当前位置:网站首页>Yolov 5 Target Detection Neural Network - Loss Function Calculation Principle
Yolov 5 Target Detection Neural Network - Loss Function Calculation Principle
2022-07-05 11:42:00 【Network Star (luoc)】
Catalogue des articles
C'est déjà écrit4Article suryolov5Article de,Liens ci - dessous:
1、Basé surlibtorchDeyolov5Mise en œuvre du réseau de détection des cibles——COCOEnsemble de donnéesjsonRésolution de fichiers d'étiquettes
2、Basé surlibtorchDeyolov5Mise en œuvre du réseau de détection des cibles(2)——Mise en œuvre de la structure du réseau
3、Basé surlibtorchDeyolov5Mise en œuvre du réseau de détection des cibles(3)——KmeansAcquisition par regroupementanchorTaille du cadre
4、C++RéalisationKmeansAcquisition d'algorithmes de regroupementCOCODe l'ensemble de données de détection des ciblesanchorEncadré
Parmi eux:
Première partieCOCOEnsemble de donnéesjsonRésolution des étiquettes;
Deuxième partieyolov5Propagation positive du réseau neuronalliborchRéalisation;
Chapitre 3 UtilisationOpencvFourniKmeans Algorithme pour obtenir anchorTaille du cadre;
Le chapitre 4 parle de l'usage personnel C++RéaliséKmeans Algorithme pour obtenir anchorTaille du cadre,En termes relatifs, Acquis dans ce chapitre anchor Plus précis que celui obtenu au titre III .
Dans cet article, nous nous concentrons sur yolov5 Principe de calcul de la fonction de perte du réseau .
Mesure de l'exactitude des résultats de la détection des cibles
La tâche de détection des cibles a trois objectifs principaux: :
(1) Position de la cible détectée dans l'image , Plusieurs cibles de détection peuvent être présentes dans la même image ;
(2) Taille de la cible détectée , Habituellement un rectangle qui entoure la cible ;
(3) Identification et classification des cibles détectées .
Alors..., Déterminer l'exactitude et l'inexactitude des résultats des essais , Mesuré principalement en fonction des trois objectifs ci - dessus :
(1) Commençons par définir la situation idéale. : Toutes les positions de la cible réelle dans l'image , Ont été détectés . Plus le résultat du test est proche de cet état idéal , C'est - à - dire qu'il n'y a pas d'inspection. / Moins il y a d'erreurs de détection , Plus le résultat est précis ;
(2) Définir également le cas idéal : La boîte rectangulaire détectée entoure exactement la cible détectée . Plus le résultat du test est proche de cet état idéal , Donc plus le résultat est précis ;
(3) Cible détectée , Identification et classification , Plus le résultat de la classification correspond à la classification réelle de l'objectif , Plus le résultat est précis .
Comme le montre la figure ci - dessous,Les gens、 Bus comme cible de détection , Tout le monde et le bus doivent être détectés. , Détectez également le plus petit rectangle qui entoure la personne et le bus , En même temps, identifiez quel rectangle est une personne , Quelle boîte rectangulaire contient le bus .
yolov5Composition de la fonction de perte du réseau
Comme nous l'avons déjà dit yolov5 L'idée de base du réseau :
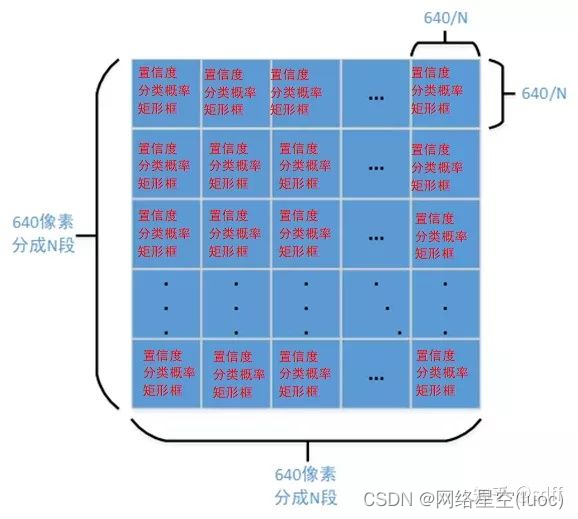
Prends ça.640640 L'image d'entrée est divisée en NN(Généralement8080、4040、20*20)Grille pour, Trois indicateurs sont ensuite prévus pour chaque grille de la grille :Cadre rectangulaire、Degré de confiance、Probabilité de classification.Parmi eux:
- La boîte rectangulaire représente la taille et la position exacte de la cible .
- Cadre rectangulaire prédit par la représentation du degré de confiance ( Cadre de prévision abrégé )Degré de confiance,Plage de valeurs0~1, Plus la valeur est élevée, plus la cible est probable dans ce rectangle .
- Classification probabilité caractérisation de la catégorie cible .
Donc au moment de l'examen :
- Déterminer d'abord si le niveau de confiance prévu de chaque boîte de prévision dépasse le seuil fixé. , Si elle est dépassée, l'objectif est considéré comme présent dans la zone de prévision. , Pour obtenir l'emplacement approximatif de la cible .
- Ensuite, le cadre de prédiction de la cible existante est filtré selon l'algorithme de suppression non maximale. , Supprimer les rectangles dupliqués correspondant à la même cible ( .Algorithme de suppression non maximum ).
