当前位置:网站首页>How is the entered query SQL statement executed?
How is the entered query SQL statement executed?
2022-07-04 20:01:00 【51CTO】
Abstract : Enter a statement , Return a result , But I don't know that this sentence is in MySQL Internal execution process .
This article is shared from Huawei cloud community 《 A query SQL How is it implemented 》, author : Have a drink together .
The implementation is as follows SQL, What we see is just typing a statement , Return a result , But I don't know that this sentence is in MySQL Internal execution process .

The picture above shows MySQL Basic architecture diagram , You can see clearly from it SQL Statements in MySQL The execution process in each function module of . In general ,MySQL Can be divided into Server Layer and storage engine layer .
Server Layers include connectors 、 The query cache 、 analyzer 、 Optimizer 、 Actuators etc. , cover MySQL Most of the core service functions of , And all the built-in functions ( Such as date 、 Time 、 Mathematics and cryptographic functions ), All cross-storage engine functionality is implemented in this layer , Like stored procedures 、 trigger 、 View etc. .
The storage engine layer is responsible for data storage and extraction . Its architecture pattern is plug-in , Support InnoDB、MyISAM、Memory Wait for multiple storage engines . Now the most commonly used storage engine is InnoDB, It is from MySQL 5.5.5 Version began to be the default storage engine . You can also select another engine by specifying the type of storage engine , For example create table Use in statement engine=memory, To specify the use of the memory engine to create tables .
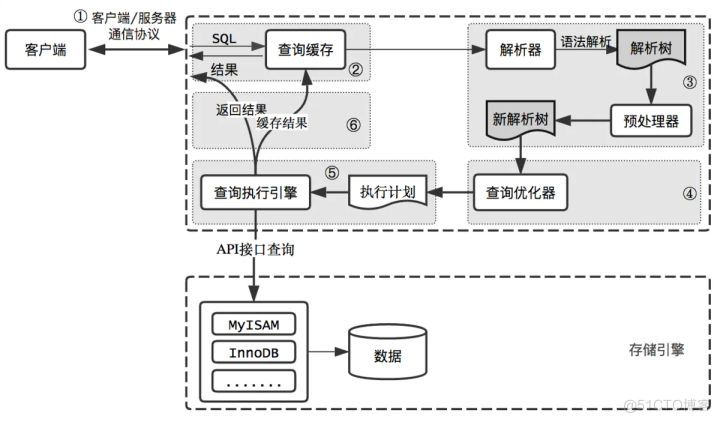
One SQL The complete execution process of query is shown in the figure above .
Server Service layer
The connector
Connecting to the database must be a connector at first . The connector is responsible for establishing a connection with the client 、 Access permissions 、 Maintaining and managing connections . The connection command is usually written like this :
After the command is lost , You need to enter the password in the interactive dialogue . Although the password can also be directly followed by -p It's on the command line , But this may cause your password to leak . If you're connected to a production server , It is strongly recommended that you do not do this .
Connect... In the command mysql It's a client tool , Used to establish a connection with the server . In the completion of the classic TCP After shaking hands , The connector is about to start authenticating your identity , This is the user name and password you entered .
- If the user name or password is wrong , You'll get one "Access denied for user" Error of , Then the client program ends execution .
- If the user name and password are authenticated , The connector will go to the permission table to find out the permissions you have . after , The permission judgment logic in this connection , Will depend on the permissions read at this time .
That means , After a user successfully establishes a connection , Even if you use the administrator account to modify the permissions of this user , It does not affect the permissions of existing connections . After the modification is completed , Only new connections will use the new permission settings .
When the connection is complete , If you don't follow up , This connection is idle , You can show processlist See it in the command . The picture in the text is show processlist Result , Among them Command The column is shown as “Sleep” This line , It means that there is an idle connection in the system .

If the client does not move for a long time , The connector will automatically disconnect it . This time is determined by the parameter wait_timeout The control of the , The default value is 8 Hours .
If after the connection is broken , The client sends the request again , You'll get an error alert : Lost connection to MySQL server during query. At this time, if you want to continue , You have to reconnect , Then the request is executed .
In the database , Long connection refers to the successful connection , If the client continues to have requests , Always use the same connection . Short join refers to the disconnection after a few queries are executed , Create another query the next time .
