当前位置:网站首页>按需视觉识别:愿景和初步方案
按需视觉识别:愿景和初步方案
2022-08-04 19:10:00 【PaperWeekly】

作者 | 谢凌曦
单位 | 清华大学
研究方向 | 计算机视觉
本次写文章,是希望宣传我们最近放在 arXiv 上,并且开源的文章《按需视觉识别》。这是我个人比较看重的一个工作,因为它讨论了视觉识别中的评价指标问题;而我越来越坚定地认为,在计算机视觉进入瓶颈期的当下,定义合理的评价指标,比刷新现有评价指标上的 SOTA,要更重要一些。
当然,限于水平原因,文章只揭示了很肤浅的问题,并且提供了非常初步的解决方案。我们希望能够以此为契机,抛砖引玉,引发大家对这些重要问题的思考,进而促进更优方案的诞生。
文章的第一作者是唐楚峰 @chufengt 同学,文章的合作者也包括我的同事张晓鹏博士、清华大学胡晓林教授以及我的导师田奇教授。除此以外,我还要特别感谢我的同事魏龙辉和彭君然博士,他们都给文章提出了非常宝贵的建议。
声明:所有内容均只代表作者本人观点,均有可能被推翻,二次转载务必连同声明一起转载。谢谢!

论文标题:
Visual Recognition by Request
论文作者:
Chufeng Tang, Lingxi Xie, Xiaopeng Zhang, Xiaolin Hu, Qi Tian
论文链接:
https://arxiv.org/abs/2207.14227
代码链接:
https://github.com/chufengt/Visual-Recognition-by-Request

背景和研究动机
这个工作的动机,来源于我对于视觉识别局限性的思考。我先简单地做一些铺垫。这些铺垫和这个工作没有直接联系,读者可以跳过直接看正文。
众所周知,当前基于深度学习的计算机视觉算法,与人类的学习方式具有本质不同。其根本性原因在于:人类是在一个真实的三维世界中,以任务为驱动,进行交互式学习,而计算机只能通过标注数据来学习各种分散的任务。为什么会有这样大的区别?其实早在上个世纪 70 年代,计算机视觉的先驱之一 David Marr(Marr 奖的纪念对象)就表达过他的观点:计算机视觉算法的根本目的,是建立环境的三维模型,并且在交互过程中进行学习。然而,将近半个世纪过去,人们还是没有实现这个愿景。这里的主要原因,是三维模型难以构建,例如下面的两套方案:
1. 将真实世界建模为虚拟环境,以训练智能体。这种方式的困难之处在于,人类目前还无法构建起足够真实的虚拟环境(从虚拟环境向真实环境迁移时,通常会遇到比较大的 domain gap,以致于诞生了 unsupervised domain adaptation 等专门的领域);即使真实性得到了解决,也无法在虚拟环境中模拟真实智能体的行为,导致无法以任务来驱动学习。在这条路上走得比较远的,是一些简单的环境,比如棋类游戏和 Atari 游戏等,但是它们的复杂度和真实世界相比,有非常大的差距。
2. 将智能体放置于真实环境中进行学习。这种方式的困难之处在于,智能体在真实环境中的不可控性,将产生巨大的试错成本,包括对环境产生的危险性(如自动驾驶)和其他智能体(主要是人)与它们交互的人力成本。在这条路上走得比较远的,是一些机器人相关的研究,但是它们只能在受限环境中完成行走、抓取等相对简单的任务。
