当前位置:网站首页>Flink SQL knows why (XI): weight removal is not only count distinct, but also powerful duplication
Flink SQL knows why (XI): weight removal is not only count distinct, but also powerful duplication
2022-07-03 13:10:00 【Big data sheep said】
What do you think , Baby , Not three in a row ???( Focus on + give the thumbs-up + Look again ), Affirmation of bloggers , It will urge bloggers to continuously output more high-quality practical content !!!
1. Preface
Source official account back office reply 1.13.2 deduplication The wonderful way of analysis obtain .
The following is the article directory , It also corresponds to the conclusion of this paper , Small partners can see the conclusion first and quickly understand what help the blogger expects this article to bring to small partners :
Introduction to background and application scenarios : Bloggers expect you to know ,flink sql Of deduplication In fact, that is row_number = 1, So it can be heavy at the same time , It can also retain the original field data
A practical case : Bloggers report repeated scenes with a log , To lead to the following flink sql deduplication Solution
be based on Deduplication Solution and principle analysis of : Bloggers expect you to know ,deduplication in , When row_number order by proctime( The processing time ) The principle of weight removal is to give each partition key Maintain a value state. If at present value state Not empty , shows id I've been here , At present, this data does not need to be distributed . If value state It's empty , be id Not yet... Not yet , hold value state After marking , Distribute the current data .
Summary and prospect
2. Introduction to background and application scenarios
Have you ever encountered a scene :
Because the data sent from the upstream is duplicate or the log source data is repeatedly reported , Lead to downstream calculation count,sum Time is too much
Want to do the same time of de recalculation , All fields of the original table can be retained and distributed normally
So what solutions can you think of ?
A small partner familiar with offline computing may soon be able to give the answer . you 're right ,hive sql Medium row_number = 1.flink sql It also provides as like as two peas. ,xdm, Solve this problem perfectly .
Let's start the official chapter .
3. A practical case
First, let's take a real case to see in the scenario of specific input values , What the output value should look like .
scene : The fields of buried point data reporting are id( Identify the only log ),timestamp( Event timestamp ),page( The current page at which the event occurred ),param1,param2,paramN…. However, when the log is reported, the log report is repeated due to some mechanisms , There are many downstream , Therefore, we need to do a weight removal , Downstream to consume heavy data .
A wave of input data :
| id | timestamp | page | param1 | param2 | paramN |
|---|---|---|---|---|---|
| 1 | 2021-11-01 00:01:00 | A | xxx1 | xxx2 | xxxN |
| 1 | 2021-11-01 00:01:00 | A | xxx1 | xxx2 | xxxN |
| 2 | 2021-11-01 00:01:00 | A | xxx3 | xxx2 | xxxN |
| 2 | 2021-11-01 00:01:00 | A | xxx3 | xxx2 | xxxN |
| 3 | 2021-11-01 00:03:00 | C | xxx5 | xxx2 | xxxN |
The second and fourth articles are the repeatedly reported data , The expected output data are as follows :
| id | timestamp | page | param1 | param2 | paramN |
|---|---|---|---|---|---|
| 1 | 2021-11-01 00:01:00 | A | xxx1 | xxx2 | xxxN |
| 2 | 2021-11-01 00:01:00 | A | xxx3 | xxx2 | xxxN |
| 3 | 2021-11-01 00:03:00 | C | xxx5 | xxx2 | xxxN |
4. be based on Deduplication Solution and principle analysis of
4.1.sql How to write it
Or the above case , Let's look at the final sql How to write :
select id,
timestamp,
page,
param1,
param2,
paramN
from (
SELECT
id,
timestamp,
page,
param1,
param2,
paramN
-- proctime Represents the processing time, i.e source In the table PROCTIME()
row_number() over(partition by id order by proctime) as rn
FROM source_table
)
where rn = 1
above sql It should be well understood . Because we don't care about the time of duplicate data reporting , So we can use it directly here order by proctime To deal with , Go to the first item according to the time before and after the data .
4.2.proctime Next flink Generated operator graph and sql Operator semantics
The operator diagram is as follows :

deduplication
source operator :source adopt keyby The way to deduplication When the operator sends data , among keyby Of key Namely sql Medium id
deduplication operator :deduplication Operator for each partition key All maintained a value state Used to remove heavy . Every time a piece of data comes, it will start from the current partition key Of value state To get value, If it's not empty , It means that there has been data , The current data is duplicate data , You won't send it to the downstream operator , If it is empty , It means that there is no data before , The current data is the first data , The current value state Value is set to true, Send data to downstream operator
4.3.proctime Next deduplication Principle analysis
The specific de duplication operator is deduplication. We go through transformation You can see that the de duplication operator is shown in the figure below :

transformation
The above de duplication logic focuses on org.apache.flink.table.runtime.operators.deduplicate.ProcTimeDeduplicateKeepFirstRowFunction Of processFirstRowOnProcTime, As shown in the figure below :