- Enfin, selon la probabilité de classification de la boîte de prévision filtrée , Prendre l'index correspondant à la probabilité maximale , Est l'index de classification cible , Pour obtenir la catégorie cible .
Le rôle de la fonction de perte est de mesurer l'information prédictive et l'information attendue du réseau neuronal. (Étiquettes)Distance de, Plus l'information prévue est proche de l'information attendue ,Moins la valeur de la fonction de perte est élevée. À partir des informations de prévision de chaque grille ci - dessus , La formation comporte trois aspects principaux de la perte : Perte de cadre rectangulaire (lossrect)、Perte de confiance(lossobj)、Pertes classées(lossclc).Donc,yolov5 La fonction de perte du réseau est définie comme suit: :
Loss=alossobj+ blossrect+ c*lossclc
C'est - à - dire que la perte totale est la somme pondérée des trois pertes , Habituellement, la perte de confiance prend le poids maximal , Poids de la perte de cadre rectangulaire et de la perte de classification ,Par exemple,:
a = 0.4
b = 0.3
c = 0.3
yolov5UtiliserCIOU loss Calculer la perte de cadre rectangulaire , Perte de confiance et perte de classification BCE lossCalcul, Les principes de calcul des différentes fonctions de perte sont décrits en détail ci - dessous. .
maskMatrice de masque
En bas, nous prenons8080 Exemple de grille mask Définition du masque 、Objet, Et comment obtenir .4040 Grille et 20*20 La grille est similaire .
Qu'est - ce quemaskMasque?
Une image segmentée par un réseau neuronal 80 * 80 La grille prédit 3 * 80 * 80Boîte de prévision, Y a - t - il des cibles de détection dans chaque boîte de prévision? ?Apparemment non.. Il faut donc d'abord faire un jugement préliminaire sur l'étiquette lors de l'entraînement , Quelles zones de prévision sont susceptibles d'avoir des cibles ?mask Le masque est comme ça 3 * 80 * 80DeboolMatrice de type:3 * 80 * 80- Oui.boolValeur et3 * 80 * 80 Chaque boîte de prévision correspond à , Déterminer s'il y a des cibles dans chaque zone de prévision en fonction de l'information sur l'étiquette et de certaines règles ,S'il existemask La valeur de la position correspondante dans la matrice est définie à true,Sinon, définissez àfalse.
mask À quoi sert un masque? ?
Les réseaux neuronaux8080 Chaque grille de la grille prédit trois boîtes rectangulaires ,Donc la sortie380*80Boîte de prévision, L'information sur les prévisions pour chaque boîte de prévision comprend l'information sur les boîtes rectangulaires 、Degré de confiance、Probabilité de classification.En fait,, Toutes les cases de prévision ne nécessitent pas le calcul des valeurs de la fonction de perte pour toutes les catégories ,Mais selonmask Matrice à déterminer :
- Seulementmask La position correspondante dans la matrice est trueBoîte de prévision pour, La perte de rectangle doit être calculée ;
- Seulementmask La position correspondante dans la matrice est trueBoîte de prévision pour, La perte de classification doit être calculée ;
- La perte de confiance doit être calculée pour toutes les cases de prévision. ,MaismaskPourtrue Cadre de prévision et maskPourfalse La valeur de l'étiquette de confiance de la boîte de prévision est différente .
Pour80*80Grille, Les expressions de calcul des différentes fonctions de perte sont les suivantes: ,Parmi euxaPourmaskPourtrue Poids de la perte de confiance dans le temps ,En général, les valeurs sont0.5~1Entre, Permet au réseau de se concentrer davantage sur la formation maskPourtrueSituation.
4040Grille et2020 Calcul de la fonction de perte et 80*80La grille est similaire, Enfin, les valeurs de la fonction de perte de toutes les grilles sont pondérées en somme , C'est - à - dire obtenir la valeur finale de la fonction de perte d'une image d'entraînement :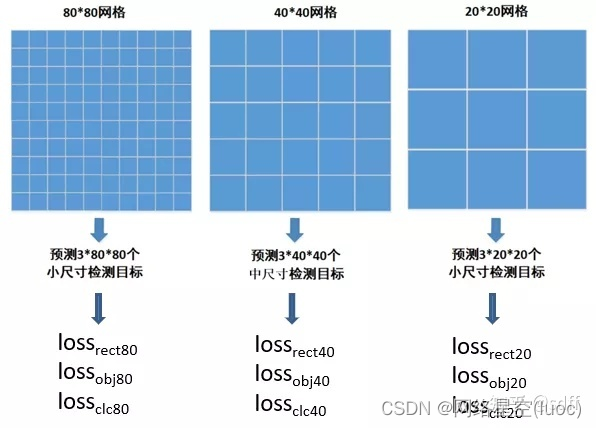
En hautα1、α2、α3 Est le coefficient de pondération de la valeur de la fonction de perte de chaque grille . Étant donné qu'il y a souvent plus de petites cibles dans l'image, , Cible moyenne secondaire , Les grands objectifs sont les moins importants , C'est pourquoi, en général, 8080 Poids du maillage α1Définir le maximum,4040 Poids du maillage α2Deuxième,20*20 Poids du maillage α3Minimum, Faire en sorte que le réseau se concentre davantage sur un grand nombre d'objectifs pendant la formation ,Par exemple,α1、α2、α3À tour de rôle.0.5、0.3、0.2.