The process of establishing a connection is usually more complicated , So I suggest that you try to minimize the action of establishing connection in use , That is, try to use long connections . But after using all the long connections , You might notice , Sometimes MySQL Memory usage is rising very fast , This is because MySQL Memory temporarily used during execution is managed in connection objects . These resources will be released when the connection is broken . So if long connections accumulate , May cause too much memory , Killed by the system (OOM), From a phenomenological point of view MySQL Abnormal restart .
How to solve this problem ? You can consider the following two options .
- Regularly disconnect long connections . Use it for a while , Or it can be judged in the program that a large memory consuming query has been executed , disconnect , Then query and reconnect .
- If you're using a MySQL 5.7 Or later , You can do this after each large operation , Through execution mysql_reset_connection To reinitialize the connection resources . This process does not require reconnection and re-authorization , But it restores the connection to the state it was in when it was created .
The query cache
After the connection is established , You can do it select Statement . The execution logic will come to the second step : The query cache .
MySQL After getting a query request , I will go to query cache first , Have you executed this statement before . Previously executed statements and their results may be key-value On the form of , Is directly cached in memory .key Is the statement of the query ,value Is the result of a query . If your query can be found directly in this cache key, So this value Will be returned directly to the client .
If the statement is not in the query cache , I'm going to continue the execution phase . After execution , The execution result will be stored in the query cache . You can see , If the query hits the cache ,MySQL There is no need to perform the following complex operations , I can just return the result , This will be very efficient .
But for the most part I would advise you not to use the query cache , Why? ? Because query caching often does more harm than good .
Query cache failures are very frequent , As long as there is an update to a table , All query caches on this table will be cleared . So it's likely that you're struggling to save the results , It's not in use yet , It's all cleared by an update . For databases that are under pressure to update , The hit rate for the query cache will be very low . Unless your business is a static table , It takes a long time to update . such as , A system configuration table , Then the query on this table is suitable for the query cache .
Fortunately MySQL This is also provided “ According to the need to use ” The way . You can set the parameters query_cache_type Set to DEMAND, So for the default SQL Statements do not use the query cache . For the statements that you decide to use the query cache , It can be used SQL_CACHE Explicitly specify , Like the following statement :
It should be noted that ,MySQL 8.0 Version of the query cache directly removed the entire block , in other words 8.0 It's starting to disappear completely .
analyzer
If the query cache is not hit , It's about time to actually execute the statement . First ,MySQL Need to know what you're going to do , So you need to SQL Statement parsing .
The analyzer will do “ Lexical analysis ”. What you enter is a string with multiple Spaces SQL sentence ,MySQL You need to identify the strings in it , What is the .
MySQL From what you typed "select" This keyword recognizes , This is a query statement . It also takes strings “T” Identify a “ Table name T”, Put the string “ID” Identify a “ Column ID”.
After these identifications , Just do it “ Syntax analysis ”. According to the result of lexical analysis , The parser will follow the grammar rules , Judge the one you typed SQL Does the statement satisfy MySQL grammar .
If your statement is wrong , Will receive “You have an error in your SQL syntax” Error warning , Take the following statement select Less initial letters “s”.
A general syntax error will indicate the first place where the error occurred , So what you want to focus on is immediately “use near” The content of .
Optimizer
Through the analyser ,MySQL You know what you're gonna do . Before we start executing , It's also handled by the optimizer .
The optimizer is when there are multiple indexes in a table , Decide which index to use ; Or there are multiple table associations in a statement (join) When , Determine the join order of the tables . Usually, the logical results of the two execution methods are the same , But the efficiency of the execution will be different , The role of the optimizer is to decide which scheme to use . After the optimizer phase is complete , The execution of this statement is determined , Then we go to the executor phase .
perform SQL When querying, the optimizer mainly performs the following tasks :
- Choose the most appropriate index ;
- Choose table scan or index walk ;
- Select the table Association order ;
- Optimize where Clause ;
- Eliminate useless tables in management ;
- decision order by and group by Whether to follow the index ;
- Try to use inner join Replace outer join;
- Simplify subqueries , Determine the result cache ;
MySQL The query optimizer has several goals , But the main goal is to use indexes as much as possible , And use the strictest index to eliminate as many rows of data as possible .
The reason the optimizer tries to exclude data rows is that the faster it can exclude data rows , The faster it is to find the data row that matches the condition . If you can do the most rigorous testing first , Queries can be executed faster .
actuator
MySQL I know what you are going to do through the analyzer , You know what to do with the optimizer , So it goes into the actuator stage , Start statement execution .