由于无法对世界建模,人们就只能退而求其次,对世界采样,并且从样本中学习。这就是为什么人们要构建、标注越来越大的图像数据集:数据集的规模越大,采样的精度就越高,就越能反映真实世界的规律。然而,这种方式是极其低效的。一方面,随着数据集的规模不断增大,上述方案产生了明显的边际效应,使得学习方法的性价比不断降低;另一方面,随着视觉概念的不断增加和细化,视觉标签的歧义性不断上升,使得评价指标的不确定性显著增加。
这里所谓视觉标签的歧义性是说,随着标签种类数的增加,一个物体究竟属于什么类,哪些部分属于这个类,就会变得不确定起来——前者可以参照 ImageNet,不少物体细粒度标签存在歧义性;后者参照各种 part-based 数据集,一只狗的头部和躯干的边界究竟在什么地方,其实是很难定义的,遑论更加细粒度的 part 了。
更重要的是,人类并不需要基于分类来认知世界。举一个直观的例子。在 ImageNet 中,存在着“家具”和“电器”两个大类;显然“椅子”属于“家具”,而“电视机”属于“家电”,但是“按摩椅”属于“家具”还是“家电”,就很难说了。然而,人类并不纠结于这件事:一个人到商场里买东西,不管商场把“按摩椅”放在“家具”区还是“家电”区,人类都可以通过简单的指引,快速找到“按摩椅”所在的区域。
综上所述,随着视觉识别的不断细化,基于分类的识别任务终将遇到不可逾越的瓶颈。这里基于分类的识别任务,包括分类、检测、分割等一切需要给目标打上明确标签的任务,因为基于分类的标注无法满足视觉信号具有的近乎无限细粒度的特性。换句话说,只要人类愿意,就可以从一张图像中识别出越来越细粒度的语义信息(如图 1 所示);而这些信息,很难通过有限而规范的标注,形成语义上完整的数据集,供算法学习。我在去年年中写了一篇 opinion paper,整理了这些观点(见下)。经过一年的思考,我们终于在 opinion paper 的基础上迈出了一小步。
怎样的视觉识别算法才是完整的?
https://zhuanlan.zhihu.com/p/376145664
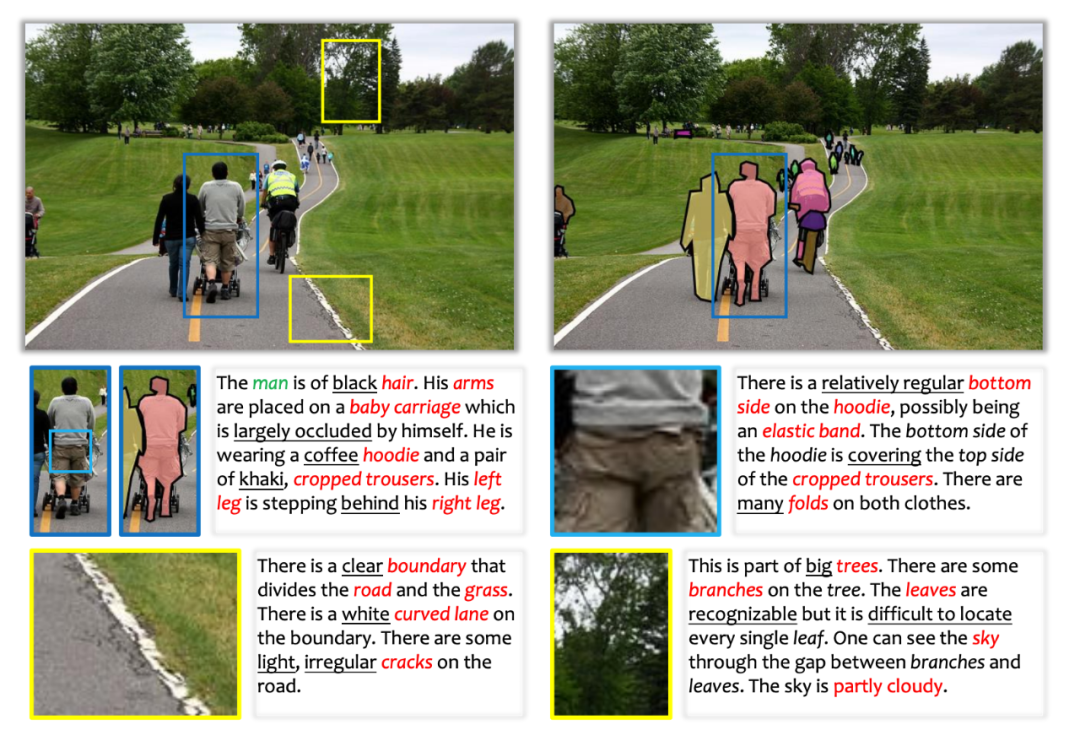
▲ 图1. 现有数据集(如MS-COCO)距离完整地识别所有语义信息,还相差甚远。其中下划线和红色字体标出的部分,都是未在数据集中呈现,而人类能够轻易识别或描述的语义内容。

走向按需视觉识别
基于上述分析,当前基于封闭域(closed-domain)的视觉识别算法无法满足无限细粒度的要求,业界亟需基于开放域(open-domain)的视觉识别算法。当前,在视觉识别中引入文本指引(text-guided),是一种很有前景的,实现开放域的做法。与其他相关工作不同,我们的工作希望探讨识别的完整性,也就是在愿意的情况下能够无限细粒度地识别图像中的语义概念。然而,如果要达到无限细粒度的目标,当前方法存在两大负担。