Comment?maskMasque?
Voici quelques détails. mask Comment obtenir la matrice .
D'abord38080Demask Toutes les matrices sont définies à false.PourCOCOEnsemble de donnéesjson Chaque boîte cible d'une image marquée dans un fichier d'étiquettes , Suivez ces étapes pour juger , Et sur la base de ce jugement mask La position correspondante de la matrice est définie à true:
(1)Dejson Le fichier label résout les coordonnées centrales et la largeur et la hauteur de toutes les boîtes cibles dans une seule image , Et la largeur et la hauteur de l'image . Supposons que l'analyse donne les coordonnées centrales d'une boîte cible comme (x, y),Large、Les hauteurs sontw、h, La largeur et la hauteur de l'image sont respectivement wi、hi.Il faut(x, y)Convertir en640640Coordonnées de l'image(x’, y’),Et vaw、hConvertir en640640 Largeur et hauteur du cadre cible dans l'image wgt、hgt.
(2)Puis par(x’, y’) Calculer la zone cible dans 80*80 Coordonnées de la grille dans la grille (xg,yg),Attention!xg,、ygCe sont des nombres flottants.
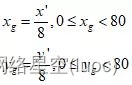
(3)- Oui.xg、ygArrondi vers le bas, Obtenir les coordonnées de la grille entière (x0, y0). En même temps, afin d'accélérer la vitesse de convergence de l'entraînement, ,yolov5 Sur la grille (x0, y0)Gauche et droite、 Prenez une grille adjacente de haut en bas :(x1, y0)Et(x0, y1). Comment le prendre? ?Comme le montre la figure ci - dessous:, Point rouge (xg,yg):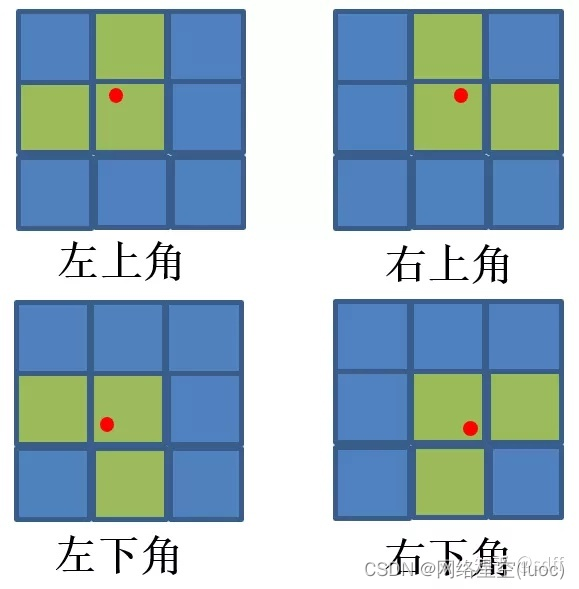
Si vous commandez(xg,yg) Dans le coin supérieur gauche de la grille , Prends à gauche. 、 Les deux grilles au - dessus ;Si vous commandez(xg,yg) Dans le coin supérieur droit de la grille , Prends à droite. 、 Les deux grilles au - dessus ;Si vous commandez(xg,yg) Dans le coin inférieur gauche de la grille , Prends à gauche. 、 Deux grilles en dessous ;Si vous commandez(xg,yg) Dans le coin inférieur droit de la grille , Prends à droite. 、 Deux grilles en haut et en bas ;
Selon les principes ci - dessus,x1Ety1 Peut être calculé selon la formule suivante: ,Parmi euxround Pour arrondir :
(4)Après la(3)Pas, Trois grilles adjacentes. (x0, y0)、(x1, y0)、(x0, y1), Nous pensons que le cadre cible est situé près de ces trois grilles .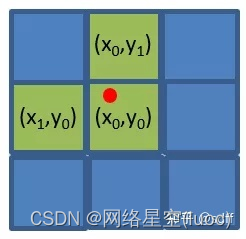
Comme nous l'avons mentionné précédemment, nous utilisons Kmeans L'algorithme de regroupement obtient neuf anchor Dans la boîte ,C'est tout.:
- Large、 Plus petit anchor0、anchor1、anchor2Affectation à80*80 Chaque grille de la grille ;
- Large、 Supérieur et inférieur anchor3、anchor4、anchor5Affectation à40*40 Chaque grille de la grille ;
- Large、 Plus grand anchor6、anchor7、anchor8Affectation à20*20 Chaque grille de la grille .