At the beginning of execution , Let's first judge what you do to this watch T Do you have permission to execute the query , without , An error with no permissions is returned , As shown below ( In engineering implementation , If you hit the query cache , When the query cache returns results , Do authority verification . Queries will also be called before the optimizer precheck Verify permissions ).
If you have authority , Open the table and continue . When I open my watch , The actuator is defined according to the engine of the table , Use the interface provided by the engine .
For example, the table in our example T in ,ID Field has no index , So the execution process of the actuator is like this :
- call InnoDB The engine interface takes the first row of this table , Judge ID Value is 10, If not, skip , If it is, the row will exist in the result set ;
- Call the engine interface “ The next line ”, Repeat the same logic of judgment , Until you get to the last row of the table .
- The executor returns the record set composed of all the rows that meet the conditions in the traversal process to the client as a result set .
thus , This statement is executed .
For tables with indexes , The execution logic is similar . The first time I call this “ Let's take the first row that satisfies our condition ” This interface , And then we loop “ That satisfies the next row ” This interface , These interfaces are all defined in the engine .
You will see a... In the slow query log of the database rows_examined Field of , Indicates how many rows were scanned during the execution of the statement . This value is accumulated each time the actuator calls the engine to get a row of data .
In some cases , The executor is called once , Inside the engine, it scans multiple lines , So the engine scans the number of rows followed rows_examined It's not exactly the same .
Storage engine
adopt show engines; View engine type , You can see that you can only use InnoDB Engine type .

InnoDB Storage engine
InnoDB yes MySQL The default transactional engine for , And most importantly 、 The most widely used storage engine , And there are row level locking and foreign key constraints . It's designed to handle a lot of short-term (short-lived) Business , Short term transactions are mostly committed normally , It's rarely rolled back .InnoDB Performance and auto crash recovery features , This makes it popular in the demand of non transactional storage . Unless there's a very special reason to use another storage engine , Otherwise, priority should be given to InnoDB engine .
InnoDB The applicable scenarios of / characteristic , There are the following :
- Frequently updated tables , Suitable for handling multiple concurrent update requests .
- Support transactions .
- Can recover from disaster ( adopt bin-log Log etc. ).
- Foreign key constraints . Only he supports foreign key .
- Support automatic addition of column properties auto_increment.
MyISAM Storage engine
MyISAM There are a lot of features , Including full-text search 、 Compression etc. , But transaction and row level locks are not supported , Support table level lock . For read-only data , Or the table is smaller 、 Scenarios that can tolerate repair operations , Still usable MyISAM.
MyISAM The applicable scenarios of / characteristic , There are the following :
- Transaction design is not supported , But it doesn't mean that projects with transaction operations can't be used MyISAM Storage engine , It can be completely controlled at the program level according to its own business requirements .
- Table design that does not support foreign keys .
- Fast query , If the database insert and update If there are more operations, they are more applicable .
- All day The scene of locking a table .
- MyISAM Extreme emphasis on fast read operations .
- MyIASM The number of rows in the table is stored in , therefore SELECT COUNT(*) FROM TABLE Only the saved values need to be read directly without scanning the whole table . If the read operation of the table is far more than the write operation and does not need the support of database transaction , that MyIASM It's also a good choice .
MySQL Other built-in storage engines
MySQL There are also some special purpose storage engines , It's great to use in some special situations . stay MySQL In the new version , Some may no longer support it for some reason , Others will continue to support , But it needs to be explicitly enabled before it can be used .
Archive Storage engine
Archive The engine only supports insert and select operation , And in MySQL 5.1 It didn't even support indexing before .
Archive The engine caches all writes and takes advantage of zlib Compress the inserted rows , So than MyISAM The disk of the engine I/O less . But every time select All queries need full table scanning , therefore Archive It is more suitable for log and data collection applications , Moreover, this kind of application often needs full table scanning when doing data analysis .
Archive The engine supports row level locks and dedicated buffers , So we can achieve high concurrency insertion . Before a query starts until all the rows in the table are returned ,Archive The engine will stop the others select perform , To achieve consistent reading . in addition , This also enables batch inserts to be invisible to read operations until they are completed .