1. 一致性。当大量物体存在于一张图像上时,必须将这些物体逐一标注/识别出来,除非使用类似 ignore 的选项来回避这个问题。例如,如果拍摄一张人群密集场所的照片,标注其中每个“人”将是很大的负担,甚至是不可能完成的任务。我们的问题是:是否存在一种方式,能够不必标注/识别出所有的物体,只需要标注/识别重要的或者感兴趣的物体?
2. 可扩展性。当一个新的概念被加入到数据集中,必须逐一检查已有的图像,将这个概念标注出来,并且在必要时区分它与其他概念的关系。例如,数据集中已经存在“人”的概念,如果要进一步标注“人的头部”,就需要将所有“人”的“头部”都标注出来,即使有些“人”太小了,他们的“头部”并不容易标注或者容易带来标注误差。当数据集不断增大时,这种方式将会大大增加引入新概念的标注成本。我们的问题是:是否存在一种方式,在引入新概念时,只需要标注若干与新概念相关的图像,而可以忽略已有图像?
显然,只有解决了上述问题,我们才可能构建具有无限细粒度的识别数据集。此时,虽然数据集中包含的视觉概念非常丰富,但这并不意味着我们需要在每张图像上都标注出所有的物体或者概念。这样说也许不够直观,那么重新考虑以上两个例子:
1. 在人群密集场所标注“人”时,能不能允许标注者只标注少数几个人,而标注数量的多少,不会造成精度计算的误差?
2. 在大数据集上标注“人”的部件(如“头部”)时,能不能允许某些“人”的“头部”被标注,某些“人”的“头部”不被标注,而标注数量的多少,不会造成精度计算的误差?
为了达成上述目标,我们需要引入按需视觉识别(visual recognition by request)的概念,即识别算法根据交互式需求,不断地从图像中识别出越来越精细的语义概念。相对地,我们将传统意义上识别任务定义为统一视觉识别(visual recognition all at once),即识别算法事先获取了一个固定的语义概念列表(字典),从而能够从图像中一次性地识别出所有预先定义好的语义概念。

▲ 图2. 统一视觉识别和按需视觉识别的概念性介绍
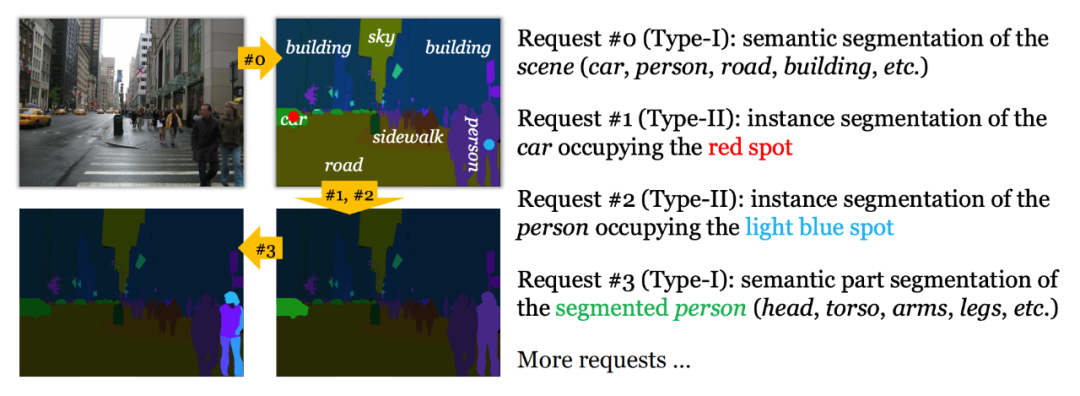
图2直观地对比了两种识别方式。在图中展示的复杂街景图像中,统一视觉识别定义了“人”、“车”等物体以及它们的部件,但是由于图像中某些物体尺寸太小,无法对这些物体以及它们的部件进行标注,这就产生了标注的不一致性。与之相比,按需识别并不假定图中所有物体都需要被标注出来,而是将标注任务表示为若干需求(request),标注者/算法只需要处理这些 request。具体地说,request 被分为两类:
1. 第 1 类 request:整体到部分的语义分割(输入实例、输出语义)。给定某个实例,以及该实例包含的部件列表,将该实例语义级分割为部件。注意:每张图像本身就是一个实例,而其中的第一级语义概念是统一定义的。因此,标注者或者算法在每张图像上处理的第一个request,必然是第1类request。
2. 第 2 类 request:实例分割(输入语义,输出实例)。给定某个语义区域和若干像素(称为 probe),将这些像素对应的实例从该语义区域中分割出来。在当前设定下,这是唯一能够产生实例的方式。然而再次强调:并非所有实例都要被分割出来。
