 002-Go语言环境安装
随机推荐
Kubernetes 通信异常网络故障 解决思路
强化學習-學習筆記1 | 基礎概念
JS three families
Change deepin to Alibaba image source
MySQL dump - exclude some table data - MySQL dump - exclude some table data
Day6 merge two ordered arrays
Assign the CMD command execution result to a variable
【愚公系列】2022年7月 Go教学课程 002-Go语言环境安装
JVM JNI and PVM pybind11 mass data transmission and optimization
Research Report on the overall scale, major manufacturers, major regions, products and application segmentation of rotary tablet presses in the global market in 2022
6006. Take out the minimum number of magic beans
C 10 new feature [caller parameter expression] solves my confusion seven years ago
Plan for the first half of 2022 -- pass the PMP Exam
Global and Chinese market of liquid antifreeze 2022-2028: Research Report on technology, participants, trends, market size and share
[Yugong series] February 2022 Net architecture class 004 ABP vNext used in WPF project
2.7 format output of values
Set, weakset, map, weakmap in ES6
不同业务场景该如何选择缓存的读写策略?
2022 safety officer-c certificate examination and safety officer-c certificate registration examination
《ActBERT》百度&悉尼科技大学提出ActBERT,学习全局局部视频文本表示,在五个视频-文本任务中有效!...