Donc,80*80Dans la grille(x0, y0)、(x1, y0)、(x0, y1) Ces trois grilles correspondent anchor0、anchor1、anchor2Ces troisanchorEncadré.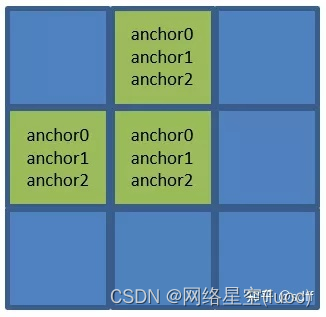
(5)Hypothèsesanchor0、anchor1、anchor2Ces troisanchor La largeur et la hauteur du cadre sont respectivement (w0, h0)、(w1, h1)、(w2, h2),Dejson Le fichier Tag est analysé pour obtenir la largeur et la hauteur de la boîte cible de (wgt, hgt), Et calculer séparément (wgt, hgt)Avec(w0, h0)、(w1, h1)、(w2, h2)Proportion de, Les produits qui ne satisfont pas aux exigences sont éliminés en fonction de la proportion. anchorEncadré:
À conserver anchor Les cases sont marquées comme suit: true,Suppriméanchor Les cases sont marquées comme suit: false,Alorsanchor0、anchor1、anchor2 L'étiquette correspondante est (m0, m1, m2):
(6)Selon80*80Dans la grille(x0, y0)、(x1, y0)、(x0, y1) Ces trois coordonnées ,On est séparés.maskAffectation matricielle: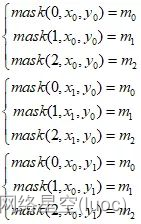
Pour toutes les boîtes cibles d'une image , Tout ce qui précède et maskAffectation matricielle, Pour obtenir cette image maskMatrice.
Principe de calcul de la perte de cadre rectangulaire
Pourquoi commencer par la perte d'un cadre rectangulaire? ? Parce que le principe de perte de confiance décrit plus loin est utilisé pour la perte de rectangle .
Comme nous l'avons déjà dit,yolov5 Prévoir pour chaque grille 3 Boîtes rectangulaires de différentes positions et tailles , Où l'information pour chaque rectangle est au Centre du rectangle xCoordonnées、yCoordonnées, Et la largeur du rectangle 、Élevé. Supposons que le rectangle prévu pour une grille soit (xp, yp, wp, hp), Le rectangle cible correspondant à la grille est (xl, yl, wl, hl), Les principes de calcul des fonctions de perte des cadres rectangulaires les plus courants sont expliqués ci - dessous. .
L1、L2、smooth L1Fonction de perte
D'abordL1Fonction de perte: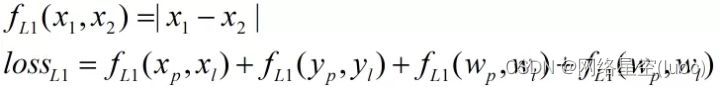
Et ensuite,L2Fonction de perte: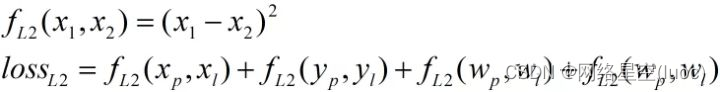
Et puis...smooth L1Fonction de perte: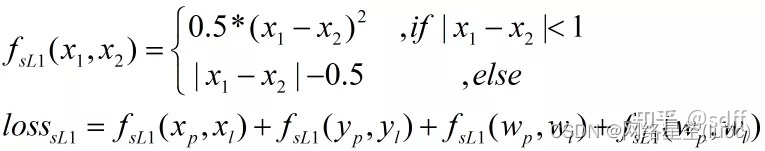
Dans la formule ci - dessus,Noted=x1-x2,Dessinez séparémentfL1(d)、fL2(d)、fsL1(d)La courbe de:
Comme le montrent les formules et les courbes de calcul ci - dessus, :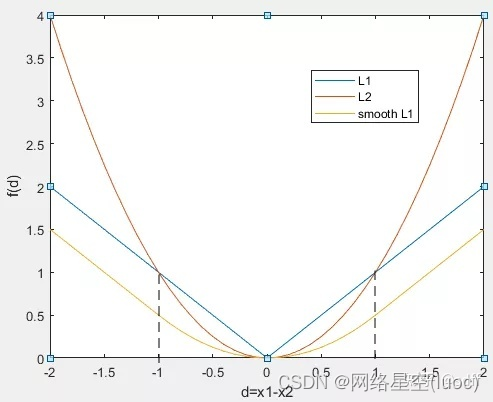
(1)fL1(d) Les courbes gauche et droite de la fonction sont dDérivé de(Pente)Est constant,Mais dansd=0 La fonction n'est pas dérivée à , Mais avec l'entraînement ,d=x1-x2Ça va s'approcher0, Il en résulte que la valeur de la fonction de perte fluctue autour d'une certaine valeur à la fin de l'entraînement. ,Difficile de converger.
(2)fL2(d)Fonction dansd=0 La provenance est dérivable ,N'existe pasfL1(d)Le problème avec la fonction, Mais dans la phase de pré - formation dTrès souvent,fL2(d)Fonction pourd La dérivée de , Cela pourrait causer des problèmes d'explosion par gradient , Donc l'entraînement n'a pas pu aller dans la direction de l'optimisation .
(3)fsL1(d) La fonction est fragmentée ,Il vafL1(d)Fonctions、fL2(d) Les avantages de la fonction sont combinés , Et en même temps parfaitement contourné fL1(d)Fonctions、fL2(d)Inconvénients de la fonction.