显然,上述两种 request,通过递归调用的形式,可以达成无限细粒度的识别任务。例如,在“人”的基础上,可以识别它的部件“头”,进而识别“头”的部件“眼睛”,进而识别“眼睛”的部件“眼珠”,进而识别“眼珠”的部件“瞳孔”,等等。
注意,为了完成第 1 类 request,我们需要定义一个知识库(knowledge base,如图 1 右部所示),显式地定义每个视觉概念的部件列表。从严格定义上说,知识库是一个具有拓扑结构的图,具体定义可以参见论文。知识库可以在任何时候被更新(如加入某个物体或者在某个物体上增加部件),而由于按需视觉识别的性质,加入新概念并不需要刷新整个数据集,只需要额外加入若干包含新概念的图片,将其中的新概念标注出来即可。
为了实现按需视觉识别,神经网络的输入也略有不同。在传统的统一视觉识别中,网络的输入是图像和固定字典,输出分割结果;而在按需视觉识别中,网络的输入不仅包括图像、知识库(可变字典),还包括当前识别结果和当前 request。神经网络需要进行调整,以适应新的输入。
总而言之,按需视觉识别希望定义一种新的评价体系,使得人们可以实现视觉识别的无限细粒度特性,从而接近视觉识别的开放性和完整性目标。本文的核心思想至此已经介绍完毕。以下,我们详细叙述按需视觉识别的标注、识别、评价方法,并且给出一种基于 query 的解决方案。注意:如果只想了解文章的主要思想,读者并不需要仔细阅读以下的部分,因为它们都很直观,而且可以被视为某种意义上的“实现细节”。
因此,下面的部分我会写得比较简略,对细节感兴趣的读者,请参看我们的论文。

标注和评价指标
既然追求无限细粒度,我们就只考虑分割这种较为彻底的识别任务。如上所述,在知识库(数学定义见论文)的基础上,一张图像的无限细粒度分割,可以表示为一系列 request 任务的集合(数学定义见论文),而这些 request 可以分为两大类:不断调用这两类 request,就可以实现任意粒度的识别。
▲ 图3. 按需视觉识别对应的交互式标注
按需视觉识别,提供了一种新的交互式标注体系。如图 3 所示,一张图像的标注过程(同时也是识别过程)可以表达为若干个 request 的列表(其中某些 request 有严格的先后关系)。其中,第一个 request 永远是全局的语义分割,而后续的 request,则通常是实例分割和语义分割交替的形式。
为了评判分割结果的好坏,我们在全景分割精度指标 PQ 的基础上,定义了一种专门用于按需视觉识别的评价指标,即 Hierarchical PQ(HPQ)。HPQ 将每个语义单元视为一个节点,递归地计算每个节点上的 PQ,并且最终将 PQ 值汇总至根节点,得到全图的 PQ。具体计算方式,请参看论文。

基于query的解决方案
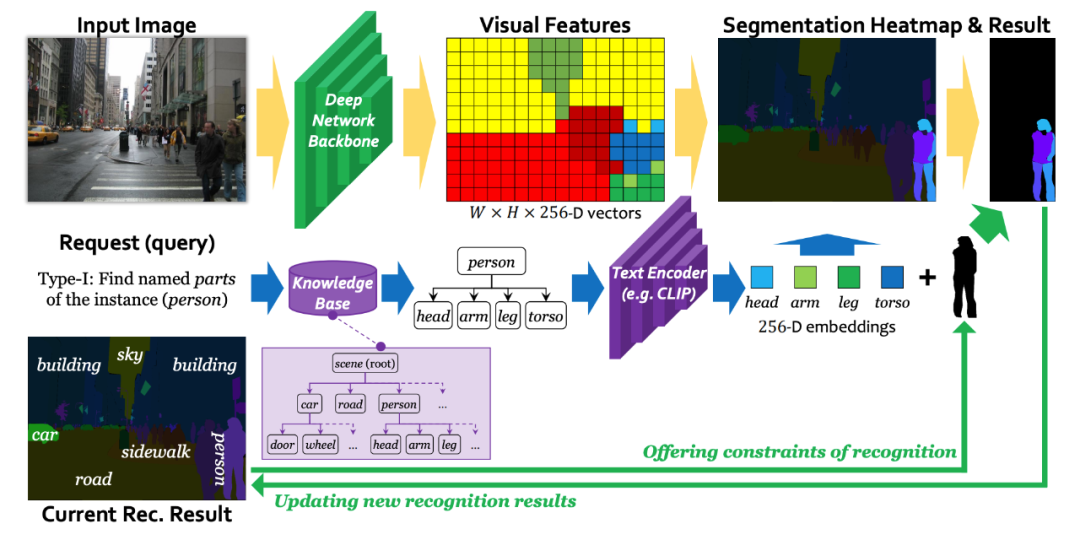
▲ 图4. 处理第1类request的识别框架
识别算法其实很简单。我们分开处理了两类 request,其中第 1 类 request 的处理借鉴了 LSeg[1](其中借用了 CLIP[2] 预训练模型的 text encoder,以处理文本类别输入),而第 2 类 request 的处理借鉴了 CondInst[3]。具体实现,可以参看论文。图 4 是简单的示意图。