ProcTimeDeduplicateKeepFirstRowFunction
5. Summary and prospect
Source official account back office reply 1.13.2 deduplication The wonderful way of analysis obtain .
This paper mainly introduces deduplication Application scenario and its operation principle , It mainly includes the following two parts :
Introduction to background and application scenarios : Bloggers expect you to know ,flink sql Of deduplication In fact, that is row_number = 1, So it can be heavy at the same time , It can also retain the original field data
A practical case : Bloggers report repeated scenes with a log , To lead to the following flink sql deduplication Solution
be based on Deduplication Solution and principle analysis of : Bloggers expect you to know ,deduplication in , When row_number order by proctime( The processing time ) The principle of weight removal is to give each partition key Maintain a value state. If at present value state Not empty , shows id I've been here , At present, this data does not need to be distributed . If value state It's empty , be id Not yet... Not yet , hold value state After marking , Distribute the current data .
Summary and prospect
边栏推荐
- 有限状态机FSM
- [exercise 5] [Database Principle]
- GaN图腾柱无桥 Boost PFC(单相)七-PFC占空比前馈
- 【计网】第三章 数据链路层(2)流量控制与可靠传输、停止等待协议、后退N帧协议(GBN)、选择重传协议(SR)
- The 35 required questions in MySQL interview are illustrated, which is too easy to understand
- SLF4J 日志门面
- 我的创作纪念日:五周年
- Simple use and precautions of kotlin's array array and set list
- Differences and connections between final and static
- Brief introduction to mvcc
猜你喜欢

Image component in ETS development mode of openharmony application development

【数据挖掘复习题】
Detailed explanation of the most complete constraintlayout in history
![[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter IV exercises]](/img/8b/bef94d11ac22e3762a570dab3a96fa.jpg)
[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter IV exercises]

GaN图腾柱无桥 Boost PFC(单相)七-PFC占空比前馈
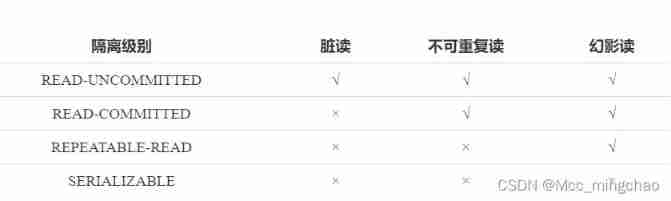
Four problems and isolation level of MySQL concurrency

Node. Js: use of express + MySQL
![[comprehensive question] [Database Principle]](/img/d7/8c51306bb390e0383a017d9097e1e5.png)
[comprehensive question] [Database Principle]
【数据库原理及应用教程(第4版|微课版)陈志泊】【第四章习题】
对业务的一些思考
随机推荐
[exercise 7] [Database Principle]
The upward and downward transformation of polymorphism
C graphical tutorial (Fourth Edition)_ Chapter 15 interface: interfacesamplep268
我的创作纪念日:五周年
Understanding of CPU buffer line
Deeply understand the mvcc mechanism of MySQL
【数据库原理复习题】
The 35 required questions in MySQL interview are illustrated, which is too easy to understand
GaN图腾柱无桥 Boost PFC(单相)七-PFC占空比前馈
The foreground uses RSA asymmetric security to encrypt user information
【计网】第三章 数据链路层(2)流量控制与可靠传输、停止等待协议、后退N帧协议(GBN)、选择重传协议(SR)
【R】 [density clustering, hierarchical clustering, expectation maximization clustering]
Cache penetration and bloom filter
CVPR 2022 图像恢复论文
Grid connection - Analysis of low voltage ride through and island coexistence
剑指 Offer 14- II. 剪绳子 II
Sword finger offer 11 Rotate the minimum number of the array
Huffman coding experiment report
【判断题】【简答题】【数据库原理】
35道MySQL面试必问题图解,这样也太好理解了吧