IOU Fonction de perte de série
Pour calculer le cadre rectangulaire ci - dessus L1、L2、smooth L1 Il y a une chose en commun quand on perd , Calcule séparément le point central du rectangle xCoordonnées、Point centralyCoordonnées、Large、 Pertes élevées , Enfin, les quatre valeurs de perte sont additionnées pour obtenir la valeur de perte finale du rectangle. . La prémisse de cette méthode de calcul est que le point central xCoordonnées、Point centralyCoordonnées、Large、 Ces quatre valeurs sont indépendantes les unes des autres. , En fait, ils sont pertinents , Il y a donc un problème avec cette méthode de calcul .
Et donc,,IOU Fonction de perte de série (IOU、GIOU、DIOU、CIOU) Il a été mentionné successivement .CalculIOU La fonction de perte de série nécessite l'utilisation du coin supérieur gauche de la boîte rectangulaire 、Coordonnées du coin inférieur droit, Supposons que le coin supérieur gauche du rectangle de prévision 、 Les coordonnées du coin inférieur droit sont (xp1, yp1)、(xp2, yp2), Coin supérieur gauche du rectangle de l'étiquette 、 Les coordonnées du coin inférieur droit sont (xl1, yl1)、(xl2, yl2),Comme le montre la figure ci - dessous: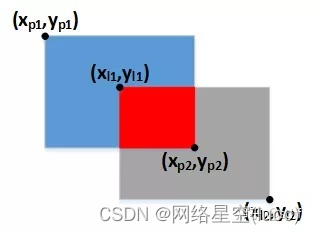
Coordonnées centrales du rectangle 、Large、 La hauteur peut être convertie en haut à gauche selon la formule ci - dessous 、Coordonnées du coin inférieur droit: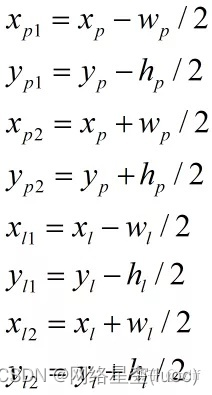
Voici une description deIOU、GIOU、DIOU、CIOU Principe de calcul de la fonction de perte .
(1)IOU loss
IOU Est le rapport entre la surface de la zone d'intersection de deux boîtes et la surface de la partie parallèle , C'est aussi connu sous le nom de . Trouvez d'abord la zone de la partie d'intersection :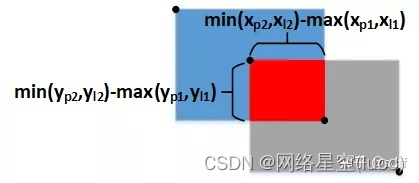
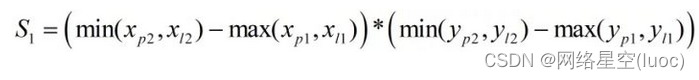
Ensuite, trouvez la zone de la partie parallèle de la phase :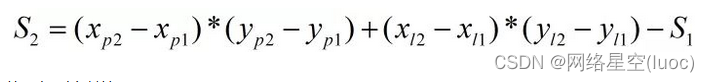
Pour obtenir un rapport IOU: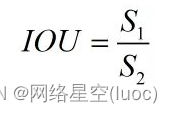
IOULa plage de valeurs pour0~1, Lorsque deux boîtes rectangulaires ne se croisent pas du tout ,IOUPour0, Quand ils coïncident complètement IOUPour1, C'est - à - dire que plus le degré de coïncidence est faible IOUPlus vous approchez0, Plus le degré de coïncidence est élevé IOUPlus vous approchez1.
Enfin.IOU lossEst calculé comme suit:, Plus les deux cadres rectangulaires coïncident IOU lossPlus vous approchez0: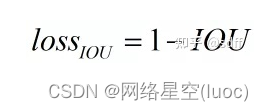
(2)GIOU loss
Lorsque deux boîtes rectangulaires ne se chevauchent pas du tout ,Quelle que soit leur distance,LeurIOUTous.0. Dans ce cas, le gradient est également 0, Impossible d'optimiser .Pour résoudre ce problème,GIOU Encore une fois. .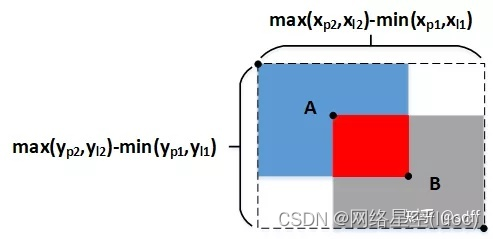
Comme le montre la figure ci - dessus,GIOUInIOUSur la base de, Enveloppe rectangulaire A Et rectangle B Boîte rectangulaire minimale pour ( Lignes pointillées dans l'illustration ) La surface de .