实现细节方面,为了加速训练,我们采用了并行化处理的方式,使得每次迭代中,每张图像只需要被送入 LSeg 和 CondInst 各一次。推理时,如果 request 固定,我们也可以如此做,但是系统显然也可以进行交互式推理。

实验结果
我们测试了两个数据集,即 Cityscapes Panoptic Parts(CPP)[4] 和 ADE20K[5]。CPP 数据集包含 19 类物体,其中 5 类物体有共计 9 种部件(有重复),物体和部件的标注都较为完整。ADE20K 数据集包含超过 3000 类物体和超过 600 种部件,我们选取了常用的 150 类物体和 83 种部件,物体和部件的标注有较多缺失。我们使用 CPP 数据集进行诊断实验,而在 ADE20K 数据集上验证按需视觉识别方法的通用性。
具体实验结果请参看论文。我们无意与 SOTA 方法对标精度(我们的精度在给定 backbone 下是 reasonable 的),只是希望说明几个点:
1. 按需视觉识别任务,以及相应的基于 query 的解决方案,可以正常运行,得到 reasonable 的结果。
2. 在物体和部件的标注有较多缺失时(包括在 CPP 数据集上刻意只采样少部分标注,以及在 ADE20K 数据集上),我们的方案能够几乎不受影响地照常运行,这就体现出了按需视觉识别任务的通用性。据我们所知,我们是第一个在 ADE20K 数据集上定量评测带有部件分割结果的工作——我们猜测,之前的方法很可能因为部件标注缺失过多,而很难利用 ADE20K 数据集做相应的实验。
3. 在 ADE20K 数据集上的定量和定性结果表明,在如此复杂(层次化概念多)、noisy(标注很不完整)的数据集上,按需视觉识别的精度还很低。考虑到该数据集中部分标注的内容通常是比较简单的元素,因此真实精度可能更低。也就是说,完整的、无限细粒度的视觉识别问题,可能会暴露出当前深度学习方法更多的不足,值得花费更多的精力去探索。
图 5 展示了在 CPP 数据集上和 ADE20K 数据集上的若干可视化结果。显然,ADE20K 上的结果更差,这一方面是因为 ADE20K 上标注的视觉概念更多,一方面也是因为 ADE20K 上的标注更不完整。
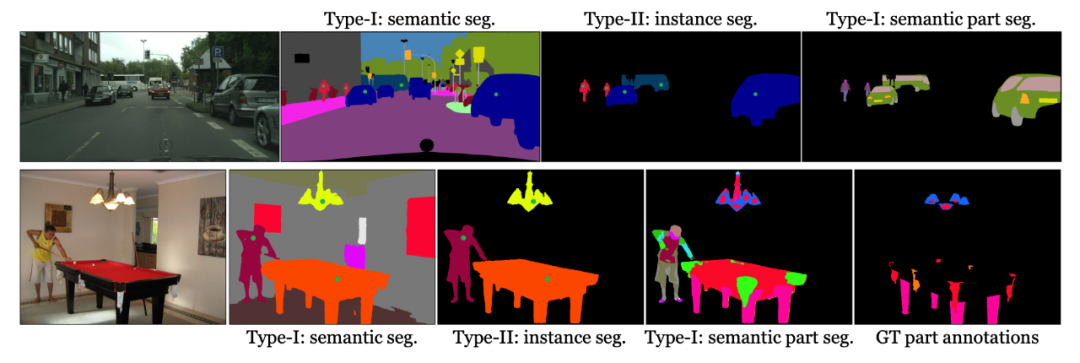
▲ 图5. 若干可视化分割结果,注意分割结果如何随着request,渐进地变得更精细。

总结和未来方向
在这个工作中,我们探索了一种走向完整的、无限细粒度的视觉识别的方法,即按需视觉识别方法。它的核心思想在于,不追求一次性地识别图像中的所有物体,而是在基本语义分割的基础上,(按照需求)交互式地处理 request,并且不断细化识别结果。这样做的最大好处,是增加了标注和识别的一致性和可扩展性,从而揭示了完整的、无限细粒度的视觉识别的可能性。
在此,我也希望澄清几个可能的误解。