Blackhole Storage engine
Blackhole The engine doesn't implement any storage mechanism , It will lose all inserted data , Don't save anything . Strange , Isn't it useless ? But the server will record Blackhole Log , So it can be used to copy data to the standby database , Or simply log it . This special storage engine can play a role in some special replication architecture and log auditing .
But the existence of this storage engine , It's still hard to understand .
CSV Storage engine
CSV The engine can make ordinary CSV File as MySQL To deal with , But this kind of table doesn't support indexes .
CSV The engine can copy in or out files when the database is running , Can be Excel The data in the spreadsheet software is stored as CSV file , Then copy it to MySQL Data directory , You can be in MySQL Open to use . Again , If you write data to a CSV In the engine list , Other external programs can also immediately read from the table's data file CSV Formatted data .
therefore ,CSV The engine can be used as a data exchange mechanism , It's very useful .
Memory Storage engine
If you need to access data quickly , And the data won't be modified , It doesn't matter if it's lost after restart , So use Memory Engines are very useful .Memory The engine is at least better than MyISAM The engine needs to be an order of magnitude faster , Because all the data is stored in memory , No disk required I/O.Memory The table structure of the engine will remain after restart , But the data will be lost .
Memory Engines can work well in many scenarios :
- Used to find or map tables , For example, a table that maps a mailbox to a state .
- Used to cache the results of periodically aggregated data .
- Used to save intermediate data generated in data analysis .
Memory Engine support Hash Indexes , So the search is very fast . although Memory Very fast , But it can't replace the traditional disk based tables .Memory The engine is a table level lock , Therefore, the performance of concurrent inhalation is low .
If MySQL During the execution of the query , You need to use a temporary table to save intermediate results , The temporary watch used internally is Memory engine . If the intermediate result is too big, it goes beyond Memory The limitation of , Or it contains BLOB or TEXT Field , Then the temporary table is converted to MyISAM The engine of .
Look at the instructions above , People will often confuse Memory And temporary tables . Temporary tables refer to the use of CREATE TEMPORARY TABLE Statement , It can use any storage engine , So with Memory It's not the same thing . Temporary tables are only visible in a single connection , When the connection is disconnected , Temporary tables will no longer exist .
About temporary tables and Memory Things about the engine , May refer to MySQL · Engine features · Temporary watch things .
MySQL Storage engine and third-party storage engine , There are still a lot of it , I will not introduce you here , Follow up if necessary , Let's go further .
How to choose the right storage engine
So many storage engines , It's dazzling , How can we choose ?
In most cases , Will choose the default storage engine ——InnoDB, And it's the right choice , therefore Oracle stay MySQL 5.5 Version will finally InnoDB As the default storage engine .
How to choose the right storage engine , It can be simply summed up into a sentence :” Unless you need to use something InnoDB Features not available , And there is no substitute for , Otherwise, we should give priority to InnoDB engine ”.
for example , If you want to use Full-text Retrieval , It is suggested that priority be given to InnoDB add Sphinx The combination of , Instead of using MyISAM. Of course , If you don't need to use InnoDB Characteristics of , At the same time, other engine features can better meet the needs , Consider other storage engines .
Unless you have to , It is not recommended to mix multiple storage engines , Otherwise, it may bring a series of complex problems , And some potential bug And boundary problems .
If you need to use a different storage engine , It is suggested to consider the following factors .
- Business
- Backup
- recovery
- Unique characteristics
Other search engines SQL
View the default storage engine through the following command .