GIOU Peut être calculé selon la formule suivante: ,Parmi euxS1PourA、B Zone de la partie d'intersection (Zone rouge).Parmi euxS3 Pour encercler A、B Surface de la plus petite boîte rectangulaire de ,S2PourA、B Zone de la zone de fusion (Bleu+Rouge+Zone grise).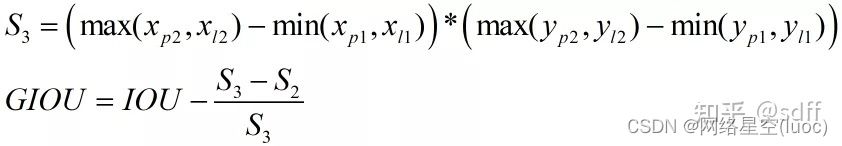
D'après la formule ci - dessusGIOUComparé àIOU,Ajouté(S3-S2)/S3Celui - ci. Qu'est - ce que ça veut dire? ?D'après ce qui précède,S3-S2 Est la zone de la zone blanche dans le cadre pointillé , C'est - à - dire qu'il n'appartient pas à AÇa n'appartient pas non plus.BEspace blanc pour,Alors(S3-S2)/S3 Est la proportion de la zone vide par rapport à la zone du cadre pointillé , Plus cette proportion est élevée, plus A、BPlus la distance est grande、 Plus le chevauchement est faible ,Et inversement,A、BPlus la distance est proche、 Plus le chevauchement est grand .GIOULa plage de valeurs pour est-1~1,QuandA、B Quand il n'y a pas de chevauchement IOUPour0,AlorsGIOUValeur négative,Cas extrêmes,QuandA、B Sans chevauchement et à une distance infinie ,En ce moment(S3-S2)/S3égal à1,AlorsGIOUPrends - le.-1; Un autre cas extrême ,QuandA、B Lorsque le chevauchement est complet (S3-S2)/S3égal à0,IOUPour1,AlorsGIOUPrends - le.1.Donc,,GIOURésolu quandA、B Quand il n'y a pas de chevauchement IOUHengwei0La question de.
Enfin.GIOU lossFormule de calcul pour: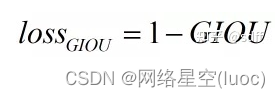
(3)DIOU loss
GIOUBien queIOULe problème est résolu., Mais c'est toujours une mesure basée sur la surface , Avec les deux rectangles A、B Compte tenu de la distance . Pour rendre l'entraînement plus stable 、Convergence plus rapide,DIOU Et il a été soulevé ,DIOU Boîte rectangulaire A、B Distance du point central ρ、 Cadre rectangulaire externe (Tirets)Longueur diagonale dec C'est tout. ,Comme le montre la figure ci - dessous: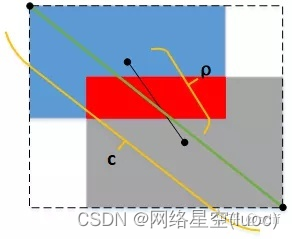
DIOU Peut être calculé selon la formule suivante: :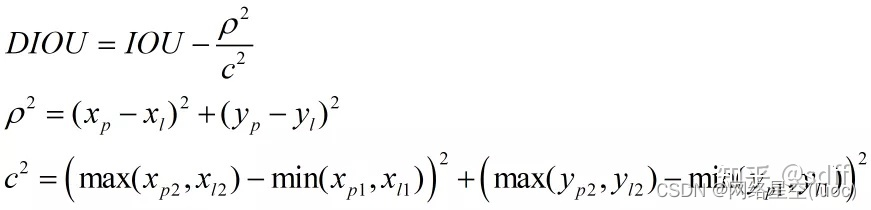
D'après la formule ci - dessusDIOU La plage de valeurs pour -1~1, Quand deux boîtes A、B Quand ils coïncident complètement DIOUPrends - le.1,QuandA、B à une distance infinie ,DIOUPrends - le.-1.
Pour obtenirDIOU lossFormule de calcul pour: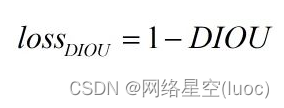
(4)CIOU loss
yolov5UtiliserCIOU loss Pour mesurer la perte d'un cadre rectangulaire .
DIOU Placer deux cadres rectangulaires A、B Zone de chevauchement 、 La distance du Centre est prise en compte , Mais n'a pas considéré A、BRapport d'aspect. Afin d'améliorer encore la stabilité et la vitesse de convergence de l'entraînement ,InDIOUSur la base deCIOU Encore une fois. , Il chevauchera la zone 、Distance du point central、 Le rapport d'aspect est ajouté au calcul .CIOU Peut être calculé selon la formule suivante: :
En haut,ρEncadréAEt la boîteB Distance du point central ,cEncadréAEt la boîteB Longueur diagonale minimale du rectangle environnant pour ,vEncadréA、EncadréB Similitude du rapport d'aspect ,αPourv Facteurs d'influence .
Coupe de toute façonarctanLa plage de valeurs de la fonction est0Π/2,AlorsvLa plage de valeurs pour01,Quand la boîteA、EncadréB Lorsque le rapport d'aspect est égal vPrends - le.0,Quand la boîteA、EncadréB Lorsque le rapport d'aspect est infiniment différent vPrends - le.1.
Quand la boîteA、EncadréB La distance est infinie. , Et le rapport d'aspect est infiniment différent DIOUPrends - le.-1,vPrends - le.1,alphaPrends - le.0.5,En ce momentCIOUPrends - le.-1-0.5=-1.5;Quand la boîteA、EncadréB Lorsque le chevauchement est complet ,DIOUPrends - le.1,vPrends - le.0,αPrends - le.0,EtCIOUPrends - le.1.Donc,CIOULa plage de valeurs est-1.5~1.