1. 按需视觉识别只是图文跨模态识别任务的一个变种。诚然,我们的任务和算法都建立在跨模态的基础上,但是我们的核心目的是探索一种更彻底的视觉识别方法,在此过程中语言起到了辅助作用。与 visual grounding 任务相比,我们不仅局限于使用一句话来 refer 图像中的某个物体,而是希望以一种结构化(基于知识库)的定义方式,使得标注和识别算法有能力识别无限细粒度的语义单元。
2. 按需视觉识别可以被 zero-shot 任务替代。我想表达两个观点。第一,我认为这个世界上本不存在真正的 zero-shot,现行的所谓 zero-shot 都是使用各种方式(如图文预训练)将信息泄露给算法。因此,是否具有类似 zero-shot 的 setting 并非本质,如何定义更合理的视觉识别任务才是更重要的问题。第二, CLIP 的 zero-shot 能力并不像许多人想象的那么强:指望它学习了“人”的身体结构,就能 zero-shot 地迁移到“猩猩”上,其实并不容易也并不合理。因此,我们的建议是,使用 CLIP 配合知识库,并且在加入新概念时配合少量样本(不追求 zero-shot 而追求 few-shot),这从直觉上要更合理一些。
3. 我们的方法没有刷新任何 SOTA。我们本无意这样做。我们感兴趣的,是揭示当前视觉识别系统的局限性,并且提出一种新的可能性。
最后,我简单展望未来的几个重要的研究方向。
1. 按需视觉识别,应当允许引入更多 request,例如允许将分类标签细粒度化,例如对物体的属性进行询问(甚至允许文本输出),又例如对物体之间的关系进行询问(包括引入 scene graph 等信息)。它们都需要修改知识库的基本结构,以支持更复杂的逻辑结构。
2. 进一步地,对于知识库(knowledge base)的改进甚至优化,会成为未来研究的重要课题。尤其是,如何通过一些语料库(包括图像和文本),自主地学习、更新知识库,使其符合需求,是一个非常具有挑战性的问题。
3. 虽然 CLIP 提供了很好的图文预训练模型,如何理解 CLIP、利用 CLIP(包括类似 CLIP 的模型),会成为将来一段时间的重要问题。在这个研究的过程中,我们对于 CLIP 的理解也得到了刷新:比如 CLIP 的开放域识别能力究竟有多强,能做什么、不能做什么,这些问题都需要进一步探讨。
最后的最后,我还是要强调我的观点:对于当前的视觉识别研究来说,定义更合适的评价指标,远比在现有数据集上刷 SOTA 更重要!这个工作只是很小的一步,希望能够为这个 community 带来些许启发。我们也非常欢迎大家的讨论。

参考文献
[1] Li B, Weinberger K Q, Belongie S, et al. Language-driven semantic segmentation[J]. arXiv preprint arXiv:2201.03546, 2022.
[2] Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//International Conference on Machine Learning. PMLR, 2021: 8748-8763.