If there is harvest , Just like it
Click to follow , The first time to learn about Huawei's new cloud technology ~
边栏推荐
- BCG 使用之CBCGPProgressDlgCtrl進度條使用
- Niuke Xiaobai month race 7 e applese's super ability
- 实战模拟│JWT 登录认证
- Functional interface
- HMM隐马尔可夫模型最详细讲解与代码实现
- 黑马程序员-软件测试--07阶段2-linux和数据库-09-24-linux命令学习步骤,通配符,绝对路径,相对路径,文件和目录常用命令,文件内容相关操作,查看日志文件,ping命令使用,
- Personal thoughts on Architecture Design (this article will be revised and updated continuously later)
- . Net ORM framework hisql practice - Chapter 2 - using hisql to realize menu management (add, delete, modify and check)
- New wizard effect used by BCG
- kotlin 条件控制
猜你喜欢
Cbcgptabwnd control used by BCG (equivalent to MFC TabControl)

Introduction to polyfit software
YOLOv5s-ShuffleNetV2

"Only one trip", active recommendation and exploration of community installation and maintenance tasks
BCG 使用之新建向导效果

Hough transform Hough transform principle

Several methods of online database migration
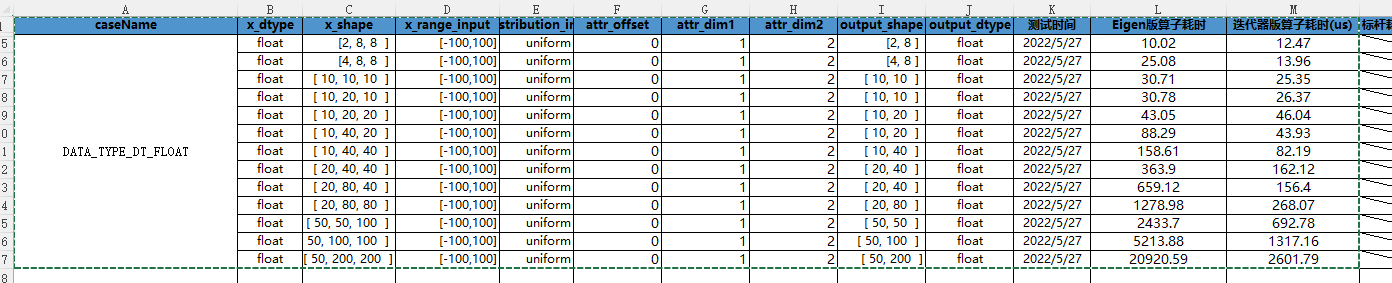
CANN算子:利用迭代器高效实现Tensor数据切割分块处理

Online text line fixed length fill tool
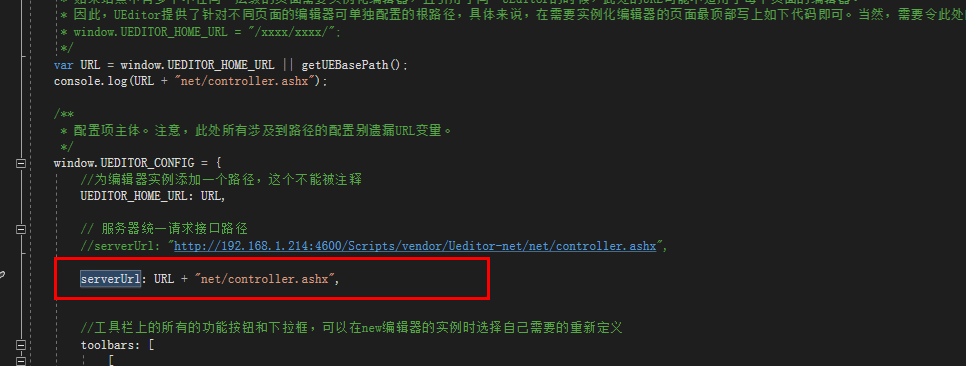
c# .net mvc 使用百度Ueditor富文本框上传文件(图片,视频等)
随机推荐
In the first month of its launch, the tourist praise rate of this campsite was as high as 99.9%! How did he do it?
Basic use of kotlin
Pointnext: review pointnet through improved model training and scaling strategies++
1007 maximum subsequence sum (25 points) (PAT class a)
Educational codeforces round 22 E. Army Creation
1002. A+B for Polynomials (25)(PAT甲级)
Detailed explanation of the binary processing function threshold() of opencv
多表操作-外连接查询
1003 Emergency(25 分)(PAT甲级)
Kotlin classes and objects
牛客小白月赛7 I 新建 Microsoft Office Word 文档
PointNeXt:通过改进的模型训练和缩放策略审视PointNet++
记一次 .NET 某工控数据采集平台 线程数 爆高分析
Niuke Xiaobai monthly race 7 I new Microsoft Office Word document
Several methods of online database migration
1005 Spell It Right(20 分)(PAT甲级)
黑马程序员-软件测试--07阶段2-linux和数据库-09-24-linux命令学习步骤,通配符,绝对路径,相对路径,文件和目录常用命令,文件内容相关操作,查看日志文件,ping命令使用,
Comment utiliser async awati asynchrone Task Handling au lieu de backgroundworker?
An example of multi module collaboration based on NCF
Multi table operation - external connection query