IOU Plus il est grand, plus il est grand. A、B Plus la zone de chevauchement est grande ,EtαPlus grand.,Et doncvPlus l'impact de;Au contraireIOU Plus petit c'est A、B Plus la zone de chevauchement est petite ,EtαPlus petit.,Et doncvPlus l'impact est faible. Donc dans le processus d'optimisation :
- SiA、B La zone de chevauchement est petite , Rapport d'aspect v Moins d'influence dans la fonction de perte , Mettre l'accent sur l'optimisation A、BDistance de;
- SiA、B Grande zone de chevauchement , Rapport d'aspect v L'influence est également importante dans la fonction de perte , Mettre l'accent sur l'optimisation A、BRapport d'aspect.
En un mot,, Il manque quelque chose. , Plus on se concentre sur ce qu'il faut compenser , Afin d'accélérer la vitesse de convergence et la stabilité de la formation optimale .
Disponible à partir de CIOU lossEst calculé comme suit::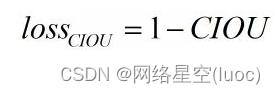
Principe de calcul de la perte de confiance
En bas8080 Exemple de grille , Expliquer en détail le principe de calcul de la perte de confiance ,4040Et2020 Le principe de calcul de la perte de confiance de la grille 8080 La grille est la même. , Et ainsi de suite .
Confiance dans la prédiction des réseaux neuronaux
Pour une image 8080Grille pour, Le réseau neuronal prédit trois cadres rectangulaires près de chaque grille ( Cadre de prévision abrégé ), Les informations de prévision pour chaque boîte de prévision comprennent les coordonnées centrales 、Large、Élevé、Degré de confiance、Probabilité de classification, Donc la sortie totale du réseau neuronal 38080- Oui.0~1Confiance dans les prévisions,Avec380*80 Boîte de prévision 1 Une correspondance. Le degré de confiance de chaque cadre de prévision représente la fiabilité spectrale de ce cadre de prévision. , Plus la valeur est élevée, plus le cadre de prévision est fiable. , C'est - à - dire la vraie boîte de délimitation minimale plus près de la cible .Comme dans la figure ci - dessous.,Point rougeA、B、C、D Indique la cible de détection , Ensuite, les trois niveaux de confiance prédictive du réseau où chaque point rouge est situé devraient être plus grands ou plus proches. 1, D'autres grilles devraient avoir un niveau de confiance plus faible ou même plus proche 0.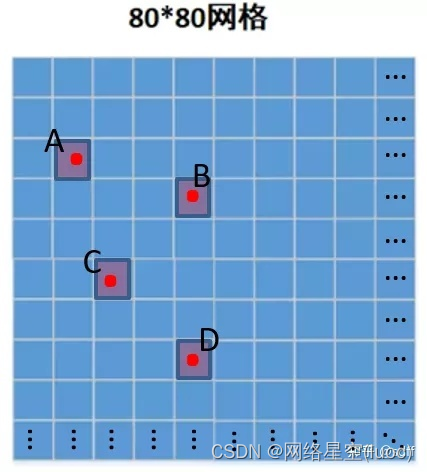
Étiquette de confiance
La dimension de l'étiquette doit être compatible avec la dimension de sortie du réseau neuronal , Par conséquent, l'étiquette de confiance est également une dimension 38080La matrice de. C'est ce que nous avons dit plus haut. maskMatrice de masque: Les dimensions sont également 38080Demask Matrice marquée , Assigner des valeurs à la matrice des étiquettes de confiance .yolo Les versions précédentes sont directement liées à maskLa matrice esttrue Affectation locale 1,maskLa matrice estfalse Affectation locale 0,Pense que tant quemaskPourtrue Cela signifie que le cadre de prévision correspondant entoure parfaitement la cible. . Ce serait trop absolu ,Parce quemaskPourtrue Ça veut juste dire que la boîte de prévision est proche de la cible. , Ce n'est pas forcément parfait. .Alors...yolov5 Changement d'approche :C'est exact.maskPourtrue La position n'est pas directement assignée 1, Au lieu de cela, calculez la valeur CIOU,UtiliserCIOU Étiquette de confiance pour cette boîte de prévision ,Bien sûr.maskPourfalse La position de 0.C'est comme ça., Taille de la valeur de l'étiquette et zone de prévision 、 Le degré de coïncidence de la boîte cible est lié à , Plus le degré de chevauchement des deux boîtes est élevé, plus la valeur de l'étiquette est élevée. .Bien sûr., Comme nous l'avons dit plus haut CIOULa plage de valeurs pour est-1.51, La plage de valeurs de l'étiquette de confiance est 01,Il faut donc avoir raison.CIOU Faire une troncature :QuandCIOUMoins de0 Prendre directement 0Valeur comme étiquette.
BCE lossFonction de perte
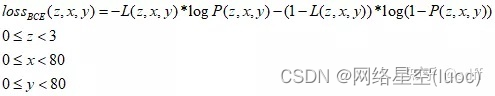
Fausse étiquette de fiabilité de la matrice L, Le degré de confiance prévu est une matrice P, Donc chaque valeur de la matrice BCE lossEst calculé comme suit::
Attention!BCE loss La plage de valeurs requise pour les données d'entrée doit être 0~1Entre.
De80*80 Valeur de perte de confiance pour la grille :
En outre, On appelle ça une correspondance. maskBitstrue La boîte de prévision pour est un échantillon positif ,Correspondant àmaskPourfalse La boîte de prévision pour est un échantillon négatif , Les échantillons négatifs doivent être beaucoup plus nombreux que les échantillons positifs. , Pour que la formation se concentre davantage sur les échantillons positifs ,Et puisFocal loss Encore une fois. , Nous ne nous attarderons pas ici sur , Plus de détails dans le prochain article .