[3] Tian Z, Shen C, Chen H. Conditional convolutions for instance segmentation[C]//European conference on computer vision. Springer, Cham, 2020: 282-298.
[4] de Geus D, Meletis P, Lu C, et al. Part-aware panoptic segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 5485-5494.
[5] Zhou B, Zhao H, Puig X, et al. Semantic understanding of scenes through the ade20k dataset[J]. International Journal of Computer Vision, 2019, 127(3): 302-321.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·

边栏推荐
- curl命令的那些事
- BigDecimal 使用注意!!“别踩坑”
- Kubernetes之list-watch机制
- Exploration and Practice of Database Governance
- 企业应当实施的5个云安全管理策略
- 12. SAP ABAP OData 服务如何支持 $select 有选择性地仅读取部分模型字段值
- 重构指标之如何监控代码圈复杂度
- The CPU suddenly soars and the system responds slowly, what is the cause?Is there any way to check?
- How to add custom syntax to MySQL?
- SAP UI5 视图控制器 View Controller 的生命周期方法 - Lifecycle methods
猜你喜欢




随机推荐
路由技术
[Distributed Advanced] Let's fill in those pits in Redis distributed locks.
internship:改了需求
STP实验
工业相机CCD与CMOS
ros2订阅esp32发布的电池电压数据-补充
SOA面向服务架构:服务、服务实例、ARXML、服务接口调用以及各参与方
测试工程师如何突破职业瓶颈?
指静脉识别-matlab
PostgreSQL的 SPI_接口函数
如何进行自动化测试?
零基础做出高端堆叠极环图
老电脑怎么重装系统win10
server
win10 uwp DataContext
The CPU suddenly soars and the system responds slowly, what is the cause?Is there any way to check?
《学会写作》粥佐罗著
win10 uwp MVVM 语义耦合
win10 uwp 动态修改ListView元素布局
LVS负载均衡群集之原理叙述