Principe de calcul des pertes par catégorie
En bas aussi. 8080 Exemple de grille , Expliquer en détail le principe de calcul des pertes classifiées ,4040Et2020 Principe de calcul de la perte de classification et 8080 La grille est la même. , Et ainsi de suite .Les réseaux neuronaux8080 Chaque grille de la grille prévoit trois boîtes de prévision , Les informations de prévision pour chaque boîte de prévision contiennent: NProbabilité de classification.Parmi euxNEst le nombre total de catégories,Par exemple,COCOL'ensemble de données contient:80Catégories,AlorsNPrends - le.80.Donc, pourCOCOEnsemble de données,Chaque case de prévision contient80- Oui.0~1 Probabilité de classification , Donc le réseau neuronal prédit 3808080Probabilité de classification, Composition de la matrice de probabilité de prédiction .
8080 La matrice de probabilité de l'étiquette de la grille est la même que la dimension de la matrice de probabilité prédictive. ,C'est aussi3808080. Étiquette de chaque boîte de prévision ,Par résolutionjson Fichier d'étiquettes obtenu ,C'est un079La valeur de,Il faut079 Valeur numérique convertie en 80 Nombre de codes thermiques uniques :
Et pourtant,Pour réduire le surajustement, Et augmenter la stabilité de l'entraînement , Habituellement, une opération de lissage est effectuée sur une étiquette de code thermique unique .Comme suit:,label Est toutes les valeurs du Code thermique unique ,αEst le facteur de lissage,Plage de valeurs0~1,Normalement.0.1.
De même, la probabilité de fausse étiquette est la matrice Lsmooth, La probabilité de prévision est une matrice P, Donc chaque valeur de la matrice BCE lossEst calculé comme suit::
Et j'ai80*80 Formule de calcul de la valeur de la fonction de perte de classification du maillage :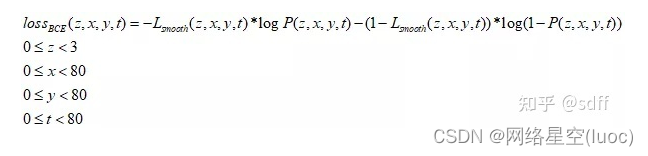
Conclusion
C'est bon, On en est arrivés là .Dis quelque chose., Aucun article n'a été mis à jour tous les deux ou trois mois , Je suis désolé, les fans . Parce que je n'ai pas seulement changé d'emploi à la fin de l'année , Les villes de travail ont changé. , On ne peut pas s'empêcher de courir et de s'adapter. , La mise à jour a donc été retardée .Mais..., Je prends toujours mon temps libre pour étudier. 、Mise à jour, Répondre aux attentes de mes fans ~Bonne année à tous les amis,Tout va bien.(Une bénédiction tardive^^)!
边栏推荐
- Oneforall installation and use
- 【爬虫】wasm遇到的bug
- 【TFLite, ONNX, CoreML, TensorRT Export】
- 居家办公那些事|社区征文
- Proof of the thinking of Hanoi Tower problem
- AUTOCAD——遮罩命令、如何使用CAD对图纸进行局部放大
- 以交互方式安装ESXi 6.0
- 谜语1
- COMSOL -- establishment of geometric model -- establishment of two-dimensional graphics
- Idea set the number of open file windows
猜你喜欢
Redis集群的重定向

7 大主题、9 位技术大咖!龙蜥大讲堂7月硬核直播预告抢先看,明天见

11.(地图数据篇)OSM数据如何下载使用

How can China Africa diamond accessory stones be inlaid to be safe and beautiful?
idea设置打开文件窗口个数
go语言学习笔记-分析第一个程序

The ninth Operation Committee meeting of dragon lizard community was successfully held
Go language learning notes - analyze the first program

13.(地图数据篇)百度坐标(BD09)、国测局坐标(火星坐标,GCJ02)、和WGS84坐标系之间的转换

pytorch训练进程被中断了
随机推荐
【Win11 多用户同时登录远程桌面配置方法】
Web API配置自定义路由
[LeetCode] Wildcard Matching 外卡匹配
程序员内卷和保持行业竞争力
C operation XML file
Solve readobjectstart: expect {or N, but found n, error found in 1 byte of
NFT 交易市场主要使用 ETH 本位进行交易的局面是如何形成的?
网络五连鞭
Install esxi 6.0 interactively
[office] eight usages of if function in Excel
项目总结笔记系列 wsTax KT Session2 代码分析
Acid transaction theory
【Office】Excel中IF函数的8种用法
爬虫(9) - Scrapy框架(1) | Scrapy 异步网络爬虫框架
阻止瀏覽器後退操作
MySQL 巨坑:update 更新慎用影响行数做判断!!!
解决grpc连接问题Dial成功状态为TransientFailure
Project summary notes series wstax kt session2 code analysis
Guys, I tested three threads to write to three MySQL tables at the same time. Each thread writes 100000 pieces of data respectively, using F
IPv6与IPv4的区别 网信办等三部推进IPv6规模部署